 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Datasets and Market Environments for Financial Reinforcement Learning
Apr 25, 2023



The financial market is a particularly challenging playground for deep reinforcement learning due to its unique feature of dynamic datasets. Building high-quality market environments for training financial reinforcement learning (FinRL) agents is difficult due to major factors such as the low signal-to-noise ratio of financial data, survivorship bias of historical data, and model overfitting. In this paper, we present FinRL-Meta, a data-centric and openly accessible library that processes dynamic datasets from real-world markets into gym-style market environments and has been actively maintained by the AI4Finance community. First, following a DataOps paradigm, we provide hundreds of market environments through an automatic data curation pipeline. Second, we provide homegrown examples and reproduce popular research papers as stepping stones for users to design new trading strategies. We also deploy the library on cloud platforms so that users can visualize their own results and assess the relative performance via community-wise competitions. Third, we provide dozens of Jupyter/Python demos organized into a curriculum and a documentation website to serve the rapidly growing community. The open-source codes for the data curation pipeline are available at https://github.com/AI4Finance-Foundation/FinRL-Meta
Interactive System-wise Anomaly Detection
Apr 21, 2023



Anomaly detection, where data instances are discovered containing feature patterns different from the majority, plays a fundamental role in various applications. However, it is challenging for existing methods to handle the scenarios where the instances are systems whose characteristics are not readily observed as data. Appropriate interactions are needed to interact with the systems and identify those with abnormal responses. Detecting system-wise anomalies is a challenging task due to several reasons including: how to formally define the system-wise anomaly detection problem; how to find the effective activation signal for interacting with systems to progressively collect the data and learn the detector; how to guarantee stable training in such a non-stationary scenario with real-time interactions? To address the challenges, we propose InterSAD (Interactive System-wise Anomaly Detection). Specifically, first, we adopt Markov decision process to model the interactive systems, and define anomalous systems as anomalous transition and anomalous reward systems. Then, we develop an end-to-end approach which includes an encoder-decoder module that learns system embeddings, and a policy network to generate effective activation for separating embeddings of normal and anomaly systems. Finally, we design a training method to stabilize the learning process, which includes a replay buffer to store historical interaction data and allow them to be re-sampled. Experiments on two benchmark environments, including identifying the anomalous robotic systems and detecting user data poisoning in recommendation models, demonstrate the superiority of InterSAD compared with state-of-the-art baselines methods.
Data-centric Artificial Intelligence: A Survey
Apr 02, 2023Artificial Intelligence (AI) is making a profound impact in almost every domain. A vital enabler of its great success is the availability of abundant and high-quality data for building machine learning models. Recently, the role of data in AI has been significantly magnified, giving rise to the emerging concept of data-centric AI. The attention of researchers and practitioners has gradually shifted from advancing model design to enhancing the quality and quantity of the data. In this survey, we discuss the necessity of data-centric AI, followed by a holistic view of three general data-centric goals (training data development, inference data development, and data maintenance) and the representative methods. We also organize the existing literature from automation and collaboration perspectives, discuss the challenges, and tabulate the benchmarks for various tasks. We believe this is the first comprehensive survey that provides a global view of a spectrum of tasks across various stages of the data lifecycle. We hope it can help the readers efficiently grasp a broad picture of this field, and equip them with the techniques and further research ideas to systematically engineer data for building AI systems. A companion list of data-centric AI resources will be regularly updated on https://github.com/daochenzha/data-centric-AI
Towards Personalized Preprocessing Pipeline Search
Feb 28, 2023



Feature preprocessing, which transforms raw input features into numerical representations, is a crucial step in automated machine learning (AutoML) systems. However, the existing systems often have a very small search space for feature preprocessing with the same preprocessing pipeline applied to all the numerical features. This may result in sub-optimal performance since different datasets often have various feature characteristics, and features within a dataset may also have their own preprocessing preferences. To bridge this gap, we explore personalized preprocessing pipeline search, where the search algorithm is allowed to adopt a different preprocessing pipeline for each feature. This is a challenging task because the search space grows exponentially with more features. To tackle this challenge, we propose ClusterP3S, a novel framework for Personalized Preprocessing Pipeline Search via Clustering. The key idea is to learn feature clusters such that the search space can be significantly reduced by using the same preprocessing pipeline for the features within a cluster. To this end, we propose a hierarchical search strategy to jointly learn the clusters and search for the optimal pipelines, where the upper-level search optimizes the feature clustering to enable better pipelines built upon the clusters, and the lower-level search optimizes the pipeline given a specific cluster assignment. We instantiate this idea with a deep clustering network that is trained with reinforcement learning at the upper level, and random search at the lower level. Experiments on benchmark classification datasets demonstrate the effectiveness of enabling feature-wise preprocessing pipeline search.
Fairly Predicting Graft Failure in Liver Transplant for Organ Assigning
Feb 18, 2023Liver transplant is an essential therapy performed for severe liver diseases. The fact of scarce liver resources makes the organ assigning crucial. Model for End-stage Liver Disease (MELD) score is a widely adopted criterion when making organ distribution decisions. However, it ignores post-transplant outcomes and organ/donor features. These limitations motivate the emergence of machine learning (ML) models. Unfortunately, ML models could be unfair and trigger bias against certain groups of people. To tackle this problem, this work proposes a fair machine learning framework targeting graft failure prediction in liver transplant. Specifically, knowledge distillation is employed to handle dense and sparse features by combining the advantages of tree models and neural networks. A two-step debiasing method is tailored for this framework to enhance fairness. Experiments are conducted to analyze unfairness issues in existing models and demonstrate the superiority of our method in both prediction and fairness performance.
Data-centric AI: Perspectives and Challenges
Jan 12, 2023The role of data in building AI systems has recently been significantly magnified by the emerging concept of data-centric AI (DCAI), which advocates a fundamental shift from model advancements to ensuring data quality and reliability. Although our community has continuously invested efforts into enhancing data in different aspects, they are often isolated initiatives on specific tasks. To facilitate the collective initiative in our community and push forward DCAI, we draw a big picture and bring together three general missions: training data development, evaluation data development, and data maintenance. We provide a top-level discussion on representative DCAI tasks and share perspectives. Finally, we list open challenges to motivate future exploration.
Bring Your Own View: Graph Neural Networks for Link Prediction with Personalized Subgraph Selection
Dec 23, 2022



Graph neural networks (GNNs) have received remarkable success in link prediction (GNNLP) tasks. Existing efforts first predefine the subgraph for the whole dataset and then apply GNNs to encode edge representations by leveraging the neighborhood structure induced by the fixed subgraph. The prominence of GNNLP methods significantly relies on the adhoc subgraph. Since node connectivity in real-world graphs is complex, one shared subgraph is limited for all edges. Thus, the choices of subgraphs should be personalized to different edges. However, performing personalized subgraph selection is nontrivial since the potential selection space grows exponentially to the scale of edges. Besides, the inference edges are not available during training in link prediction scenarios, so the selection process needs to be inductive. To bridge the gap, we introduce a Personalized Subgraph Selector (PS2) as a plug-and-play framework to automatically, personally, and inductively identify optimal subgraphs for different edges when performing GNNLP. PS2 is instantiated as a bi-level optimization problem that can be efficiently solved differently. Coupling GNNLP models with PS2, we suggest a brand-new angle towards GNNLP training: by first identifying the optimal subgraphs for edges; and then focusing on training the inference model by using the sampled subgraphs. Comprehensive experiments endorse the effectiveness of our proposed method across various GNNLP backbones (GCN, GraphSage, NGCF, LightGCN, and SEAL) and diverse benchmarks (Planetoid, OGB, and Recommendation datasets). Our code is publicly available at \url{https://github.com/qiaoyu-tan/PS2}
SurCo: Learning Linear Surrogates For Combinatorial Nonlinear Optimization Problems
Oct 22, 2022



Optimization problems with expensive nonlinear cost functions and combinatorial constraints appear in many real-world applications, but remain challenging to solve efficiently. Existing combinatorial solvers like Mixed Integer Linear Programming can be fast in practice but cannot readily optimize nonlinear cost functions, while general nonlinear optimizers like gradient descent often do not handle complex combinatorial structures, may require many queries of the cost function, and are prone to local optima. To bridge this gap, we propose SurCo that learns linear Surrogate costs which can be used by existing Combinatorial solvers to output good solutions to the original nonlinear combinatorial optimization problem, combining the flexibility of gradient-based methods with the structure of linear combinatorial optimization. We learn these linear surrogates end-to-end with the nonlinear loss by differentiating through the linear surrogate solver. Three variants of SurCo are proposed: SurCo-zero operates on individual nonlinear problems, SurCo-prior trains a linear surrogate predictor on distributions of problems, and SurCo-hybrid uses a model trained offline to warm start online solving for SurCo-zero. We analyze our method theoretically and empirically, showing smooth convergence and improved performance. Experiments show that compared to state-of-the-art approaches and expert-designed heuristics, SurCo obtains lower cost solutions with comparable or faster solve time for two realworld industry-level applications: embedding table sharding and inverse photonic design.
RSC: Accelerating Graph Neural Networks Training via Randomized Sparse Computations
Oct 19, 2022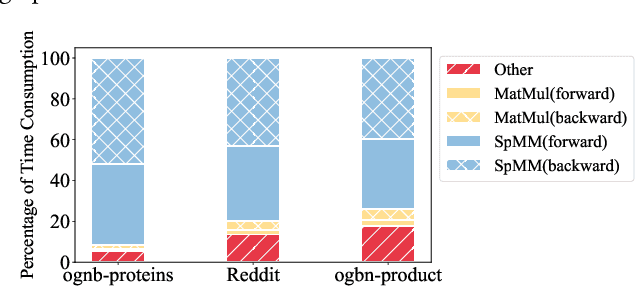

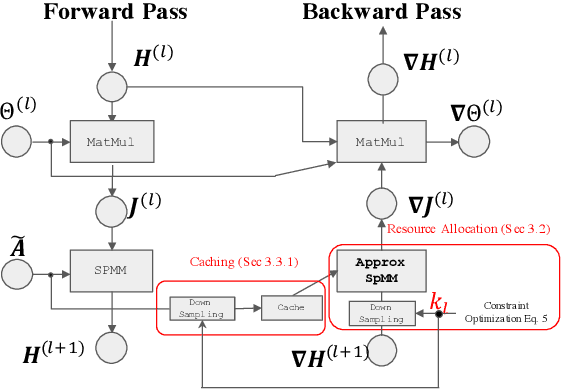
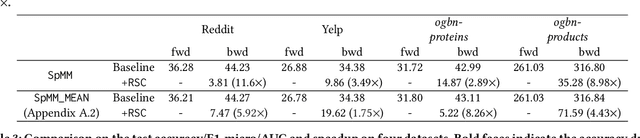
The training of graph neural networks (GNNs) is extremely time consuming because sparse graph-based operations are hard to be accelerated by hardware. Prior art explores trading off the computational precision to reduce the time complexity via sampling-based approximation. Based on the idea, previous works successfully accelerate the dense matrix based operations (e.g., convolution and linear) with negligible accuracy drop. However, unlike dense matrices, sparse matrices are stored in the irregular data format such that each row/column may have different number of non-zero entries. Thus, compared to the dense counterpart, approximating sparse operations has two unique challenges (1) we cannot directly control the efficiency of approximated sparse operation since the computation is only executed on non-zero entries; (2) sub-sampling sparse matrices is much more inefficient due to the irregular data format. To address the issues, our key idea is to control the accuracy-efficiency trade off by optimizing computation resource allocation layer-wisely and epoch-wisely. Specifically, for the first challenge, we customize the computation resource to different sparse operations, while limit the total used resource below a certain budget. For the second challenge, we cache previous sampled sparse matrices to reduce the epoch-wise sampling overhead. Finally, we propose a switching mechanisms to improve the generalization of GNNs trained with approximated operations. To this end, we propose Randomized Sparse Computation, which for the first time demonstrate the potential of training GNNs with approximated operations. In practice, rsc can achieve up to $11.6\times$ speedup for a single sparse operation and a $1.6\times$ end-to-end wall-clock time speedup with negligible accuracy drop.
DreamShard: Generalizable Embedding Table Placement for Recommender Systems
Oct 05, 2022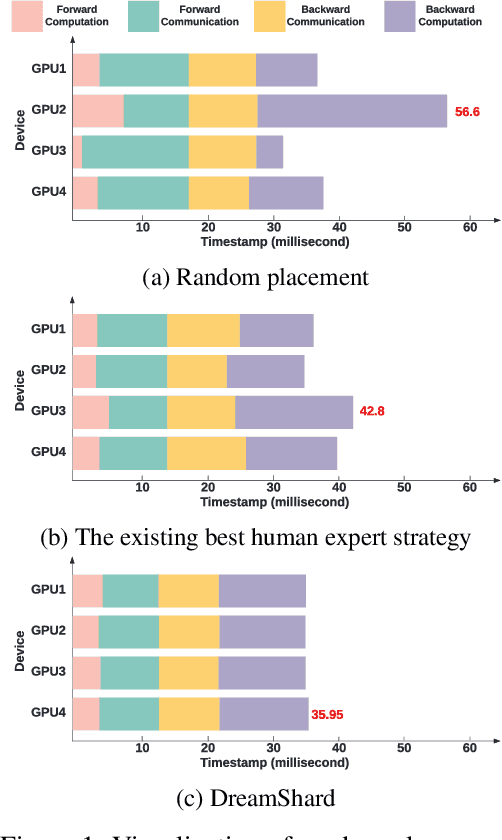
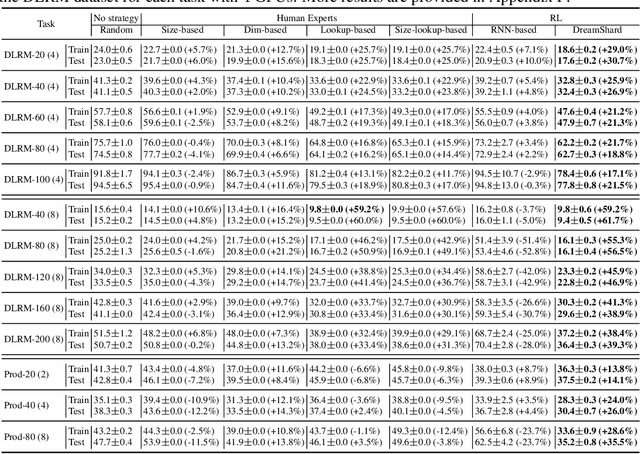
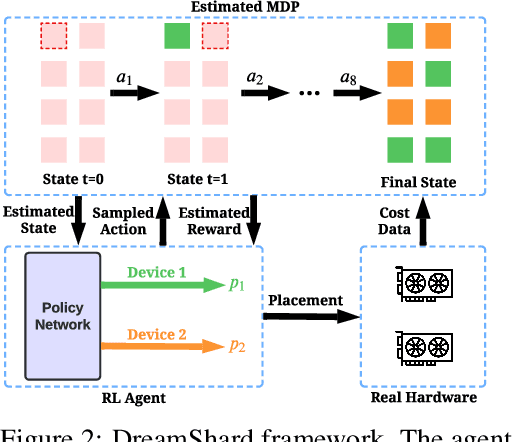
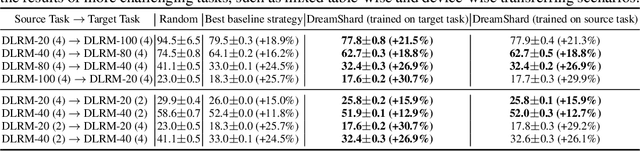
We study embedding table placement for distributed recommender systems, which aims to partition and place the tables on multiple hardware devices (e.g., GPUs) to balance the computation and communication costs. Although prior work has explored learning-based approaches for the device placement of computational graphs, embedding table placement remains to be a challenging problem because of 1) the operation fusion of embedding tables, and 2) the generalizability requirement on unseen placement tasks with different numbers of tables and/or devices. To this end, we present DreamShard, a reinforcement learning (RL) approach for embedding table placement. DreamShard achieves the reasoning of operation fusion and generalizability with 1) a cost network to directly predict the costs of the fused operation, and 2) a policy network that is efficiently trained on an estimated Markov decision process (MDP) without real GPU execution, where the states and the rewards are estimated with the cost network. Equipped with sum and max representation reductions, the two networks can directly generalize to any unseen tasks with different numbers of tables and/or devices without fine-tuning. Extensive experiments show that DreamShard substantially outperforms the existing human expert and RNN-based strategies with up to 19% speedup over the strongest baseline on large-scale synthetic tables and our production tables. The code is available at https://github.com/daochenzha/dreamshard