 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscapeBench: Pushing Language Models to Think Outside the Box
Dec 18, 2024Language model agents excel in long-session planning and reasoning, but existing benchmarks primarily focus on goal-oriented tasks with explicit objectives, neglecting creative adaptation in unfamiliar environments. To address this, we introduce EscapeBench, a benchmark suite of room escape game environments designed to challenge agents with creative reasoning, unconventional tool use, and iterative problem-solving to uncover implicit goals. Our results show that current LM models, despite employing working memory and Chain-of-Thought reasoning, achieve only 15% average progress without hints, highlighting their limitations in creativity. To bridge this gap, we propose EscapeAgent, a framework designed to enhance creative reasoning through Foresight (innovative tool use) and Reflection (identifying unsolved tasks). Experiments show that EscapeAgent can execute action chains over 1,000 steps while maintaining logical coherence. It navigates and completes games with up to 40% fewer steps and hints, performs robustly across varying difficulty levels, and achieves higher action success rates with more efficient and innovative puzzle-solving strategies. All the data and codes are released.
Do LLMs Know to Respect Copyright Notice?
Nov 02, 2024



Prior study shows that LLMs sometimes generate content that violates copyright. In this paper, we study another important yet underexplored problem, i.e., will LLMs respect copyright information in user input, and behave accordingly? The research problem is critical, as a negative answer would imply that LLMs will become the primary facilitator and accelerator of copyright infringement behavior. We conducted a series of experiments using a diverse set of language models, user prompts, and copyrighted materials, including books, news articles, API documentation, and movie scripts. Our study offers a conservative evaluation of the extent to which language models may infringe upon copyrights when processing user input containing protected material. This research emphasizes the need for further investigation and the importance of ensuring LLMs respect copyright regulations when handling user input to prevent unauthorized use or reproduction of protected content. We also release a benchmark dataset serving as a test bed for evaluating infringement behaviors by LLMs and stress the need for future alignment.
Measuring Copyright Risks of Large Language Model via Partial Information Probing
Sep 20, 2024



Exploring the data sources used to train Large Language Models (LLMs) is a crucial direction in investigating potential copyright infringement by these models. While this approach can identify the possible use of copyrighted materials in training data, it does not directly measure infringing risks. Recent research has shifted towards testing whether LLMs can directly output copyrighted content. Addressing this direction, we investigate and assess LLMs' capacity to generate infringing content by providing them with partial information from copyrighted materials, and try to use iterative prompting to get LLMs to generate more infringing content. Specifically, we input a portion of a copyrighted text into LLMs, prompt them to complete it, and then analyze the overlap between the generated content and the original copyrighted material. Our findings demonstrate that LLMs can indeed generate content highly overlapping with copyrighted materials based on these partial inputs.
FinCon: A Synthesized LLM Multi-Agent System with Conceptual Verbal Reinforcement for Enhanced Financial Decision Making
Jul 10, 2024



Large language models (LLMs) have demonstrated notable potential in conducting complex tasks and are increasingly utilized in various financial applications. However, high-quality sequential financial investment decision-making remains challenging. These tasks require multiple interactions with a volatile environment for every decision, demanding sufficient intelligence to maximize returns and manage risks. Although LLMs have been used to develop agent systems that surpass human teams and yield impressive investment returns, opportunities to enhance multi-sourced information synthesis and optimize decision-making outcomes through timely experience refinement remain unexplored. Here, we introduce the FinCon, an LLM-based multi-agent framework with CONceptual verbal reinforcement tailored for diverse FINancial tasks. Inspired by effective real-world investment firm organizational structures, FinCon utilizes a manager-analyst communication hierarchy. This structure allows for synchronized cross-functional agent collaboration towards unified goals through natural language interactions and equips each agent with greater memory capacity than humans. Additionally, a risk-control component in FinCon enhances decision quality by episodically initiating a self-critiquing mechanism to update systematic investment beliefs. The conceptualized beliefs serve as verbal reinforcement for the future agent's behavior and can be selectively propagated to the appropriate node that requires knowledge updates. This feature significantly improves performance while reducing unnecessary peer-to-peer communication costs. Moreover, FinCon demonstrates strong generalization capabilities in various financial tasks, including single stock trading and portfolio management.
Make Graph Neural Networks Great Again: A Generic Integration Paradigm of Topology-Free Patterns for Traffic Speed Prediction
Jun 24, 2024



Urban traffic speed prediction aims to estimate the future traffic speed for improving urban transportation services. Enormous efforts have been made to exploit Graph Neural Networks (GNNs) for modeling spatial correlations and temporal dependencies of traffic speed evolving patterns, regularized by graph topology.While achieving promising results, current traffic speed prediction methods still suffer from ignoring topology-free patterns, which cannot be captured by GNNs. To tackle this challenge, we propose a generic model for enabling the current GNN-based methods to preserve topology-free patterns. Specifically, we first develop a Dual Cross-Scale Transformer (DCST) architecture, including a Spatial Transformer and a Temporal Transformer, to preserve the cross-scale topology-free patterns and associated dynamics, respectively. Then, to further integrate both topology-regularized/-free patterns, we propose a distillation-style learning framework, in which the existing GNN-based methods are considered as the teacher model, and the proposed DCST architecture is considered as the student model. The teacher model would inject the learned topology-regularized patterns into the student model for integrating topology-free patterns. The extensive experimental results demonstrated the effectiveness of our methods.
FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
Dec 03, 2023



Recent advancements in Large Language Models (LLMs) have exhibited notable efficacy in question-answering (QA) tasks across diverse domains. Their prowess in integrating extensive web knowledge has fueled interest in developing LLM-based autonomous agents. While LLMs are efficient in decoding human instructions and deriving solutions by holistically processing historical inputs, transitioning to purpose-driven agents requires a supplementary rational architecture to process multi-source information, establish reasoning chains, and prioritize critical tasks. Addressing this, we introduce \textsc{FinMem}, a novel LLM-based agent framework devised for financial decision-making. It encompasses three core modules: Profiling, to customize the agent's characteristics; Memory, with layered message processing, to aid the agent in assimilating hierarchical financial data; and Decision-making, to convert insights gained from memories into investment decisions. Notably, \textsc{FinMem}'s memory module aligns closely with the cognitive structure of human traders, offering robust interpretability and real-time tuning. Its adjustable cognitive span allows for the retention of critical information beyond human perceptual limits, thereby enhancing trading outcomes. This framework enables the agent to self-evolve its professional knowledge, react agilely to new investment cues, and continuously refine trading decisions in the volatile financial environment. We first compare \textsc{FinMem} with various algorithmic agents on a scalable real-world financial dataset, underscoring its leading trading performance in stocks. We then fine-tuned the agent's perceptual span and character setting to achieve a significantly enhanced trading performance. Collectively, \textsc{FinMem} presents a cutting-edge LLM agent framework for automated trading, boosting cumulative investment returns.
Boosting Urban Traffic Speed Prediction via Integrating Implicit Spatial Correlations
Dec 25, 2022Urban traffic speed prediction aims to estimate the future traffic speed for improving the urban transportation services. Enormous efforts have been made on exploiting spatial correlations and temporal dependencies of traffic speed evolving patterns by leveraging explicit spatial relations (geographical proximity) through pre-defined geographical structures ({\it e.g.}, region grids or road networks). While achieving promising results, current traffic speed prediction methods still suffer from ignoring implicit spatial correlations (interactions), which cannot be captured by grid/graph convolutions. To tackle the challenge, we propose a generic model for enabling the current traffic speed prediction methods to preserve implicit spatial correlations. Specifically, we first develop a Dual-Transformer architecture, including a Spatial Transformer and a Temporal Transformer. The Spatial Transformer automatically learns the implicit spatial correlations across the road segments beyond the boundary of geographical structures, while the Temporal Transformer aims to capture the dynamic changing patterns of the implicit spatial correlations. Then, to further integrate both explicit and implicit spatial correlations, we propose a distillation-style learning framework, in which the existing traffic speed prediction methods are considered as the teacher model, and the proposed Dual-Transformer architectures are considered as the student model. The extensive experiments over three real-world datasets indicate significant improvements of our proposed framework over the existing methods.
Human-instructed Deep Hierarchical Generative Learning for Automated Urban Planning
Dec 01, 2022The essential task of urban planning is to generate the optimal land-use configuration of a target area. However, traditional urban planning is time-consuming and labor-intensive. Deep generative learning gives us hope that we can automate this planning process and come up with the ideal urban plans. While remarkable achievements have been obtained, they have exhibited limitations in lacking awareness of: 1) the hierarchical dependencies between functional zones and spatial grids; 2) the peer dependencies among functional zones; and 3) human regulations to ensure the usability of generated configurations. To address these limitations, we develop a novel human-instructed deep hierarchical generative model. We rethink the urban planning generative task from a unique functionality perspective, where we summarize planning requirements into different functionality projections for better urban plan generation. To this end, we develop a three-stage generation process from a target area to zones to grids. The first stage is to label the grids of a target area with latent functionalities to discover functional zones. The second stage is to perceive the planning requirements to form urban functionality projections. We propose a novel module: functionalizer to project the embedding of human instructions and geospatial contexts to the zone-level plan to obtain such projections. Each projection includes the information of land-use portfolios and the structural dependencies across spatial grids in terms of a specific urban function. The third stage is to leverage multi-attentions to model the zone-zone peer dependencies of the functionality projections to generate grid-level land-use configurations. Finally, we present extensive experiments to demonstrate the effectiveness of our framework.
Graph Soft-Contrastive Learning via Neighborhood Ranking
Sep 28, 2022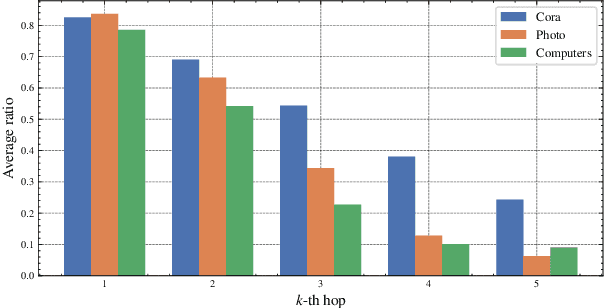
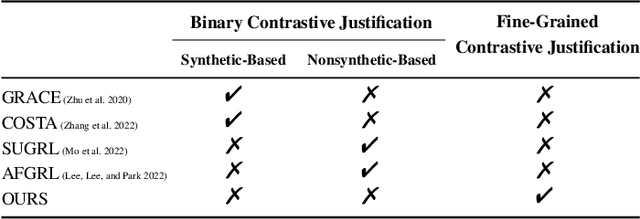
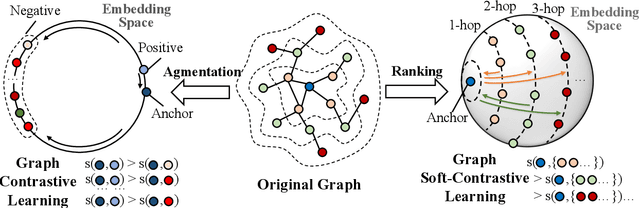
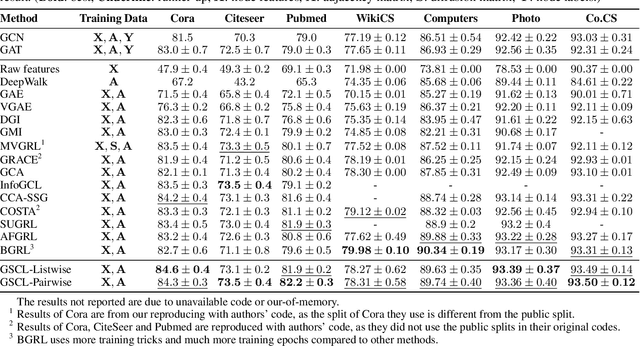
Graph contrastive learning (GCL) has been an emerging solution for graph self-supervised learning. The core principle of GCL is to reduce the distance between samples in the positive view, but increase the distance between samples in the negative view. While achieving promising performances, current GCL methods still suffer from two limitations: (1) uncontrollable validity of augmentation, that graph perturbation may produce invalid views against semantics and feature-topology correspondence of graph data; and (2) unreliable binary contrastive justification, that the positiveness and negativeness of the constructed views are difficult to be determined for non-euclidean graph data. To tackle the above limitations, we propose a new contrastive learning paradigm for graphs, namely Graph Soft-Contrastive Learning (GSCL), that conducts contrastive learning in a finer-granularity via ranking neighborhoods without any augmentations and binary contrastive justification. GSCL is built upon the fundamental assumption of graph proximity that connected neighbors are more similar than far-distant nodes. Specifically, we develop pair-wise and list-wise Gated Ranking infoNCE Loss functions to preserve the relative ranking relationship in the neighborhood. Moreover, as the neighborhood size exponentially expands with more hops considered, we propose neighborhood sampling strategies to improve learning efficiency. The extensive experimental results show that our proposed GSCL can consistently achieve state-of-the-art performances on various public datasets with comparable practical complexity to GCL.
Adversarial Attacks on ASR Systems: An Overview
Aug 03, 2022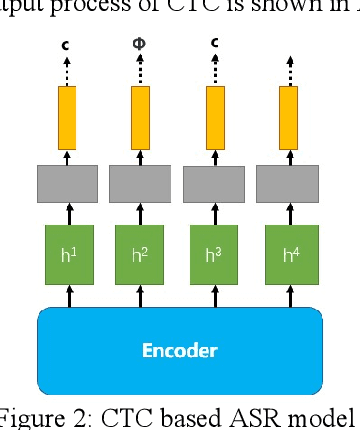
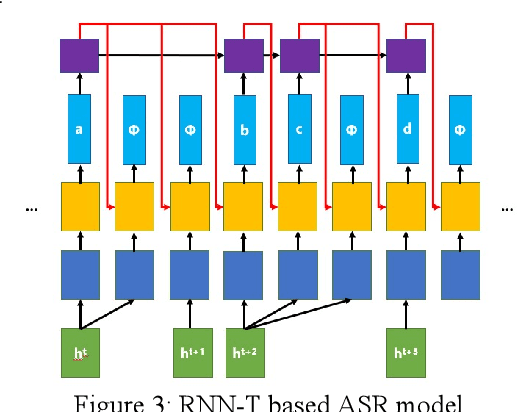
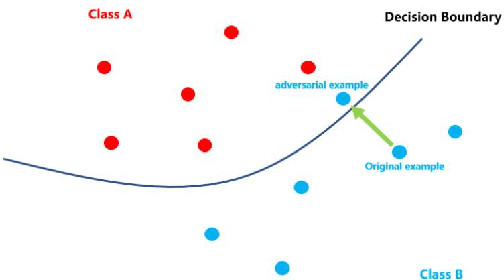
With the development of hardware and algorithms, ASR(Automatic Speech Recognition) systems evolve a lot. As The models get simpler, the difficulty of development and deployment become easier, ASR systems are getting closer to our life. On the one hand, we often use APPs or APIs of ASR to generate subtitles and record meetings. On the other hand, smart speaker and self-driving car rely on ASR systems to control AIoT devices. In past few years, there are a lot of works on adversarial examples attacks against ASR systems. By adding a small perturbation to the waveforms, the recognition results make a big difference. In this paper, we describe the development of ASR system, different assumptions of attacks, and how to evaluate these attacks. Next, we introduce the current works on adversarial examples attacks from two attack assumptions: white-box attack and black-box attack. Different from other surveys, we pay more attention to which layer they perturb waveforms in ASR system, the relationship between these attacks, and their implementation methods. We focus on the effect of their works.