 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadAgent: A tool-using AI agent for stepwise interpretation of chest computed tomography
Apr 16, 2026Vision-language models (VLM) have markedly advanced AI-driven interpretation and reporting of complex medical imaging, such as computed tomography (CT). Yet, existing methods largely relegate clinicians to passive observers of final outputs, offering no interpretable reasoning trace for them to inspect, validate, or refine. To address this, we introduce RadAgent, a tool-using AI agent that generates CT reports through a stepwise and interpretable process. Each resulting report is accompanied by a fully inspectable trace of intermediate decisions and tool interactions, allowing clinicians to examine how the reported findings are derived. In our experiments, we observe that RadAgent improves Chest CT report generation over its 3D VLM counterpart, CT-Chat, across three dimensions. Clinical accuracy improves by 6.0 points (36.4% relative) in macro-F1 and 5.4 points (19.6% relative) in micro-F1. Robustness under adversarial conditions improves by 24.7 points (41.9% relative). Furthermore, RadAgent achieves 37.0% in faithfulness, a new capability entirely absent in its 3D VLM counterpart. By structuring the interpretation of chest CT as an explicit, tool-augmented and iterative reasoning trace, RadAgent brings us closer toward transparent and reliable AI for radiology.
A Reasoning-Enabled Vision-Language Foundation Model for Chest X-ray Interpretation
Apr 01, 2026Chest X-rays (CXRs) are among the most frequently performed imaging examinations worldwide, yet rising imaging volumes increase radiologist workload and the risk of diagnostic errors. Although artificial intelligence (AI) systems have shown promise for CXR interpretation, most generate only final predictions, without making explicit how visual evidence is translated into radiographic findings and diagnostic predictions. We present CheXOne, a reasoning-enabled vision-language model for CXR interpretation. CheXOne jointly generates diagnostic predictions and explicit, clinically grounded reasoning traces that connect visual evidence, radiographic findings, and these predictions. The model is trained on 14.7 million instruction and reasoning samples curated from 30 public datasets spanning 36 CXR interpretation tasks, using a two-stage framework that combines instruction tuning with reinforcement learning to improve reasoning quality. We evaluate CheXOne in zero-shot settings across visual question answering, report generation, visual grounding and reasoning assessment, covering 17 evaluation settings. CheXOne outperforms existing medical and general-domain foundation models and achieves strong performance on independent public benchmarks. A clinical reader study demonstrates that CheXOne-drafted reports are comparable to or better than resident-written reports in 55% of cases, while effectively addressing clinical indications and enhancing both report writing and CXR interpretation efficiency. Further analyses involving radiologists reveal that the generated reasoning traces show high clinical factuality and provide causal support for the final predictions, offering a plausible explanation for the performance gains. These results suggest that explicit reasoning can improve model performance, interpretability and clinical utility in AI-assisted CXR interpretation.
Activation Matters: Test-time Activated Negative Labels for OOD Detection with Vision-Language Models
Mar 26, 2026Out-of-distribution (OOD) detection aims to identify samples that deviate from in-distribution (ID). One popular pipeline addresses this by introducing negative labels distant from ID classes and detecting OOD based on their distance to these labels. However, such labels may present poor activation on OOD samples, failing to capture the OOD characteristics. To address this, we propose \underline{T}est-time \underline{A}ctivated \underline{N}egative \underline{L}abels (TANL) by dynamically evaluating activation levels across the corpus dataset and mining candidate labels with high activation responses during the testing process. Specifically, TANL identifies high-confidence test images online and accumulates their assignment probabilities over the corpus to construct a label activation metric. Such a metric leverages historical test samples to adaptively align with the test distribution, enabling the selection of distribution-adaptive activated negative labels. By further exploring the activation information within the current testing batch, we introduce a more fine-grained, batch-adaptive variant. To fully utilize label activation knowledge, we propose an activation-aware score function that emphasizes negative labels with stronger activations, boosting performance and enhancing its robustness to the label number. Our TANL is training-free, test-efficient, and grounded in theoretical justification. Experiments on diverse backbones and wide task settings validate its effectiveness. Notably, on the large-scale ImageNet benchmark, TANL significantly reduces the FPR95 from 17.5\% to 9.8\%. Codes are available at \href{https://github.com/YBZh/OpenOOD-VLM}{YBZh/OpenOOD-VLM}.
Learning Generalizable 3D Medical Image Representations from Mask-Guided Self-Supervision
Mar 14, 2026Foundation models have transformed vision and language by learning general-purpose representations from large-scale unlabeled data, yet 3D medical imaging lacks analogous approaches. Existing self-supervised methods rely on low-level reconstruction or contrastive objectives that fail to capture the anatomical semantics critical for medical image analysis, limiting transfer to downstream tasks. We present MASS (MAsk-guided Self-Supervised learning), which treats in-context segmentation as the pretext task for learning general-purpose medical imaging representations. MASS's key insight is that automatically generated class-agnostic masks provide sufficient structural supervision for learning semantically rich representations. By training on thousands of diverse mask proposals spanning anatomical structures and pathological findings, MASS learns what semantically defines medical structures: the holistic combination of appearance, shape, spatial context, and anatomical relationships. We demonstrate effectiveness across data regimes: from small-scale pretraining on individual datasets (20-200 scans) to large-scale multi-modal pretraining on 5K CT, MRI, and PET volumes, all without annotations. MASS demonstrates: (i) few-shot segmentation on novel structures, (ii) matching full supervision with only 20-40\% labeled data while outperforming self-supervised baselines by over 20 in Dice score in low-data regimes, and (iii) frozen-encoder classification on unseen pathologies that matches full supervised training with thousands of samples. Mask-guided self-supervised pretraining captures broadly generalizable knowledge, opening a path toward 3D medical imaging foundation models without expert annotations. Code is available: https://github.com/Stanford-AIMI/MASS.
A data- and compute-efficient chest X-ray foundation model beyond aggressive scaling
Feb 26, 2026Foundation models for medical imaging are typically pretrained on increasingly large datasets, following a "scale-at-all-costs" paradigm. However, this strategy faces two critical challenges: large-scale medical datasets often contain substantial redundancy and severe class imbalance that bias representation learning toward over-represented patterns, and indiscriminate training regardless of heterogeneity in data quality incurs considerable computational inefficiency. Here we demonstrate that active, principled data curation during pretraining can serve as a viable, cost-effective alternative to brute-force dataset enlargement. We introduce CheXficient, a chest X-ray (CXR) foundation model that selectively prioritizes informative training samples. CheXficient is pretrained on only 22.7% of 1,235,004 paired CXR images and reports while consuming under 27.3% of the total compute budget, yet achieving comparable or superior performance to its full-data counterpart and other large-scale pretrained models. We assess CheXficient across 20 individual benchmarks spanning 5 task types, including non-adapted off-the-shelf evaluations (zero-shot findings classification and crossmodal retrieval) and adapted downstream tasks (disease prediction, semantic segmentation, and radiology report generation). Further analyses show that CheXficient systematically prioritizes under-represented training samples, improving generalizability on long-tailed or rare conditions. Overall, our work offers practical insights into the data and computation demands for efficient pretraining and downstream adaptation of medical vision-language foundation models.
Improving the Performance of Radiology Report De-identification with Large-Scale Training and Benchmarking Against Cloud Vendor Methods
Nov 06, 2025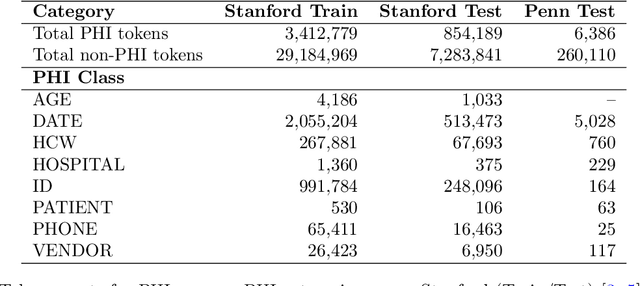

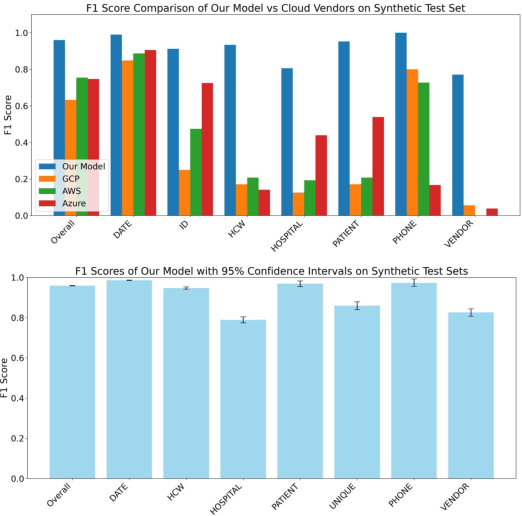
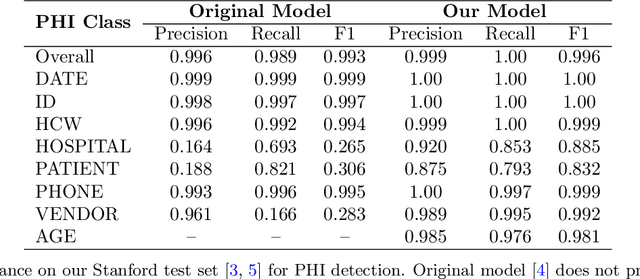
Objective: To enhance automated de-identification of radiology reports by scaling transformer-based models through extensive training datasets and benchmarking performance against commercial cloud vendor systems for protected health information (PHI) detection. Materials and Methods: In this retrospective study, we built upon a state-of-the-art, transformer-based, PHI de-identification pipeline by fine-tuning on two large annotated radiology corpora from Stanford University, encompassing chest X-ray, chest CT, abdomen/pelvis CT, and brain MR reports and introducing an additional PHI category (AGE) into the architecture. Model performance was evaluated on test sets from Stanford and the University of Pennsylvania (Penn) for token-level PHI detection. We further assessed (1) the stability of synthetic PHI generation using a "hide-in-plain-sight" method and (2) performance against commercial systems. Precision, recall, and F1 scores were computed across all PHI categories. Results: Our model achieved overall F1 scores of 0.973 on the Penn dataset and 0.996 on the Stanford dataset, outperforming or maintaining the previous state-of-the-art model performance. Synthetic PHI evaluation showed consistent detectability (overall F1: 0.959 [0.958-0.960]) across 50 independently de-identified Penn datasets. Our model outperformed all vendor systems on synthetic Penn reports (overall F1: 0.960 vs. 0.632-0.754). Discussion: Large-scale, multimodal training improved cross-institutional generalization and robustness. Synthetic PHI generation preserved data utility while ensuring privacy. Conclusion: A transformer-based de-identification model trained on diverse radiology datasets outperforms prior academic and commercial systems in PHI detection and establishes a new benchmark for secure clinical text processing.
SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning
Jun 26, 2025



Multimodal in-context learning (ICL) remains underexplored despite significant potential for domains such as medicine. Clinicians routinely encounter diverse, specialized tasks requiring adaptation from limited examples, such as drawing insights from a few relevant prior cases or considering a constrained set of differential diagnoses. While multimodal large language models (MLLMs) have shown advances in medical visual question answering (VQA), their ability to learn multimodal tasks from context is largely unknown. We introduce SMMILE, the first expert-driven multimodal ICL benchmark for medical tasks. Eleven medical experts curated problems, each including a multimodal query and multimodal in-context examples as task demonstrations. SMMILE encompasses 111 problems (517 question-image-answer triplets) covering 6 medical specialties and 13 imaging modalities. We further introduce SMMILE++, an augmented variant with 1038 permuted problems. A comprehensive evaluation of 15 MLLMs demonstrates that most models exhibit moderate to poor multimodal ICL ability in medical tasks. In open-ended evaluations, ICL contributes only 8% average improvement over zero-shot on SMMILE and 9.4% on SMMILE++. We observe a susceptibility for irrelevant in-context examples: even a single noisy or irrelevant example can degrade performance by up to 9.5%. Moreover, example ordering exhibits a recency bias, i.e., placing the most relevant example last can lead to substantial performance improvements by up to 71%. Our findings highlight critical limitations and biases in current MLLMs when learning multimodal medical tasks from context.
Automated Structured Radiology Report Generation
May 30, 2025Automated radiology report generation from chest X-ray (CXR) images has the potential to improve clinical efficiency and reduce radiologists' workload. However, most datasets, including the publicly available MIMIC-CXR and CheXpert Plus, consist entirely of free-form reports, which are inherently variable and unstructured. This variability poses challenges for both generation and evaluation: existing models struggle to produce consistent, clinically meaningful reports, and standard evaluation metrics fail to capture the nuances of radiological interpretation. To address this, we introduce Structured Radiology Report Generation (SRRG), a new task that reformulates free-text radiology reports into a standardized format, ensuring clarity, consistency, and structured clinical reporting. We create a novel dataset by restructuring reports using large language models (LLMs) following strict structured reporting desiderata. Additionally, we introduce SRR-BERT, a fine-grained disease classification model trained on 55 labels, enabling more precise and clinically informed evaluation of structured reports. To assess report quality, we propose F1-SRR-BERT, a metric that leverages SRR-BERT's hierarchical disease taxonomy to bridge the gap between free-text variability and structured clinical reporting. We validate our dataset through a reader study conducted by five board-certified radiologists and extensive benchmarking experiments.
RaVL: Discovering and Mitigating Spurious Correlations in Fine-Tuned Vision-Language Models
Nov 06, 2024



Fine-tuned vision-language models (VLMs) often capture spurious correlations between image features and textual attributes, resulting in degraded zero-shot performance at test time. Existing approaches for addressing spurious correlations (i) primarily operate at the global image-level rather than intervening directly on fine-grained image features and (ii) are predominantly designed for unimodal settings. In this work, we present RaVL, which takes a fine-grained perspective on VLM robustness by discovering and mitigating spurious correlations using local image features rather than operating at the global image level. Given a fine-tuned VLM, RaVL first discovers spurious correlations by leveraging a region-level clustering approach to identify precise image features contributing to zero-shot classification errors. Then, RaVL mitigates the identified spurious correlation with a novel region-aware loss function that enables the VLM to focus on relevant regions and ignore spurious relationships during fine-tuning. We evaluate RaVL on 654 VLMs with various model architectures, data domains, and learned spurious correlations. Our results show that RaVL accurately discovers (191% improvement over the closest baseline) and mitigates (8.2% improvement on worst-group image classification accuracy) spurious correlations. Qualitative evaluations on general-domain and medical-domain VLMs confirm our findings.
Overview of the First Shared Task on Clinical Text Generation: RRG24 and "Discharge Me!"
Sep 25, 2024



Recent developments in natural language generation have tremendous implications for healthcare. For instance, state-of-the-art systems could automate the generation of sections in clinical reports to alleviate physician workload and streamline hospital documentation. To explore these applications, we present a shared task consisting of two subtasks: (1) Radiology Report Generation (RRG24) and (2) Discharge Summary Generation ("Discharge Me!"). RRG24 involves generating the 'Findings' and 'Impression' sections of radiology reports given chest X-rays. "Discharge Me!" involves generating the 'Brief Hospital Course' and 'Discharge Instructions' sections of discharge summaries for patients admitted through the emergency department. "Discharge Me!" submissions were subsequently reviewed by a team of clinicians. Both tasks emphasize the goal of reducing clinician burnout and repetitive workloads by generating documentation. We received 201 submissions from across 8 teams for RRG24, and 211 submissions from across 16 teams for "Discharge Me!".
* ACL Proceedings. BioNLP workshop