 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMEarth-Bench: Global Model Adaptation via Multimodal Test-Time Training
Feb 06, 2026Recent research in geospatial machine learning has demonstrated that models pretrained with self-supervised learning on Earth observation data can perform well on downstream tasks with limited training data. However, most of the existing geospatial benchmark datasets have few data modalities and poor global representation, limiting the ability to evaluate multimodal pretrained models at global scales. To fill this gap, we introduce MMEarth-Bench, a collection of five new multimodal environmental tasks with 12 modalities, globally distributed data, and both in- and out-of-distribution test splits. We benchmark a diverse set of pretrained models and find that while (multimodal) pretraining tends to improve model robustness in limited data settings, geographic generalization abilities remain poor. In order to facilitate model adaptation to new downstream tasks and geographic domains, we propose a model-agnostic method for test-time training with multimodal reconstruction (TTT-MMR) that uses all the modalities available at test time as auxiliary tasks, regardless of whether a pretrained model accepts them as input. Our method improves model performance on both the random and geographic test splits, and geographic batching leads to a good trade-off between regularization and specialization during TTT. Our dataset, code, and visualization tool are linked from the project page at lgordon99.github.io/mmearth-bench.
SuperF: Neural Implicit Fields for Multi-Image Super-Resolution
Dec 09, 2025High-resolution imagery is often hindered by limitations in sensor technology, atmospheric conditions, and costs. Such challenges occur in satellite remote sensing, but also with handheld cameras, such as our smartphones. Hence, super-resolution aims to enhance the image resolution algorithmically. Since single-image super-resolution requires solving an inverse problem, such methods must exploit strong priors, e.g. learned from high-resolution training data, or be constrained by auxiliary data, e.g. by a high-resolution guide from another modality. While qualitatively pleasing, such approaches often lead to "hallucinated" structures that do not match reality. In contrast, multi-image super-resolution (MISR) aims to improve the (optical) resolution by constraining the super-resolution process with multiple views taken with sub-pixel shifts. Here, we propose SuperF, a test-time optimization approach for MISR that leverages coordinate-based neural networks, also called neural fields. Their ability to represent continuous signals with an implicit neural representation (INR) makes them an ideal fit for the MISR task. The key characteristic of our approach is to share an INR for multiple shifted low-resolution frames and to jointly optimize the frame alignment with the INR. Our approach advances related INR baselines, adopted from burst fusion for layer separation, by directly parameterizing the sub-pixel alignment as optimizable affine transformation parameters and by optimizing via a super-sampled coordinate grid that corresponds to the output resolution. Our experiments yield compelling results on simulated bursts of satellite imagery and ground-level images from handheld cameras, with upsampling factors of up to 8. A key advantage of SuperF is that this approach does not rely on any high-resolution training data.
Taxonomy-Aware Evaluation of Vision-Language Models
Apr 07, 2025
When a vision-language model (VLM) is prompted to identify an entity depicted in an image, it may answer 'I see a conifer,' rather than the specific label 'norway spruce'. This raises two issues for evaluation: First, the unconstrained generated text needs to be mapped to the evaluation label space (i.e., 'conifer'). Second, a useful classification measure should give partial credit to less-specific, but not incorrect, answers ('norway spruce' being a type of 'conifer'). To meet these requirements, we propose a framework for evaluating unconstrained text predictions, such as those generated from a vision-language model, against a taxonomy. Specifically, we propose the use of hierarchical precision and recall measures to assess the level of correctness and specificity of predictions with regard to a taxonomy. Experimentally, we first show that existing text similarity measures do not capture taxonomic similarity well. We then develop and compare different methods to map textual VLM predictions onto a taxonomy. This allows us to compute hierarchical similarity measures between the generated text and the ground truth labels. Finally, we analyze modern VLMs on fine-grained visual classification tasks based on our proposed taxonomic evaluation scheme.
Open-Set Recognition of Novel Species in Biodiversity Monitoring
Mar 03, 2025Machine learning is increasingly being applied to facilitate long-term, large-scale biodiversity monitoring. With most species on Earth still undiscovered or poorly documented, species-recognition models are expected to encounter new species during deployment. We introduce Open-Insects, a fine-grained image recognition benchmark dataset for open-set recognition and out-of-distribution detection in biodiversity monitoring. Open-Insects makes it possible to evaluate algorithms for new species detection on several geographical open-set splits with varying difficulty. Furthermore, we present a test set recently collected in the wild with 59 species that are likely new to science. We evaluate a variety of open-set recognition algorithms, including post-hoc methods, training-time regularization, and training with auxiliary data, finding that the simple post-hoc approach of utilizing softmax scores remains a strong baseline. We also demonstrate how to leverage auxiliary data to improve the detection performance when the training dataset is limited. Our results provide timely insights to guide the development of computer vision methods for biodiversity monitoring and species discovery.
Multimodal Fusion Strategies for Mapping Biophysical Landscape Features
Oct 07, 2024



Multimodal aerial data are used to monitor natural systems, and machine learning can significantly accelerate the classification of landscape features within such imagery to benefit ecology and conservation. It remains under-explored, however, how these multiple modalities ought to be fused in a deep learning model. As a step towards filling this gap, we study three strategies (Early fusion, Late fusion, and Mixture of Experts) for fusing thermal, RGB, and LiDAR imagery using a dataset of spatially-aligned orthomosaics in these three modalities. In particular, we aim to map three ecologically-relevant biophysical landscape features in African savanna ecosystems: rhino middens, termite mounds, and water. The three fusion strategies differ in whether the modalities are fused early or late, and if late, whether the model learns fixed weights per modality for each class or generates weights for each class adaptively, based on the input. Overall, the three methods have similar macro-averaged performance with Late fusion achieving an AUC of 0.698, but their per-class performance varies strongly, with Early fusion achieving the best recall for middens and water and Mixture of Experts achieving the best recall for mounds.
Labeled Data Selection for Category Discovery
Jun 07, 2024



Category discovery methods aim to find novel categories in unlabeled visual data. At training time, a set of labeled and unlabeled images are provided, where the labels correspond to the categories present in the images. The labeled data provides guidance during training by indicating what types of visual properties and features are relevant for performing discovery in the unlabeled data. As a result, changing the categories present in the labeled set can have a large impact on what is ultimately discovered in the unlabeled set. Despite its importance, the impact of labeled data selection has not been explored in the category discovery literature to date. We show that changing the labeled data can significantly impact discovery performance. Motivated by this, we propose two new approaches for automatically selecting the most suitable labeled data based on the similarity between the labeled and unlabeled data. Our observation is that, unlike in conventional supervised transfer learning, the best labeled is neither too similar, nor too dissimilar, to the unlabeled categories. Our resulting approaches obtains state-of-the-art discovery performance across a range of challenging fine-grained benchmark datasets.
Nacala-Roof-Material: Drone Imagery for Roof Detection, Classification, and Segmentation to Support Mosquito-borne Disease Risk Assessment
Jun 07, 2024



As low-quality housing and in particular certain roof characteristics are associated with an increased risk of malaria, classification of roof types based on remote sensing imagery can support the assessment of malaria risk and thereby help prevent the disease. To support research in this area, we release the Nacala-Roof-Material dataset, which contains high-resolution drone images from Mozambique with corresponding labels delineating houses and specifying their roof types. The dataset defines a multi-task computer vision problem, comprising object detection, classification, and segmentation. In addition, we benchmarked various state-of-the-art approaches on the dataset. Canonical U-Nets, YOLOv8, and a custom decoder on pretrained DINOv2 served as baselines. We show that each of the methods has its advantages but none is superior on all tasks, which highlights the potential of our dataset for future research in multi-task learning. While the tasks are closely related, accurate segmentation of objects does not necessarily imply accurate instance separation, and vice versa. We address this general issue by introducing a variant of the deep ordinal watershed (DOW) approach that additionally separates the interior of objects, allowing for improved object delineation and separation. We show that our DOW variant is a generic approach that improves the performance of both U-Net and DINOv2 backbones, leading to a better trade-off between semantic segmentation and instance segmentation.
MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning
May 04, 2024



The volume of unlabelled Earth observation (EO) data is huge, but many important applications lack labelled training data. However, EO data offers the unique opportunity to pair data from different modalities and sensors automatically based on geographic location and time, at virtually no human labor cost. We seize this opportunity to create a diverse multi-modal pretraining dataset at global scale. Using this new corpus of 1.2 million locations, we propose a Multi-Pretext Masked Autoencoder (MP-MAE) approach to learn general-purpose representations for optical satellite images. Our approach builds on the ConvNeXt V2 architecture, a fully convolutional masked autoencoder (MAE). Drawing upon a suite of multi-modal pretext tasks, we demonstrate that our MP-MAE approach outperforms both MAEs pretrained on ImageNet and MAEs pretrained on domain-specific satellite images. This is shown on several downstream tasks including image classification and semantic segmentation. We find that multi-modal pretraining notably improves the linear probing performance, e.g. 4pp on BigEarthNet and 16pp on So2Sat, compared to pretraining on optical satellite images only. We show that this also leads to better label and parameter efficiency which are crucial aspects in global scale applications.
Familiarity-Based Open-Set Recognition Under Adversarial Attacks
Nov 08, 2023Open-set recognition (OSR), the identification of novel categories, can be a critical component when deploying classification models in real-world applications. Recent work has shown that familiarity-based scoring rules such as the Maximum Softmax Probability (MSP) or the Maximum Logit Score (MLS) are strong baselines when the closed-set accuracy is high. However, one of the potential weaknesses of familiarity-based OSR are adversarial attacks. Here, we present gradient-based adversarial attacks on familiarity scores for both types of attacks, False Familiarity and False Novelty attacks, and evaluate their effectiveness in informed and uninformed settings on TinyImageNet.
Satellite-based high-resolution maps of cocoa planted area for Côte d'Ivoire and Ghana
Jun 13, 2022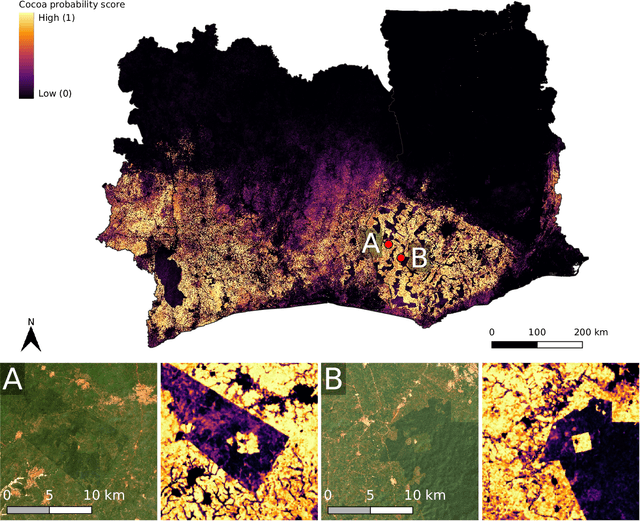
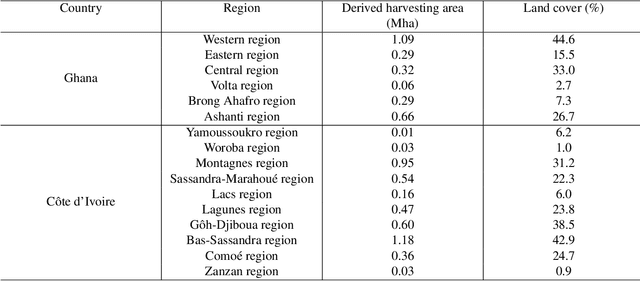
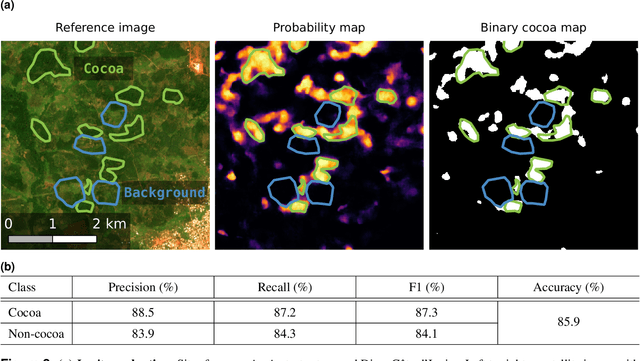
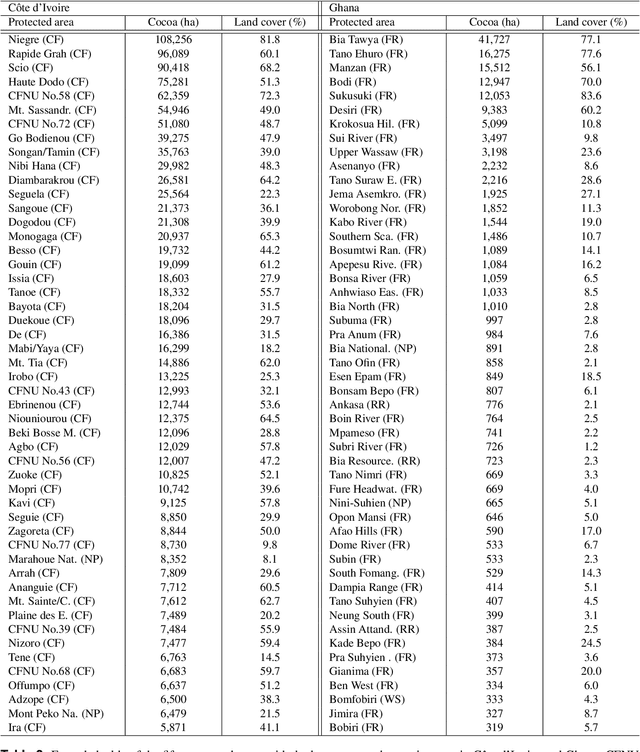
C\^ote d'Ivoire and Ghana, the world's largest producers of cocoa, account for two thirds of the global cocoa production. In both countries, cocoa is the primary perennial crop, providing income to almost two million farmers. Yet precise maps of cocoa planted area are missing, hindering accurate quantification of expansion in protected areas, production and yields, and limiting information available for improved sustainability governance. Here, we combine cocoa plantation data with publicly available satellite imagery in a deep learning framework and create high-resolution maps of cocoa plantations for both countries, validated in situ. Our results suggest that cocoa cultivation is an underlying driver of over 37% and 13% of forest loss in protected areas in C\^ote d'Ivoire and Ghana, respectively, and that official reports substantially underestimate the planted area, up to 40% in Ghana. These maps serve as a crucial building block to advance understanding of conservation and economic development in cocoa producing regions.