 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Person Images with Appearance-aware Pose Stylizer
Jul 17, 2020

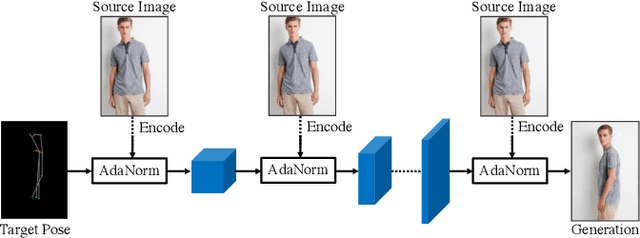
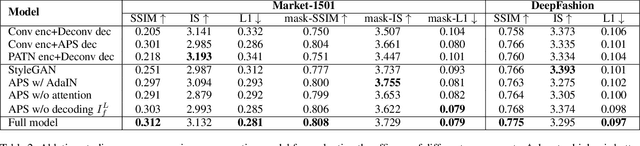
Generation of high-quality person images is challenging, due to the sophisticated entanglements among image factors, e.g., appearance, pose, foreground, background, local details, global structures, etc. In this paper, we present a novel end-to-end framework to generate realistic person images based on given person poses and appearances. The core of our framework is a novel generator called Appearance-aware Pose Stylizer (APS) which generates human images by coupling the target pose with the conditioned person appearance progressively. The framework is highly flexible and controllable by effectively decoupling various complex person image factors in the encoding phase, followed by re-coupling them in the decoding phase. In addition, we present a new normalization method named adaptive patch normalization, which enables region-specific normalization and shows a good performance when adopted in person image generation model. Experiments on two benchmark datasets show that our method is capable of generating visually appealing and realistic-looking results using arbitrary image and pose inputs.
Representation Transfer by Optimal Transport
Jul 13, 2020
Deep learning currently provides the best representations of complex objects for a wide variety of tasks. However, learning these representations is an expensive process that requires very large training samples and significant computing resources. Thankfully, sharing these representations is a common practice, enabling to solve new tasks with relatively little training data and few computing resources; the transfer of representations is nowadays an essential ingredient in numerous real-world applications of deep learning. Transferring representations commonly relies on the parameterized form of the features making up the representation, as encoded by the computational graph of these features. In this paper, we propose to use a novel non-parametric metric between representations. It is based on a functional view of features, and takes into account certain invariances of representations, such as the permutation of their features, by relying on optimal transport. This distance is used as a regularization term promoting similarity between two representations. We show the relevance of this approach in two representation transfer settings, where the representation of a trained reference model is transferred to another one, for solving a new related task (inductive transfer learning), or for distilling knowledge to a simpler model (model compression).
RIFLE: Backpropagation in Depth for Deep Transfer Learning through Re-Initializing the Fully-connected LayEr
Jul 07, 2020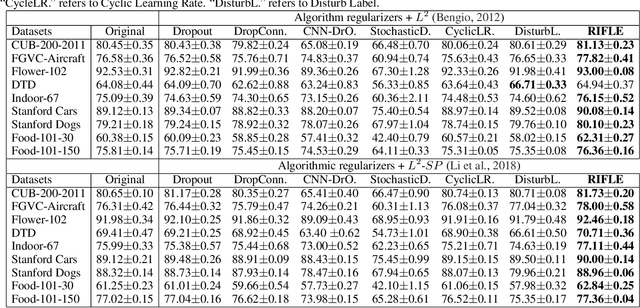
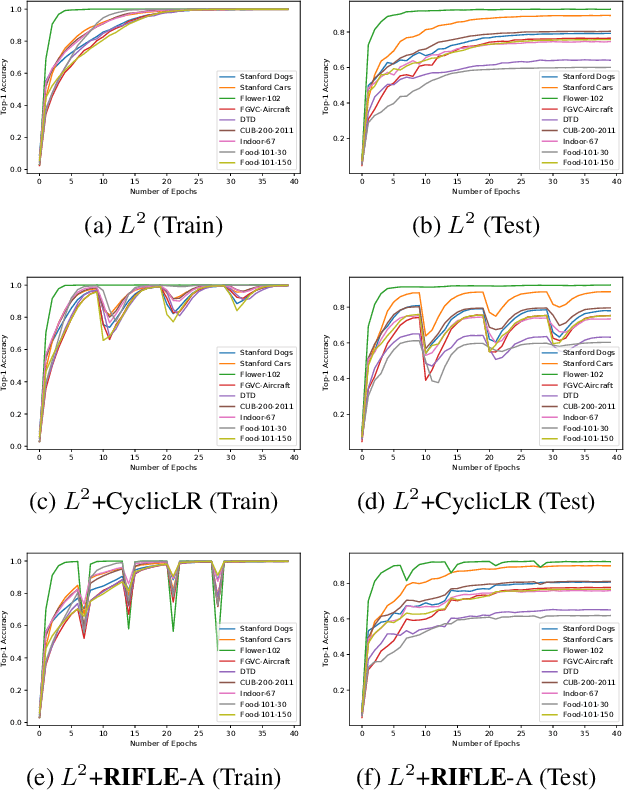
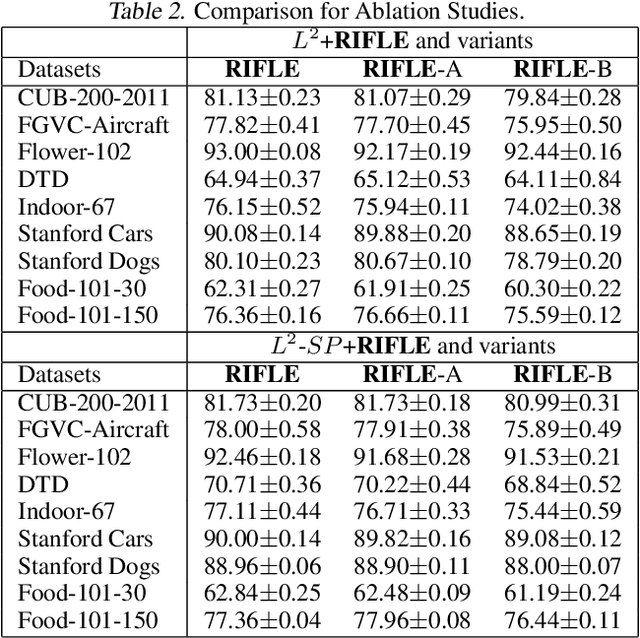
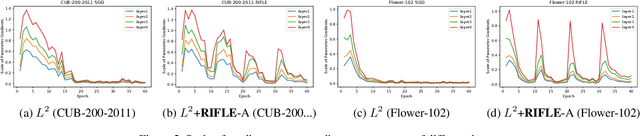
Fine-tuning the deep convolution neural network(CNN) using a pre-trained model helps transfer knowledge learned from larger datasets to the target task. While the accuracy could be largely improved even when the training dataset is small, the transfer learning outcome is usually constrained by the pre-trained model with close CNN weights (Liu et al., 2019), as the backpropagation here brings smaller updates to deeper CNN layers. In this work, we propose RIFLE - a simple yet effective strategy that deepens backpropagation in transfer learning settings, through periodically Re-Initializing the Fully-connected LayEr with random scratch during the fine-tuning procedure. RIFLE brings meaningful updates to the weights of deep CNN layers and improves low-level feature learning, while the effects of randomization can be easily converged throughout the overall learning procedure. The experiments show that the use of RIFLE significantly improves deep transfer learning accuracy on a wide range of datasets, out-performing known tricks for the similar purpose, such as Dropout, DropConnect, StochasticDepth, Disturb Label and Cyclic Learning Rate, under the same settings with 0.5% -2% higher testing accuracy. Empirical cases and ablation studies further indicate RIFLE brings meaningful updates to deep CNN layers with accuracy improved.
Cross-Task Transfer for Multimodal Aerial Scene Recognition
May 18, 2020
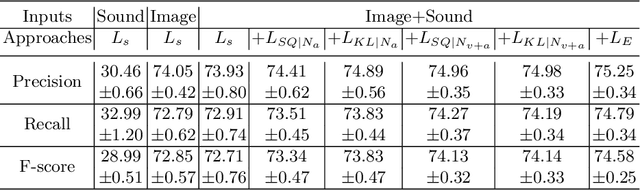
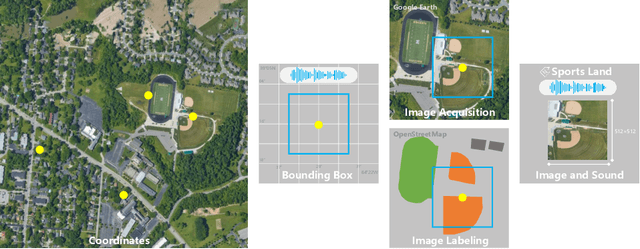
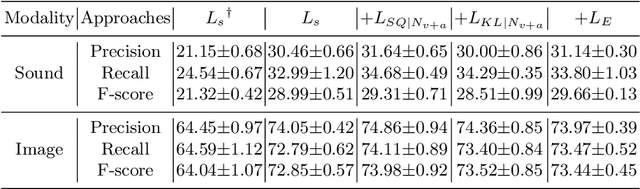
Aerial scene recognition is a fundamental task in remote sensing and has recently received increased interest. While the visual information from overhead images with powerful models and efficient algorithms yields good performance on scene recognition, additional information is always a bonus, for example, the corresponding audio information. In this paper, for improving the performance on the aerial scene recognition, we explore a novel audiovisual aerial scene recognition task using both images and sounds as input. Based on an observation that some specific sound events are more likely to be heard at a given geographic location, we propose to exploit the knowledge from the sound events to improve the performance on the aerial scene recognition. For this purpose, we have constructed a new dataset named AuDio Visual Aerial sceNe reCognition datasEt (ADVANCE). With the help of this dataset, we evaluate three proposed approaches for transferring the sound event knowledge to the aerial scene recognition task in a multimodal learning framework, and show the benefit of exploiting the audio information for the aerial scene recognition. The source code is publicly available for reproducibility purposes.https://github.com/DTaoo/Multimodal-Aerial-Scene-Recognition.
Ambient Sound Helps: Audiovisual Crowd Counting in Extreme Conditions
May 16, 2020
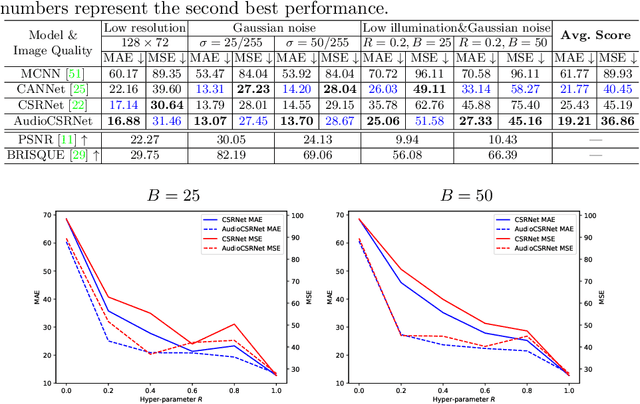

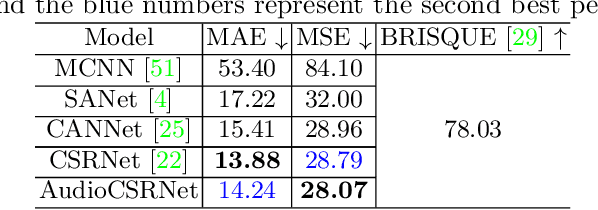
Visual crowd counting has been recently studied as a way to enable people counting in crowd scenes from images. Albeit successful, vision-based crowd counting approaches could fail to capture informative features in extreme conditions, e.g., imaging at night and occlusion. In this work, we introduce a novel task of audiovisual crowd counting, in which visual and auditory information are integrated for counting purposes. We collect a large-scale benchmark, named auDiovISual Crowd cOunting (DISCO) dataset, consisting of 1,935 images and the corresponding audio clips, and 170,270 annotated instances. In order to fuse the two modalities, we make use of a linear feature-wise fusion module that carries out an affine transformation on visual and auditory features. Finally, we conduct extensive experiments using the proposed dataset and approach. Experimental results show that introducing auditory information can benefit crowd counting under different illumination, noise, and occlusion conditions. The dataset and code will be released. Code and data have been made available
COLAM: Co-Learning of Deep Neural Networks and Soft Labels via Alternating Minimization
Apr 26, 2020
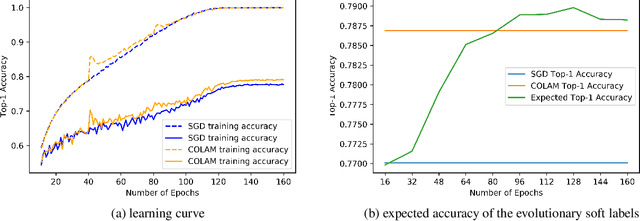

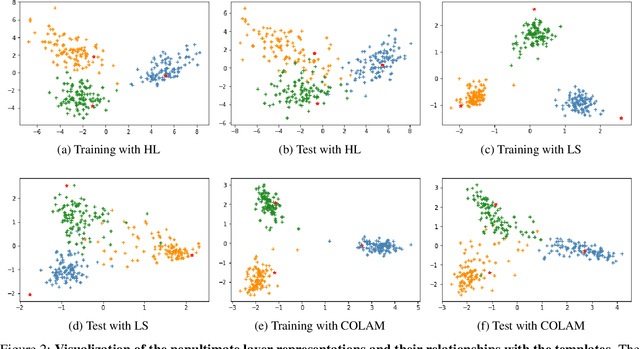
Softening labels of training datasets with respect to data representations has been frequently used to improve the training of deep neural networks (DNNs). While such a practice has been studied as a way to leverage privileged information about the distribution of the data, a well-trained learner with soft classification outputs should be first obtained as a prior to generate such privileged information. To solve such chicken-egg problem, we propose COLAM framework that Co-Learns DNNs and soft labels through Alternating Minimization of two objectives - (a) the training loss subject to soft labels and (b) the objective to learn improved soft labels - in one end-to-end training procedure. We performed extensive experiments to compare our proposed method with a series of baselines. The experiment results show that COLAM achieves improved performance on many tasks with better testing classification accuracy. We also provide both qualitative and quantitative analyses that explain why COLAM works well.
Ontology-based Interpretable Machine Learning for Textual Data
Apr 01, 2020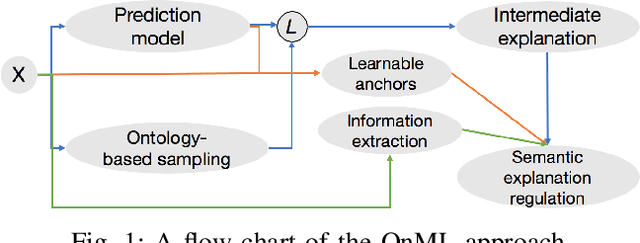

In this paper, we introduce a novel interpreting framework that learns an interpretable model based on an ontology-based sampling technique to explain agnostic prediction models. Different from existing approaches, our algorithm considers contextual correlation among words, described in domain knowledge ontologies, to generate semantic explanations. To narrow down the search space for explanations, which is a major problem of long and complicated text data, we design a learnable anchor algorithm, to better extract explanations locally. A set of regulations is further introduced, regarding combining learned interpretable representations with anchors to generate comprehensible semantic explanations. An extensive experiment conducted on two real-world datasets shows that our approach generates more precise and insightful explanations compared with baseline approaches.
Parameter-Free Style Projection for Arbitrary Style Transfer
Mar 17, 2020

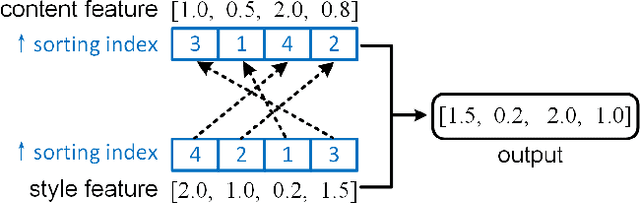
Arbitrary image style transfer is a challenging task which aims to stylize a content image conditioned on an arbitrary style image. In this task the content-style feature transformation is a critical component for a proper fusion of features. Existing feature transformation algorithms often suffer from unstable learning, loss of content and style details, and non-natural stroke patterns. To mitigate these issues, this paper proposes a parameter-free algorithm, Style Projection, for fast yet effective content-style transformation. To leverage the proposed Style Projection~component, this paper further presents a real-time feed-forward model for arbitrary style transfer, including a regularization for matching the content semantics between inputs and outputs. Extensive experiments have demonstrated the effectiveness and efficiency of the proposed method in terms of qualitative analysis, quantitative evaluation, and user study.
Label-guided Learning for Text Classification
Feb 25, 2020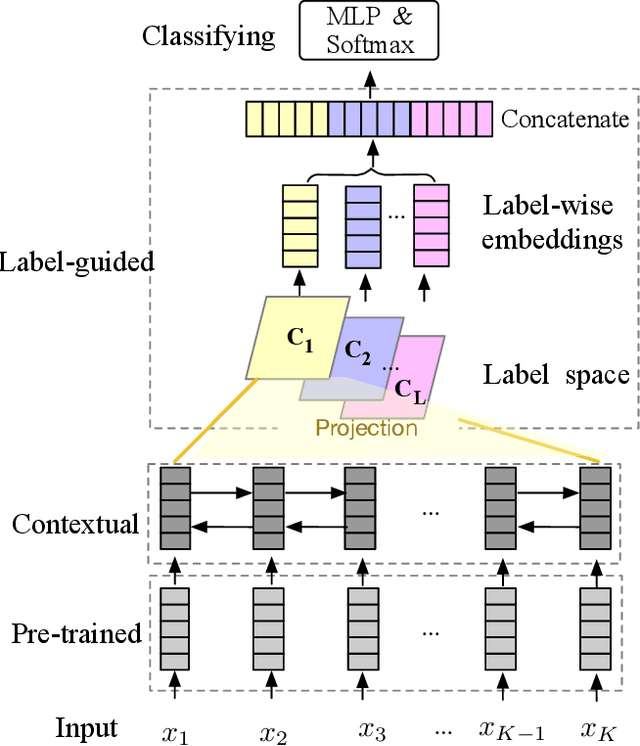
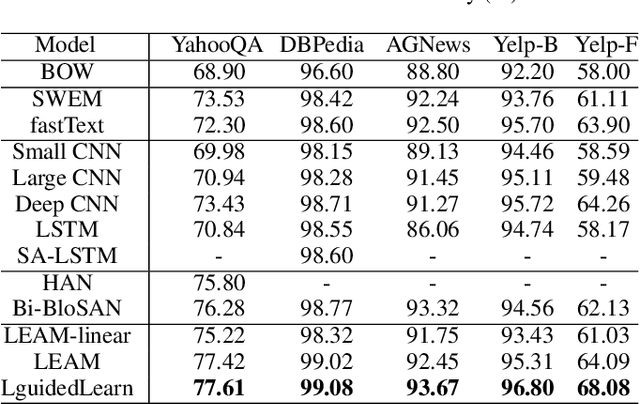
Text classification is one of the most important and fundamental tasks in natural language processing. Performance of this task mainly dependents on text representation learning. Currently, most existing learning frameworks mainly focus on encoding local contextual information between words. These methods always neglect to exploit global clues, such as label information, for encoding text information. In this study, we propose a label-guided learning framework LguidedLearn for text representation and classification. Our method is novel but simple that we only insert a label-guided encoding layer into the commonly used text representation learning schemas. That label-guided layer performs label-based attentive encoding to map the universal text embedding (encoded by a contextual information learner) into different label spaces, resulting in label-wise embeddings. In our proposed framework, the label-guided layer can be easily and directly applied with a contextual encoding method to perform jointly learning. Text information is encoded based on both the local contextual information and the global label clues. Therefore, the obtained text embeddings are more robust and discriminative for text classification. Extensive experiments are conducted on benchmark datasets to illustrate the effectiveness of our proposed method.
Curriculum Audiovisual Learning
Jan 26, 2020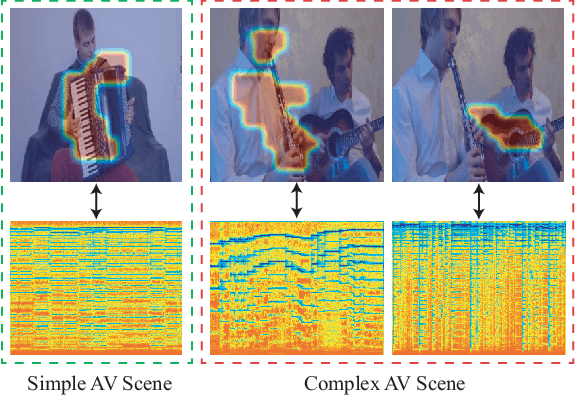

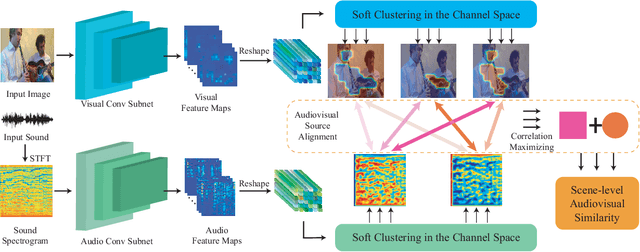
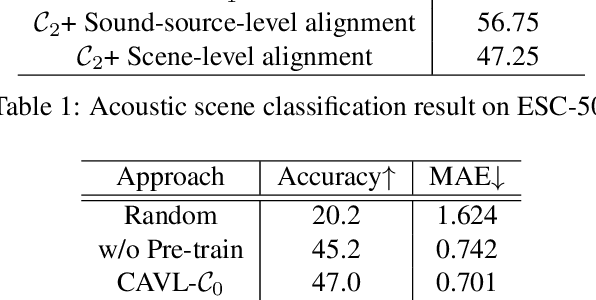
Associating sound and its producer in complex audiovisual scene is a challenging task, especially when we are lack of annotated training data. In this paper, we present a flexible audiovisual model that introduces a soft-clustering module as the audio and visual content detector, and regards the pervasive property of audiovisual concurrency as the latent supervision for inferring the correlation among detected contents. To ease the difficulty of audiovisual learning, we propose a novel curriculum learning strategy that trains the model from simple to complex scene. We show that such ordered learning procedure rewards the model the merits of easy training and fast convergence. Meanwhile, our audiovisual model can also provide effective unimodal representation and cross-modal alignment performance. We further deploy the well-trained model into practical audiovisual sound localization and separation task. We show that our localization model significantly outperforms existing methods, based on which we show comparable performance in sound separation without referring external visual supervision. Our video demo can be found at https://youtu.be/kuClfGG0cFU.