 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Image Cropping for Visual Aesthetic Enhancement Using Deep Neural Networks and Cascaded Regression
Jan 14, 2018

Despite recent progress, computational visual aesthetic is still challenging. Image cropping, which refers to the removal of unwanted scene areas, is an important step to improve the aesthetic quality of an image. However, it is challenging to evaluate whether cropping leads to aesthetically pleasing results because the assessment is typically subjective. In this paper, we propose a novel cascaded cropping regression (CCR) method to perform image cropping by learning the knowledge from professional photographers. The proposed CCR method improves the convergence speed of the cascaded method, which directly uses random-ferns regressors. In addition, a two-step learning strategy is proposed and used in the CCR method to address the problem of lacking labelled cropping data. Specifically, a deep convolutional neural network (CNN) classifier is first trained on large-scale visual aesthetic datasets. The deep CNN model is then designed to extract features from several image cropping datasets, upon which the cropping bounding boxes are predicted by the proposed CCR method. Experimental results on public image cropping datasets demonstrate that the proposed method significantly outperforms several state-of-the-art image cropping methods.
Real-time Semantic Image Segmentation via Spatial Sparsity
Dec 01, 2017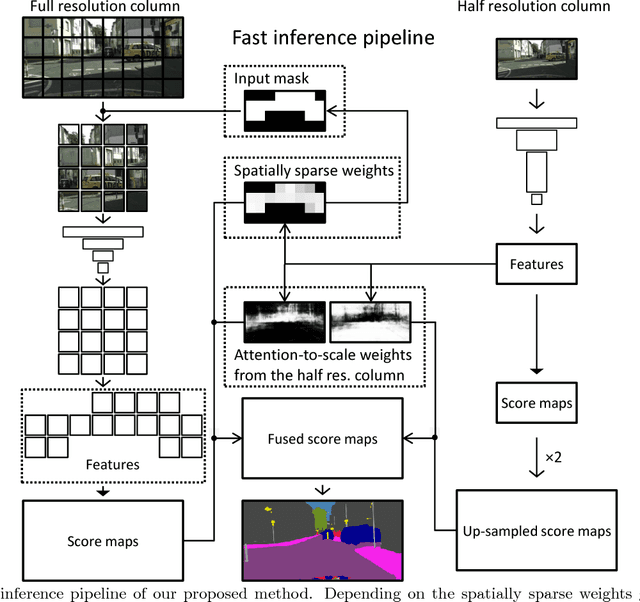

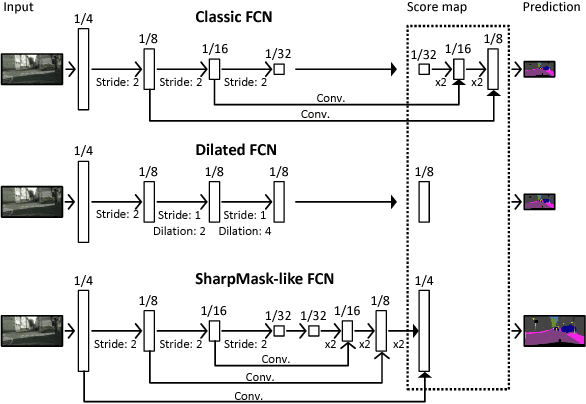
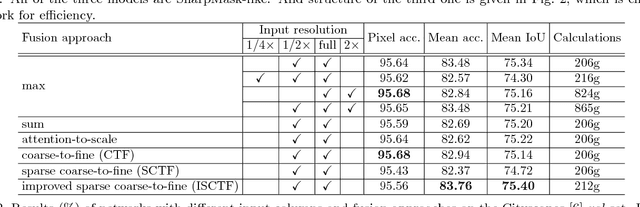
We propose an approach to semantic (image) segmentation that reduces the computational costs by a factor of 25 with limited impact on the quality of results. Semantic segmentation has a number of practical applications, and for most such applications the computational costs are critical. The method follows a typical two-column network structure, where one column accepts an input image, while the other accepts a half-resolution version of that image. By identifying specific regions in the full-resolution image that can be safely ignored, as well as carefully tailoring the network structure, we can process approximately 15 highresolution Cityscapes images (1024x2048) per second using a single GTX 980 video card, while achieving a mean intersection-over-union score of 72.9% on the Cityscapes test set.
FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors
Nov 29, 2017
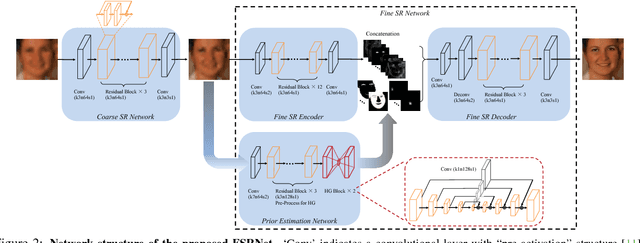

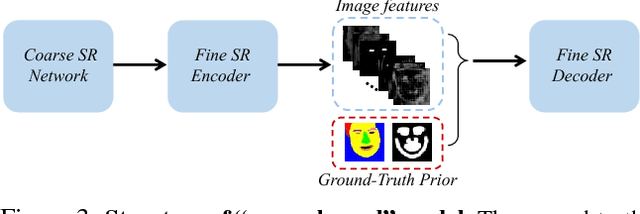
Face Super-Resolution (SR) is a domain-specific super-resolution problem. The specific facial prior knowledge could be leveraged for better super-resolving face images. We present a novel deep end-to-end trainable Face Super-Resolution Network (FSRNet), which makes full use of the geometry prior, i.e., facial landmark heatmaps and parsing maps, to super-resolve very low-resolution (LR) face images without well-aligned requirement. Specifically, we first construct a coarse SR network to recover a coarse high-resolution (HR) image. Then, the coarse HR image is sent to two branches: a fine SR encoder and a prior information estimation network, which extracts the image features, and estimates landmark heatmaps/parsing maps respectively. Both image features and prior information are sent to a fine SR decoder to recover the HR image. To further generate realistic faces, we propose the Face Super-Resolution Generative Adversarial Network (FSRGAN) to incorporate the adversarial loss into FSRNet. Moreover, we introduce two related tasks, face alignment and parsing, as the new evaluation metrics for face SR, which address the inconsistency of classic metrics w.r.t. visual perception. Extensive benchmark experiments show that FSRNet and FSRGAN significantly outperforms state of the arts for very LR face SR, both quantitatively and qualitatively. Code will be made available upon publication.
Asking the Difficult Questions: Goal-Oriented Visual Question Generation via Intermediate Rewards
Nov 21, 2017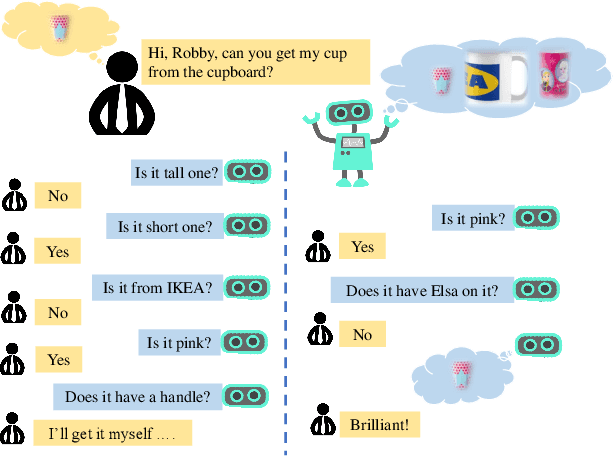
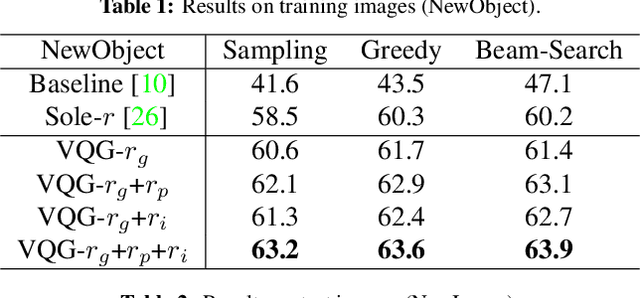
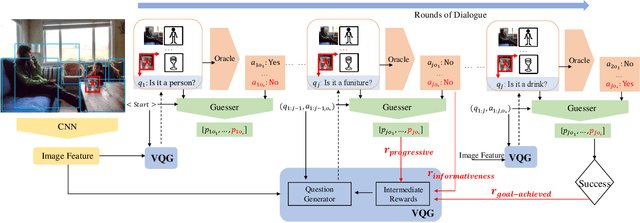
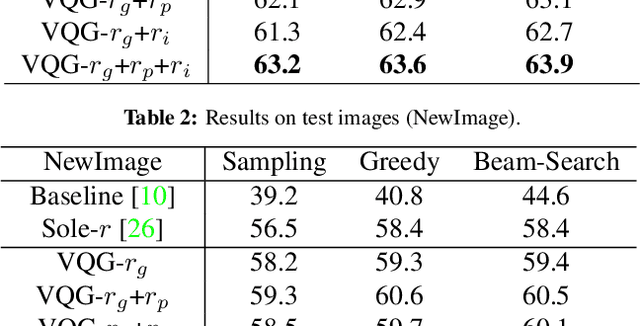
Despite significant progress in a variety of vision-and-language problems, developing a method capable of asking intelligent, goal-oriented questions about images is proven to be an inscrutable challenge. Towards this end, we propose a Deep Reinforcement Learning framework based on three new intermediate rewards, namely goal-achieved, progressive and informativeness that encourage the generation of succinct questions, which in turn uncover valuable information towards the overall goal. By directly optimizing for questions that work quickly towards fulfilling the overall goal, we avoid the tendency of existing methods to generate long series of insane queries that add little value. We evaluate our model on the GuessWhat?! dataset and show that the resulting questions can help a standard Guesser identify a specific object in an image at a much higher success rate.
Are You Talking to Me? Reasoned Visual Dialog Generation through Adversarial Learning
Nov 21, 2017
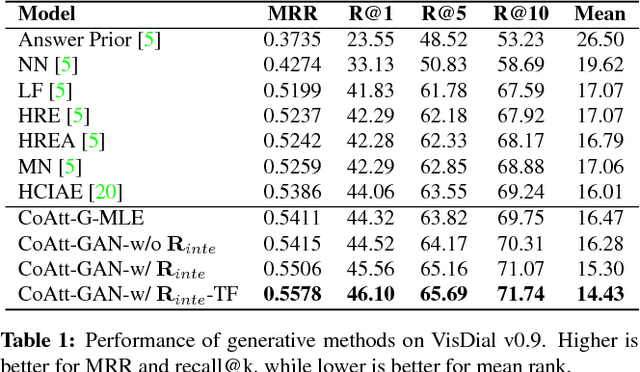
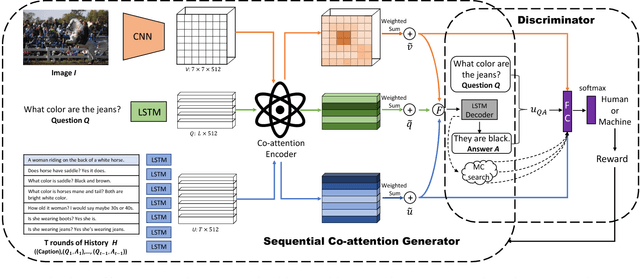
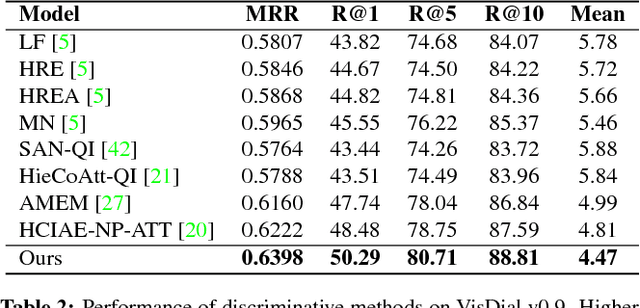
The Visual Dialogue task requires an agent to engage in a conversation about an image with a human. It represents an extension of the Visual Question Answering task in that the agent needs to answer a question about an image, but it needs to do so in light of the previous dialogue that has taken place. The key challenge in Visual Dialogue is thus maintaining a consistent, and natural dialogue while continuing to answer questions correctly. We present a novel approach that combines Reinforcement Learning and Generative Adversarial Networks (GANs) to generate more human-like responses to questions. The GAN helps overcome the relative paucity of training data, and the tendency of the typical MLE-based approach to generate overly terse answers. Critically, the GAN is tightly integrated into the attention mechanism that generates human-interpretable reasons for each answer. This means that the discriminative model of the GAN has the task of assessing whether a candidate answer is generated by a human or not, given the provided reason. This is significant because it drives the generative model to produce high quality answers that are well supported by the associated reasoning. The method also generates the state-of-the-art results on the primary benchmark.
Kill Two Birds with One Stone: Weakly-Supervised Neural Network for Image Annotation and Tag Refinement
Nov 19, 2017

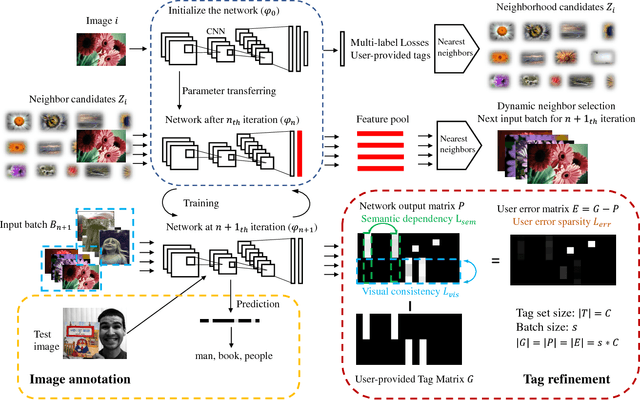
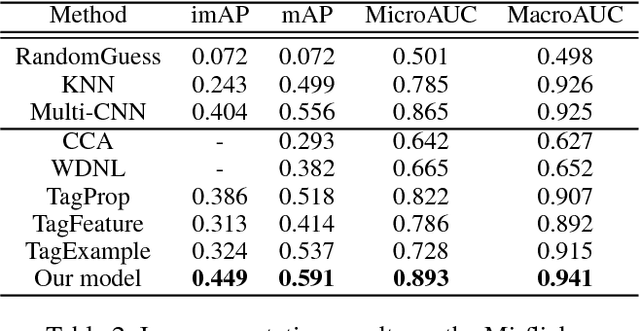
The number of social images has exploded by the wide adoption of social networks, and people like to share their comments about them. These comments can be a description of the image, or some objects, attributes, scenes in it, which are normally used as the user-provided tags. However, it is well-known that user-provided tags are incomplete and imprecise to some extent. Directly using them can damage the performance of related applications, such as the image annotation and retrieval. In this paper, we propose to learn an image annotation model and refine the user-provided tags simultaneously in a weakly-supervised manner. The deep neural network is utilized as the image feature learning and backbone annotation model, while visual consistency, semantic dependency, and user-error sparsity are introduced as the constraints at the batch level to alleviate the tag noise. Therefore, our model is highly flexible and stable to handle large-scale image sets. Experimental results on two benchmark datasets indicate that our proposed model achieves the best performance compared to the state-of-the-art methods.
Parallel Attention: A Unified Framework for Visual Object Discovery through Dialogs and Queries
Nov 17, 2017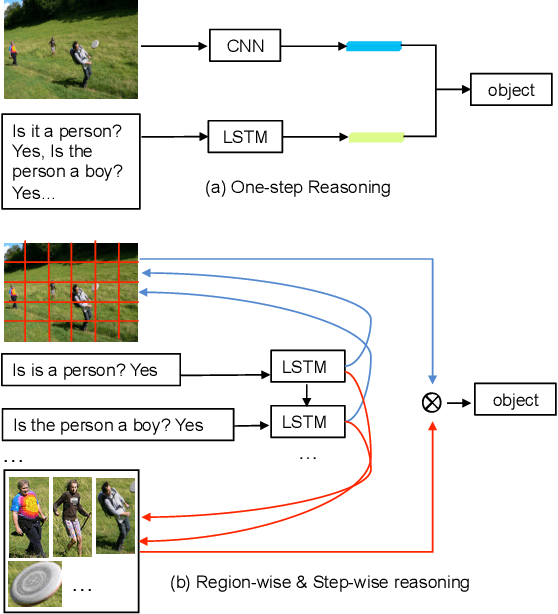
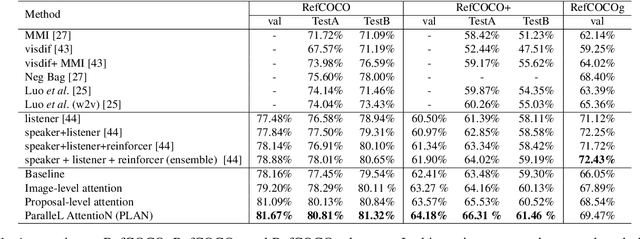
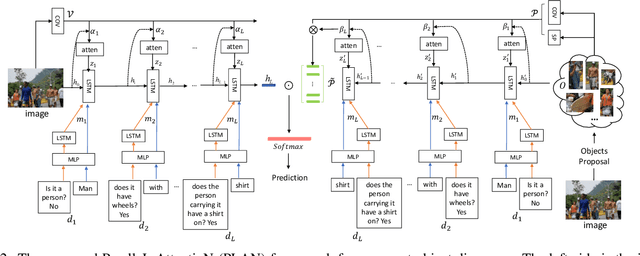
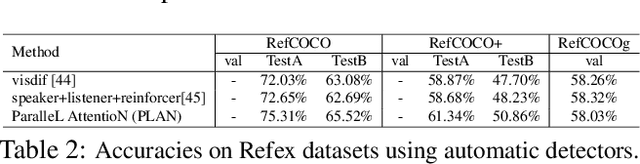
Recognising objects according to a pre-defined fixed set of class labels has been well studied in the Computer Vision. There are a great many practical applications where the subjects that may be of interest are not known beforehand, or so easily delineated, however. In many of these cases natural language dialog is a natural way to specify the subject of interest, and the task achieving this capability (a.k.a, Referring Expression Comprehension) has recently attracted attention. To this end we propose a unified framework, the ParalleL AttentioN (PLAN) network, to discover the object in an image that is being referred to in variable length natural expression descriptions, from short phrases query to long multi-round dialogs. The PLAN network has two attention mechanisms that relate parts of the expressions to both the global visual content and also directly to object candidates. Furthermore, the attention mechanisms are recurrent, making the referring process visualizable and explainable. The attended information from these dual sources are combined to reason about the referred object. These two attention mechanisms can be trained in parallel and we find the combined system outperforms the state-of-art on several benchmarked datasets with different length language input, such as RefCOCO, RefCOCO+ and GuessWhat?!.
Towards Effective Low-bitwidth Convolutional Neural Networks
Nov 17, 2017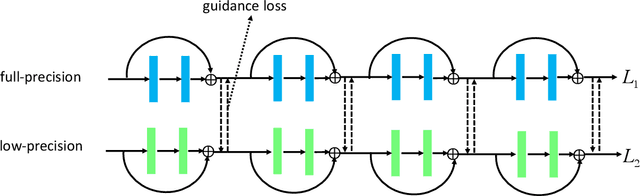

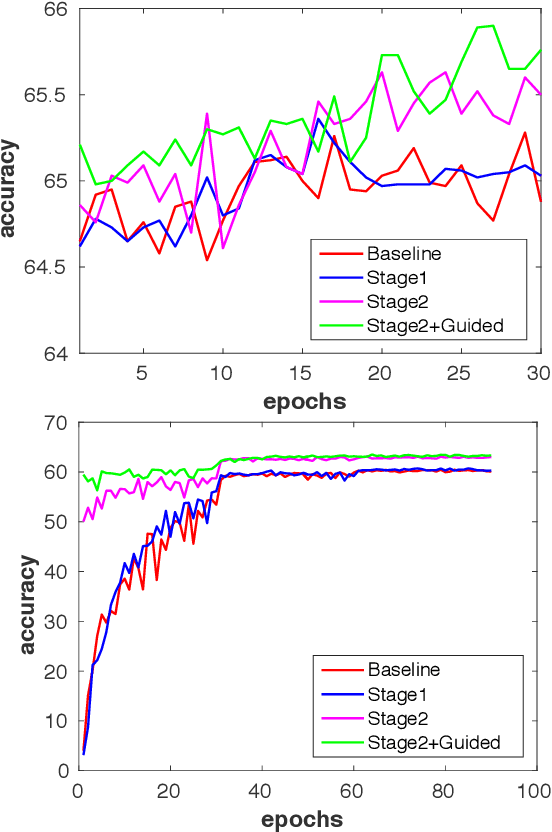
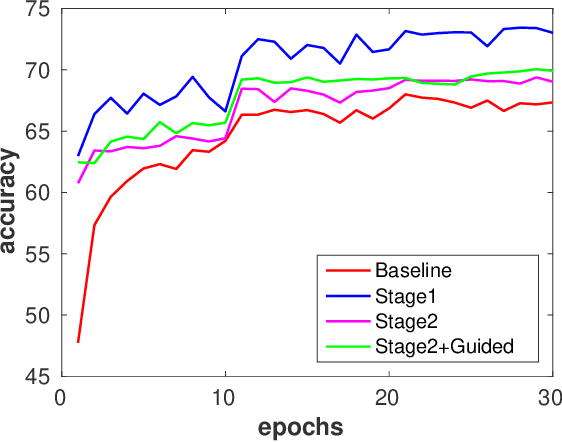
This paper tackles the problem of training a deep convolutional neural network with both low-precision weights and low-bitwidth activations. Optimizing a low-precision network is very challenging since the training process can easily get trapped in a poor local minima, which results in substantial accuracy loss. To mitigate this problem, we propose three simple-yet-effective approaches to improve the network training. First, we propose to use a two-stage optimization strategy to progressively find good local minima. Specifically, we propose to first optimize a net with quantized weights and then quantized activations. This is in contrast to the traditional methods which optimize them simultaneously. Second, following a similar spirit of the first method, we propose another progressive optimization approach which progressively decreases the bit-width from high-precision to low-precision during the course of training. Third, we adopt a novel learning scheme to jointly train a full-precision model alongside the low-precision one. By doing so, the full-precision model provides hints to guide the low-precision model training. Extensive experiments on various datasets ( i.e., CIFAR-100 and ImageNet) show the effectiveness of the proposed methods. To highlight, using our methods to train a 4-bit precision network leads to no performance decrease in comparison with its full-precision counterpart with standard network architectures ( i.e., AlexNet and ResNet-50).
Adversarial Generation of Training Examples: Applications to Moving Vehicle License Plate Recognition
Nov 10, 2017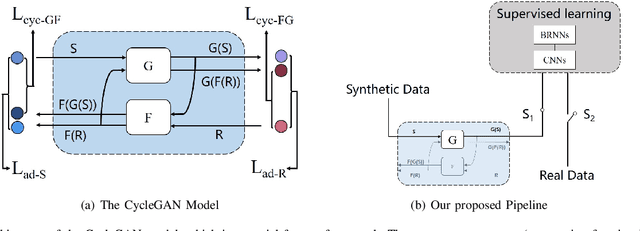

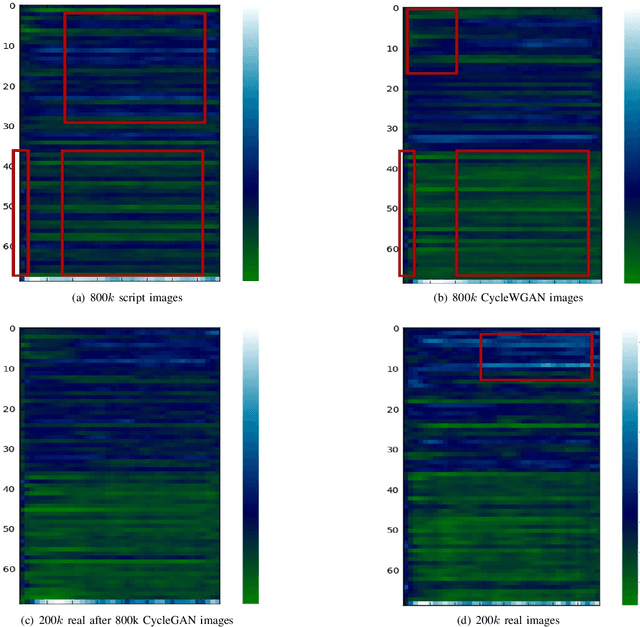

Generative Adversarial Networks (GAN) have attracted much research attention recently, leading to impressive results for natural image generation. However, to date little success was observed in using GAN generated images for improving classification tasks. Here we attempt to explore, in the context of car license plate recognition, whether it is possible to generate synthetic training data using GAN to improve recognition accuracy. With a carefully-designed pipeline, we show that the answer is affirmative. First, a large-scale image set is generated using the generator of GAN, without manual annotation. Then, these images are fed to a deep convolutional neural network (DCNN) followed by a bidirectional recurrent neural network (BRNN) with long short-term memory (LSTM), which performs the feature learning and sequence labelling. Finally, the pre-trained model is fine-tuned on real images. Our experimental results on a few data sets demonstrate the effectiveness of using GAN images: an improvement of 7.5% over a strong baseline with moderate-sized real data being available. We show that the proposed framework achieves competitive recognition accuracy on challenging test datasets. We also leverage the depthwise separate convolution to construct a lightweight convolutional RNN, which is about half size and 2x faster on CPU. Combining this framework and the proposed pipeline, we make progress in performing accurate recognition on mobile and embedded devices.
Towards End-to-End Car License Plates Detection and Recognition with Deep Neural Networks
Sep 26, 2017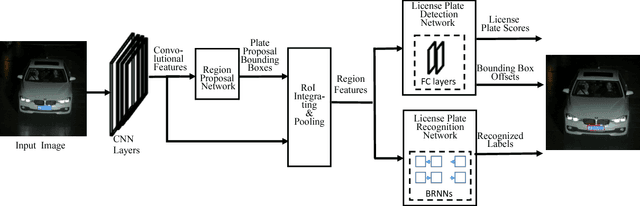
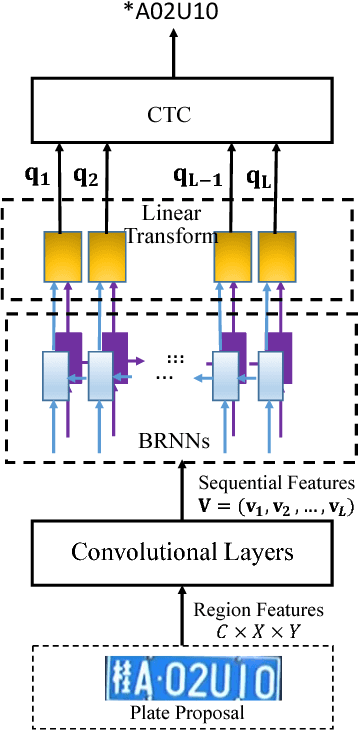

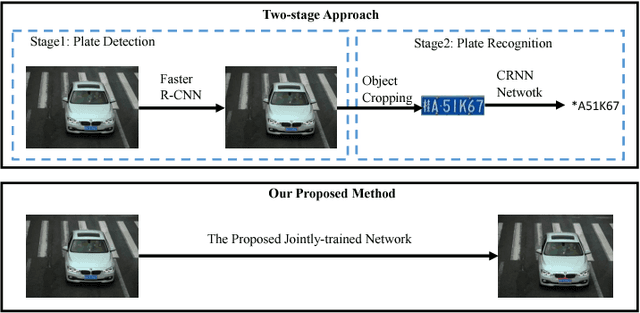
In this work, we tackle the problem of car license plate detection and recognition in natural scene images. We propose a unified deep neural network which can localize license plates and recognize the letters simultaneously in a single forward pass. The whole network can be trained end-to-end. In contrast to existing approaches which take license plate detection and recognition as two separate tasks and settle them step by step, our method jointly solves these two tasks by a single network. It not only avoids intermediate error accumulation, but also accelerates the processing speed. For performance evaluation, three datasets including images captured from various scenes under different conditions are tested. Extensive experiments show the effectiveness and efficiency of our proposed approach.