 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAerialVLA: A Vision-Language-Action Model for UAV Navigation via Minimalist End-to-End Control
Mar 15, 2026Vision-Language Navigation (VLN) for Unmanned Aerial Vehicles (UAVs) demands complex visual interpretation and continuous control in dynamic 3D environments. Existing hierarchical approaches rely on dense oracle guidance or auxiliary object detectors, creating semantic gaps and limiting genuine autonomy. We propose AerialVLA, a minimalist end-to-end Vision-Language-Action framework mapping raw visual observations and fuzzy linguistic instructions directly to continuous physical control signals. First, we introduce a streamlined dual-view perception strategy that reduces visual redundancy while preserving essential cues for forward navigation and precise grounding, which additionally facilitates future simulation-to-reality transfer. To reclaim genuine autonomy, we deploy a fuzzy directional prompting mechanism derived solely from onboard sensors, completely eliminating the dependency on dense oracle guidance. Ultimately, we formulate a unified control space that integrates continuous 3-Degree-of-Freedom (3-DoF) kinematic commands with an intrinsic landing signal, freeing the agent from external object detectors for precision landing. Extensive experiments on the TravelUAV benchmark demonstrate that AerialVLA achieves state-of-the-art performance in seen environments. Furthermore, it exhibits superior generalization in unseen scenarios by achieving nearly three times the success rate of leading baselines, validating that a minimalist, autonomy-centric paradigm captures more robust visual-motor representations than complex modular systems.
Real-time Stereo-based 3D Object Detection for Streaming Perception
Oct 16, 2024



The ability to promptly respond to environmental changes is crucial for the perception system of autonomous driving. Recently, a new task called streaming perception was proposed. It jointly evaluate the latency and accuracy into a single metric for video online perception. In this work, we introduce StreamDSGN, the first real-time stereo-based 3D object detection framework designed for streaming perception. StreamDSGN is an end-to-end framework that directly predicts the 3D properties of objects in the next moment by leveraging historical information, thereby alleviating the accuracy degradation of streaming perception. Further, StreamDSGN applies three strategies to enhance the perception accuracy: (1) A feature-flow-based fusion method, which generates a pseudo-next feature at the current moment to address the misalignment issue between feature and ground truth. (2) An extra regression loss for explicit supervision of object motion consistency in consecutive frames. (3) A large kernel backbone with a large receptive field for effectively capturing long-range spatial contextual features caused by changes in object positions. Experiments on the KITTI Tracking dataset show that, compared with the strong baseline, StreamDSGN significantly improves the streaming average precision by up to 4.33%. Our code is available at https://github.com/weiyangdaren/streamDSGN-pytorch.
Efficient Spiking Neural Networks with Logarithmic Temporal Coding
Nov 10, 2018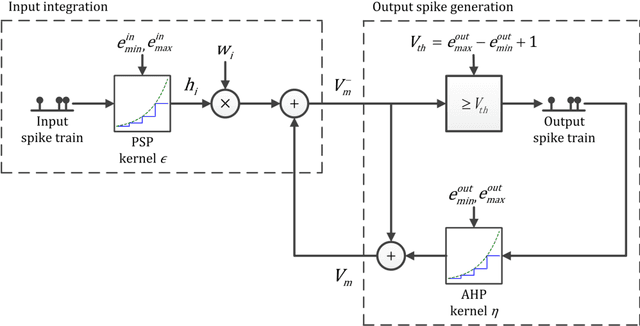
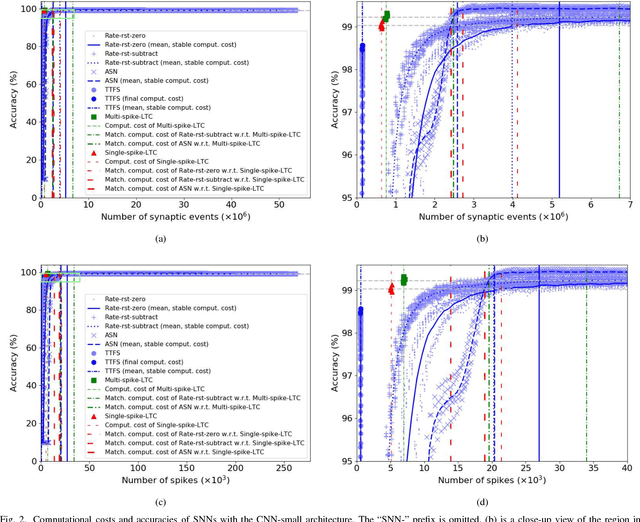
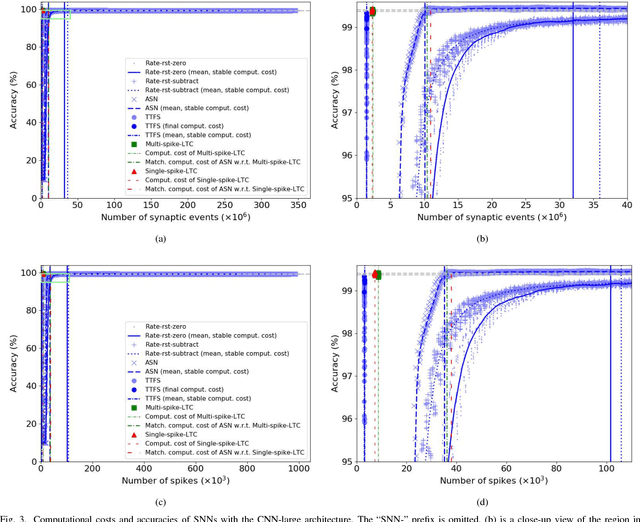

A Spiking Neural Network (SNN) can be trained indirectly by first training an Artificial Neural Network (ANN) with the conventional backpropagation algorithm, then converting it into an SNN. The conventional rate-coding method for SNNs uses the number of spikes to encode magnitude of an activation value, and may be computationally inefficient due to the large number of spikes. Temporal-coding is typically more efficient by leveraging the timing of spikes to encode information. In this paper, we present Logarithmic Temporal Coding (LTC), where the number of spikes used to encode an activation value grows logarithmically with the activation value; and the accompanying Exponentiate-and-Fire (EF) spiking neuron model, which only involves efficient bit-shift and addition operations. Moreover, we improve the training process of ANN to compensate for approximation errors due to LTC. Experimental results indicate that the resulting SNN achieves competitive performance at significantly lower computational cost than related work.
Two-Bit Networks for Deep Learning on Resource-Constrained Embedded Devices
Jan 04, 2017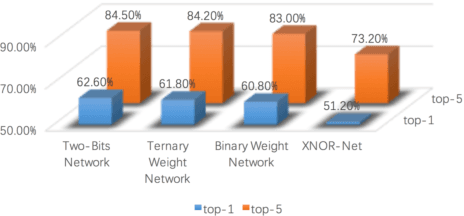
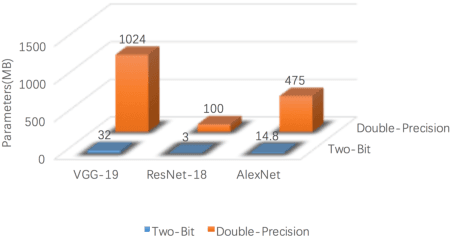
With the rapid proliferation of Internet of Things and intelligent edge devices, there is an increasing need for implementing machine learning algorithms, including deep learning, on resource-constrained mobile embedded devices with limited memory and computation power. Typical large Convolutional Neural Networks (CNNs) need large amounts of memory and computational power, and cannot be deployed on embedded devices efficiently. We present Two-Bit Networks (TBNs) for model compression of CNNs with edge weights constrained to (-2, -1, 1, 2), which can be encoded with two bits. Our approach can reduce the memory usage and improve computational efficiency significantly while achieving good performance in terms of classification accuracy, thus representing a reasonable tradeoff between model size and performance.