 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contextual Bandit Approach for Learning to Plan in Environments with Probabilistic Goal Configurations
Nov 29, 2022



Object-goal navigation (Object-nav) entails searching, recognizing and navigating to a target object. Object-nav has been extensively studied by the Embodied-AI community, but most solutions are often restricted to considering static objects (e.g., television, fridge, etc.). We propose a modular framework for object-nav that is able to efficiently search indoor environments for not just static objects but also movable objects (e.g. fruits, glasses, phones, etc.) that frequently change their positions due to human intervention. Our contextual-bandit agent efficiently explores the environment by showing optimism in the face of uncertainty and learns a model of the likelihood of spotting different objects from each navigable location. The likelihoods are used as rewards in a weighted minimum latency solver to deduce a trajectory for the robot. We evaluate our algorithms in two simulated environments and a real-world setting, to demonstrate high sample efficiency and reliability.
Best of Both Worlds Model Selection
Jun 29, 2022We study the problem of model selection in bandit scenarios in the presence of nested policy classes, with the goal of obtaining simultaneous adversarial and stochastic ("best of both worlds") high-probability regret guarantees. Our approach requires that each base learner comes with a candidate regret bound that may or may not hold, while our meta algorithm plays each base learner according to a schedule that keeps the base learner's candidate regret bounds balanced until they are detected to violate their guarantees. We develop careful mis-specification tests specifically designed to blend the above model selection criterion with the ability to leverage the (potentially benign) nature of the environment. We recover the model selection guarantees of the CORRAL algorithm for adversarial environments, but with the additional benefit of achieving high probability regret bounds, specifically in the case of nested adversarial linear bandits. More importantly, our model selection results also hold simultaneously in stochastic environments under gap assumptions. These are the first theoretical results that achieve best of both world (stochastic and adversarial) guarantees while performing model selection in (linear) bandit scenarios.
Achieving Minimax Rates in Pool-Based Batch Active Learning
Feb 11, 2022We consider a batch active learning scenario where the learner adaptively issues batches of points to a labeling oracle. Sampling labels in batches is highly desirable in practice due to the smaller number of interactive rounds with the labeling oracle (often human beings). However, batch active learning typically pays the price of a reduced adaptivity, leading to suboptimal results. In this paper we propose a solution which requires a careful trade off between the informativeness of the queried points and their diversity. We theoretically investigate batch active learning in the practically relevant scenario where the unlabeled pool of data is available beforehand (pool-based active learning). We analyze a novel stage-wise greedy algorithm and show that, as a function of the label complexity, the excess risk of this algorithm operating in the realizable setting for which we prove matches the known minimax rates in standard statistical learning settings. Our results also exhibit a mild dependence on the batch size. These are the first theoretical results that employ careful trade offs between informativeness and diversity to rigorously quantify the statistical performance of batch active learning in the pool-based scenario.
Nonstochastic Bandits with Composite Anonymous Feedback
Dec 06, 2021
We investigate a nonstochastic bandit setting in which the loss of an action is not immediately charged to the player, but rather spread over the subsequent rounds in an adversarial way. The instantaneous loss observed by the player at the end of each round is then a sum of many loss components of previously played actions. This setting encompasses as a special case the easier task of bandits with delayed feedback, a well-studied framework where the player observes the delayed losses individually. Our first contribution is a general reduction transforming a standard bandit algorithm into one that can operate in the harder setting: We bound the regret of the transformed algorithm in terms of the stability and regret of the original algorithm. Then, we show that the transformation of a suitably tuned FTRL with Tsallis entropy has a regret of order $\sqrt{(d+1)KT}$, where $d$ is the maximum delay, $K$ is the number of arms, and $T$ is the time horizon. Finally, we show that our results cannot be improved in general by exhibiting a matching (up to a log factor) lower bound on the regret of any algorithm operating in this setting.
Batch Active Learning at Scale
Jul 29, 2021
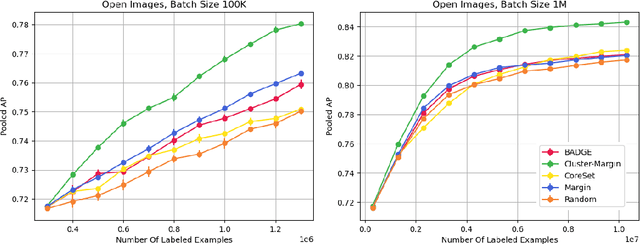
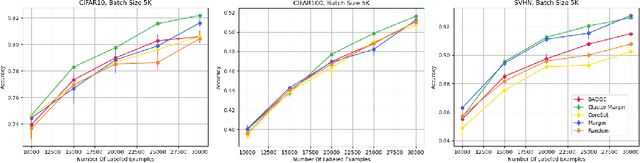
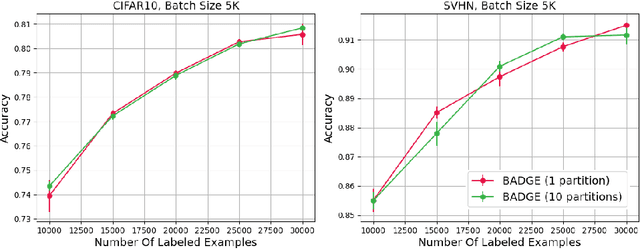
The ability to train complex and highly effective models often requires an abundance of training data, which can easily become a bottleneck in cost, time, and computational resources. Batch active learning, which adaptively issues batched queries to a labeling oracle, is a common approach for addressing this problem. The practical benefits of batch sampling come with the downside of less adaptivity and the risk of sampling redundant examples within a batch -- a risk that grows with the batch size. In this work, we analyze an efficient active learning algorithm, which focuses on the large batch setting. In particular, we show that our sampling method, which combines notions of uncertainty and diversity, easily scales to batch sizes (100K-1M) several orders of magnitude larger than used in previous studies and provides significant improvements in model training efficiency compared to recent baselines. Finally, we provide an initial theoretical analysis, proving label complexity guarantees for a related sampling method, which we show is approximately equivalent to our sampling method in specific settings.
Adapting to Misspecification in Contextual Bandits
Jul 12, 2021A major research direction in contextual bandits is to develop algorithms that are computationally efficient, yet support flexible, general-purpose function approximation. Algorithms based on modeling rewards have shown strong empirical performance, but typically require a well-specified model, and can fail when this assumption does not hold. Can we design algorithms that are efficient and flexible, yet degrade gracefully in the face of model misspecification? We introduce a new family of oracle-efficient algorithms for $\varepsilon$-misspecified contextual bandits that adapt to unknown model misspecification -- both for finite and infinite action settings. Given access to an online oracle for square loss regression, our algorithm attains optimal regret and -- in particular -- optimal dependence on the misspecification level, with no prior knowledge. Specializing to linear contextual bandits with infinite actions in $d$ dimensions, we obtain the first algorithm that achieves the optimal $O(d\sqrt{T} + \varepsilon\sqrt{d}T)$ regret bound for unknown misspecification level $\varepsilon$. On a conceptual level, our results are enabled by a new optimization-based perspective on the regression oracle reduction framework of Foster and Rakhlin, which we anticipate will find broader use.
On Learning to Rank Long Sequences with Contextual Bandits
Jun 07, 2021
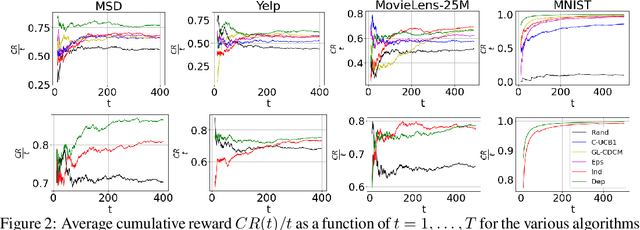
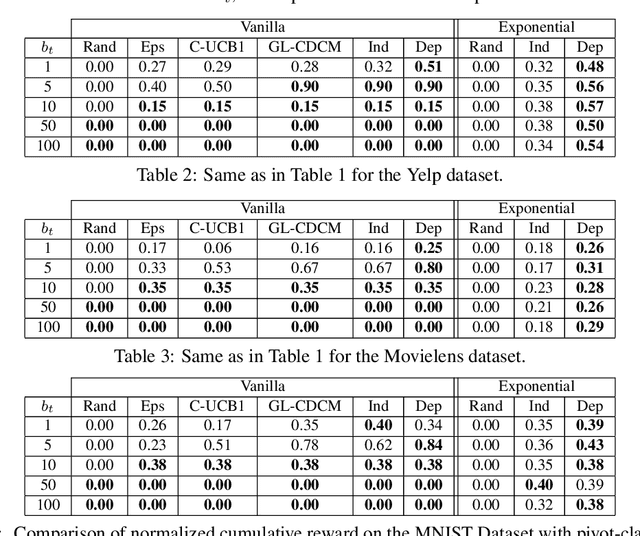
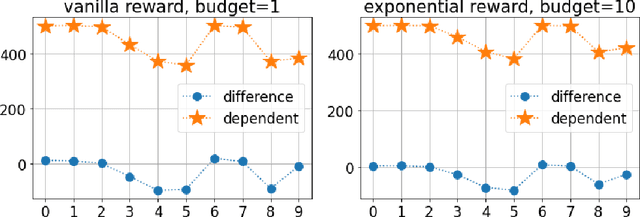
Motivated by problems of learning to rank long item sequences, we introduce a variant of the cascading bandit model that considers flexible length sequences with varying rewards and losses. We formulate two generative models for this problem within the generalized linear setting, and design and analyze upper confidence algorithms for it. Our analysis delivers tight regret bounds which, when specialized to vanilla cascading bandits, results in sharper guarantees than previously available in the literature. We evaluate our algorithms on a number of real-world datasets, and show significantly improved empirical performance as compared to known cascading bandit baselines.
Neural Active Learning with Performance Guarantees
Jun 06, 2021We investigate the problem of active learning in the streaming setting in non-parametric regimes, where the labels are stochastically generated from a class of functions on which we make no assumptions whatsoever. We rely on recently proposed Neural Tangent Kernel (NTK) approximation tools to construct a suitable neural embedding that determines the feature space the algorithm operates on and the learned model computed atop. Since the shape of the label requesting threshold is tightly related to the complexity of the function to be learned, which is a-priori unknown, we also derive a version of the algorithm which is agnostic to any prior knowledge. This algorithm relies on a regret balancing scheme to solve the resulting online model selection problem, and is computationally efficient. We prove joint guarantees on the cumulative regret and number of requested labels which depend on the complexity of the labeling function at hand. In the linear case, these guarantees recover known minimax results of the generalization error as a function of the label complexity in a standard statistical learning setting.
Regret Bound Balancing and Elimination for Model Selection in Bandits and RL
Dec 24, 2020

We propose a simple model selection approach for algorithms in stochastic bandit and reinforcement learning problems. As opposed to prior work that (implicitly) assumes knowledge of the optimal regret, we only require that each base algorithm comes with a candidate regret bound that may or may not hold during all rounds. In each round, our approach plays a base algorithm to keep the candidate regret bounds of all remaining base algorithms balanced, and eliminates algorithms that violate their candidate bound. We prove that the total regret of this approach is bounded by the best valid candidate regret bound times a multiplicative factor. This factor is reasonably small in several applications, including linear bandits and MDPs with nested function classes, linear bandits with unknown misspecification, and LinUCB applied to linear bandits with different confidence parameters. We further show that, under a suitable gap-assumption, this factor only scales with the number of base algorithms and not their complexity when the number of rounds is large enough. Finally, unlike recent efforts in model selection for linear stochastic bandits, our approach is versatile enough to also cover cases where the context information is generated by an adversarial environment, rather than a stochastic one.
Online Model Selection: a Rested Bandit Formulation
Dec 07, 2020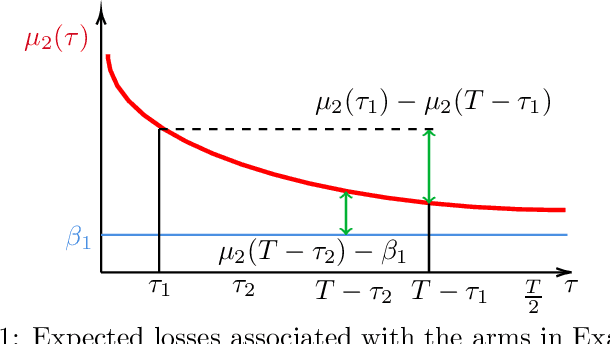
Motivated by a natural problem in online model selection with bandit information, we introduce and analyze a best arm identification problem in the rested bandit setting, wherein arm expected losses decrease with the number of times the arm has been played. The shape of the expected loss functions is similar across arms, and is assumed to be available up to unknown parameters that have to be learned on the fly. We define a novel notion of regret for this problem, where we compare to the policy that always plays the arm having the smallest expected loss at the end of the game. We analyze an arm elimination algorithm whose regret vanishes as the time horizon increases. The actual rate of convergence depends in a detailed way on the postulated functional form of the expected losses. Unlike known model selection efforts in the recent bandit literature, our algorithm exploits the specific structure of the problem to learn the unknown parameters of the expected loss function so as to identify the best arm as quickly as possible. We complement our analysis with a lower bound, indicating strengths and limitations of the proposed solution.