 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
May 26, 2022
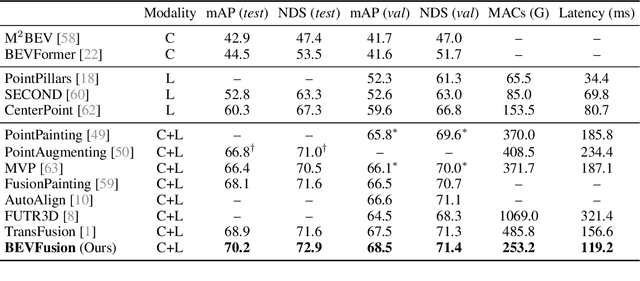
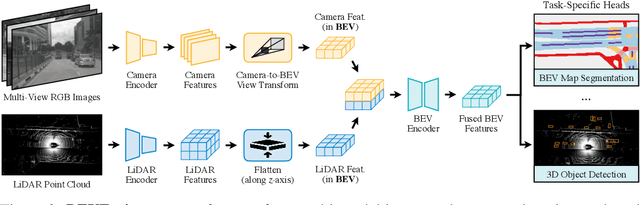
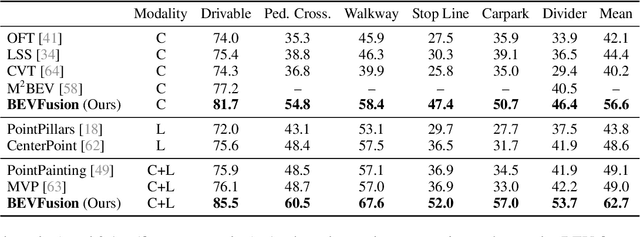
Multi-sensor fusion is essential for an accurate and reliable autonomous driving system. Recent approaches are based on point-level fusion: augmenting the LiDAR point cloud with camera features. However, the camera-to-LiDAR projection throws away the semantic density of camera features, hindering the effectiveness of such methods, especially for semantic-oriented tasks (such as 3D scene segmentation). In this paper, we break this deeply-rooted convention with BEVFusion, an efficient and generic multi-task multi-sensor fusion framework. It unifies multi-modal features in the shared bird's-eye view (BEV) representation space, which nicely preserves both geometric and semantic information. To achieve this, we diagnose and lift key efficiency bottlenecks in the view transformation with optimized BEV pooling, reducing latency by more than 40x. BEVFusion is fundamentally task-agnostic and seamlessly supports different 3D perception tasks with almost no architectural changes. It establishes the new state of the art on nuScenes, achieving 1.3% higher mAP and NDS on 3D object detection and 13.6% higher mIoU on BEV map segmentation, with 1.9x lower computation cost.
Neighborhood Mixup Experience Replay: Local Convex Interpolation for Improved Sample Efficiency in Continuous Control Tasks
May 18, 2022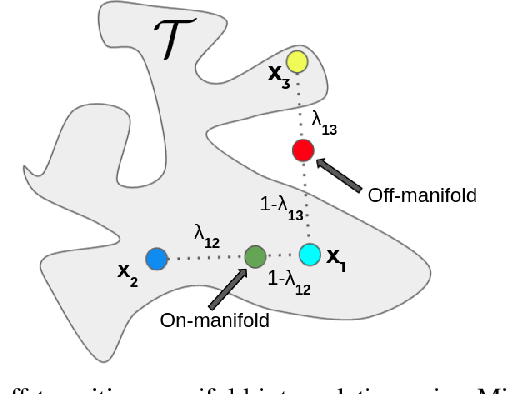
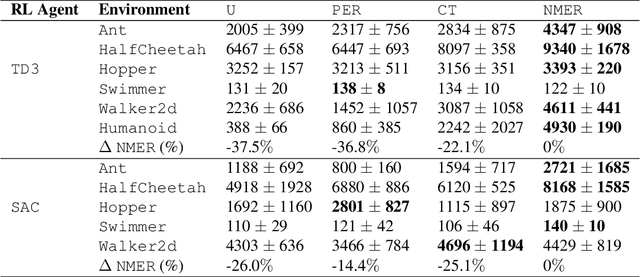
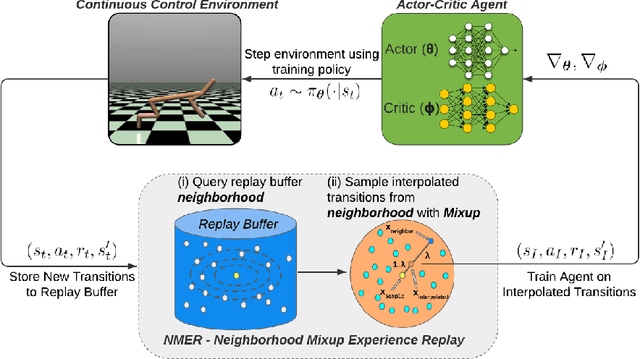

Experience replay plays a crucial role in improving the sample efficiency of deep reinforcement learning agents. Recent advances in experience replay propose using Mixup (Zhang et al., 2018) to further improve sample efficiency via synthetic sample generation. We build upon this technique with Neighborhood Mixup Experience Replay (NMER), a geometrically-grounded replay buffer that interpolates transitions with their closest neighbors in state-action space. NMER preserves a locally linear approximation of the transition manifold by only applying Mixup between transitions with vicinal state-action features. Under NMER, a given transition's set of state action neighbors is dynamic and episode agnostic, in turn encouraging greater policy generalizability via inter-episode interpolation. We combine our approach with recent off-policy deep reinforcement learning algorithms and evaluate on continuous control environments. We observe that NMER improves sample efficiency by an average 94% (TD3) and 29% (SAC) over baseline replay buffers, enabling agents to effectively recombine previous experiences and learn from limited data.
End-to-End Sensitivity-Based Filter Pruning
Apr 15, 2022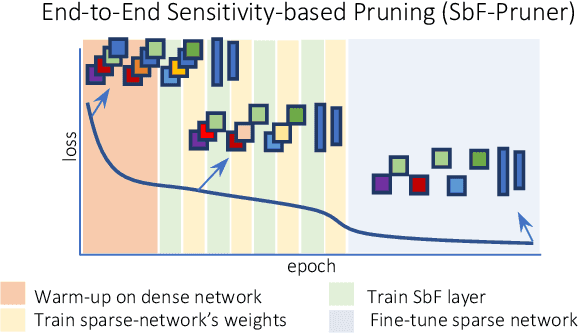
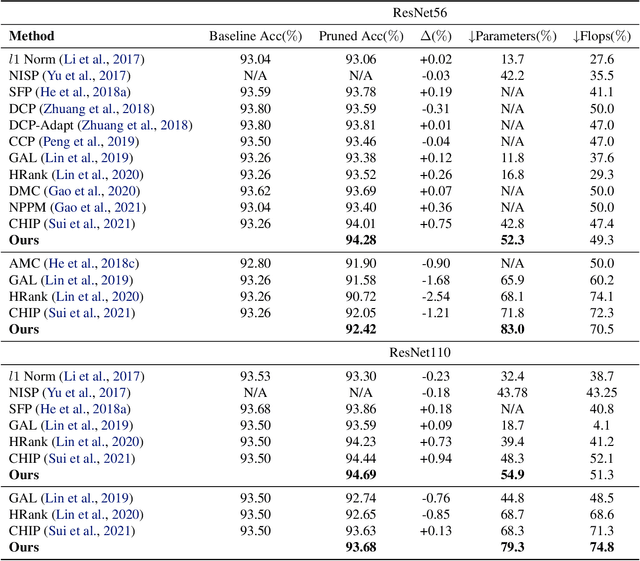
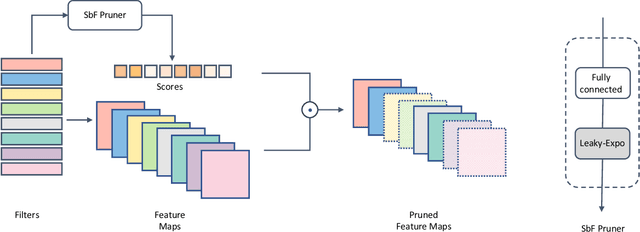
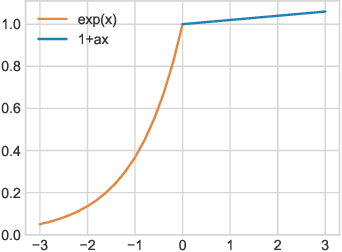
In this paper, we present a novel sensitivity-based filter pruning algorithm (SbF-Pruner) to learn the importance scores of filters of each layer end-to-end. Our method learns the scores from the filter weights, enabling it to account for the correlations between the filters of each layer. Moreover, by training the pruning scores of all layers simultaneously our method can account for layer interdependencies, which is essential to find a performant sparse sub-network. Our proposed method can train and generate a pruned network from scratch in a straightforward, one-stage training process without requiring a pretrained network. Ultimately, we do not need layer-specific hyperparameters and pre-defined layer budgets, since SbF-Pruner can implicitly determine the appropriate number of channels in each layer. Our experimental results on different network architectures suggest that SbF-Pruner outperforms advanced pruning methods. Notably, on CIFAR-10, without requiring a pretrained baseline network, we obtain 1.02% and 1.19% accuracy gain on ResNet56 and ResNet110, compared to the baseline reported for state-of-the-art pruning algorithms. This is while SbF-Pruner reduces parameter-count by 52.3% (for ResNet56) and 54% (for ResNet101), which is better than the state-of-the-art pruning algorithms with a high margin of 9.5% and 6.6%.
Revisiting the Adversarial Robustness-Accuracy Tradeoff in Robot Learning
Apr 15, 2022


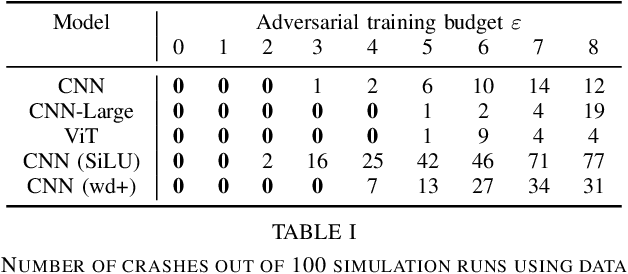
Adversarial training (i.e., training on adversarially perturbed input data) is a well-studied method for making neural networks robust to potential adversarial attacks during inference. However, the improved robustness does not come for free but rather is accompanied by a decrease in overall model accuracy and performance. Recent work has shown that, in practical robot learning applications, the effects of adversarial training do not pose a fair trade-off but inflict a net loss when measured in holistic robot performance. This work revisits the robustness-accuracy trade-off in robot learning by systematically analyzing if recent advances in robust training methods and theory in conjunction with adversarial robot learning can make adversarial training suitable for real-world robot applications. We evaluate a wide variety of robot learning tasks ranging from autonomous driving in a high-fidelity environment amenable to sim-to-real deployment, to mobile robot gesture recognition. Our results demonstrate that, while these techniques make incremental improvements on the trade-off on a relative scale, the negative side-effects caused by adversarial training still outweigh the improvements by an order of magnitude. We conclude that more substantial advances in robust learning methods are necessary before they can benefit robot learning tasks in practice.
Deep Interactive Motion Prediction and Planning: Playing Games with Motion Prediction Models
Apr 05, 2022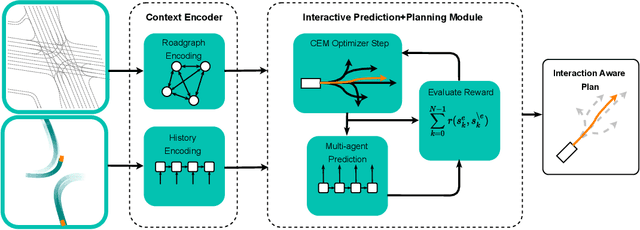
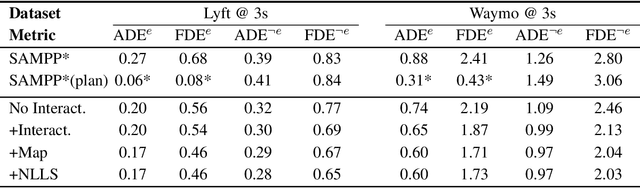

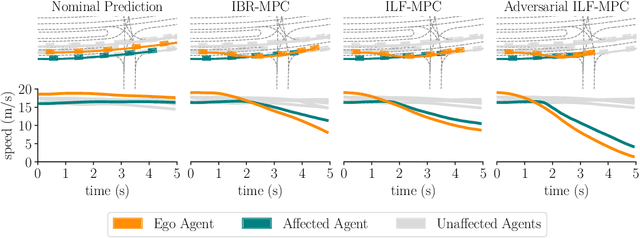
In most classical Autonomous Vehicle (AV) stacks, the prediction and planning layers are separated, limiting the planner to react to predictions that are not informed by the planned trajectory of the AV. This work presents a module that tightly couples these layers via a game-theoretic Model Predictive Controller (MPC) that uses a novel interactive multi-agent neural network policy as part of its predictive model. In our setting, the MPC planner considers all the surrounding agents by informing the multi-agent policy with the planned state sequence. Fundamental to the success of our method is the design of a novel multi-agent policy network that can steer a vehicle given the state of the surrounding agents and the map information. The policy network is trained implicitly with ground-truth observation data using backpropagation through time and a differentiable dynamics model to roll out the trajectory forward in time. Finally, we show that our multi-agent policy network learns to drive while interacting with the environment, and, when combined with the game-theoretic MPC planner, can successfully generate interactive behaviors.
Control Barrier Functions for Systems with Multiple Control Inputs
Mar 15, 2022
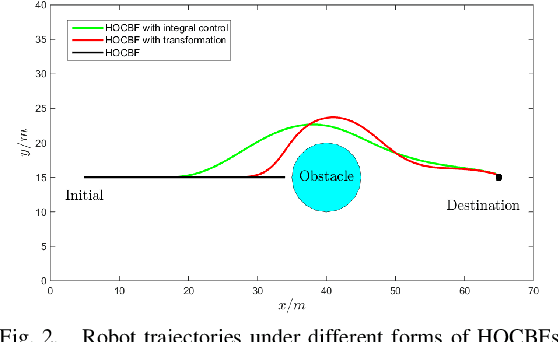
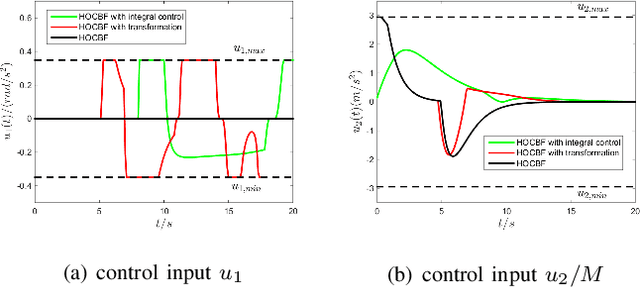
Control Barrier Functions (CBFs) are becoming popular tools in guaranteeing safety for nonlinear systems and constraints, and they can reduce a constrained optimal control problem into a sequence of Quadratic Programs (QPs) for affine control systems. The recently proposed High Order Control Barrier Functions (HOCBFs) work for arbitrary relative degree constraints. One of the challenges in a HOCBF is to address the relative degree problem when a system has multiple control inputs, i.e., the relative degree could be defined with respect to different components of the control vector. This paper proposes two methods for HOCBFs to deal with systems with multiple control inputs: a general integral control method and a method which is simpler but limited to specific classes of physical systems. When control bounds are involved, the feasibility of the above mentioned QPs can also be significantly improved with the proposed methods. We illustrate our approaches on a unicyle model with two control inputs, and compare the two proposed methods to demonstrate their effectiveness and performance.
Differentiable Control Barrier Functions for Vision-based End-to-End Autonomous Driving
Mar 04, 2022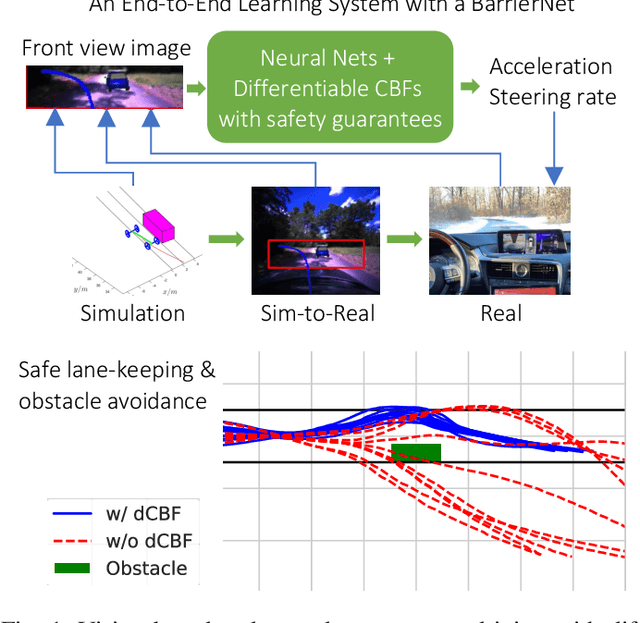

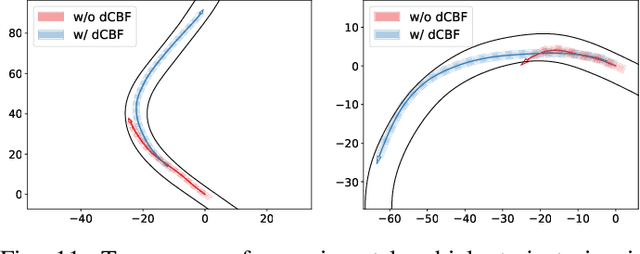
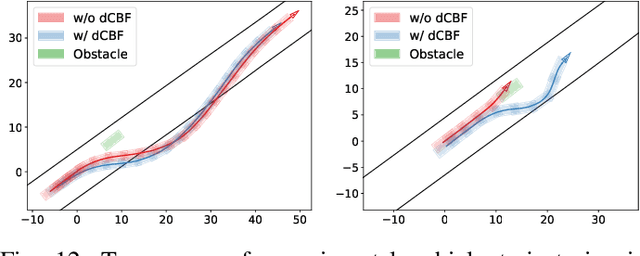
Guaranteeing safety of perception-based learning systems is challenging due to the absence of ground-truth state information unlike in state-aware control scenarios. In this paper, we introduce a safety guaranteed learning framework for vision-based end-to-end autonomous driving. To this end, we design a learning system equipped with differentiable control barrier functions (dCBFs) that is trained end-to-end by gradient descent. Our models are composed of conventional neural network architectures and dCBFs. They are interpretable at scale, achieve great test performance under limited training data, and are safety guaranteed in a series of autonomous driving scenarios such as lane keeping and obstacle avoidance. We evaluated our framework in a sim-to-real environment, and tested on a real autonomous car, achieving safe lane following and obstacle avoidance via Augmented Reality (AR) and real parked vehicles.
Concept Graph Neural Networks for Surgical Video Understanding
Feb 27, 2022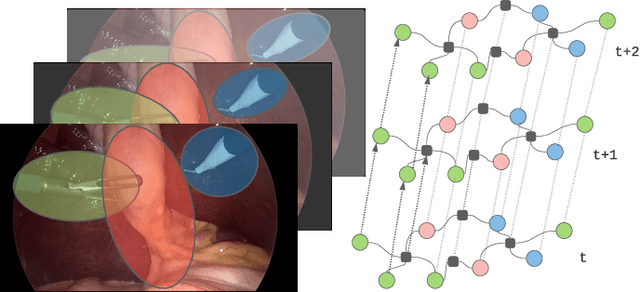
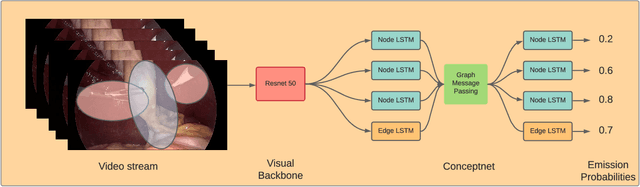
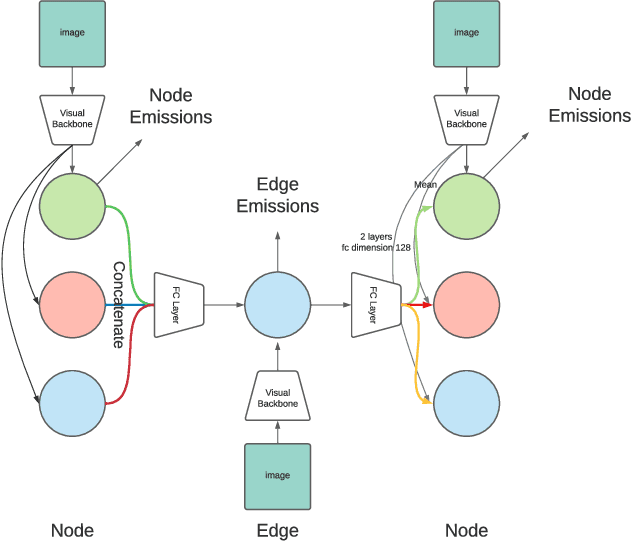
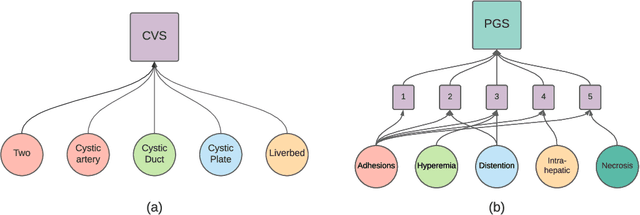
We constantly integrate our knowledge and understanding of the world to enhance our interpretation of what we see. This ability is crucial in application domains which entail reasoning about multiple entities and concepts, such as AI-augmented surgery. In this paper, we propose a novel way of integrating conceptual knowledge into temporal analysis tasks via temporal concept graph networks. In the proposed networks, a global knowledge graph is incorporated into the temporal analysis of surgical instances, learning the meaning of concepts and relations as they apply to the data. We demonstrate our results in surgical video data for tasks such as verification of critical view of safety, as well as estimation of Parkland grading scale. The results show that our method improves the recognition and detection of complex benchmarks as well as enables other analytic applications of interest.
Learning Interactive Driving Policies via Data-driven Simulation
Nov 23, 2021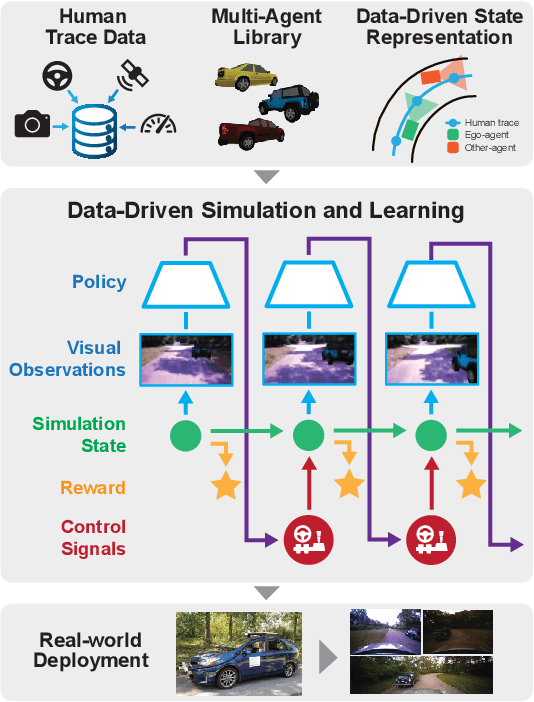

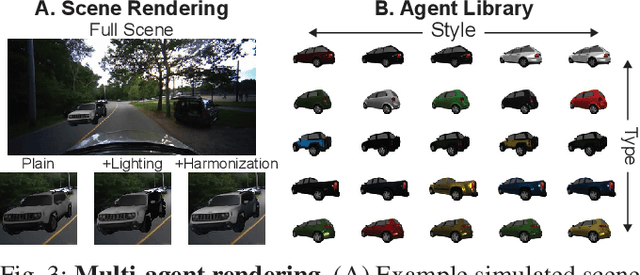
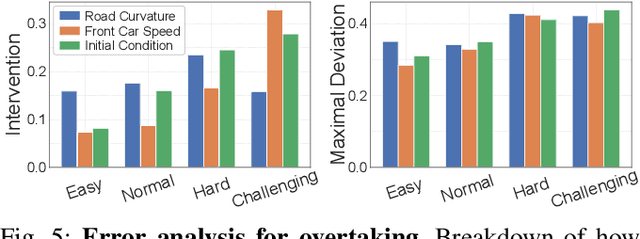
Data-driven simulators promise high data-efficiency for driving policy learning. When used for modelling interactions, this data-efficiency becomes a bottleneck: Small underlying datasets often lack interesting and challenging edge cases for learning interactive driving. We address this challenge by proposing a simulation method that uses in-painted ado vehicles for learning robust driving policies. Thus, our approach can be used to learn policies that involve multi-agent interactions and allows for training via state-of-the-art policy learning methods. We evaluate the approach for learning standard interaction scenarios in driving. In extensive experiments, our work demonstrates that the resulting policies can be directly transferred to a full-scale autonomous vehicle without making use of any traditional sim-to-real transfer techniques such as domain randomization.
VISTA 2.0: An Open, Data-driven Simulator for Multimodal Sensing and Policy Learning for Autonomous Vehicles
Nov 23, 2021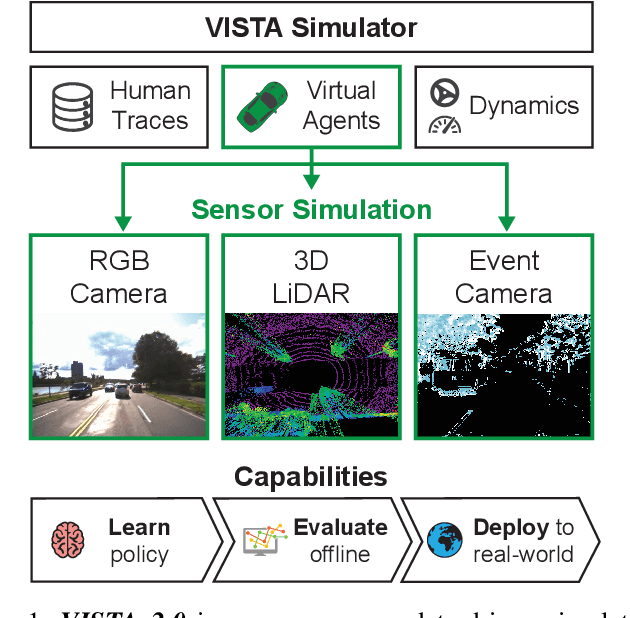
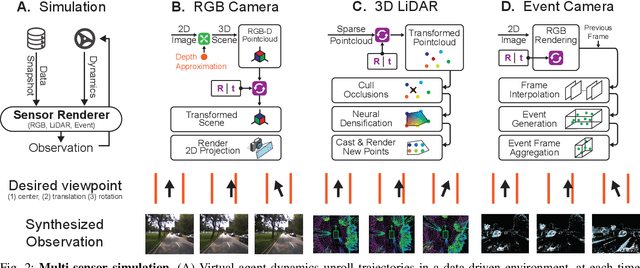
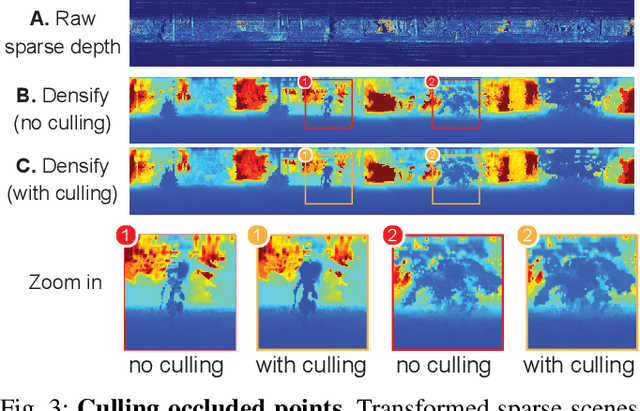

Simulation has the potential to transform the development of robust algorithms for mobile agents deployed in safety-critical scenarios. However, the poor photorealism and lack of diverse sensor modalities of existing simulation engines remain key hurdles towards realizing this potential. Here, we present VISTA, an open source, data-driven simulator that integrates multiple types of sensors for autonomous vehicles. Using high fidelity, real-world datasets, VISTA represents and simulates RGB cameras, 3D LiDAR, and event-based cameras, enabling the rapid generation of novel viewpoints in simulation and thereby enriching the data available for policy learning with corner cases that are difficult to capture in the physical world. Using VISTA, we demonstrate the ability to train and test perception-to-control policies across each of the sensor types and showcase the power of this approach via deployment on a full scale autonomous vehicle. The policies learned in VISTA exhibit sim-to-real transfer without modification and greater robustness than those trained exclusively on real-world data.