 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Drifted: the System or the Judge? Anytime-Valid Attribution in LLM Evaluation Pipelines
Jun 13, 2026Continuous evaluation of LLM products relies on a strong LLM judge treated as ground truth: a cheap monitor scores every interaction and a team is paged when the score drifts down. But the judge is itself a model behind an API, and a silent version bump or scoring-prompt update changes how it scores -- so every drift alarm is ambiguous between a worse product and a changed judge. We resolve the ambiguity with a fixed, human-labeled anchor set that the current judge re-scores at a steady interleave, a second betting e-process on the judge-versus-human gap, and a guard-window rule returning a verdict in {none, system, judge}. We prove anytime-validity, one-way identification (only the judge can move the anchors), an attribution race whose design law is that the anchors must out-run the main process they guard, and process orthogonality. On two real judge changes, a silent version bump is detected as judge drift in 60/60 runs with zero judge-to-system misattribution, and a contaminating strict-prompt change is correctly attributed on 110 of 120 runs at guard width 300 -- while the industry-default rolling z-test false-alarms on 75% of drift-free streams. Every experiment replicates on a second domain (TL;DR summarization) with nothing re-tuned, and where the domains differ the differences are the ones the race predicts: the strict-prompt change shifts scores harder there, so the anchors fire faster and attribution becomes perfect (240/240). The monitor runs at approximately 0.64 of the cost of strong-judging every item, or 0.21 in a cheaper-but-deafer regime.
FEMOT: Multi-Object Tracking using Frame and Event Cameras
Jun 12, 2026Conventional RGB cameras have been widely used in multi-object tracking due to their ability to capture rich appearance and semantic information. However, their performance is often degraded under complex real-world challenges, such as motion blur, low illumination, and overexposure. Bio-inspired event cameras offer high temporal resolution and high dynamic range, providing complementary cues under extreme scenarios. Nevertheless, RGB-event multi-object tracking remains underexplored due to the lack of large-scale and well-annotated datasets. To address this issue, we propose FEMOT, a large-scale RGB-event multi-object tracking dataset that covers diverse real-world scenarios and 14 challenging attributes. With both RGB and event data as well as high-quality annotations, FEMOT provides a reliable platform for systematically evaluating RGB-event multi-object tracking methods. Based on FEMOT, we retrain and evaluate over ten strong trackers, thereby establishing a comprehensive benchmark for future research. Furthermore, we propose FEMOTR, a multimodal tracking framework that decouples RGB and event features and fuses them in the frequency domain, thereby effectively exploiting their complementary characteristics for robust object localization and identity association. Extensive experiments on FEMOT and DSEC-MOT datasets demonstrate the effectiveness of the proposed method. The source code and benchmark dataset have been released on https://github.com/Event-AHU/FEMOT.
OntoKG: Ontology-Oriented Knowledge Graph Construction with Intrinsic-Relational Routing
Apr 03, 2026Organizing a large-scale knowledge graph into a typed property graph requires structural decisions -- which entities become nodes, which properties become edges, and what schema governs these choices. Existing approaches embed these decisions in pipeline code or extract relations ad hoc, producing schemas that are tightly coupled to their construction process and difficult to reuse for downstream ontology-level tasks. We present an ontology-oriented approach in which the schema is designed from the outset for ontology analysis, entity disambiguation, domain customization, and LLM-guided extraction -- not merely as a byproduct of graph building. The core mechanism is intrinsic-relational routing, which classifies every property as either intrinsic or relational and routes it to the corresponding schema module. This routing produces a declarative schema that is portable across storage backends and independently reusable. We instantiate the approach on the January 2026 Wikidata dump. A rule-based cleaning stage identifies a 34.6M-entity core set from the full dump, followed by iterative intrinsic-relational routing that assigns each property to one of 94 modules organized into 8 categories. With tool-augmented LLM support and human review, the schema reaches 93.3% category coverage and 98.0% module assignment among classified entities. Exporting this schema yields a property graph with 34.0M nodes and 61.2M edges across 38 relationship types. We validate the ontology-oriented claim through five applications that consume the schema independently of the construction pipeline: ontology structure analysis, benchmark annotation auditing, entity disambiguation, domain customization, and LLM-guided extraction.
Greedy Is a Strong Default: Agents as Iterative Optimizers
Mar 28, 2026Classical optimization algorithms--hill climbing, simulated annealing, population-based methods--generate candidate solutions via random perturbations. We replace the random proposal generator with an LLM agent that reasons about evaluation diagnostics to propose informed candidates, and ask: does the classical optimization machinery still help when the proposer is no longer random? We evaluate on four tasks spanning discrete, mixed, and continuous search spaces (all replicated across 3 independent runs): rule-based classification on Breast Cancer (test accuracy 86.0% to 96.5%), mixed hyperparameter optimization for MobileNetV3-Small on STL-10 (84.5% to 85.8%, zero catastrophic failures vs. 60% for random search), LoRA fine-tuning of Qwen2.5-0.5B on SST-2 (89.5% to 92.7%, matching Optuna TPE with 2x efficiency), and XGBoost on Adult Census (AUC 0.9297 to 0.9317, tying CMA-ES with 3x fewer evaluations). Empirically, on these tasks: a cross-task ablation shows that simulated annealing, parallel investigators, and even a second LLM model (OpenAI Codex) provide no benefit over greedy hill climbing while requiring 2-3x more evaluations. In our setting, the LLM's learned prior appears strong enough that acceptance-rule sophistication has limited impact--round 1 alone delivers the majority of improvement, and variants converge to similar configurations across strategies. The practical implication is surprising simplicity: greedy hill climbing with early stopping is a strong default. Beyond accuracy, the framework produces human-interpretable artifacts--the discovered cancer classification rules independently recapitulate established cytopathology principles.
EPOCH: An Agentic Protocol for Multi-Round System Optimization
Mar 10, 2026Autonomous agents are increasingly used to improve prompts, code, and machine learning systems through iterative execution and feedback. Yet existing approaches are usually designed as task-specific optimization loops rather than as a unified protocol for establishing baselines and managing tracked multi-round self-improvement. We introduce EPOCH, an engineering protocol for multi-round system optimization in heterogeneous environments. EPOCH organizes optimization into two phases: baseline construction and iterative self-improvement. It further structures each round through role-constrained stages that separate planning, implementation, and evaluation, and standardizes execution through canonical command interfaces and round-level tracking. This design enables coordinated optimization across prompts, model configurations, code, and rule-based components while preserving stability, reproducibility, traceability, and integrity of evaluation. Empirical studies in various tasks illustrate the practicality of EPOCH for production-oriented autonomous improvement workflows.
Skill-LLM: Repurposing General-Purpose LLMs for Skill Extraction
Oct 15, 2024



Accurate skill extraction from job descriptions is crucial in the hiring process but remains challenging. Named Entity Recognition (NER) is a common approach used to address this issue. With the demonstrated success of large language models (LLMs) in various NLP tasks, including NER, we propose fine-tuning a specialized Skill-LLM and a light weight model to improve the precision and quality of skill extraction. In our study, we evaluated the fine-tuned Skill-LLM and the light weight model using a benchmark dataset and compared its performance against state-of-the-art (SOTA) methods. Our results show that this approach outperforms existing SOTA techniques.
Darwin3: A large-scale neuromorphic chip with a Novel ISA and On-Chip Learning
Dec 29, 2023



Spiking Neural Networks (SNNs) are gaining increasing attention for their biological plausibility and potential for improved computational efficiency. To match the high spatial-temporal dynamics in SNNs, neuromorphic chips are highly desired to execute SNNs in hardware-based neuron and synapse circuits directly. This paper presents a large-scale neuromorphic chip named Darwin3 with a novel instruction set architecture(ISA), which comprises 10 primary instructions and a few extended instructions. It supports flexible neuron model programming and local learning rule designs. The Darwin3 chip architecture is designed in a mesh of computing nodes with an innovative routing algorithm. We used a compression mechanism to represent synaptic connections, significantly reducing memory usage. The Darwin3 chip supports up to 2.35 million neurons, making it the largest of its kind in neuron scale. The experimental results showed that code density was improved up to 28.3x in Darwin3, and neuron core fan-in and fan-out were improved up to 4096x and 3072x by connection compression compared to the physical memory depth. Our Darwin3 chip also provided memory saving between 6.8X and 200.8X when mapping convolutional spiking neural networks (CSNN) onto the chip, demonstrating state-of-the-art performance in accuracy and latency compared to other neuromorphic chips.
Dissecting Ethereum Blockchain Analytics: What We Learn from Topology and Geometry of Ethereum Graph
Dec 20, 2019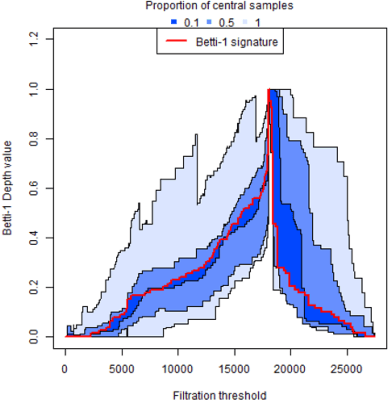
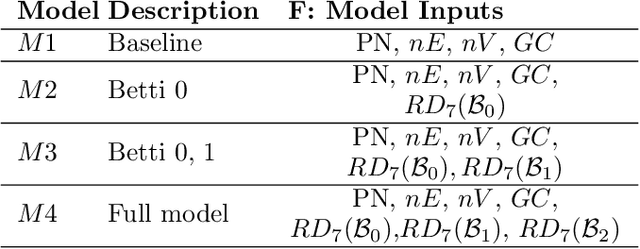
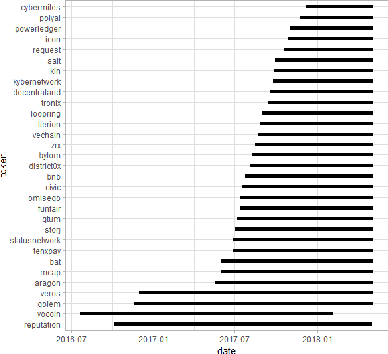
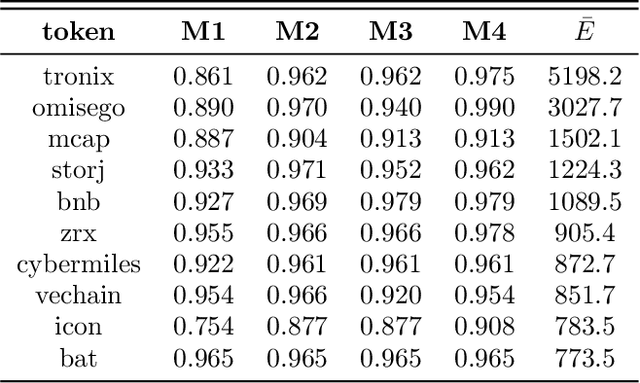
Blockchain technology and, in particular, blockchain-based cryptocurrencies offer us information that has never been seen before in the financial world. In contrast to fiat currencies, all transactions of crypto-currencies and crypto-tokens are permanently recorded on distributed ledgers and are publicly available. As a result, this allows us to construct a transaction graph and to assess not only its organization but to glean relationships between transaction graph properties and crypto price dynamics. The ultimate goal of this paper is to facilitate our understanding on horizons and limitations of what can be learned on crypto-tokens from local topology and geometry of the Ethereum transaction network whose even global network properties remain scarcely explored. By introducing novel tools based on topological data analysis and functional data depth into Blockchain Data Analytics, we show that Ethereum network (one of the most popular blockchains for creating new crypto-tokens) can provide critical insights on price strikes of crypto-tokens that are otherwise largely inaccessible with conventional data sources and traditional analytic methods.
Efficiently Searching for Frustrated Cycles in MAP Inference
Oct 16, 2012
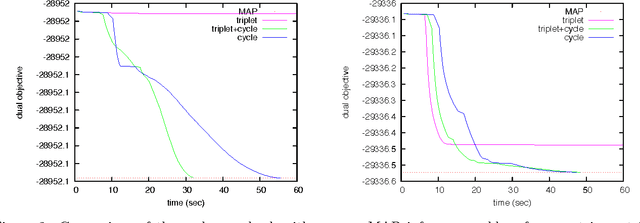
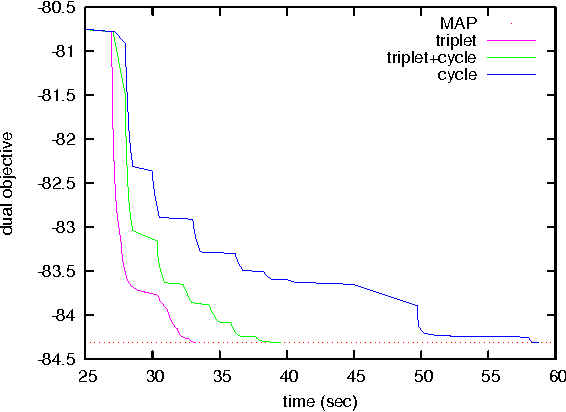
Dual decomposition provides a tractable framework for designing algorithms for finding the most probable (MAP) configuration in graphical models. However, for many real-world inference problems, the typical decomposition has a large integrality gap, due to frustrated cycles. One way to tighten the relaxation is to introduce additional constraints that explicitly enforce cycle consistency. Earlier work showed that cluster-pursuit algorithms, which iteratively introduce cycle and other higherorder consistency constraints, allows one to exactly solve many hard inference problems. However, these algorithms explicitly enumerate a candidate set of clusters, limiting them to triplets or other short cycles. We solve the search problem for cycle constraints, giving a nearly linear time algorithm for finding the most frustrated cycle of arbitrary length. We show how to use this search algorithm together with the dual decomposition framework and clusterpursuit. The new algorithm exactly solves MAP inference problems arising from relational classification and stereo vision.