 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Similarity Metrics for Data Selection for Language Model Pretraining
Feb 04, 2025



Similarity between training examples is used to curate pretraining datasets for language models by many methods -- for diversification and to select examples similar to high-quality data. However, similarity is typically measured with off-the-shelf embedding models that are generic or trained for tasks such as retrieval. This paper introduces a framework to analyze the suitability of embedding models specifically for data curation in the language model pretraining setting. We quantify the correlation between similarity in the embedding space to similarity in pretraining loss between different training examples, and how diversifying in the embedding space affects pretraining quality. We analyze a variety of embedding models in our framework, with experiments using the Pile dataset for pretraining a 1.7B parameter decoder-only language model. We find that the embedding models we consider are all useful for pretraining data curation. Moreover, a simple approach of averaging per-token embeddings proves to be surprisingly competitive with more sophisticated embedding models -- likely because the latter are not designed specifically for pretraining data curation. Indeed, we believe our analysis and evaluation framework can serve as a foundation for the design of embedding models that specifically reason about similarity in pretraining datasets.
GIST: Greedy Independent Set Thresholding for Diverse Data Summarization
May 29, 2024

We propose a novel subset selection task called min-distance diverse data summarization ($\textsf{MDDS}$), which has a wide variety of applications in machine learning, e.g., data sampling and feature selection. Given a set of points in a metric space, the goal is to maximize an objective that combines the total utility of the points and a diversity term that captures the minimum distance between any pair of selected points, subject to the constraint $|S| \le k$. For example, the points may correspond to training examples in a data sampling problem, e.g., learned embeddings of images extracted from a deep neural network. This work presents the $\texttt{GIST}$ algorithm, which achieves a $\frac{2}{3}$-approximation guarantee for $\textsf{MDDS}$ by approximating a series of maximum independent set problems with a bicriteria greedy algorithm. We also prove a complementary $(\frac{2}{3}+\varepsilon)$-hardness of approximation, for any $\varepsilon > 0$. Finally, we provide an empirical study that demonstrates $\texttt{GIST}$ outperforms existing methods for $\textsf{MDDS}$ on synthetic data, and also for a real-world image classification experiment the studies single-shot subset selection for ImageNet.
SpacTor-T5: Pre-training T5 Models with Span Corruption and Replaced Token Detection
Jan 24, 2024Pre-training large language models is known to be extremely resource intensive and often times inefficient, under-utilizing the information encapsulated in the training text sequences. In this paper, we present SpacTor, a new training procedure consisting of (1) a hybrid objective combining span corruption (SC) and token replacement detection (RTD), and (2) a two-stage curriculum that optimizes the hybrid objective over the initial $\tau$ iterations, then transitions to standard SC loss. We show empirically that the effectiveness of the hybrid objective is tied to the two-stage pre-training schedule, and provide extensive analysis on why this is the case. In our experiments with encoder-decoder architectures (T5) on a variety of NLP tasks, SpacTor-T5 yields the same downstream performance as standard SC pre-training, while enabling a 50% reduction in pre-training iterations and 40% reduction in total FLOPs. Alternatively, given the same amount of computing budget, we find that SpacTor results in significantly improved downstream benchmark performance.
Leveraging Importance Weights in Subset Selection
Jan 28, 2023



We present a subset selection algorithm designed to work with arbitrary model families in a practical batch setting. In such a setting, an algorithm can sample examples one at a time but, in order to limit overhead costs, is only able to update its state (i.e. further train model weights) once a large enough batch of examples is selected. Our algorithm, IWeS, selects examples by importance sampling where the sampling probability assigned to each example is based on the entropy of models trained on previously selected batches. IWeS admits significant performance improvement compared to other subset selection algorithms for seven publicly available datasets. Additionally, it is competitive in an active learning setting, where the label information is not available at selection time. We also provide an initial theoretical analysis to support our importance weighting approach, proving generalization and sampling rate bounds.
Batch Active Learning at Scale
Jul 29, 2021
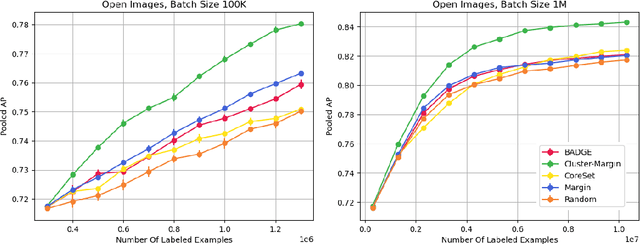
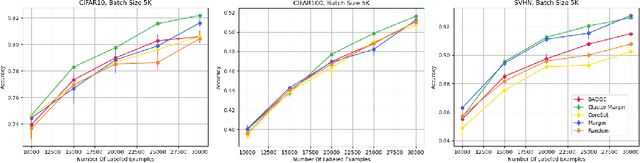
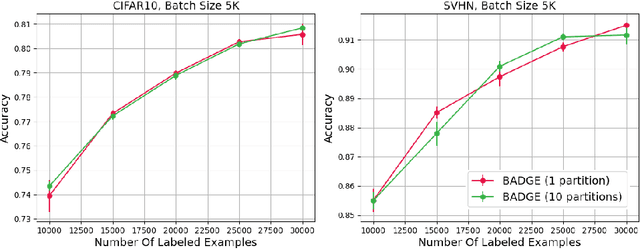
The ability to train complex and highly effective models often requires an abundance of training data, which can easily become a bottleneck in cost, time, and computational resources. Batch active learning, which adaptively issues batched queries to a labeling oracle, is a common approach for addressing this problem. The practical benefits of batch sampling come with the downside of less adaptivity and the risk of sampling redundant examples within a batch -- a risk that grows with the batch size. In this work, we analyze an efficient active learning algorithm, which focuses on the large batch setting. In particular, we show that our sampling method, which combines notions of uncertainty and diversity, easily scales to batch sizes (100K-1M) several orders of magnitude larger than used in previous studies and provides significant improvements in model training efficiency compared to recent baselines. Finally, we provide an initial theoretical analysis, proving label complexity guarantees for a related sampling method, which we show is approximately equivalent to our sampling method in specific settings.
Scaling Hierarchical Agglomerative Clustering to Billion-sized Datasets
May 25, 2021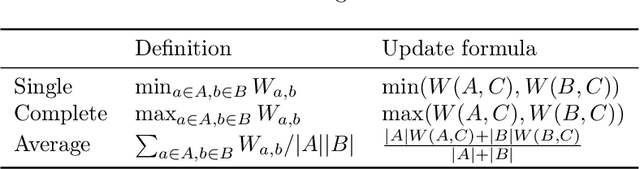
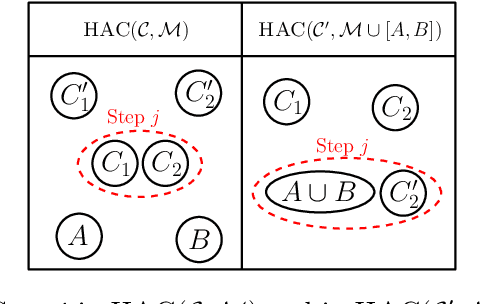

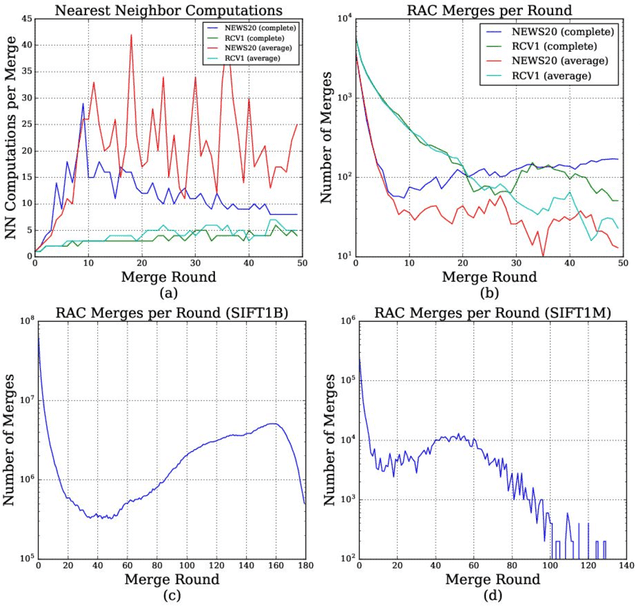
Hierarchical Agglomerative Clustering (HAC) is one of the oldest but still most widely used clustering methods. However, HAC is notoriously hard to scale to large data sets as the underlying complexity is at least quadratic in the number of data points and many algorithms to solve HAC are inherently sequential. In this paper, we propose {Reciprocal Agglomerative Clustering (RAC)}, a distributed algorithm for HAC, that uses a novel strategy to efficiently merge clusters in parallel. We prove theoretically that RAC recovers the exact solution of HAC. Furthermore, under clusterability and balancedness assumption we show provable speedups in total runtime due to the parallelism. We also show that these speedups are achievable for certain probabilistic data models. In extensive experiments, we show that this parallelism is achieved on real world data sets and that the proposed RAC algorithm can recover the HAC hierarchy on billions of data points connected by trillions of edges in less than an hour.
Online Hierarchical Clustering Approximations
Sep 20, 2019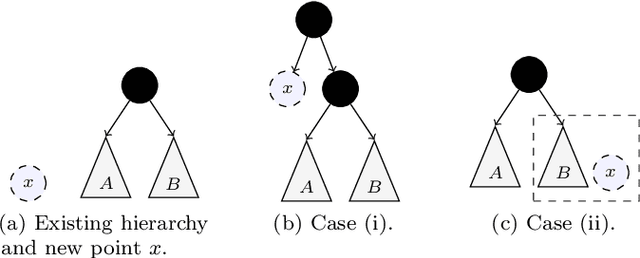

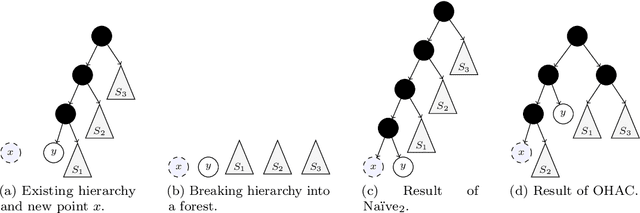
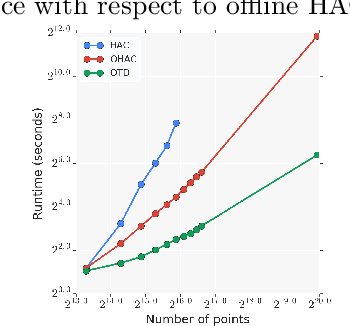
Hierarchical clustering is a widely used approach for clustering datasets at multiple levels of granularity. Despite its popularity, existing algorithms such as hierarchical agglomerative clustering (HAC) are limited to the offline setting, and thus require the entire dataset to be available. This prohibits their use on large datasets commonly encountered in modern learning applications. In this paper, we consider hierarchical clustering in the online setting, where points arrive one at a time. We propose two algorithms that seek to optimize the Moseley and Wang (MW) revenue function, a variant of the Dasgupta cost. These algorithms offer different tradeoffs between efficiency and MW revenue performance. The first algorithm, OTD, is a highly efficient Online Top Down algorithm which provably achieves a 1/3-approximation to the MW revenue under a data separation assumption. The second algorithm, OHAC, is an online counterpart to offline HAC, which is known to yield a 1/3-approximation to the MW revenue, and produce good quality clusters in practice. We show that OHAC approximates offline HAC by leveraging a novel split-merge procedure. We empirically show that OTD and OHAC offer significant efficiency and cluster quality gains respectively over baselines.