 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourCastNet: Accelerating Global High-Resolution Weather Forecasting using Adaptive Fourier Neural Operators
Aug 08, 2022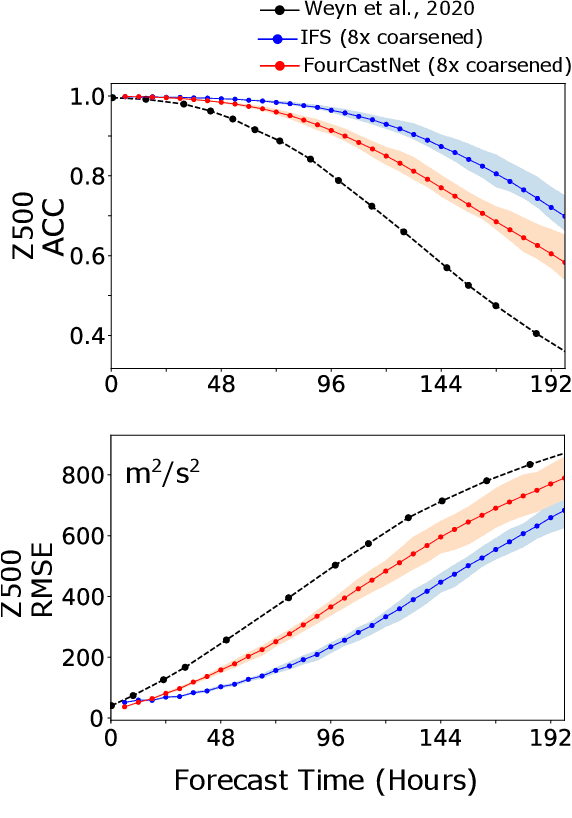
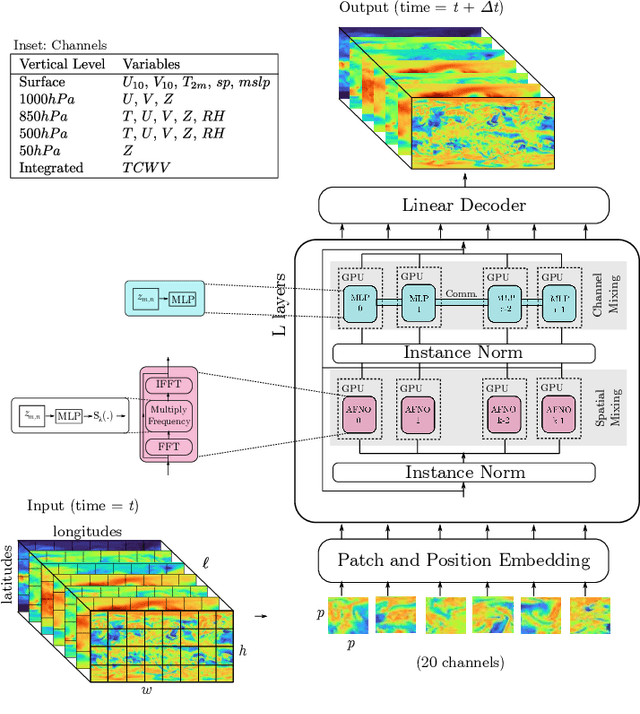
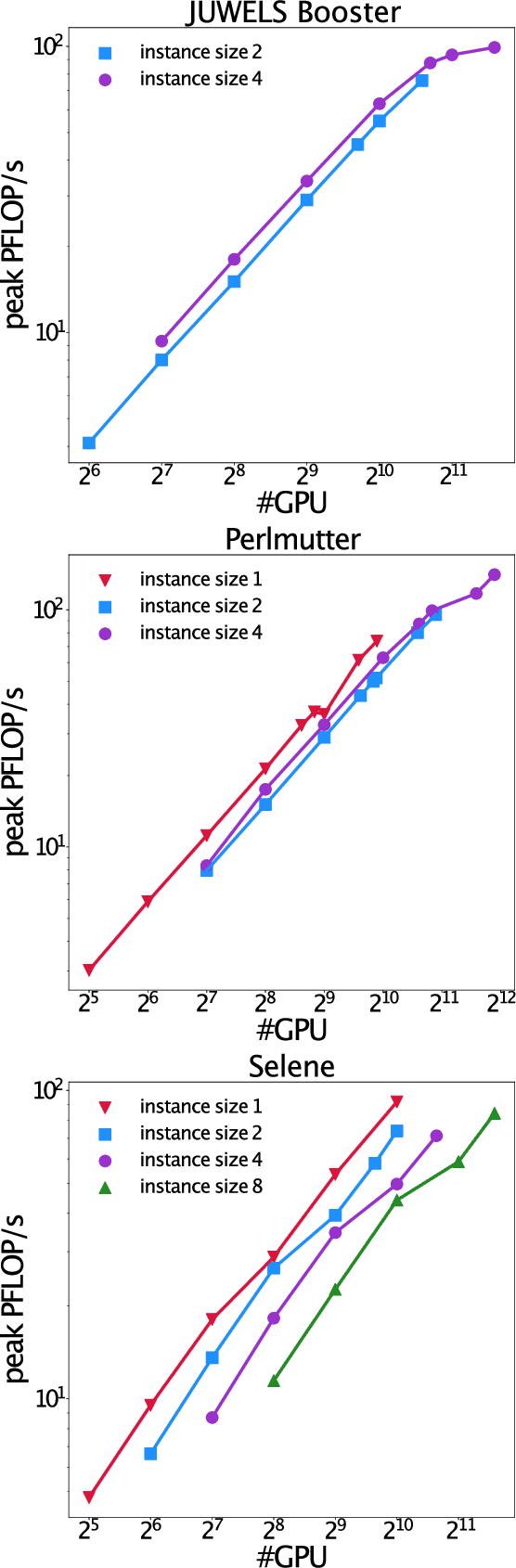
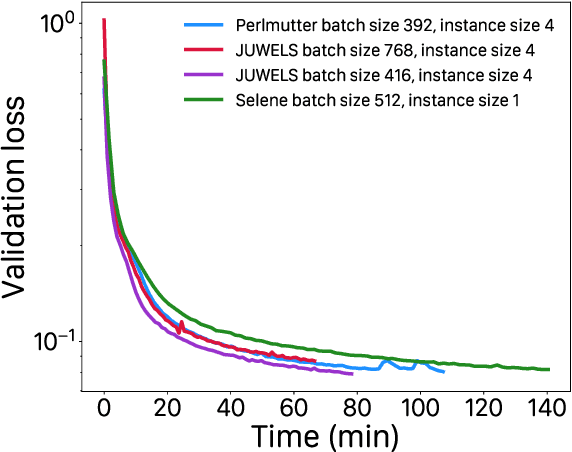
Extreme weather amplified by climate change is causing increasingly devastating impacts across the globe. The current use of physics-based numerical weather prediction (NWP) limits accuracy due to high computational cost and strict time-to-solution limits. We report that a data-driven deep learning Earth system emulator, FourCastNet, can predict global weather and generate medium-range forecasts five orders-of-magnitude faster than NWP while approaching state-of-the-art accuracy. FourCast-Net is optimized and scales efficiently on three supercomputing systems: Selene, Perlmutter, and JUWELS Booster up to 3,808 NVIDIA A100 GPUs, attaining 140.8 petaFLOPS in mixed precision (11.9%of peak at that scale). The time-to-solution for training FourCastNet measured on JUWELS Booster on 3,072GPUs is 67.4minutes, resulting in an 80,000times faster time-to-solution relative to state-of-the-art NWP, in inference. FourCastNet produces accurate instantaneous weather predictions for a week in advance, enables enormous ensembles that better capture weather extremes, and supports higher global forecast resolutions.
FourCastNet: A Global Data-driven High-resolution Weather Model using Adaptive Fourier Neural Operators
Feb 22, 2022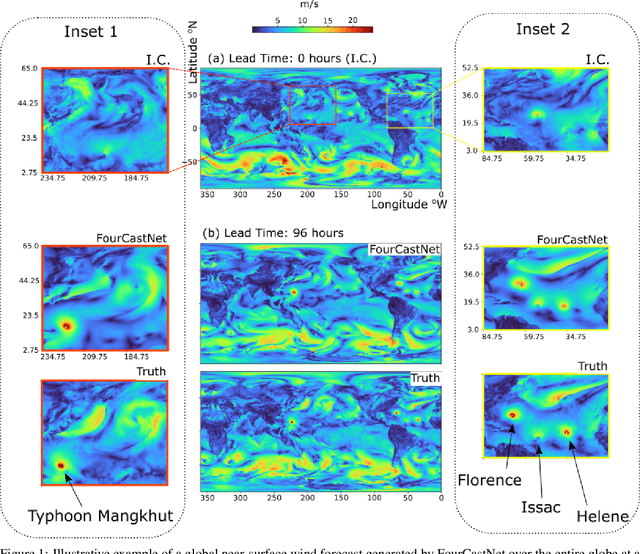

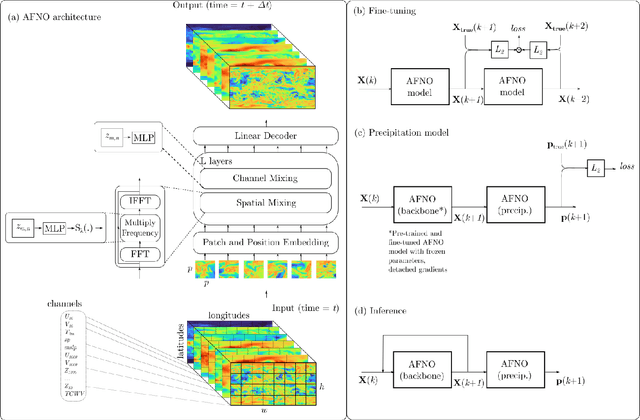
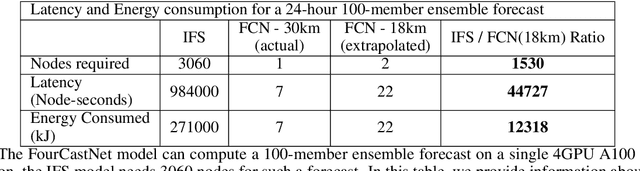
FourCastNet, short for Fourier Forecasting Neural Network, is a global data-driven weather forecasting model that provides accurate short to medium-range global predictions at $0.25^{\circ}$ resolution. FourCastNet accurately forecasts high-resolution, fast-timescale variables such as the surface wind speed, precipitation, and atmospheric water vapor. It has important implications for planning wind energy resources, predicting extreme weather events such as tropical cyclones, extra-tropical cyclones, and atmospheric rivers. FourCastNet matches the forecasting accuracy of the ECMWF Integrated Forecasting System (IFS), a state-of-the-art Numerical Weather Prediction (NWP) model, at short lead times for large-scale variables, while outperforming IFS for variables with complex fine-scale structure, including precipitation. FourCastNet generates a week-long forecast in less than 2 seconds, orders of magnitude faster than IFS. The speed of FourCastNet enables the creation of rapid and inexpensive large-ensemble forecasts with thousands of ensemble-members for improving probabilistic forecasting. We discuss how data-driven deep learning models such as FourCastNet are a valuable addition to the meteorology toolkit to aid and augment NWP models.
Evaluating the Impact of Semantic Segmentation and Pose Estimation on Dense Semantic SLAM
Sep 16, 2021

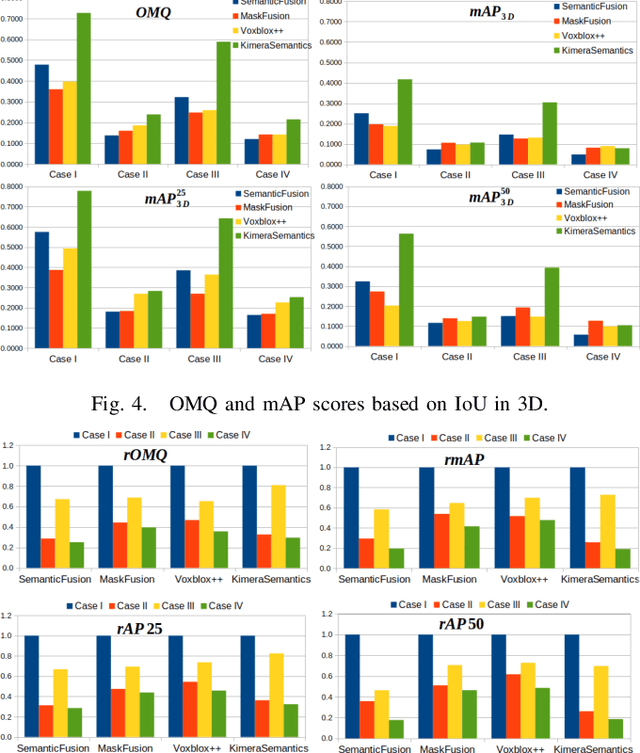
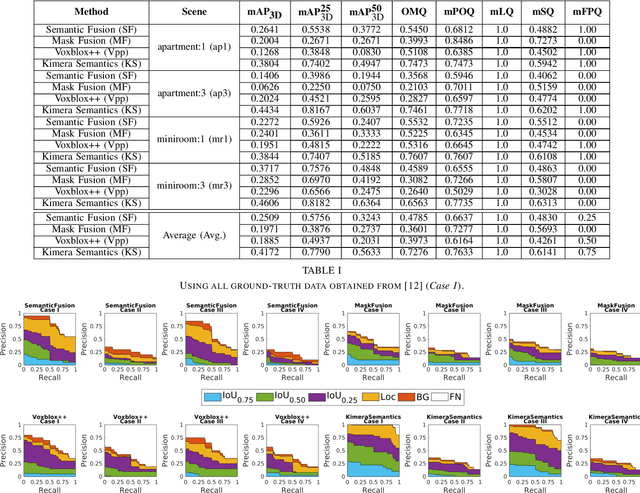
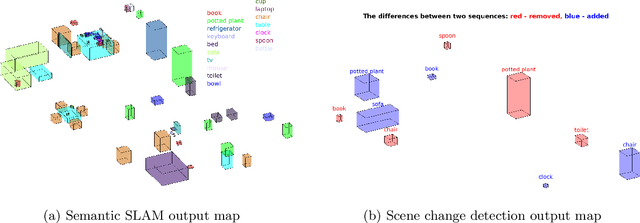
Recent Semantic SLAM methods combine classical geometry-based estimation with deep learning-based object detection or semantic segmentation. In this paper we evaluate the quality of semantic maps generated by state-of-the-art class- and instance-aware dense semantic SLAM algorithms whose codes are publicly available and explore the impacts both semantic segmentation and pose estimation have on the quality of semantic maps. We obtain these results by providing algorithms with ground-truth pose and/or semantic segmentation data available from simulated environments. We establish that semantic segmentation is the largest source of error through our experiments, dropping mAP and OMQ performance by up to 74.3% and 71.3% respectively.
A simulation environment for drone cinematography
Oct 03, 2020

In this paper, we present a workflow for the simulation of drone operations exploiting realistic background environments constructed within Unreal Engine 4 (UE4). Methods for environmental image capture, 3D reconstruction (photogrammetry) and the creation of foreground assets are presented along with a flexible and user-friendly simulation interface. Given the geographical location of the selected area and the camera parameters employed, the scanning strategy and its associated flight parameters are first determined for image capture. Source imagery can be extracted from virtual globe software or obtained through aerial photography of the scene (e.g. using drones). The latter case is clearly more time consuming but can provide enhanced detail, particularly where coverage of virtual globe software is limited. The captured images are then used to generate 3D background environment models employing photogrammetry software. The reconstructed 3D models are then imported into the simulation interface as background environment assets together with appropriate foreground object models as a basis for shot planning and rehearsal. The tool supports both free-flight and parameterisable standard shot types along with programmable scenarios associated with foreground assets and event dynamics. It also supports the exporting of flight plans. Camera shots can also be designed to provide suitable coverage of any landmarks which need to appear in-shot. This simulation tool will contribute to enhanced productivity, improved safety (awareness and mitigations for crowds and buildings), improved confidence of operators and directors and ultimately enhanced quality of viewer experience.
Task-Oriented Dialogue as Dataflow Synthesis
Oct 02, 2020We describe an approach to task-oriented dialogue in which dialogue state is represented as a dataflow graph. A dialogue agent maps each user utterance to a program that extends this graph. Programs include metacomputation operators for reference and revision that reuse dataflow fragments from previous turns. Our graph-based state enables the expression and manipulation of complex user intents, and explicit metacomputation makes these intents easier for learned models to predict. We introduce a new dataset, SMCalFlow, featuring complex dialogues about events, weather, places, and people. Experiments show that dataflow graphs and metacomputation substantially improve representability and predictability in these natural dialogues. Additional experiments on the MultiWOZ dataset show that our dataflow representation enables an otherwise off-the-shelf sequence-to-sequence model to match the best existing task-specific state tracking model. The SMCalFlow dataset and code for replicating experiments are available at https://www.microsoft.com/en-us/research/project/dataflow-based-dialogue-semantic-machines.
The Robotic Vision Scene Understanding Challenge
Sep 11, 2020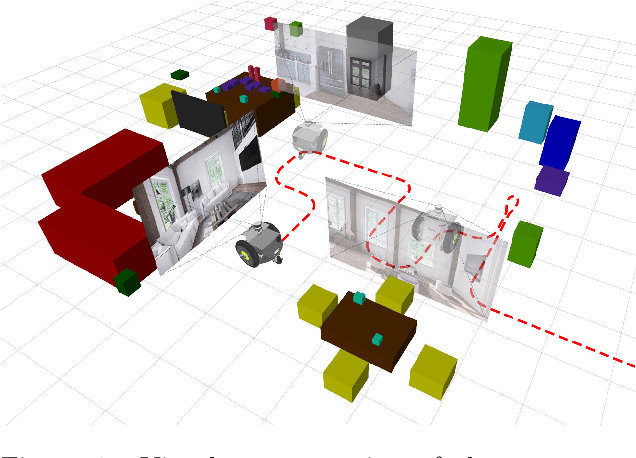
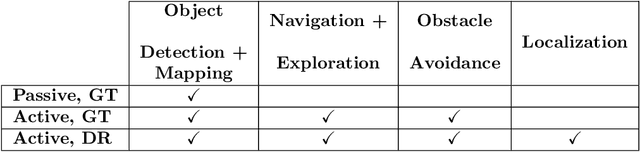

Being able to explore an environment and understand the location and type of all objects therein is important for indoor robotic platforms that must interact closely with humans. However, it is difficult to evaluate progress in this area due to a lack of standardized testing which is limited due to the need for active robot agency and perfect object ground-truth. To help provide a standard for testing scene understanding systems, we present a new robot vision scene understanding challenge using simulation to enable repeatable experiments with active robot agency. We provide two challenging task types, three difficulty levels, five simulated environments and a new evaluation measure for evaluating 3D cuboid object maps. Our aim is to drive state-of-the-art research in scene understanding through enabling evaluation and comparison of active robotic vision systems.
BenchBot: Evaluating Robotics Research in Photorealistic 3D Simulation and on Real Robots
Aug 03, 2020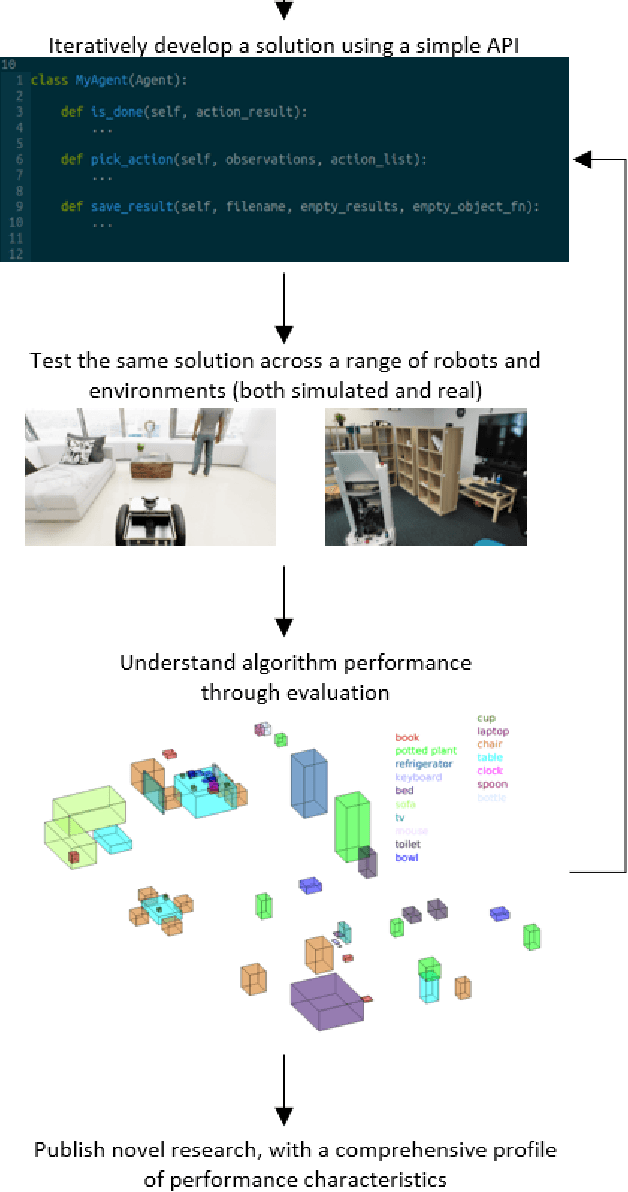

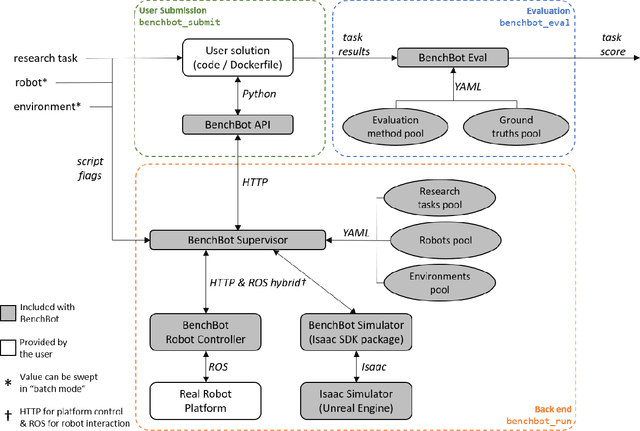

We introduce BenchBot, a novel software suite for benchmarking the performance of robotics research across both photorealistic 3D simulations and real robot platforms. BenchBot provides a simple interface to the sensorimotor capabilities of a robot when solving robotics research problems; an interface that is consistent regardless of whether the target platform is simulated or a real robot. In this paper we outline the BenchBot system architecture, and explore the parallels between its user-centric design and an ideal research development process devoid of tangential robot engineering challenges. The paper describes the research benefits of using the BenchBot system, including: enhanced capacity to focus solely on research problems, direct quantitative feedback to inform research development, tools for deriving comprehensive performance characteristics, and submission formats which promote sharability and repeatability of research outcomes. BenchBot is publicly available (http://benchbot.org), and we encourage its use in the research community for comprehensively evaluating the simulated and real world performance of novel robotic algorithms.
Tropical and Extratropical Cyclone Detection Using Deep Learning
May 18, 2020

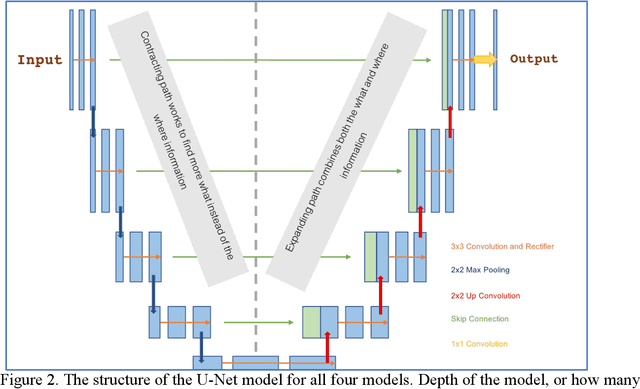
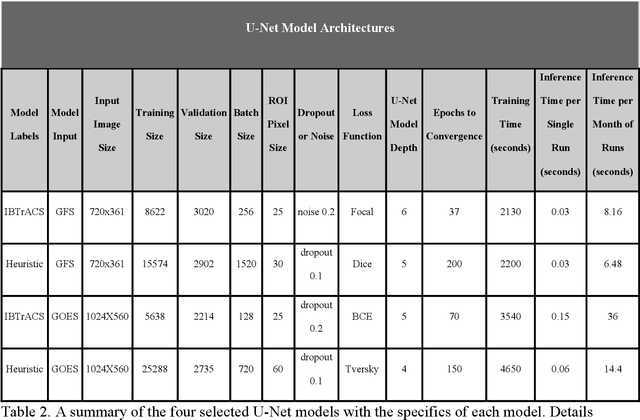
Extracting valuable information from large sets of diverse meteorological data is a time-intensive process. Machine learning methods can help improve both speed and accuracy of this process. Specifically, deep learning image segmentation models using the U-Net structure perform faster and can identify areas missed by more restrictive approaches, such as expert hand-labeling and a priori heuristic methods. This paper discusses four different state-of-the-art U-Net models designed for detection of tropical and extratropical cyclone Regions Of Interest (ROI) from two separate input sources: total precipitable water output from the Global Forecasting System (GFS) model and water vapor radiance images from the Geostationary Operational Environmental Satellite (GOES). These models are referred to as IBTrACS-GFS, Heuristic-GFS, IBTrACS-GOES, and Heuristic-GOES. All four U-Nets are fast information extraction tools and perform with a ROI detection accuracy ranging from 80% to 99%. These are additionally evaluated with the Dice and Tversky Intersection over Union (IoU) metrics, having Dice coefficient scores ranging from 0.51 to 0.76 and Tversky coefficients ranging from 0.56 to 0.74. The extratropical cyclone U-Net model performed 3 times faster than the comparable heuristic model used to detect the same ROI. The U-Nets were specifically selected for their capabilities in detecting cyclone ROI beyond the scope of the training labels. These machine learning models identified more ambiguous and active ROI missed by the heuristic model and hand-labeling methods commonly used in generating real-time weather alerts, having a potentially direct impact on public safety.
What can robotics research learn from computer vision research?
Jan 08, 2020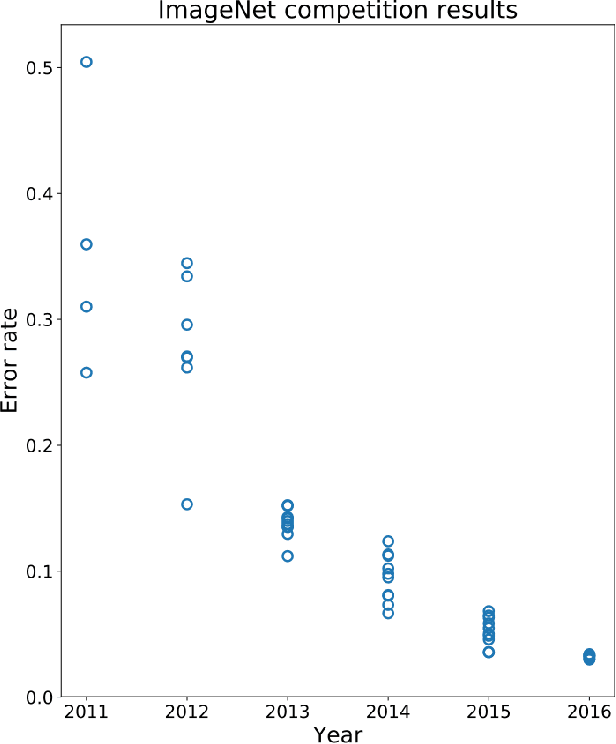
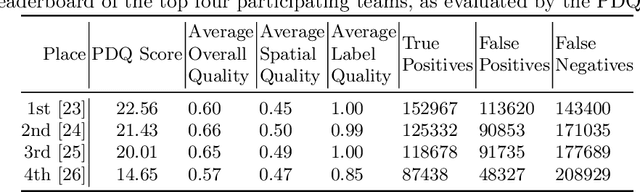


The computer vision and robotics research communities are each strong. However progress in computer vision has become turbo-charged in recent years due to big data, GPU computing, novel learning algorithms and a very effective research methodology. By comparison, progress in robotics seems slower. It is true that robotics came later to exploring the potential of learning -- the advantages over the well-established body of knowledge in dynamics, kinematics, planning and control is still being debated, although reinforcement learning seems to offer real potential. However, the rapid development of computer vision compared to robotics cannot be only attributed to the former's adoption of deep learning. In this paper, we argue that the gains in computer vision are due to research methodology -- evaluation under strict constraints versus experiments; bold numbers versus videos.
From Google Maps to a Fine-Grained Catalog of Street trees
Oct 07, 2019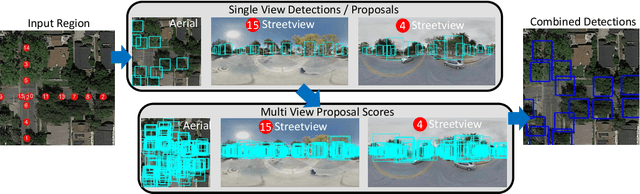
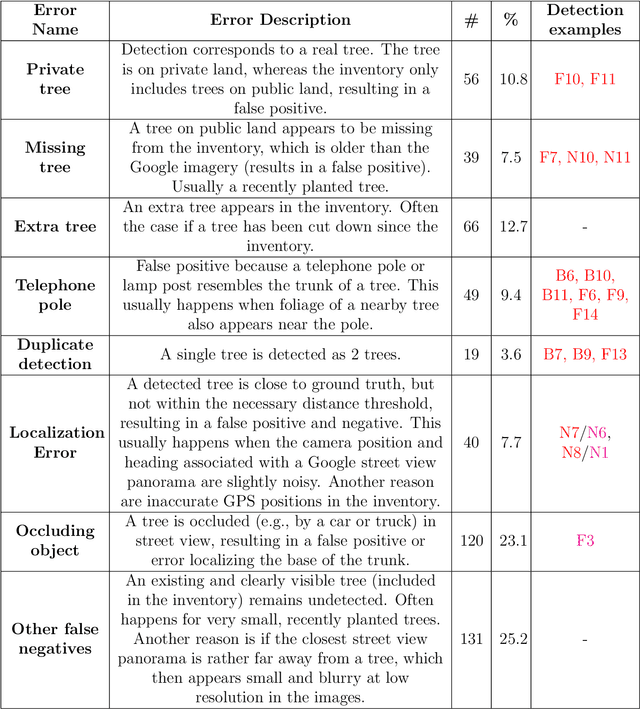

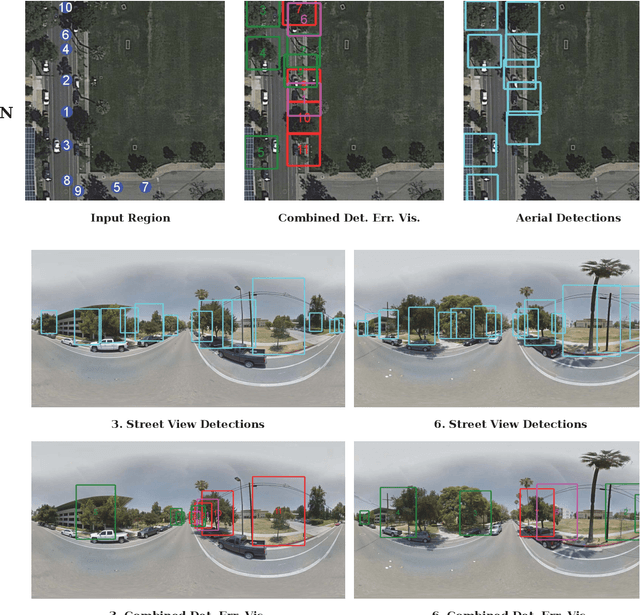
Up-to-date catalogs of the urban tree population are important for municipalities to monitor and improve quality of life in cities. Despite much research on automation of tree mapping, mainly relying on dedicated airborne LiDAR or hyperspectral campaigns, trees are still mostly mapped manually in practice. We present a fully automated tree detection and species recognition pipeline to process thousands of trees within a few hours using publicly available aerial and street view images of Google MapsTM. These data provide rich information (viewpoints, scales) from global tree shapes to bark textures. Our work-flow is built around a supervised classification that automatically learns the most discriminative features from thousands of trees and corresponding, public tree inventory data. In addition, we introduce a change tracker to keep urban tree inventories up-to-date. Changes of individual trees are recognized at city-scale by comparing street-level images of the same tree location at two different times. Drawing on recent advances in computer vision and machine learning, we apply convolutional neural networks (CNN) for all classification tasks. We propose the following pipeline: download all available panoramas and overhead images of an area of interest, detect trees per image and combine multi-view detections in a probabilistic framework, adding prior knowledge; recognize fine-grained species of detected trees. In a later, separate module, track trees over time and identify the type of change. We believe this is the first work to exploit publicly available image data for fine-grained tree mapping at city-scale, respectively over many thousands of trees. Experiments in the city of Pasadena, California, USA show that we can detect > 70% of the street trees, assign correct species to > 80% for 40 different species, and correctly detect and classify changes in > 90% of the cases.