 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLRNet: Cross Layer Refinement Network for Lane Detection
Mar 19, 2022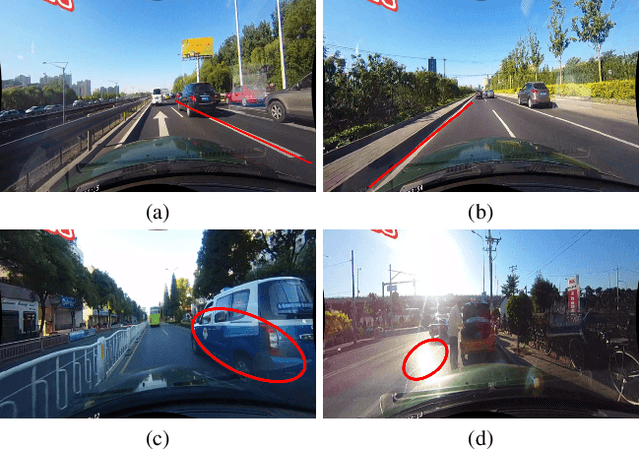
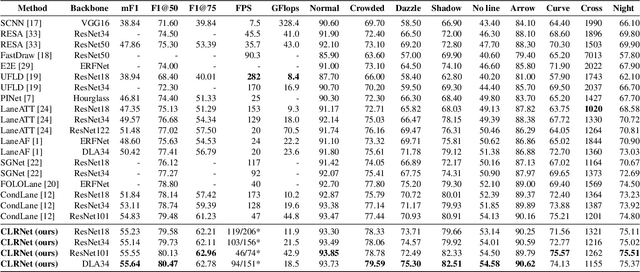
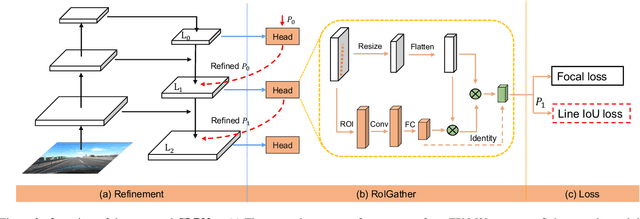
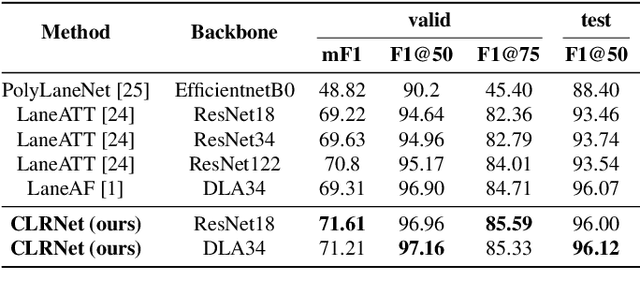
Lane is critical in the vision navigation system of the intelligent vehicle. Naturally, lane is a traffic sign with high-level semantics, whereas it owns the specific local pattern which needs detailed low-level features to localize accurately. Using different feature levels is of great importance for accurate lane detection, but it is still under-explored. In this work, we present Cross Layer Refinement Network (CLRNet) aiming at fully utilizing both high-level and low-level features in lane detection. In particular, it first detects lanes with high-level semantic features then performs refinement based on low-level features. In this way, we can exploit more contextual information to detect lanes while leveraging local detailed lane features to improve localization accuracy. We present ROIGather to gather global context, which further enhances the feature representation of lanes. In addition to our novel network design, we introduce Line IoU loss which regresses the lane line as a whole unit to improve the localization accuracy. Experiments demonstrate that the proposed method greatly outperforms the state-of-the-art lane detection approaches.
Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion
Mar 18, 2022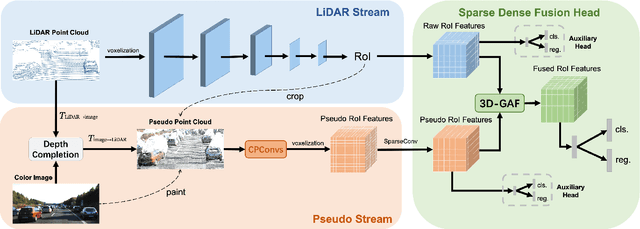
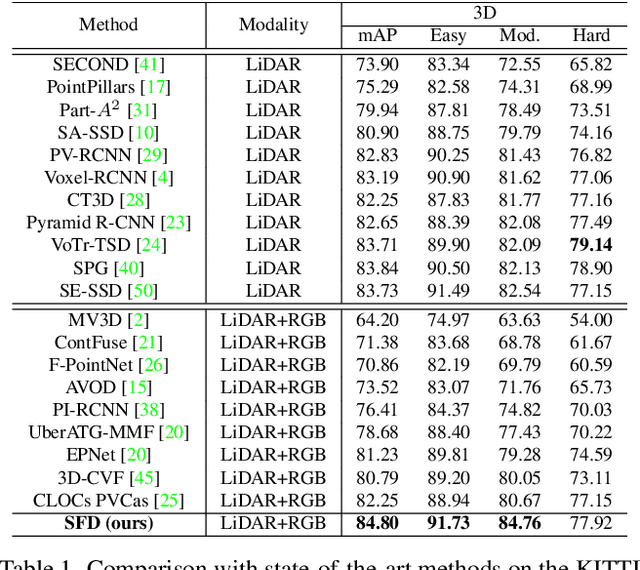
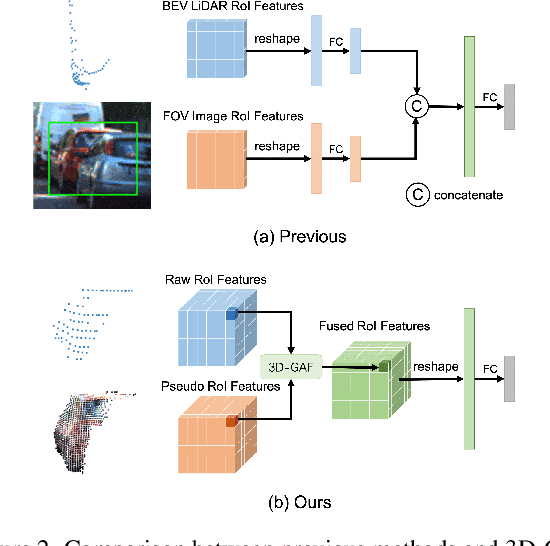
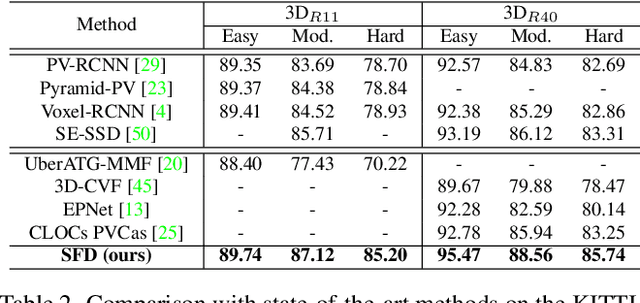
Current LiDAR-only 3D detection methods inevitably suffer from the sparsity of point clouds. Many multi-modal methods are proposed to alleviate this issue, while different representations of images and point clouds make it difficult to fuse them, resulting in suboptimal performance. In this paper, we present a novel multi-modal framework SFD (Sparse Fuse Dense), which utilizes pseudo point clouds generated from depth completion to tackle the issues mentioned above. Different from prior works, we propose a new RoI fusion strategy 3D-GAF (3D Grid-wise Attentive Fusion) to make fuller use of information from different types of point clouds. Specifically, 3D-GAF fuses 3D RoI features from the couple of point clouds in a grid-wise attentive way, which is more fine-grained and more precise. In addition, we propose a SynAugment (Synchronized Augmentation) to enable our multi-modal framework to utilize all data augmentation approaches tailored to LiDAR-only methods. Lastly, we customize an effective and efficient feature extractor CPConv (Color Point Convolution) for pseudo point clouds. It can explore 2D image features and 3D geometric features of pseudo point clouds simultaneously. Our method holds the highest entry on the KITTI car 3D object detection leaderboard, demonstrating the effectiveness of our SFD. Code will be made publicly available.
WeakM3D: Towards Weakly Supervised Monocular 3D Object Detection
Mar 16, 2022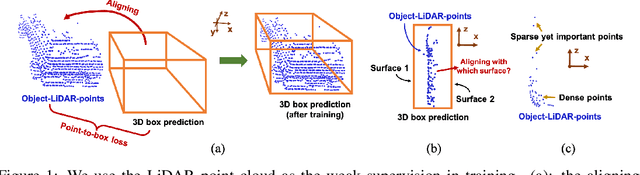
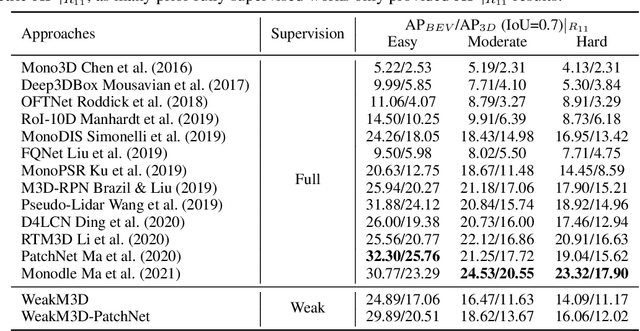
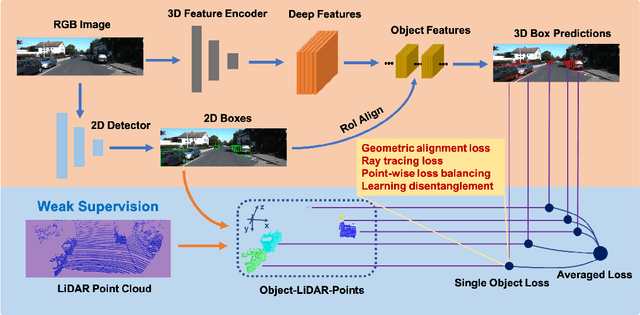
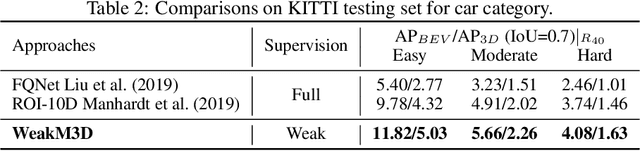
Monocular 3D object detection is one of the most challenging tasks in 3D scene understanding. Due to the ill-posed nature of monocular imagery, existing monocular 3D detection methods highly rely on training with the manually annotated 3D box labels on the LiDAR point clouds. This annotation process is very laborious and expensive. To dispense with the reliance on 3D box labels, in this paper we explore the weakly supervised monocular 3D detection. Specifically, we first detect 2D boxes on the image. Then, we adopt the generated 2D boxes to select corresponding RoI LiDAR points as the weak supervision. Eventually, we adopt a network to predict 3D boxes which can tightly align with associated RoI LiDAR points. This network is learned by minimizing our newly-proposed 3D alignment loss between the 3D box estimates and the corresponding RoI LiDAR points. We will illustrate the potential challenges of the above learning problem and resolve these challenges by introducing several effective designs into our method. Codes will be available at https://github.com/SPengLiang/WeakM3D.
A Survey on Retrieval-Augmented Text Generation
Feb 13, 2022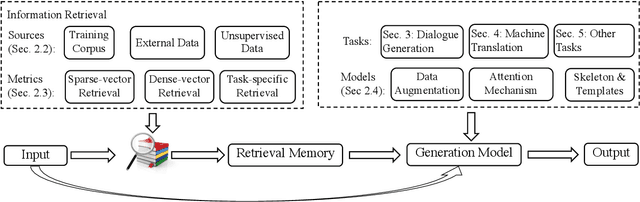
Recently, retrieval-augmented text generation attracted increasing attention of the computational linguistics community. Compared with conventional generation models, retrieval-augmented text generation has remarkable advantages and particularly has achieved state-of-the-art performance in many NLP tasks. This paper aims to conduct a survey about retrieval-augmented text generation. It firstly highlights the generic paradigm of retrieval-augmented generation, and then it reviews notable approaches according to different tasks including dialogue response generation, machine translation, and other generation tasks. Finally, it points out some important directions on top of recent methods to facilitate future research.
Measuring and Reducing Model Update Regression in Structured Prediction for NLP
Feb 07, 2022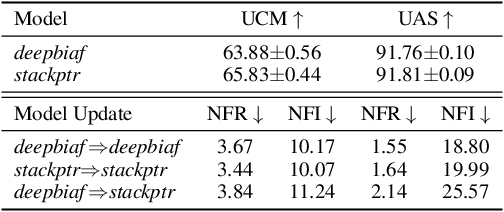

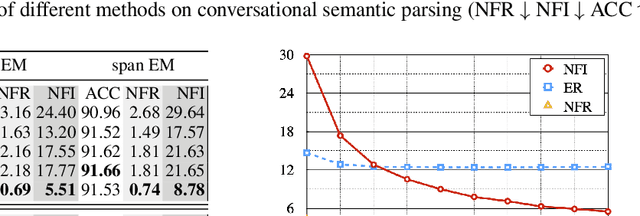
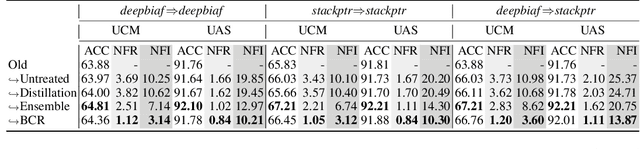
Recent advance in deep learning has led to rapid adoption of machine learning based NLP models in a wide range of applications. Despite the continuous gain in accuracy, backward compatibility is also an important aspect for industrial applications, yet it received little research attention. Backward compatibility requires that the new model does not regress on cases that were correctly handled by its predecessor. This work studies model update regression in structured prediction tasks. We choose syntactic dependency parsing and conversational semantic parsing as representative examples of structured prediction tasks in NLP. First, we measure and analyze model update regression in different model update settings. Next, we explore and benchmark existing techniques for reducing model update regression including model ensemble and knowledge distillation. We further propose a simple and effective method, Backward-Congruent Re-ranking (BCR), by taking into account the characteristics of structured output. Experiments show that BCR can better mitigate model update regression than model ensemble and knowledge distillation approaches.
TopNet: Learning from Neural Topic Model to Generate Long Stories
Dec 14, 2021
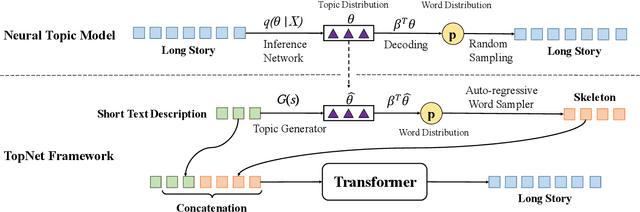

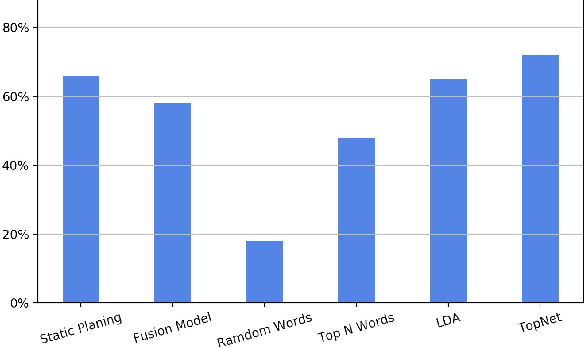
Long story generation (LSG) is one of the coveted goals in natural language processing. Different from most text generation tasks, LSG requires to output a long story of rich content based on a much shorter text input, and often suffers from information sparsity. In this paper, we propose \emph{TopNet} to alleviate this problem, by leveraging the recent advances in neural topic modeling to obtain high-quality skeleton words to complement the short input. In particular, instead of directly generating a story, we first learn to map the short text input to a low-dimensional topic distribution (which is pre-assigned by a topic model). Based on this latent topic distribution, we can use the reconstruction decoder of the topic model to sample a sequence of inter-related words as a skeleton for the story. Experiments on two benchmark datasets show that our proposed framework is highly effective in skeleton word selection and significantly outperforms the state-of-the-art models in both automatic evaluation and human evaluation.
* KDD2021, 9 pages
Multilingual AMR Parsing with Noisy Knowledge Distillation
Oct 14, 2021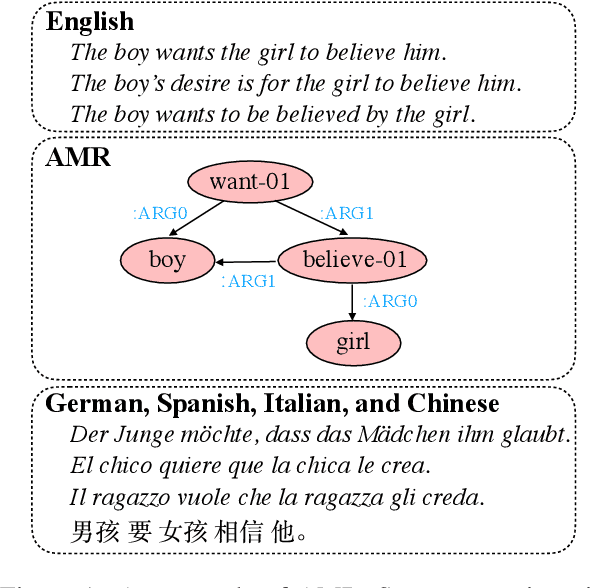
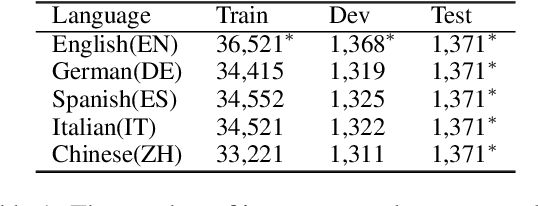
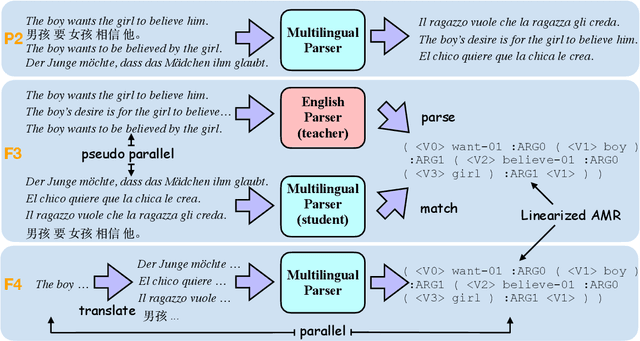
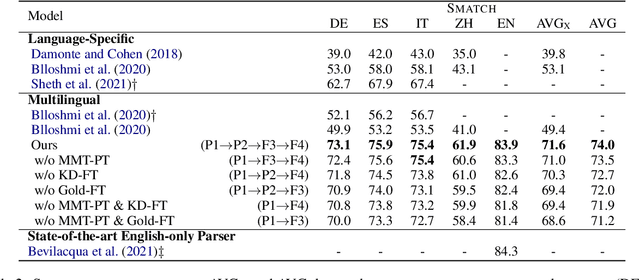
We study multilingual AMR parsing from the perspective of knowledge distillation, where the aim is to learn and improve a multilingual AMR parser by using an existing English parser as its teacher. We constrain our exploration in a strict multilingual setting: there is but one model to parse all different languages including English. We identify that noisy input and precise output are the key to successful distillation. Together with extensive pre-training, we obtain an AMR parser whose performances surpass all previously published results on four different foreign languages, including German, Spanish, Italian, and Chinese, by large margins (up to 18.8 \textsc{Smatch} points on Chinese and on average 11.3 \textsc{Smatch} points). Our parser also achieves comparable performance on English to the latest state-of-the-art English-only parser.
Exploring Dense Retrieval for Dialogue Response Selection
Oct 13, 2021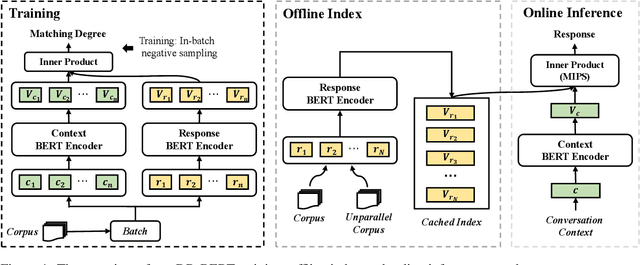

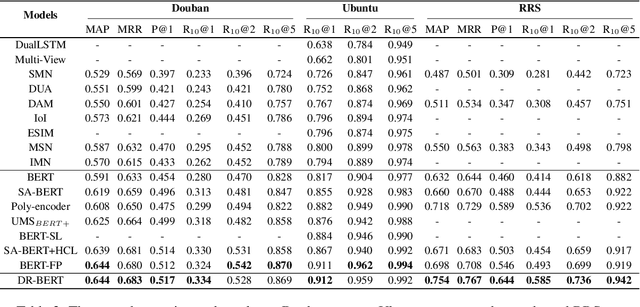
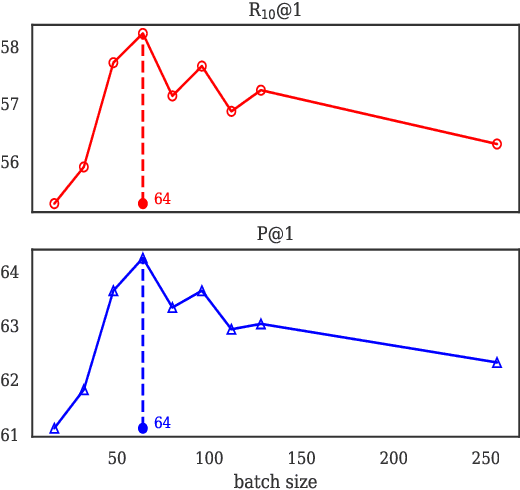
Recent research on dialogue response selection has been mainly focused on selecting a proper response from a pre-defined small set of candidates using sophisticated neural models. Due to their heavy computational overhead, they are unable to select responses from a large candidate pool. In this study, we present a solution to directly select proper responses from a large corpus or even a nonparallel corpus that only consists of unpaired sentences, using a dense retrieval model. We extensively test our proposed approach under two experiment settings: (i) re-rank experiment that aims to rank a small set of pre-defined candidates; (ii) full-rank experiment where the target is to directly select proper responses from a full candidate pool that may contain millions of candidates. For re-rank setting, the superiority is quite surprising given its simplicity. For full-rank setting, we can emphasize that we are the first to do such evaluation. Moreover, human evaluation results show that increasing the size of nonparallel corpus leads to further improvement of our model performance\footnote{All our source codes, models and other related resources are publically available at \url{https://github.com/gmftbyGMFTBY/SimpleReDial-v1}.
Multi-Task Pre-Training for Plug-and-Play Task-Oriented Dialogue System
Sep 29, 2021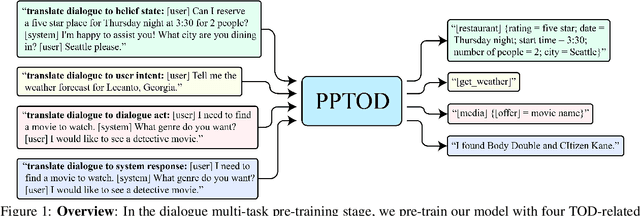
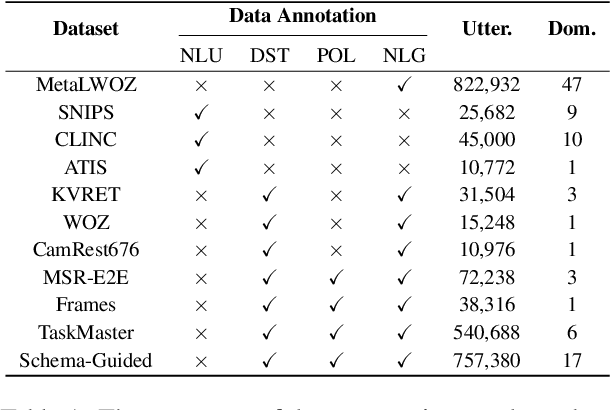
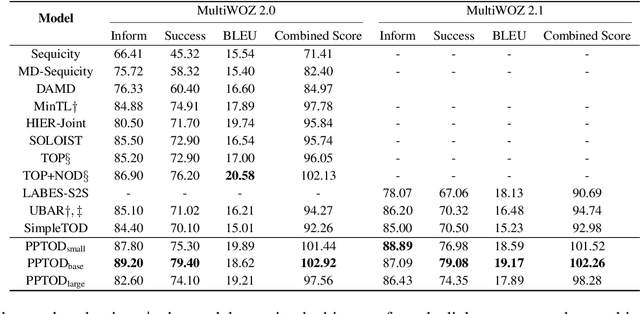
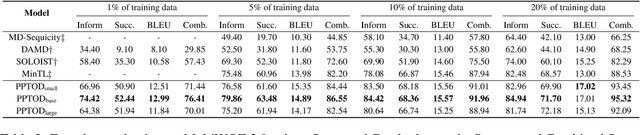
Pre-trained language models have been recently shown to benefit task-oriented dialogue (TOD) systems. Despite their success, existing methods often formulate this task as a cascaded generation problem which can lead to error accumulation across different sub-tasks and greater data annotation overhead. In this study, we present PPTOD, a unified plug-and-play model for task-oriented dialogue. In addition, we introduce a new dialogue multi-task pre-training strategy that allows the model to learn the primary TOD task completion skills from heterogeneous dialog corpora. We extensively test our model on three benchmark TOD tasks, including end-to-end dialogue modelling, dialogue state tracking, and intent classification. Experimental results show that PPTOD achieves new state of the art on all evaluated tasks in both high-resource and low-resource scenarios. Furthermore, comparisons against previous SOTA methods show that the responses generated by PPTOD are more factually correct and semantically coherent as judged by human annotators.
Exploiting Reasoning Chains for Multi-hop Science Question Answering
Sep 07, 2021
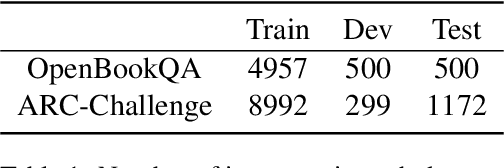
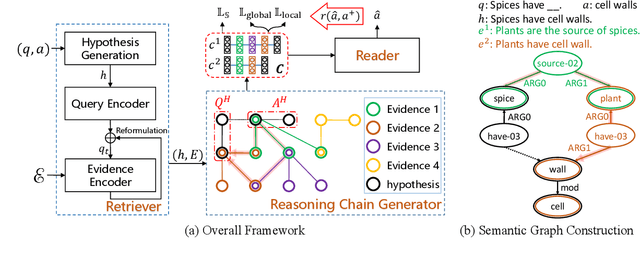
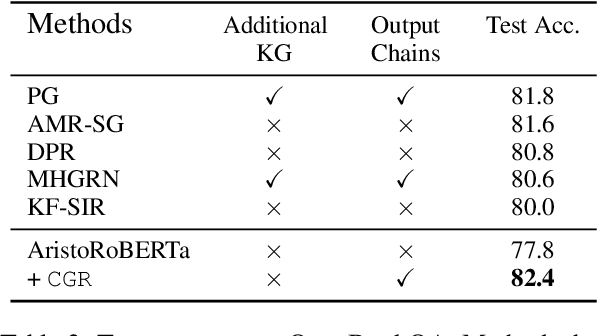
We propose a novel Chain Guided Retriever-reader ({\tt CGR}) framework to model the reasoning chain for multi-hop Science Question Answering. Our framework is capable of performing explainable reasoning without the need of any corpus-specific annotations, such as the ground-truth reasoning chain, or human-annotated entity mentions. Specifically, we first generate reasoning chains from a semantic graph constructed by Abstract Meaning Representation of retrieved evidence facts. A \textit{Chain-aware loss}, concerning both local and global chain information, is also designed to enable the generated chains to serve as distant supervision signals for training the retriever, where reinforcement learning is also adopted to maximize the utility of the reasoning chains. Our framework allows the retriever to capture step-by-step clues of the entire reasoning process, which is not only shown to be effective on two challenging multi-hop Science QA tasks, namely OpenBookQA and ARC-Challenge, but also favors explainability.