 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConFi-GS Confidence-Guided High-Frequency Injection for 3D Gaussian Splatting Super-Resolution
May 24, 2026Reconstructing high-quality 3D scenes from low-resolution multi-view images remains challenging for 3D Gaussian Splatting (3DGS), because insufficient high-frequency observations often lead to blurred textures, weak boundaries, and view-inconsistent details. Existing approaches either apply super-resolution guidance uniformly or localize enhancement regions based mainly on geometric sampling. However, they typically do not distinguish between two fundamentally different questions: where additional detail is needed, and whether the corresponding candidate high-frequency content is reliable enough to be internalized into a multi-view consistent 3D representation. In this paper, we propose a reliability-aware frequency modeling framework for low-resolution 3DGS reconstruction. The framework first estimates a geometry-guided detail-demand prior to locate regions that are likely under-detailed under low-resolution supervision. It then computes a frequency-aware reliability map to determine whether candidate high-frequency details are structurally supported, spectrally unresolved, and cross-view stable. Combining these signals yields a detail-injection map that guides where super-resolved details should be introduced during optimization. Based on this map, we design a unified optimization scheme comprising spatially selective supervision, coarse-to-fine frequency regularization, and reliability-aware Gaussian densification. This scheme controls where reliable details are injected, when high-frequency supervision is activated, and how unresolved yet reliable details are internalized into the Gaussian representation. Experiments on multiple benchmarks show improved fidelity and perceptual quality while suppressing unstable or view-inconsistent details.
ResLPR: A LiDAR Data Restoration Network and Benchmark for Robust Place Recognition Against Weather Corruptions
Mar 16, 2025



LiDAR-based place recognition (LPR) is a key component for autonomous driving, and its resilience to environmental corruption is critical for safety in high-stakes applications. While state-of-the-art (SOTA) LPR methods perform well in clean weather, they still struggle with weather-induced corruption commonly encountered in driving scenarios. To tackle this, we propose ResLPRNet, a novel LiDAR data restoration network that largely enhances LPR performance under adverse weather by restoring corrupted LiDAR scans using a wavelet transform-based network. ResLPRNet is efficient, lightweight and can be integrated plug-and-play with pretrained LPR models without substantial additional computational cost. Given the lack of LPR datasets under adverse weather, we introduce ResLPR, a novel benchmark that examines SOTA LPR methods under a wide range of LiDAR distortions induced by severe snow, fog, and rain conditions. Experiments on our proposed WeatherKITTI and WeatherNCLT datasets demonstrate the resilience and notable gains achieved by using our restoration method with multiple LPR approaches in challenging weather scenarios. Our code and benchmark are publicly available here: https://github.com/nubot-nudt/ResLPR.
LuSeg: Efficient Negative and Positive Obstacles Segmentation via Contrast-Driven Multi-Modal Feature Fusion on the Lunar
Mar 14, 2025



As lunar exploration missions grow increasingly complex, ensuring safe and autonomous rover-based surface exploration has become one of the key challenges in lunar exploration tasks. In this work, we have developed a lunar surface simulation system called the Lunar Exploration Simulator System (LESS) and the LunarSeg dataset, which provides RGB-D data for lunar obstacle segmentation that includes both positive and negative obstacles. Additionally, we propose a novel two-stage segmentation network called LuSeg. Through contrastive learning, it enforces semantic consistency between the RGB encoder from Stage I and the depth encoder from Stage II. Experimental results on our proposed LunarSeg dataset and additional public real-world NPO road obstacle dataset demonstrate that LuSeg achieves state-of-the-art segmentation performance for both positive and negative obstacles while maintaining a high inference speed of approximately 57\,Hz. We have released the implementation of our LESS system, LunarSeg dataset, and the code of LuSeg at:https://github.com/nubot-nudt/LuSeg.
HI-GVF: Shared Control based on Human-Influenced Guiding Vector Fields for Human-multi-robot Cooperation
Feb 17, 2025



Human-multi-robot shared control leverages human decision-making and robotic autonomy to enhance human-robot collaboration. While widely studied, existing systems often adopt a leader-follower model, limiting robot autonomy to some extent. Besides, a human is required to directly participate in the motion control of robots through teleoperation, which significantly burdens the operator. To alleviate these two issues, we propose a layered shared control computing framework using human-influenced guiding vector fields (HI-GVF) for human-robot collaboration. HI-GVF guides the multi-robot system along a desired path specified by the human. Then, an intention field is designed to merge the human and robot intentions, accelerating the propagation of the human intention within the multi-robot system. Moreover, we give the stability analysis of the proposed model and use collision avoidance based on safety barrier certificates to fine-tune the velocity. Eventually, considering the firefighting task as an example scenario, we conduct simulations and experiments using multiple human-robot interfaces (brain-computer interface, myoelectric wristband, eye-tracking), and the results demonstrate that our proposed approach boosts the effectiveness and performance of the task.
NeuroVE: Brain-inspired Linear-Angular Velocity Estimation with Spiking Neural Networks
Aug 28, 2024



Vision-based ego-velocity estimation is a fundamental problem in robot state estimation. However, the constraints of frame-based cameras, including motion blur and insufficient frame rates in dynamic settings, readily lead to the failure of conventional velocity estimation techniques. Mammals exhibit a remarkable ability to accurately estimate their ego-velocity during aggressive movement. Hence, integrating this capability into robots shows great promise for addressing these challenges. In this paper, we propose a brain-inspired framework for linear-angular velocity estimation, dubbed NeuroVE. The NeuroVE framework employs an event camera to capture the motion information and implements spiking neural networks (SNNs) to simulate the brain's spatial cells' function for velocity estimation. We formulate the velocity estimation as a time-series forecasting problem. To this end, we design an Astrocyte Leaky Integrate-and-Fire (ALIF) neuron model to encode continuous values. Additionally, we have developed an Astrocyte Spiking Long Short-term Memory (ASLSTM) structure, which significantly improves the time-series forecasting capabilities, enabling an accurate estimate of ego-velocity. Results from both simulation and real-world experiments indicate that NeuroVE has achieved an approximate 60% increase in accuracy compared to other SNN-based approaches.
DVRP-MHSI: Dynamic Visualization Research Platform for Multimodal Human-Swarm Interaction
Aug 20, 2024



In recent years, there has been a significant amount of research on algorithms and control methods for distributed collaborative robots. However, the emergence of collective behavior in a swarm is still difficult to predict and control. Nevertheless, human interaction with the swarm helps render the swarm more predictable and controllable, as human operators can utilize intuition or knowledge that is not always available to the swarm. Therefore, this paper designs the Dynamic Visualization Research Platform for Multimodal Human-Swarm Interaction (DVRP-MHSI), which is an innovative open system that can perform real-time dynamic visualization and is specifically designed to accommodate a multitude of interaction modalities (such as brain-computer, eye-tracking, electromyographic, and touch-based interfaces), thereby expediting progress in human-swarm interaction research. Specifically, the platform consists of custom-made low-cost omnidirectional wheeled mobile robots, multitouch screens and two workstations. In particular, the mutitouch screens can recognize human gestures and the shapes of objects placed on them, and they can also dynamically render diverse scenes. One of the workstations processes communication information within robots and the other one implements human-robot interaction methods. The development of DVRP-MHSI frees researchers from hardware or software details and allows them to focus on versatile swarm algorithms and human-swarm interaction methods without being limited to fixed scenarios, tasks, and interfaces. The effectiveness and potential of the platform for human-swarm interaction studies are validated by several demonstrative experiments.
TD-NeRF: Novel Truncated Depth Prior for Joint Camera Pose and Neural Radiance Field Optimization
May 11, 2024



The reliance on accurate camera poses is a significant barrier to the widespread deployment of Neural Radiance Fields (NeRF) models for 3D reconstruction and SLAM tasks. The existing method introduces monocular depth priors to jointly optimize the camera poses and NeRF, which fails to fully exploit the depth priors and neglects the impact of their inherent noise. In this paper, we propose Truncated Depth NeRF (TD-NeRF), a novel approach that enables training NeRF from unknown camera poses - by jointly optimizing learnable parameters of the radiance field and camera poses. Our approach explicitly utilizes monocular depth priors through three key advancements: 1) we propose a novel depth-based ray sampling strategy based on the truncated normal distribution, which improves the convergence speed and accuracy of pose estimation; 2) to circumvent local minima and refine depth geometry, we introduce a coarse-to-fine training strategy that progressively improves the depth precision; 3) we propose a more robust inter-frame point constraint that enhances robustness against depth noise during training. The experimental results on three datasets demonstrate that TD-NeRF achieves superior performance in the joint optimization of camera pose and NeRF, surpassing prior works, and generates more accurate depth geometry. The implementation of our method has been released at https://github.com/nubot-nudt/TD-NeRF.
Spatio-Temporal Calibration for Omni-Directional Vehicle-Mounted Event Cameras
Jul 19, 2023We present a solution to the problem of spatio-temporal calibration for event cameras mounted on an onmi-directional vehicle. Different from traditional methods that typically determine the camera's pose with respect to the vehicle's body frame using alignment of trajectories, our approach leverages the kinematic correlation of two sets of linear velocity estimates from event data and wheel odometers, respectively. The overall calibration task consists of estimating the underlying temporal offset between the two heterogeneous sensors, and furthermore, recovering the extrinsic rotation that defines the linear relationship between the two sets of velocity estimates. The first sub-problem is formulated as an optimization one, which looks for the optimal temporal offset that maximizes a correlation measurement invariant to arbitrary linear transformation. Once the temporal offset is compensated, the extrinsic rotation can be worked out with an iterative closed-form solver that incrementally registers associated linear velocity estimates. The proposed algorithm is proved effective on both synthetic data and real data, outperforming traditional methods based on alignment of trajectories.
Convolutional Neural Networks with A Topographic Representation Module for EEG-Based Brain-Computer Interfaces
Aug 30, 2022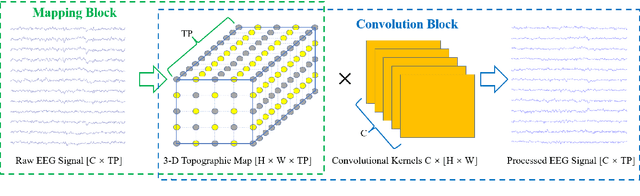
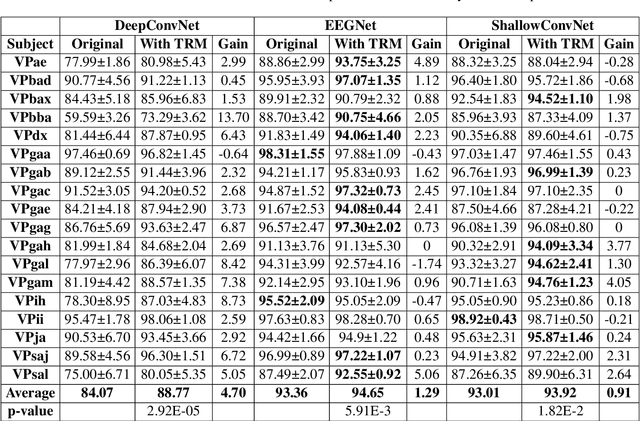
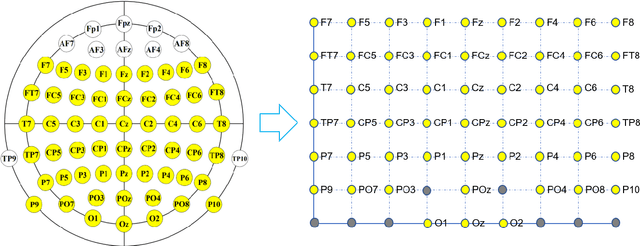
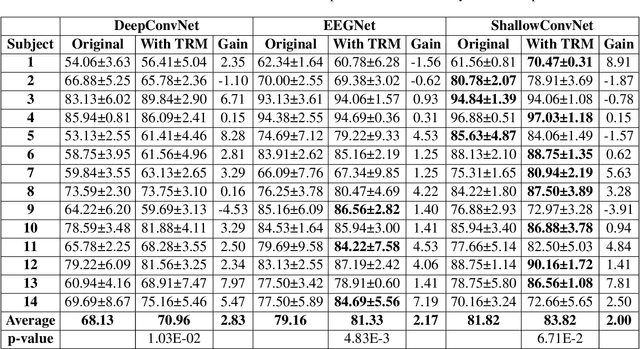
Objective: Convolutional Neural Networks (CNNs) have shown great potential in the field of Brain-Computer Interfaces (BCIs). The raw Electroencephalogram (EEG) signal is usually represented as 2-Dimensional (2-D) matrix composed of channels and time points, which ignores the spatial topological information. Our goal is to make the CNN with the raw EEG signal as input have the ability to learn EEG spatial topological features, and improve its performance while essentially maintaining its original structure. Methods:We propose an EEG Topographic Representation Module (TRM). This module consists of (1) a mapping block from the raw EEG signal to a 3-D topographic map and (2) a convolution block from the topographic map to an output of the same size as input. According to the size of the kernel used in the convolution block, we design 2 types of TRMs, namely TRM-(5,5) and TRM-(3,3). We embed the TRM into 3 widely used CNNs, and tested them on 2 publicly available datasets (Emergency Braking During Simulated Driving Dataset (EBDSDD), and High Gamma Dataset (HGD)). Results: The results show that the classification accuracies of all 3 CNNs are improved on both datasets after using the TRM. With TRM-(5,5), the average accuracies of DeepConvNet, EEGNet and ShallowConvNet are improved by 6.54%, 1.72% and 2.07% on EBDSDD, and by 6.05%, 3.02% and 5.14% on HGD, respectively; with TRM-(3,3), they are improved by 7.76%, 1.71% and 2.17% on EBDSDD, and by 7.61%, 5.06% and 6.28% on HGD, respectively. Significance: We improve the classification performance of 3 CNNs on 2 datasets by the use of TRM, indicating that it has the capability to mine the EEG spatial topological information. In addition, since the output of TRM has the same size as the input, CNNs with the raw EEG signal as input can use this module without changing their original structures.
Robot Navigation in a Crowd by Integrating Deep Reinforcement Learning and Online Planning
Feb 26, 2021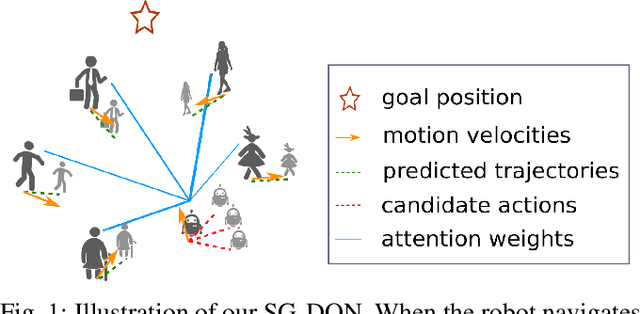
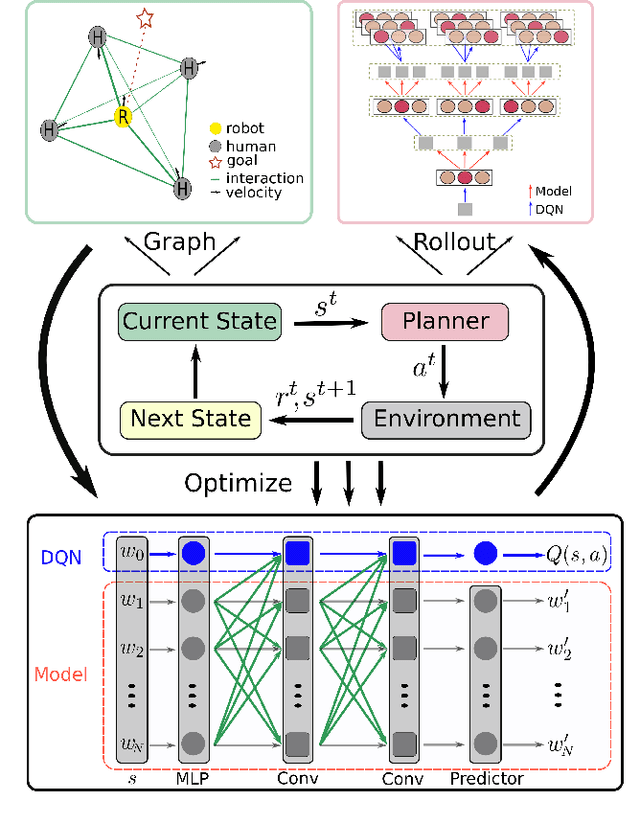
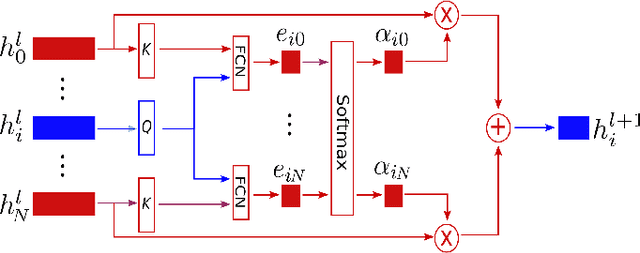
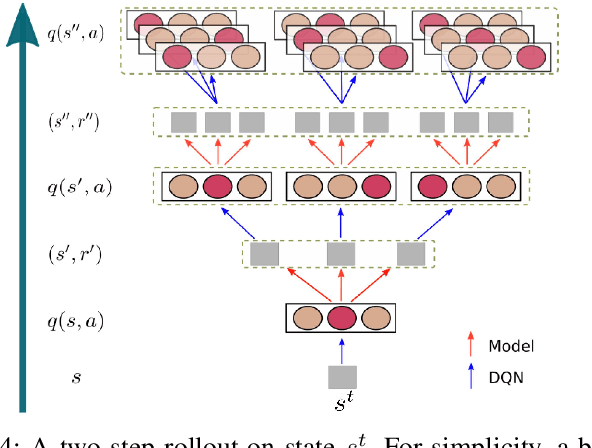
It is still an open and challenging problem for mobile robots navigating along time-efficient and collision-free paths in a crowd. The main challenge comes from the complex and sophisticated interaction mechanism, which requires the robot to understand the crowd and perform proactive and foresighted behaviors. Deep reinforcement learning is a promising solution to this problem. However, most previous learning methods incur a tremendous computational burden. To address these problems, we propose a graph-based deep reinforcement learning method, SG-DQN, that (i) introduces a social attention mechanism to extract an efficient graph representation for the crowd-robot state; (ii) directly evaluates the coarse q-values of the raw state with a learned dueling deep Q network(DQN); and then (iii) refines the coarse q-values via online planning on possible future trajectories. The experimental results indicate that our model can help the robot better understand the crowd and achieve a high success rate of more than 0.99 in the crowd navigation task. Compared against previous state-of-the-art algorithms, our algorithm achieves an equivalent, if not better, performance while requiring less than half of the computational cost.