 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchauder Bases for $C[0, 1]$ Using ReLU, Softplus and Two Sigmoidal Functions
Jun 09, 2025We construct four Schauder bases for the space $C[0,1]$, one using ReLU functions, another using Softplus functions, and two more using sigmoidal versions of the ReLU and Softplus functions. This establishes the existence of a basis using these functions for the first time, and improves on the universal approximation property associated with them.
On the Approximability of Stationary Processes using the ARMA Model
Aug 20, 2024


We identify certain gaps in the literature on the approximability of stationary random variables using the Autoregressive Moving Average (ARMA) model. To quantify approximability, we propose that an ARMA model be viewed as an approximation of a stationary random variable. We map these stationary random variables to Hardy space functions, and formulate a new function approximation problem that corresponds to random variable approximation, and thus to ARMA. Based on this Hardy space formulation we identify a class of stationary processes where approximation guarantees are feasible. We also identify an idealized stationary random process for which we conjecture that a good ARMA approximation is not possible. Next, we provide a constructive proof that Pad\'e approximations do not always correspond to the best ARMA approximation. Finally, we note that the spectral methods adopted in this paper can be seen as a generalization of unit root methods for stationary processes even when an ARMA model is not defined.
Batch Active Learning at Scale
Jul 29, 2021
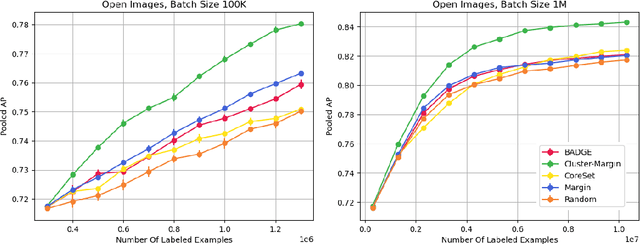
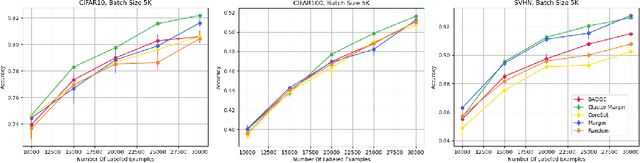
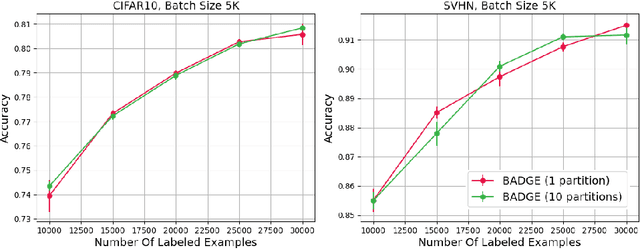
The ability to train complex and highly effective models often requires an abundance of training data, which can easily become a bottleneck in cost, time, and computational resources. Batch active learning, which adaptively issues batched queries to a labeling oracle, is a common approach for addressing this problem. The practical benefits of batch sampling come with the downside of less adaptivity and the risk of sampling redundant examples within a batch -- a risk that grows with the batch size. In this work, we analyze an efficient active learning algorithm, which focuses on the large batch setting. In particular, we show that our sampling method, which combines notions of uncertainty and diversity, easily scales to batch sizes (100K-1M) several orders of magnitude larger than used in previous studies and provides significant improvements in model training efficiency compared to recent baselines. Finally, we provide an initial theoretical analysis, proving label complexity guarantees for a related sampling method, which we show is approximately equivalent to our sampling method in specific settings.
Scaling Hierarchical Agglomerative Clustering to Billion-sized Datasets
May 25, 2021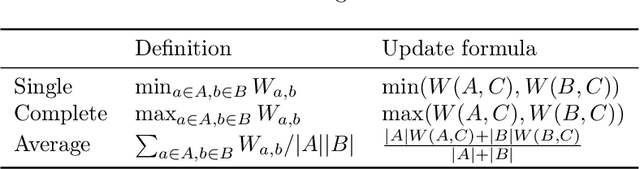
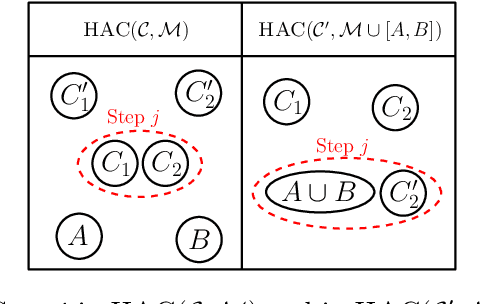

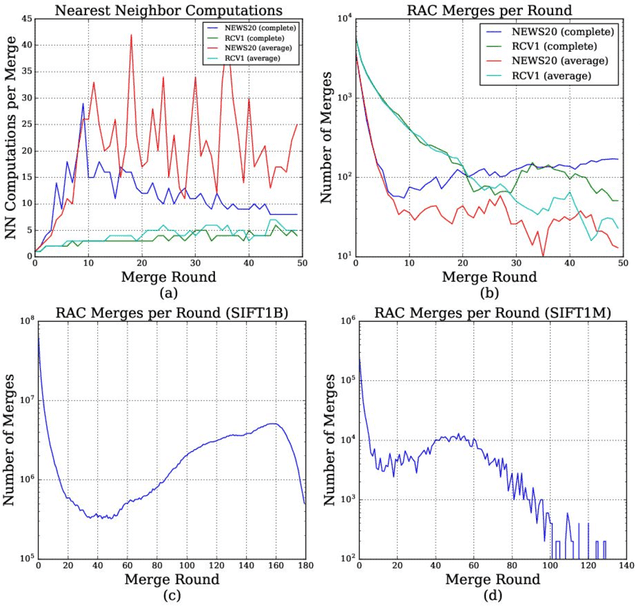
Hierarchical Agglomerative Clustering (HAC) is one of the oldest but still most widely used clustering methods. However, HAC is notoriously hard to scale to large data sets as the underlying complexity is at least quadratic in the number of data points and many algorithms to solve HAC are inherently sequential. In this paper, we propose {Reciprocal Agglomerative Clustering (RAC)}, a distributed algorithm for HAC, that uses a novel strategy to efficiently merge clusters in parallel. We prove theoretically that RAC recovers the exact solution of HAC. Furthermore, under clusterability and balancedness assumption we show provable speedups in total runtime due to the parallelism. We also show that these speedups are achievable for certain probabilistic data models. In extensive experiments, we show that this parallelism is achieved on real world data sets and that the proposed RAC algorithm can recover the HAC hierarchy on billions of data points connected by trillions of edges in less than an hour.
Online Hierarchical Clustering Approximations
Sep 20, 2019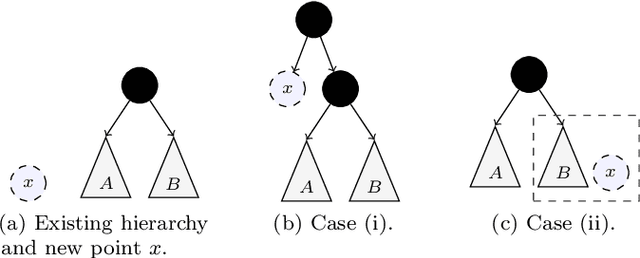

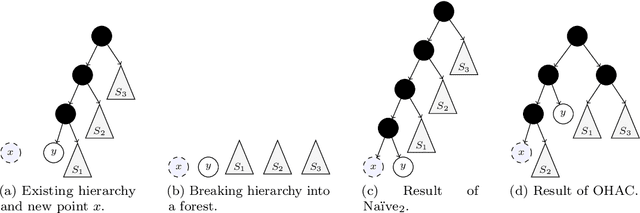
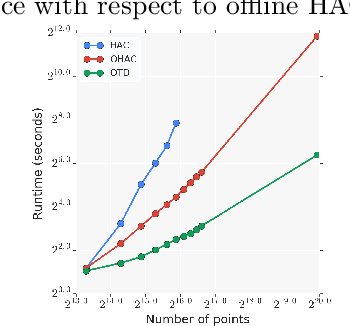
Hierarchical clustering is a widely used approach for clustering datasets at multiple levels of granularity. Despite its popularity, existing algorithms such as hierarchical agglomerative clustering (HAC) are limited to the offline setting, and thus require the entire dataset to be available. This prohibits their use on large datasets commonly encountered in modern learning applications. In this paper, we consider hierarchical clustering in the online setting, where points arrive one at a time. We propose two algorithms that seek to optimize the Moseley and Wang (MW) revenue function, a variant of the Dasgupta cost. These algorithms offer different tradeoffs between efficiency and MW revenue performance. The first algorithm, OTD, is a highly efficient Online Top Down algorithm which provably achieves a 1/3-approximation to the MW revenue under a data separation assumption. The second algorithm, OHAC, is an online counterpart to offline HAC, which is known to yield a 1/3-approximation to the MW revenue, and produce good quality clusters in practice. We show that OHAC approximates offline HAC by leveraging a novel split-merge procedure. We empirically show that OTD and OHAC offer significant efficiency and cluster quality gains respectively over baselines.
Flattening a Hierarchical Clustering through Active Learning
Jun 22, 2019
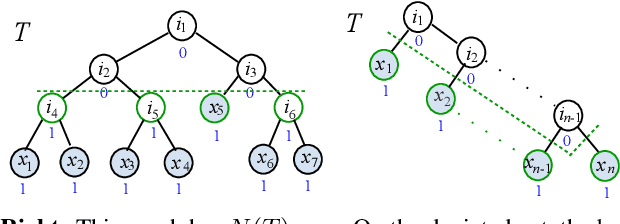
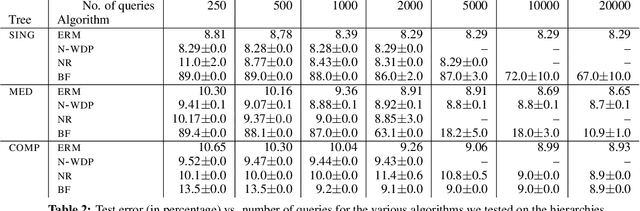
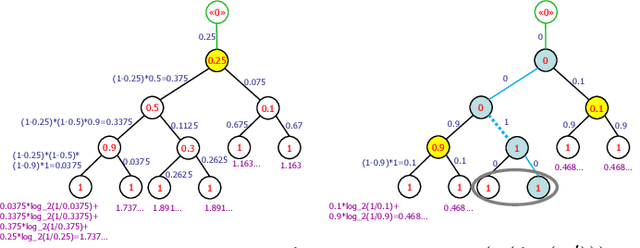
We investigate active learning by pairwise similarity over the leaves of trees originating from hierarchical clustering procedures. In the realizable setting, we provide a full characterization of the number of queries needed to achieve perfect reconstruction of the tree cut. In the non-realizable setting, we rely on known important-sampling procedures to obtain regret and query complexity bounds. Our algorithms come with theoretical guarantees on the statistical error and, more importantly, lend themselves to linear-time implementations in the relevant parameters of the problem. We discuss such implementations, prove running time guarantees for them, and present preliminary experiments on real-world datasets showing the compelling practical performance of our algorithms as compared to both passive learning and simple active learning baselines.