 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Consistent Inverse GAN for Text-to-Image Synthesis
Aug 03, 2021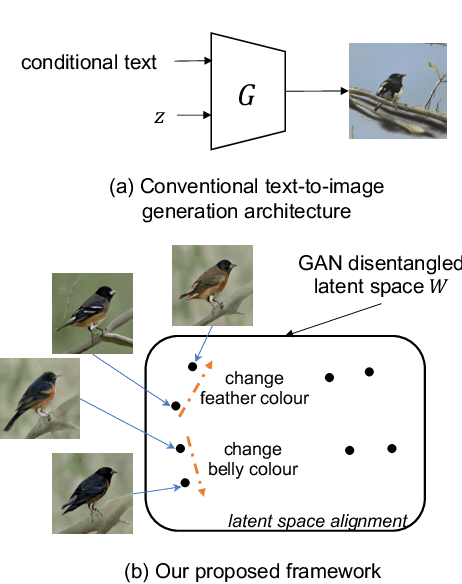

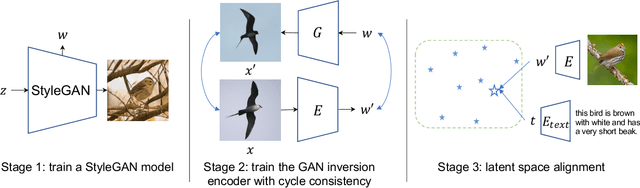
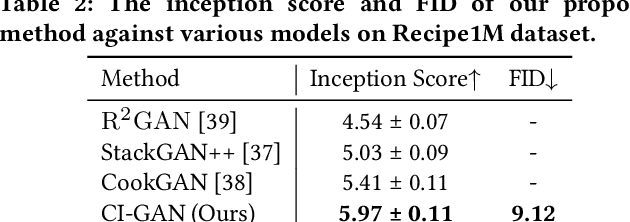
This paper investigates an open research task of text-to-image synthesis for automatically generating or manipulating images from text descriptions. Prevailing methods mainly use the text as conditions for GAN generation, and train different models for the text-guided image generation and manipulation tasks. In this paper, we propose a novel unified framework of Cycle-consistent Inverse GAN (CI-GAN) for both text-to-image generation and text-guided image manipulation tasks. Specifically, we first train a GAN model without text input, aiming to generate images with high diversity and quality. Then we learn a GAN inversion model to convert the images back to the GAN latent space and obtain the inverted latent codes for each image, where we introduce the cycle-consistency training to learn more robust and consistent inverted latent codes. We further uncover the latent space semantics of the trained GAN model, by learning a similarity model between text representations and the latent codes. In the text-guided optimization module, we generate images with the desired semantic attributes by optimizing the inverted latent codes. Extensive experiments on the Recipe1M and CUB datasets validate the efficacy of our proposed framework.
WaveFill: A Wavelet-based Generation Network for Image Inpainting
Jul 23, 2021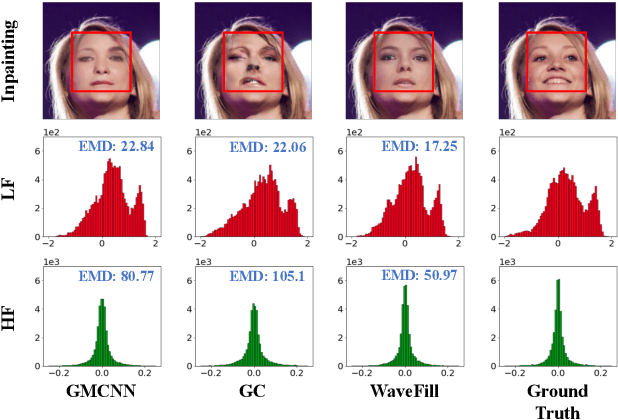
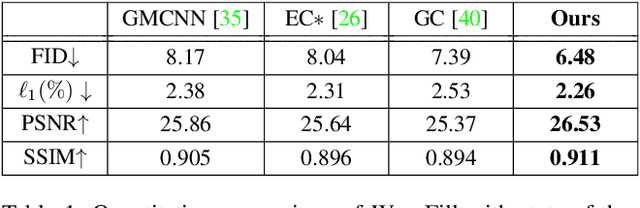
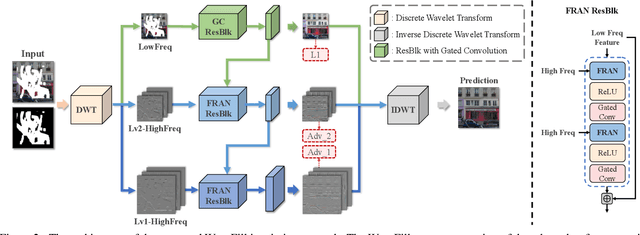
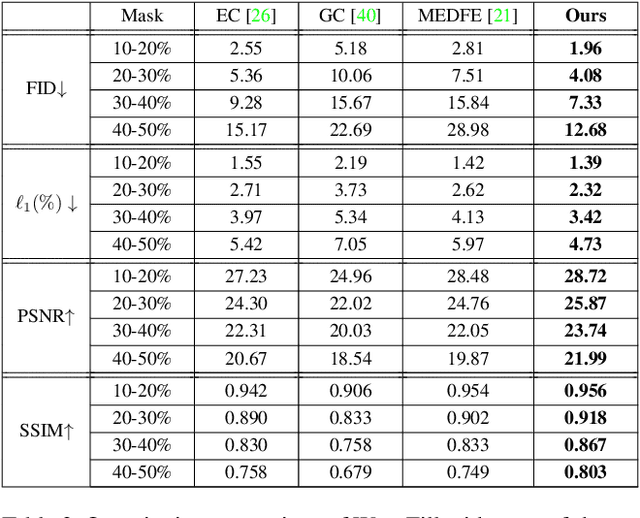
Image inpainting aims to complete the missing or corrupted regions of images with realistic contents. The prevalent approaches adopt a hybrid objective of reconstruction and perceptual quality by using generative adversarial networks. However, the reconstruction loss and adversarial loss focus on synthesizing contents of different frequencies and simply applying them together often leads to inter-frequency conflicts and compromised inpainting. This paper presents WaveFill, a wavelet-based inpainting network that decomposes images into multiple frequency bands and fills the missing regions in each frequency band separately and explicitly. WaveFill decomposes images by using discrete wavelet transform (DWT) that preserves spatial information naturally. It applies L1 reconstruction loss to the decomposed low-frequency bands and adversarial loss to high-frequency bands, hence effectively mitigate inter-frequency conflicts while completing images in spatial domain. To address the inpainting inconsistency in different frequency bands and fuse features with distinct statistics, we design a novel normalization scheme that aligns and fuses the multi-frequency features effectively. Extensive experiments over multiple datasets show that WaveFill achieves superior image inpainting qualitatively and quantitatively.
SelfCF: A Simple Framework for Self-supervised Collaborative Filtering
Jul 07, 2021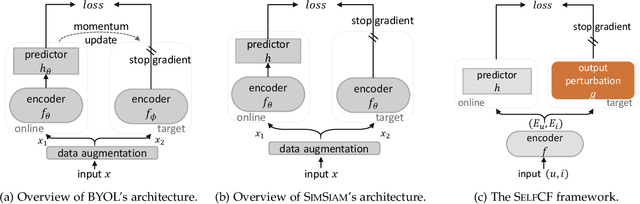
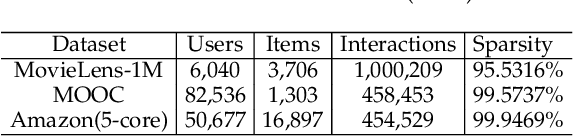
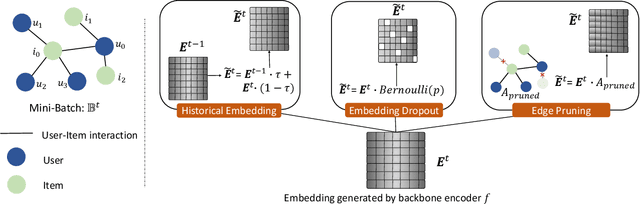

Collaborative filtering (CF) is widely used to learn an informative latent representation of a user or item from observed interactions. Existing CF-based methods commonly adopt negative sampling to discriminate different items. That is, observed user-item pairs are treated as positive instances; unobserved pairs are considered as negative instances and are sampled under a defined distribution for training. Training with negative sampling on large datasets is computationally expensive. Further, negative items should be carefully sampled under the defined distribution, in order to avoid selecting an observed positive item in the training dataset. Unavoidably, some negative items sampled from the training dataset could be positive in the test set. Recently, self-supervised learning (SSL) has emerged as a powerful tool to learn a model without negative samples. In this paper, we propose a self-supervised collaborative filtering framework (SelfCF), that is specially designed for recommender scenario with implicit feedback. The main idea of SelfCF is to augment the output embeddings generated by backbone networks, because it is infeasible to augment raw input of user/item ids. We propose and study three output perturbation techniques that can be applied to different types of backbone networks including both traditional CF models and graph-based models. By encapsulating two popular recommendation models into the framework, our experiments on three datasets show that the best performance of our framework is comparable or better than the supervised counterpart. We also show that SelfCF can boost up the performance by up to 8.93\% on average, compared with another self-supervised framework as the baseline. Source codes are available at: https://github.com/enoche/SelfCF.
Unbalanced Feature Transport for Exemplar-based Image Translation
Jun 19, 2021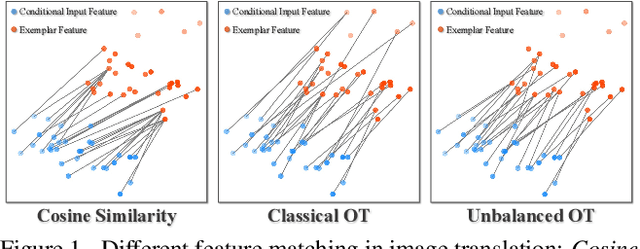
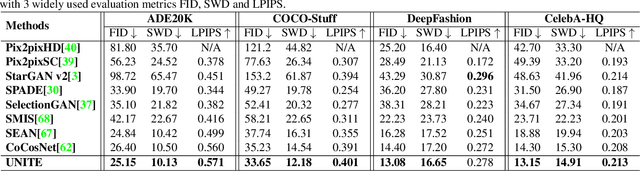
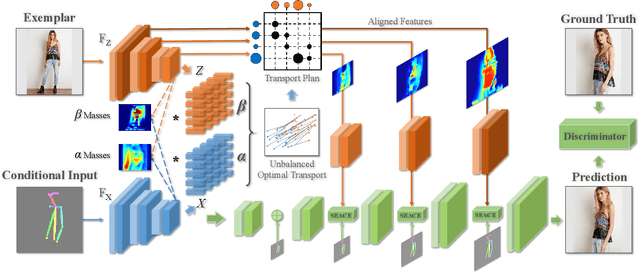
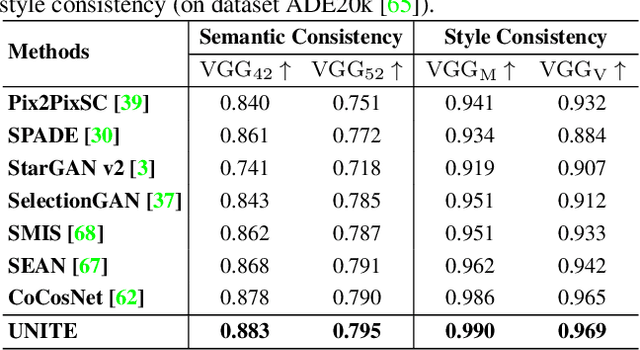
Despite the great success of GANs in images translation with different conditioned inputs such as semantic segmentation and edge maps, generating high-fidelity realistic images with reference styles remains a grand challenge in conditional image-to-image translation. This paper presents a general image translation framework that incorporates optimal transport for feature alignment between conditional inputs and style exemplars in image translation. The introduction of optimal transport mitigates the constraint of many-to-one feature matching significantly while building up accurate semantic correspondences between conditional inputs and exemplars. We design a novel unbalanced optimal transport to address the transport between features with deviational distributions which exists widely between conditional inputs and exemplars. In addition, we design a semantic-activation normalization scheme that injects style features of exemplars into the image translation process successfully. Extensive experiments over multiple image translation tasks show that our method achieves superior image translation qualitatively and quantitatively as compared with the state-of-the-art.
Initialization Matters: Regularizing Manifold-informed Initialization for Neural Recommendation Systems
Jun 09, 2021

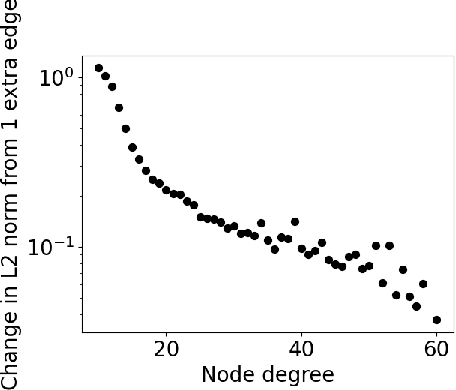
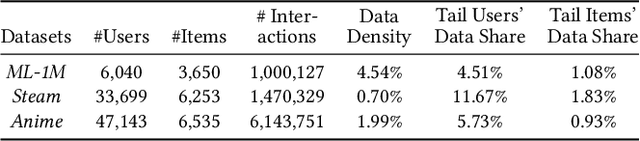
Proper initialization is crucial to the optimization and the generalization of neural networks. However, most existing neural recommendation systems initialize the user and item embeddings randomly. In this work, we propose a new initialization scheme for user and item embeddings called Laplacian Eigenmaps with Popularity-based Regularization for Isolated Data (LEPORID). LEPORID endows the embeddings with information regarding multi-scale neighborhood structures on the data manifold and performs adaptive regularization to compensate for high embedding variance on the tail of the data distribution. Exploiting matrix sparsity, LEPORID embeddings can be computed efficiently. We evaluate LEPORID in a wide range of neural recommendation models. In contrast to the recent surprising finding that the simple K-nearest-neighbor (KNN) method often outperforms neural recommendation systems, we show that existing neural systems initialized with LEPORID often perform on par or better than KNN. To maximize the effects of the initialization, we propose the Dual-Loss Residual Recommendation (DLR2) network, which, when initialized with LEPORID, substantially outperforms both traditional and state-of-the-art neural recommender systems.
KECRS: Towards Knowledge-Enriched Conversational Recommendation System
May 18, 2021
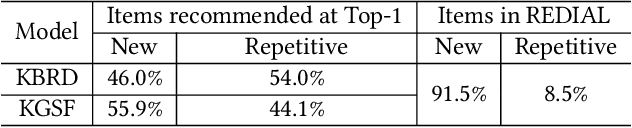
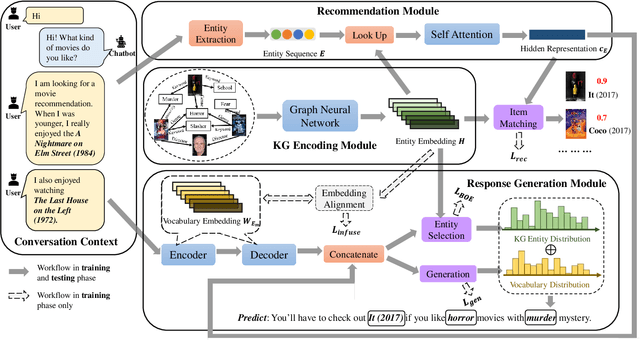
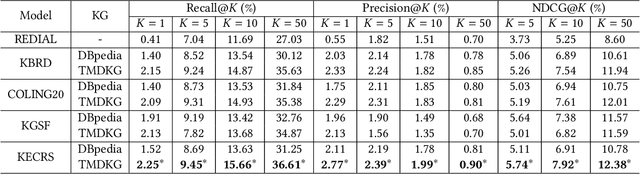
The chit-chat-based conversational recommendation systems (CRS) provide item recommendations to users through natural language interactions. To better understand user's intentions, external knowledge graphs (KG) have been introduced into chit-chat-based CRS. However, existing chit-chat-based CRS usually generate repetitive item recommendations, and they cannot properly infuse knowledge from KG into CRS to generate informative responses. To remedy these issues, we first reformulate the conversational recommendation task to highlight that the recommended items should be new and possibly interested by users. Then, we propose the Knowledge-Enriched Conversational Recommendation System (KECRS). Specifically, we develop the Bag-of-Entity (BOE) loss and the infusion loss to better integrate KG with CRS for generating more diverse and informative responses. BOE loss provides an additional supervision signal to guide CRS to learn from both human-written utterances and KG. Infusion loss bridges the gap between the word embeddings and entity embeddings by minimizing distances of the same words in these two embeddings. Moreover, we facilitate our study by constructing a high-quality KG, \ie The Movie Domain Knowledge Graph (TMDKG). Experimental results on a large-scale dataset demonstrate that KECRS outperforms state-of-the-art chit-chat-based CRS, in terms of both recommendation accuracy and response generation quality.
Diverse Image Inpainting with Bidirectional and Autoregressive Transformers
Apr 30, 2021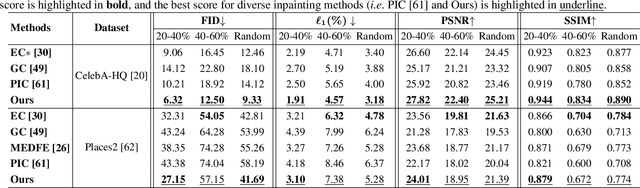
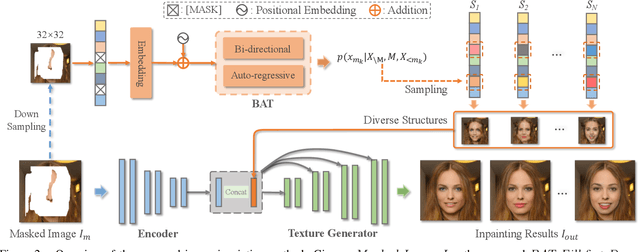
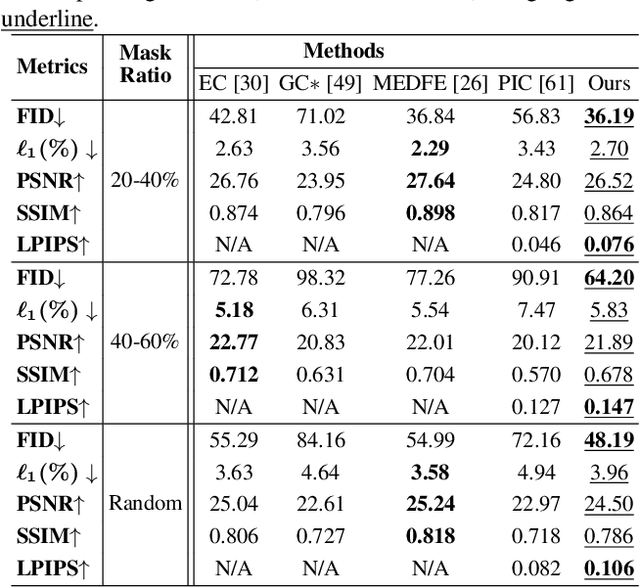
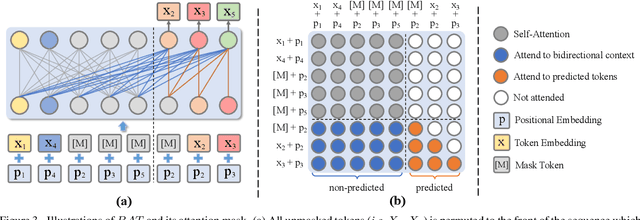
Image inpainting is an underdetermined inverse problem, it naturally allows diverse contents that fill up the missing or corrupted regions reasonably and realistically. Prevalent approaches using convolutional neural networks (CNNs) can synthesize visually pleasant contents, but CNNs suffer from limited perception fields for capturing global features. With image-level attention, transformers enable to model long-range dependencies and generate diverse contents with autoregressive modeling of pixel-sequence distributions. However, the unidirectional attention in transformers is suboptimal as corrupted regions can have arbitrary shapes with contexts from arbitrary directions. We propose BAT-Fill, an image inpainting framework with a novel bidirectional autoregressive transformer (BAT) that models deep bidirectional contexts for autoregressive generation of diverse inpainting contents. BAT-Fill inherits the merits of transformers and CNNs in a two-stage manner, which allows to generate high-resolution contents without being constrained by the quadratic complexity of attention in transformers. Specifically, it first generates pluralistic image structures of low resolution by adapting transformers and then synthesizes realistic texture details of high resolutions with a CNN-based up-sampling network. Extensive experiments over multiple datasets show that BAT-Fill achieves superior diversity and fidelity in image inpainting qualitatively and quantitatively.
Understanding Chinese Video and Language via Contrastive Multimodal Pre-Training
Apr 19, 2021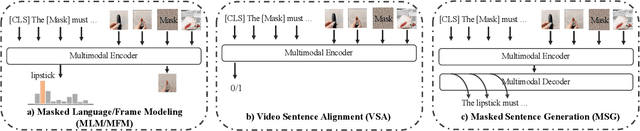
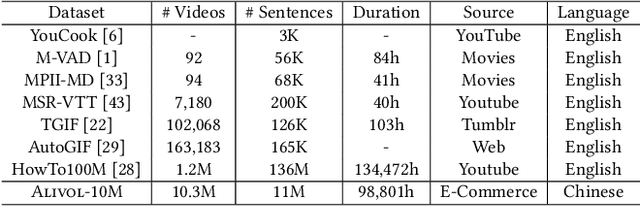

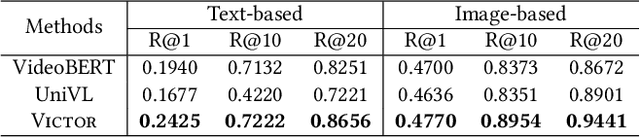
The pre-trained neural models have recently achieved impressive performances in understanding multimodal content. However, it is still very challenging to pre-train neural models for video and language understanding, especially for Chinese video-language data, due to the following reasons. Firstly, existing video-language pre-training algorithms mainly focus on the co-occurrence of words and video frames, but ignore other valuable semantic and structure information of video-language content, e.g., sequential order and spatiotemporal relationships. Secondly, there exist conflicts between video sentence alignment and other proxy tasks. Thirdly, there is a lack of large-scale and high-quality Chinese video-language datasets (e.g., including 10 million unique videos), which are the fundamental success conditions for pre-training techniques. In this work, we propose a novel video-language understanding framework named VICTOR, which stands for VIdeo-language understanding via Contrastive mulTimOdal pRe-training. Besides general proxy tasks such as masked language modeling, VICTOR constructs several novel proxy tasks under the contrastive learning paradigm, making the model be more robust and able to capture more complex multimodal semantic and structural relationships from different perspectives. VICTOR is trained on a large-scale Chinese video-language dataset, including over 10 million complete videos with corresponding high-quality textual descriptions. We apply the pre-trained VICTOR model to a series of downstream applications and demonstrate its superior performances, comparing against the state-of-the-art pre-training methods such as VideoBERT and UniVL. The codes and trained checkpoints will be publicly available to nourish further developments of the research community.
Latent-Optimized Adversarial Neural Transfer for Sarcasm Detection
Apr 19, 2021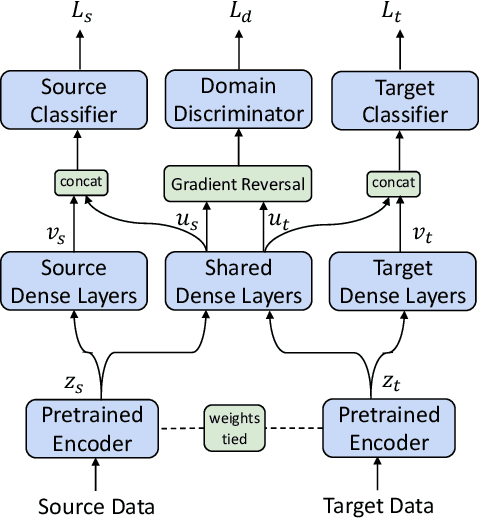
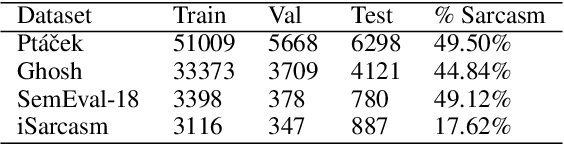
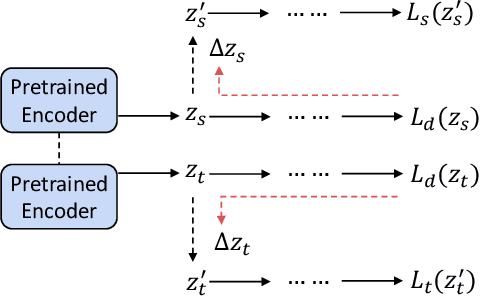
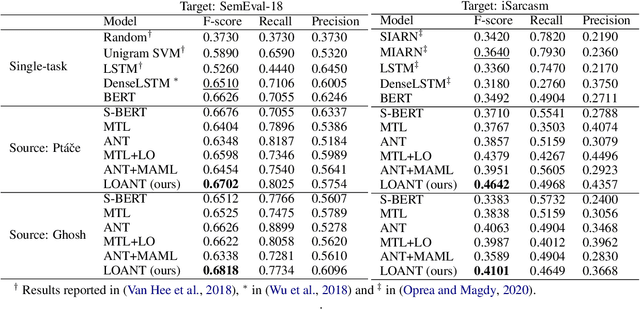
The existence of multiple datasets for sarcasm detection prompts us to apply transfer learning to exploit their commonality. The adversarial neural transfer (ANT) framework utilizes multiple loss terms that encourage the source-domain and the target-domain feature distributions to be similar while optimizing for domain-specific performance. However, these objectives may be in conflict, which can lead to optimization difficulties and sometimes diminished transfer. We propose a generalized latent optimization strategy that allows different losses to accommodate each other and improves training dynamics. The proposed method outperforms transfer learning and meta-learning baselines. In particular, we achieve 10.02% absolute performance gain over the previous state of the art on the iSarcasm dataset.
Noise-resistant Deep Metric Learning with Ranking-based Instance Selection
Apr 12, 2021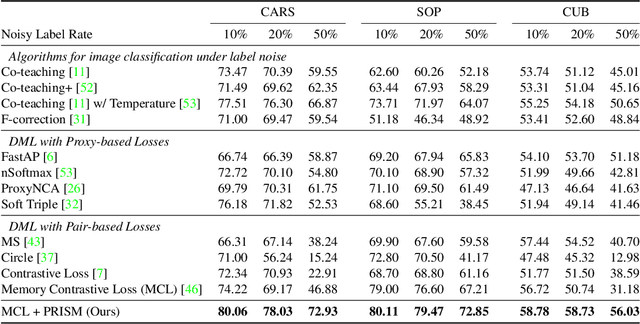

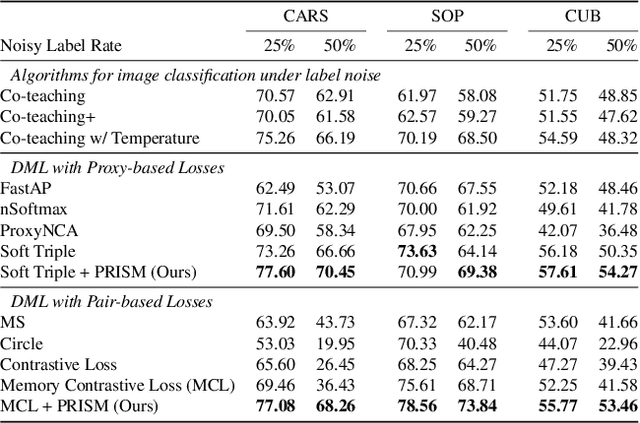
The existence of noisy labels in real-world data negatively impacts the performance of deep learning models. Although much research effort has been devoted to improving robustness to noisy labels in classification tasks, the problem of noisy labels in deep metric learning (DML) remains open. In this paper, we propose a noise-resistant training technique for DML, which we name Probabilistic Ranking-based Instance Selection with Memory (PRISM). PRISM identifies noisy data in a minibatch using average similarity against image features extracted by several previous versions of the neural network. These features are stored in and retrieved from a memory bank. To alleviate the high computational cost brought by the memory bank, we introduce an acceleration method that replaces individual data points with the class centers. In extensive comparisons with 12 existing approaches under both synthetic and real-world label noise, PRISM demonstrates superior performance of up to 6.06% in Precision@1.