 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo more hard prompts: SoftSRV prompting for synthetic data generation
Oct 23, 2024



We present a novel soft prompt based framework, SoftSRV, that leverages a frozen pre-trained large language model (LLM) to generate targeted synthetic text sequences. Given a sample from the target distribution, our proposed framework uses data-driven loss minimization to train a parameterized "contextual" soft prompt. This soft prompt is then used to steer the frozen LLM to generate synthetic sequences that are similar to the target distribution. We argue that SoftSRV provides a practical improvement over common hard-prompting approaches that rely on human-curated prompt-templates, which can be idiosyncratic, labor-intensive to craft, and may need to be specialized per domain. We empirically evaluate SoftSRV and hard-prompting baselines by generating synthetic data to fine-tune a small Gemma model on three different domains (coding, math, reasoning). To stress the generality of SoftSRV, we perform these evaluations without any particular specialization of the framework to each domain. We find that SoftSRV significantly improves upon hard-prompting baselines, generating data with superior fine-tuning performance and that better matches the target distribution according to the MAUVE similarity metric.
SpacTor-T5: Pre-training T5 Models with Span Corruption and Replaced Token Detection
Jan 24, 2024Pre-training large language models is known to be extremely resource intensive and often times inefficient, under-utilizing the information encapsulated in the training text sequences. In this paper, we present SpacTor, a new training procedure consisting of (1) a hybrid objective combining span corruption (SC) and token replacement detection (RTD), and (2) a two-stage curriculum that optimizes the hybrid objective over the initial $\tau$ iterations, then transitions to standard SC loss. We show empirically that the effectiveness of the hybrid objective is tied to the two-stage pre-training schedule, and provide extensive analysis on why this is the case. In our experiments with encoder-decoder architectures (T5) on a variety of NLP tasks, SpacTor-T5 yields the same downstream performance as standard SC pre-training, while enabling a 50% reduction in pre-training iterations and 40% reduction in total FLOPs. Alternatively, given the same amount of computing budget, we find that SpacTor results in significantly improved downstream benchmark performance.
Batch Active Learning at Scale
Jul 29, 2021
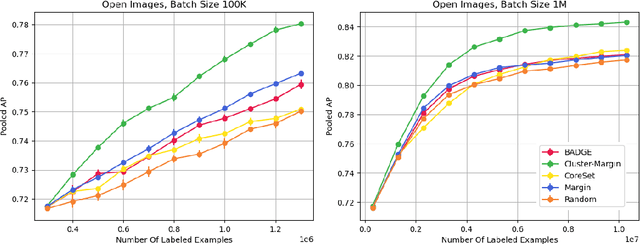
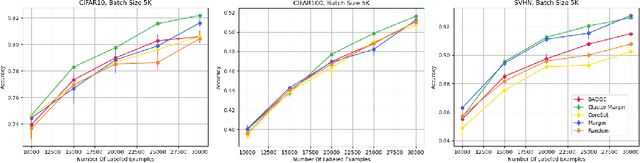
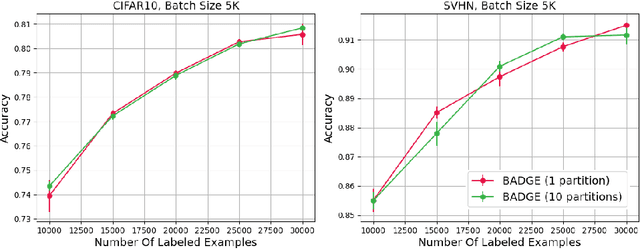
The ability to train complex and highly effective models often requires an abundance of training data, which can easily become a bottleneck in cost, time, and computational resources. Batch active learning, which adaptively issues batched queries to a labeling oracle, is a common approach for addressing this problem. The practical benefits of batch sampling come with the downside of less adaptivity and the risk of sampling redundant examples within a batch -- a risk that grows with the batch size. In this work, we analyze an efficient active learning algorithm, which focuses on the large batch setting. In particular, we show that our sampling method, which combines notions of uncertainty and diversity, easily scales to batch sizes (100K-1M) several orders of magnitude larger than used in previous studies and provides significant improvements in model training efficiency compared to recent baselines. Finally, we provide an initial theoretical analysis, proving label complexity guarantees for a related sampling method, which we show is approximately equivalent to our sampling method in specific settings.