 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss Smoothing for Stable Adaptation Under Distribution Shift
Jul 01, 2026In settings such as fine-tuning and reinforcement learning, neural networks are often adapted under distribution shift. Standard adaptation methods typically optimize the target objective directly, inducing an abrupt change from the source training objective. This abrupt transition can distort learned representations, including features that may still be useful for the new task. We investigate whether a more gradual transition can improve adaptation. We propose loss smoothing, a simple approach that interpolates between the source and target training objectives at the start of adaptation. This smooth transition helps to preserve useful features from the source distribution while still enabling the model to specialize to the target distribution. Across controlled supervised shifts, pretrained vision adaptation, offline-to-online and online reinforcement learning, and language model fine-tuning, we find that loss smoothing consistently improves performance, suggesting that smoother objective transitions are a broadly useful tool for model adaptation.
CoPeP: Benchmarking Continual Pretraining for Protein Language Models
Mar 03, 2026Protein language models (pLMs) have recently gained significant attention for their ability to uncover relationships between sequence, structure, and function from evolutionary statistics, thereby accelerating therapeutic drug discovery. These models learn from large protein databases that are continuously updated by the biology community and whose dynamic nature motivates the application of continual learning, not only to keep up with the ever-growing data, but also as an opportunity to take advantage of the temporal meta-information that is created during this process. As a result, we introduce the Continual Pretraining of Protein Language Models (CoPeP) benchmark, a novel benchmark for evaluating continual learning approaches on pLMs. Specifically, we curate a sequence of protein datasets derived from the UniProt Knowledgebase spanning a decade and define metrics to assess pLM performance across 31 protein understanding tasks. We evaluate several methods from the continual learning literature, including replay, unlearning, and plasticity-based methods, some of which have never been applied to models and data of this scale. Our findings reveal that incorporating temporal meta-information improves perplexity by up to 7% even when compared to training on data from all tasks jointly. Moreover, even at scale, several continual learning methods outperform naive continual pretraining. The CoPeP benchmark offers an exciting opportunity to study these methods at scale in an impactful real-world application.
Modular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
Operationalising the Superficial Alignment Hypothesis via Task Complexity
Feb 17, 2026The superficial alignment hypothesis (SAH) posits that large language models learn most of their knowledge during pre-training, and that post-training merely surfaces this knowledge. The SAH, however, lacks a precise definition, which has led to (i) different and seemingly orthogonal arguments supporting it, and (ii) important critiques to it. We propose a new metric called task complexity: the length of the shortest program that achieves a target performance on a task. In this framework, the SAH simply claims that pre-trained models drastically reduce the complexity of achieving high performance on many tasks. Our definition unifies prior arguments supporting the SAH, interpreting them as different strategies to find such short programs. Experimentally, we estimate the task complexity of mathematical reasoning, machine translation, and instruction following; we then show that these complexities can be remarkably low when conditioned on a pre-trained model. Further, we find that pre-training enables access to strong performances on our tasks, but it can require programs of gigabytes of length to access them. Post-training, on the other hand, collapses the complexity of reaching this same performance by several orders of magnitude. Overall, our results highlight that task adaptation often requires surprisingly little information -- often just a few kilobytes.
Toward Debugging Deep Reinforcement Learning Programs with RLExplorer
Oct 06, 2024



Deep reinforcement learning (DRL) has shown success in diverse domains such as robotics, computer games, and recommendation systems. However, like any other software system, DRL-based software systems are susceptible to faults that pose unique challenges for debugging and diagnosing. These faults often result in unexpected behavior without explicit failures and error messages, making debugging difficult and time-consuming. Therefore, automating the monitoring and diagnosis of DRL systems is crucial to alleviate the burden on developers. In this paper, we propose RLExplorer, the first fault diagnosis approach for DRL-based software systems. RLExplorer automatically monitors training traces and runs diagnosis routines based on properties of the DRL learning dynamics to detect the occurrence of DRL-specific faults. It then logs the results of these diagnoses as warnings that cover theoretical concepts, recommended practices, and potential solutions to the identified faults. We conducted two sets of evaluations to assess RLExplorer. Our first evaluation of faulty DRL samples from Stack Overflow revealed that our approach can effectively diagnose real faults in 83% of the cases. Our second evaluation of RLExplorer with 15 DRL experts/developers showed that (1) RLExplorer could identify 3.6 times more defects than manual debugging and (2) RLExplorer is easily integrated into DRL applications.
Intelligent Switching for Reset-Free RL
May 02, 2024In the real world, the strong episode resetting mechanisms that are needed to train agents in simulation are unavailable. The \textit{resetting} assumption limits the potential of reinforcement learning in the real world, as providing resets to an agent usually requires the creation of additional handcrafted mechanisms or human interventions. Recent work aims to train agents (\textit{forward}) with learned resets by constructing a second (\textit{backward}) agent that returns the forward agent to the initial state. We find that the termination and timing of the transitions between these two agents are crucial for algorithm success. With this in mind, we create a new algorithm, Reset Free RL with Intelligently Switching Controller (RISC) which intelligently switches between the two agents based on the agent's confidence in achieving its current goal. Our new method achieves state-of-the-art performance on several challenging environments for reset-free RL.
An Empirical Investigation of the Role of Pre-training in Lifelong Learning
Dec 16, 2021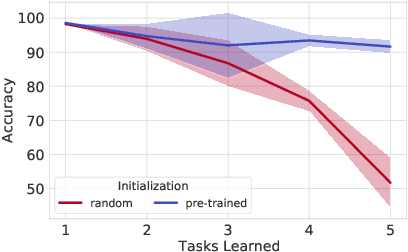
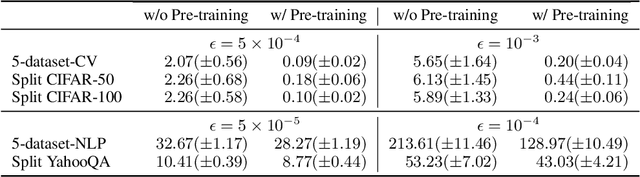
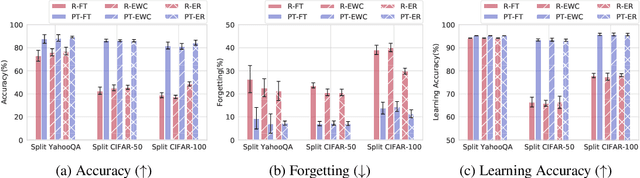
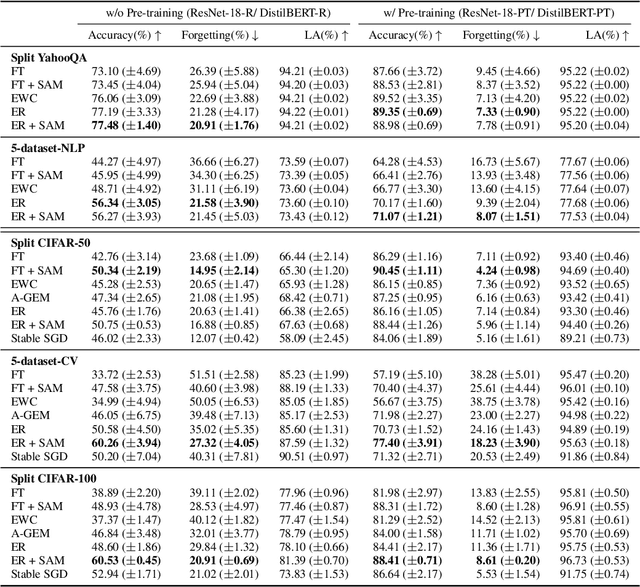
The lifelong learning paradigm in machine learning is an attractive alternative to the more prominent isolated learning scheme not only due to its resemblance to biological learning, but also its potential to reduce energy waste by obviating excessive model re-training. A key challenge to this paradigm is the phenomenon of catastrophic forgetting. With the increasing popularity and success of pre-trained models in machine learning, we pose the question: What role does pre-training play in lifelong learning, specifically with respect to catastrophic forgetting? We investigate existing methods in the context of large, pre-trained models and evaluate their performance on a variety of text and image classification tasks, including a large-scale study using a novel dataset of 15 diverse NLP tasks. Across all settings, we observe that generic pre-training implicitly alleviates the effects of catastrophic forgetting when learning multiple tasks sequentially compared to randomly initialized models. We then further investigate why pre-training alleviates forgetting in this setting. We study this phenomenon by analyzing the loss landscape, finding that pre-trained weights appear to ease forgetting by leading to wider minima. Based on this insight, we propose jointly optimizing for current task loss and loss basin sharpness in order to explicitly encourage wider basins during sequential fine-tuning. We show that this optimization approach leads to performance comparable to the state-of-the-art in task-sequential continual learning across multiple settings, without retaining a memory that scales in size with the number of tasks.
Disentangling 3D Prototypical Networks For Few-Shot Concept Learning
Nov 06, 2020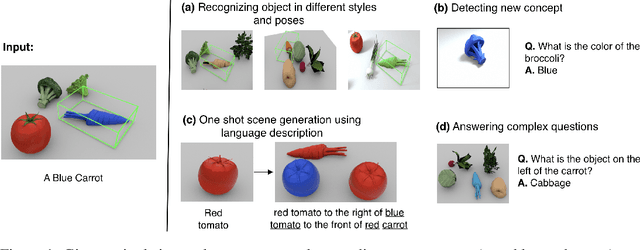
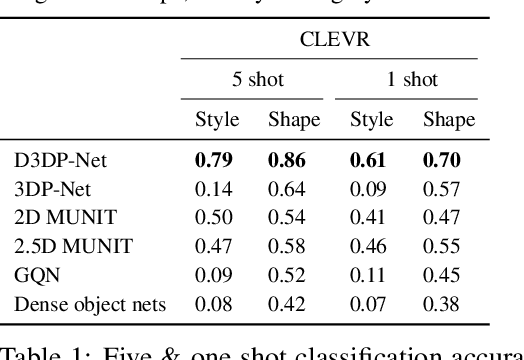
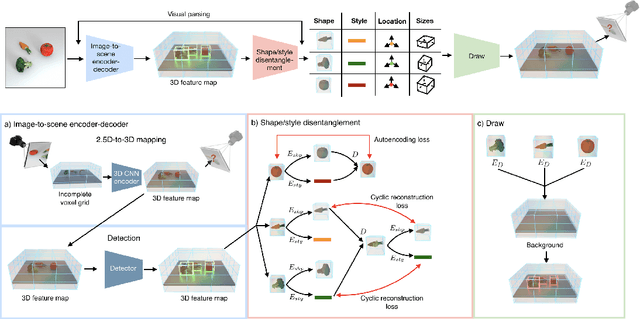
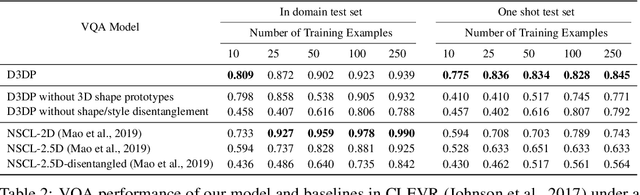
We present neural architectures that disentangle RGB-D images into objects' shapes and styles and a map of the background scene, and explore their applications for few-shot 3D object detection and few-shot concept classification. Our networks incorporate architectural biases that reflect the image formation process, 3D geometry of the world scene, and shape-style interplay. They are trained end-to-end self-supervised by predicting views in static scenes, alongside a small number of 3D object boxes. Objects and scenes are represented in terms of 3D feature grids in the bottleneck of the network. We show that the proposed 3D neural representations are compositional: they can generate novel 3D scene feature maps by mixing object shapes and styles, resizing and adding the resulting object 3D feature maps over background scene feature maps. We show that classifiers for object categories, color, materials, and spatial relationships trained over the disentangled 3D feature sub-spaces generalize better with dramatically fewer examples than the current state-of-the-art, and enable a visual question answering system that uses them as its modules to generalize one-shot to novel objects in the scene.
Towards modular and programmable architecture search
Sep 30, 2019
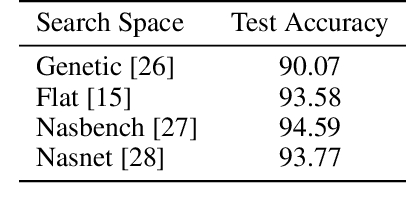

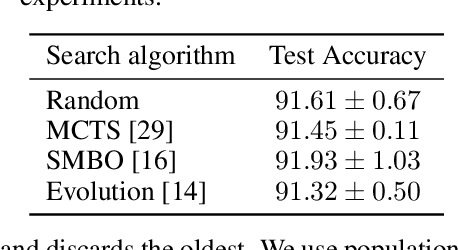
Neural architecture search methods are able to find high performance deep learning architectures with minimal effort from an expert. However, current systems focus on specific use-cases (e.g. convolutional image classifiers and recurrent language models), making them unsuitable for general use-cases that an expert might wish to write. Hyperparameter optimization systems are general-purpose but lack the constructs needed for easy application to architecture search. In this work, we propose a formal language for encoding search spaces over general computational graphs. The language constructs allow us to write modular, composable, and reusable search space encodings and to reason about search space design. We use our language to encode search spaces from the architecture search literature. The language allows us to decouple the implementations of the search space and the search algorithm, allowing us to expose search spaces to search algorithms through a consistent interface. Our experiments show the ease with which we can experiment with different combinations of search spaces and search algorithms without having to implement each combination from scratch. We release an implementation of our language with this paper.