 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoTZero: Annotation-Free Human-Like Vision Reasoning via Hierarchical Synthetic CoT
Feb 09, 2026Recent advances in vision-language models (VLMs) have markedly improved image-text alignment, yet they still fall short of human-like visual reasoning. A key limitation is that many VLMs rely on surface correlations rather than building logically coherent structured representations, which often leads to missed higher-level semantic structure and non-causal relational understanding, hindering compositional and verifiable reasoning. To address these limitations by introducing human models into the reasoning process, we propose CoTZero, an annotation-free paradigm with two components: (i) a dual-stage data synthesis approach and (ii) a cognition-aligned training method. In the first component, we draw inspiration from neurocognitive accounts of compositional productivity and global-to-local analysis. In the bottom-up stage, CoTZero extracts atomic visual primitives and incrementally composes them into diverse, structured question-reasoning forms. In the top-down stage, it enforces hierarchical reasoning by using coarse global structure to guide the interpretation of local details and causal relations. In the cognition-aligned training component, built on the synthesized CoT data, we introduce Cognitively Coherent Verifiable Rewards (CCVR) in Reinforcement Fine-Tuning (RFT) to further strengthen VLMs' hierarchical reasoning and generalization, providing stepwise feedback on reasoning coherence and factual correctness. Experiments show that CoTZero achieves an F1 score of 83.33 percent on our multi-level semantic inconsistency benchmark with lexical-perturbation negatives, across both in-domain and out-of-domain settings. Ablations confirm that each component contributes to more interpretable and human-aligned visual reasoning.
Rethinking Popularity Bias in Collaborative Filtering via Analytical Vector Decomposition
Dec 24, 2025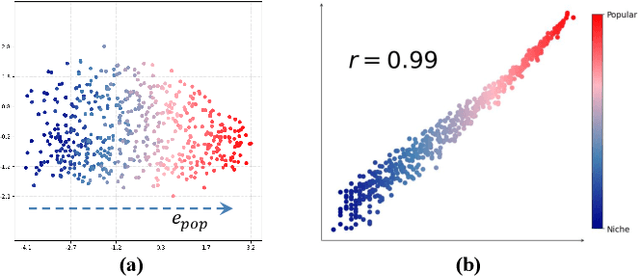
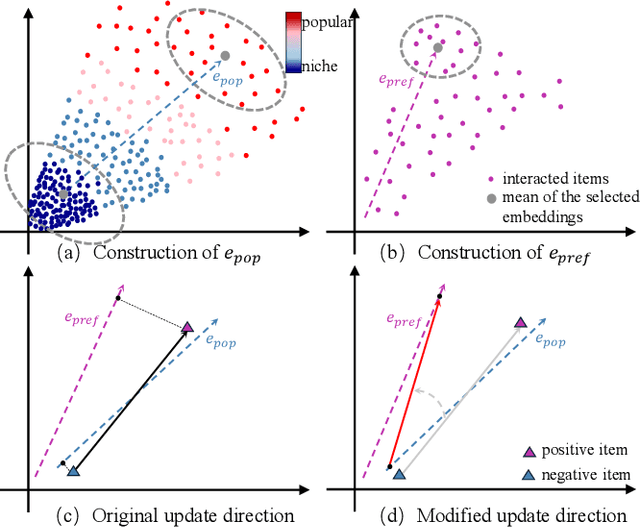
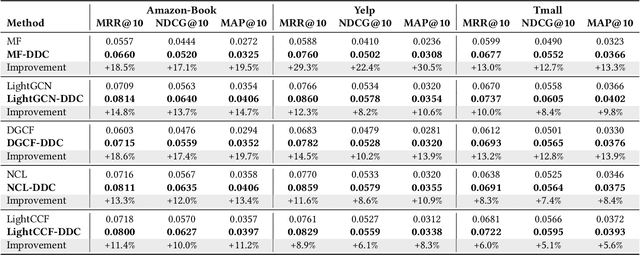
Popularity bias fundamentally undermines the personalization capabilities of collaborative filtering (CF) models, causing them to disproportionately recommend popular items while neglecting users' genuine preferences for niche content. While existing approaches treat this as an external confounding factor, we reveal that popularity bias is an intrinsic geometric artifact of Bayesian Pairwise Ranking (BPR) optimization in CF models. Through rigorous mathematical analysis, we prove that BPR systematically organizes item embeddings along a dominant "popularity direction" where embedding magnitudes directly correlate with interaction frequency. This geometric distortion forces user embeddings to simultaneously handle two conflicting tasks-expressing genuine preference and calibrating against global popularity-trapping them in suboptimal configurations that favor popular items regardless of individual tastes. We propose Directional Decomposition and Correction (DDC), a universally applicable framework that surgically corrects this embedding geometry through asymmetric directional updates. DDC guides positive interactions along personalized preference directions while steering negative interactions away from the global popularity direction, disentangling preference from popularity at the geometric source. Extensive experiments across multiple BPR-based architectures demonstrate that DDC significantly outperforms state-of-the-art debiasing methods, reducing training loss to less than 5% of heavily-tuned baselines while achieving superior recommendation quality and fairness. Code is available in https://github.com/LingFeng-Liu-AI/DDC.
ChemATP: A Training-Free Chemical Reasoning Framework for Large Language Models
Dec 22, 2025Large Language Models (LLMs) exhibit strong general reasoning but struggle in molecular science due to the lack of explicit chemical priors in standard string representations. Current solutions face a fundamental dilemma. Training-based methods inject priors into parameters, but this static coupling hinders rapid knowledge updates and often compromises the model's general reasoning capabilities. Conversely, existing training-free methods avoid these issues but rely on surface-level prompting, failing to provide the fine-grained atom-level priors essential for precise chemical reasoning. To address this issue, we introduce ChemATP, a framework that decouples chemical knowledge from the reasoning engine. By constructing the first atom-level textual knowledge base, ChemATP enables frozen LLMs to explicitly retrieve and reason over this information dynamically. This architecture ensures interpretability and adaptability while preserving the LLM's intrinsic general intelligence. Experiments show that ChemATP significantly outperforms training-free baselines and rivals state-of-the-art training-based models, demonstrating that explicit prior injection is a competitive alternative to implicit parameter updates.
Enhancing Conversational Recommender Systems with Tree-Structured Knowledge and Pretrained Language Models
Nov 16, 2025



Recent advances in pretrained language models (PLMs) have significantly improved conversational recommender systems (CRS), enabling more fluent and context-aware interactions. To further enhance accuracy and mitigate hallucination, many methods integrate PLMs with knowledge graphs (KGs), but face key challenges: failing to fully exploit PLM reasoning over graph relationships, indiscriminately incorporating retrieved knowledge without context filtering, and neglecting collaborative preferences in multi-turn dialogues. To this end, we propose PCRS-TKA, a prompt-based framework employing retrieval-augmented generation to integrate PLMs with KGs. PCRS-TKA constructs dialogue-specific knowledge trees from KGs and serializes them into texts, enabling structure-aware reasoning while capturing rich entity semantics. Our approach selectively filters context-relevant knowledge and explicitly models collaborative preferences using specialized supervision signals. A semantic alignment module harmonizes heterogeneous inputs, reducing noise and enhancing accuracy. Extensive experiments demonstrate that PCRS-TKA consistently outperforms all baselines in both recommendation and conversational quality.
NGTM: Substructure-based Neural Graph Topic Model for Interpretable Graph Generation
Jul 17, 2025Graph generation plays a pivotal role across numerous domains, including molecular design and knowledge graph construction. Although existing methods achieve considerable success in generating realistic graphs, their interpretability remains limited, often obscuring the rationale behind structural decisions. To address this challenge, we propose the Neural Graph Topic Model (NGTM), a novel generative framework inspired by topic modeling in natural language processing. NGTM represents graphs as mixtures of latent topics, each defining a distribution over semantically meaningful substructures, which facilitates explicit interpretability at both local and global scales. The generation process transparently integrates these topic distributions with a global structural variable, enabling clear semantic tracing of each generated graph. Experiments demonstrate that NGTM achieves competitive generation quality while uniquely enabling fine-grained control and interpretability, allowing users to tune structural features or induce biological properties through topic-level adjustments.
MolEditRL: Structure-Preserving Molecular Editing via Discrete Diffusion and Reinforcement Learning
May 26, 2025Molecular editing aims to modify a given molecule to optimize desired chemical properties while preserving structural similarity. However, current approaches typically rely on string-based or continuous representations, which fail to adequately capture the discrete, graph-structured nature of molecules, resulting in limited structural fidelity and poor controllability. In this paper, we propose MolEditRL, a molecular editing framework that explicitly integrates structural constraints with precise property optimization. Specifically, MolEditRL consists of two stages: (1) a discrete graph diffusion model pretrained to reconstruct target molecules conditioned on source structures and natural language instructions; (2) an editing-aware reinforcement learning fine-tuning stage that further enhances property alignment and structural preservation by explicitly optimizing editing decisions under graph constraints. For comprehensive evaluation, we construct MolEdit-Instruct, the largest and most property-rich molecular editing dataset, comprising 3 million diverse examples spanning single- and multi-property tasks across 10 chemical attributes. Experimental results demonstrate that MolEditRL significantly outperforms state-of-the-art methods in both property optimization accuracy and structural fidelity, achieving a 74\% improvement in editing success rate while using 98\% fewer parameters.
ADT: Tuning Diffusion Models with Adversarial Supervision
Apr 15, 2025



Diffusion models have achieved outstanding image generation by reversing a forward noising process to approximate true data distributions. During training, these models predict diffusion scores from noised versions of true samples in a single forward pass, while inference requires iterative denoising starting from white noise. This training-inference divergences hinder the alignment between inference and training data distributions, due to potential prediction biases and cumulative error accumulation. To address this problem, we propose an intuitive but effective fine-tuning framework, called Adversarial Diffusion Tuning (ADT), by stimulating the inference process during optimization and aligning the final outputs with training data by adversarial supervision. Specifically, to achieve robust adversarial training, ADT features a siamese-network discriminator with a fixed pre-trained backbone and lightweight trainable parameters, incorporates an image-to-image sampling strategy to smooth discriminative difficulties, and preserves the original diffusion loss to prevent discriminator hacking. In addition, we carefully constrain the backward-flowing path for back-propagating gradients along the inference path without incurring memory overload or gradient explosion. Finally, extensive experiments on Stable Diffusion models (v1.5, XL, and v3), demonstrate that ADT significantly improves both distribution alignment and image quality.
Boosting Knowledge Graph-based Recommendations through Confidence-Aware Augmentation with Large Language Models
Feb 06, 2025



Knowledge Graph-based recommendations have gained significant attention due to their ability to leverage rich semantic relationships. However, constructing and maintaining Knowledge Graphs (KGs) is resource-intensive, and the accuracy of KGs can suffer from noisy, outdated, or irrelevant triplets. Recent advancements in Large Language Models (LLMs) offer a promising way to improve the quality and relevance of KGs for recommendation tasks. Despite this, integrating LLMs into KG-based systems presents challenges, such as efficiently augmenting KGs, addressing hallucinations, and developing effective joint learning methods. In this paper, we propose the Confidence-aware KG-based Recommendation Framework with LLM Augmentation (CKG-LLMA), a novel framework that combines KGs and LLMs for recommendation task. The framework includes: (1) an LLM-based subgraph augmenter for enriching KGs with high-quality information, (2) a confidence-aware message propagation mechanism to filter noisy triplets, and (3) a dual-view contrastive learning method to integrate user-item interactions and KG data. Additionally, we employ a confidence-aware explanation generation process to guide LLMs in producing realistic explanations for recommendations. Finally, extensive experiments demonstrate the effectiveness of CKG-LLMA across multiple public datasets.
A Comprehensive Survey on Self-Interpretable Neural Networks
Jan 26, 2025Neural networks have achieved remarkable success across various fields. However, the lack of interpretability limits their practical use, particularly in critical decision-making scenarios. Post-hoc interpretability, which provides explanations for pre-trained models, is often at risk of robustness and fidelity. This has inspired a rising interest in self-interpretable neural networks, which inherently reveal the prediction rationale through the model structures. Although there exist surveys on post-hoc interpretability, a comprehensive and systematic survey of self-interpretable neural networks is still missing. To address this gap, we first collect and review existing works on self-interpretable neural networks and provide a structured summary of their methodologies from five key perspectives: attribution-based, function-based, concept-based, prototype-based, and rule-based self-interpretation. We also present concrete, visualized examples of model explanations and discuss their applicability across diverse scenarios, including image, text, graph data, and deep reinforcement learning. Additionally, we summarize existing evaluation metrics for self-interpretability and identify open challenges in this field, offering insights for future research. To support ongoing developments, we present a publicly accessible resource to track advancements in this domain: https://github.com/yangji721/Awesome-Self-Interpretable-Neural-Network.
Hierarchical Time-Aware Mixture of Experts for Multi-Modal Sequential Recommendation
Jan 24, 2025Multi-modal sequential recommendation (SR) leverages multi-modal data to learn more comprehensive item features and user preferences than traditional SR methods, which has become a critical topic in both academia and industry. Existing methods typically focus on enhancing multi-modal information utility through adaptive modality fusion to capture the evolving of user preference from user-item interaction sequences. However, most of them overlook the interference caused by redundant interest-irrelevant information contained in rich multi-modal data. Additionally, they primarily rely on implicit temporal information based solely on chronological ordering, neglecting explicit temporal signals that could more effectively represent dynamic user interest over time. To address these limitations, we propose a Hierarchical time-aware Mixture of experts for multi-modal Sequential Recommendation (HM4SR) with a two-level Mixture of Experts (MoE) and a multi-task learning strategy. Specifically, the first MoE, named Interactive MoE, extracts essential user interest-related information from the multi-modal data of each item. Then, the second MoE, termed Temporal MoE, captures user dynamic interests by introducing explicit temporal embeddings from timestamps in modality encoding. To further address data sparsity, we propose three auxiliary supervision tasks: sequence-level category prediction (CP) for item feature understanding, contrastive learning on ID (IDCL) to align sequence context with user interests, and placeholder contrastive learning (PCL) to integrate temporal information with modalities for dynamic interest modeling. Extensive experiments on four public datasets verify the effectiveness of HM4SR compared to several state-of-the-art approaches.