 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Propagation-based Methods for Video Object Segmentation
Jul 30, 2019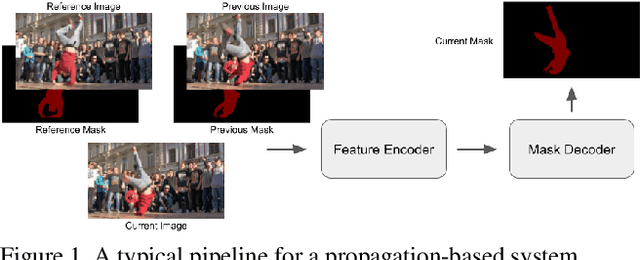
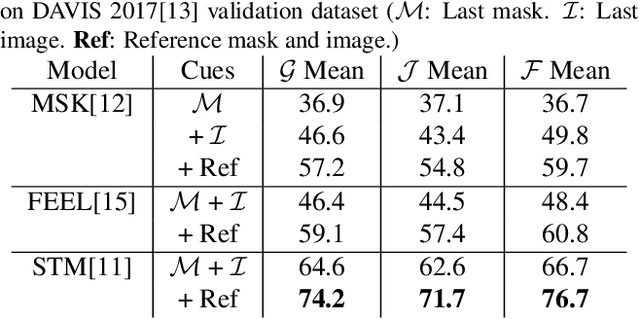
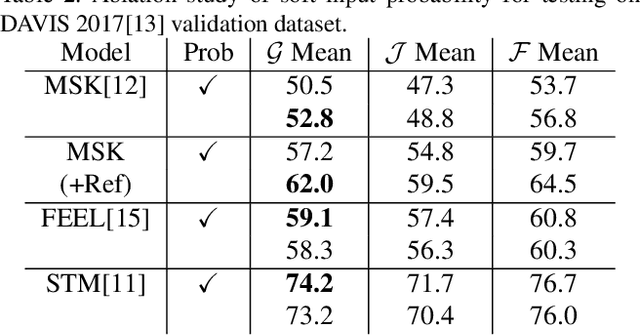
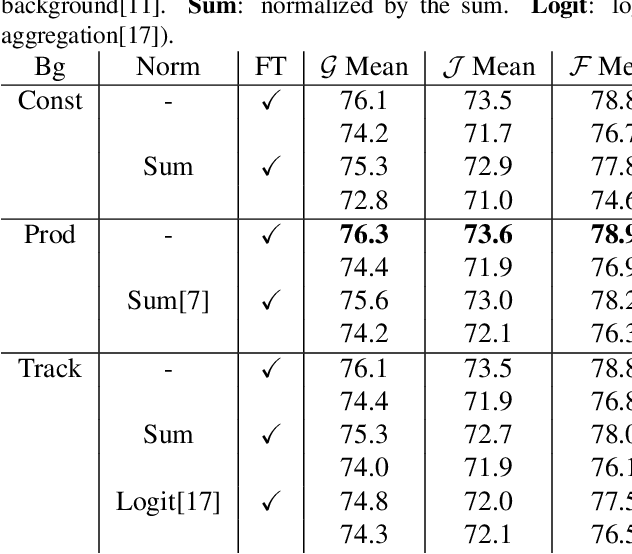
While propagation-based approaches have achieved state-of-the-art performance for video object segmentation, the literature lacks a fair comparison of different methods using the same settings. In this paper, we carry out an empirical study for propagation-based methods. We view these approaches from a unified perspective and conduct detailed ablation study for core methods, input cues, multi-object combination and training strategies. With careful designs, our improved end-to-end memory networks achieve a global mean of 76.1 on DAVIS 2017 val set.
A Fast Face Detection Method via Convolutional Neural Network
Mar 27, 2018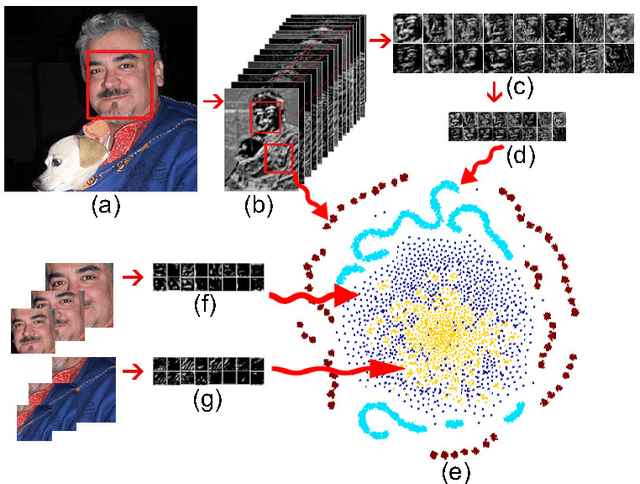
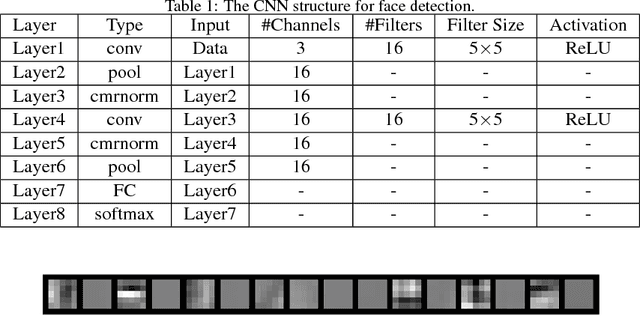
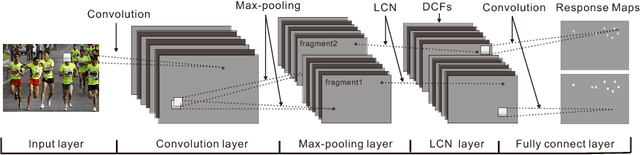
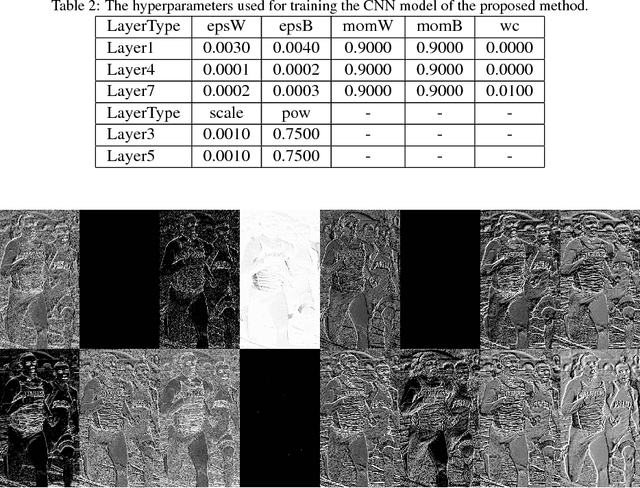
Current face or object detection methods via convolutional neural network (such as OverFeat, R-CNN and DenseNet) explicitly extract multi-scale features based on an image pyramid. However, such a strategy increases the computational burden for face detection. In this paper, we propose a fast face detection method based on discriminative complete features (DCFs) extracted by an elaborately designed convolutional neural network, where face detection is directly performed on the complete feature maps. DCFs have shown the ability of scale invariance, which is beneficial for face detection with high speed and promising performance. Therefore, extracting multi-scale features on an image pyramid employed in the conventional methods is not required in the proposed method, which can greatly improve its efficiency for face detection. Experimental results on several popular face detection datasets show the efficiency and the effectiveness of the proposed method for face detection.
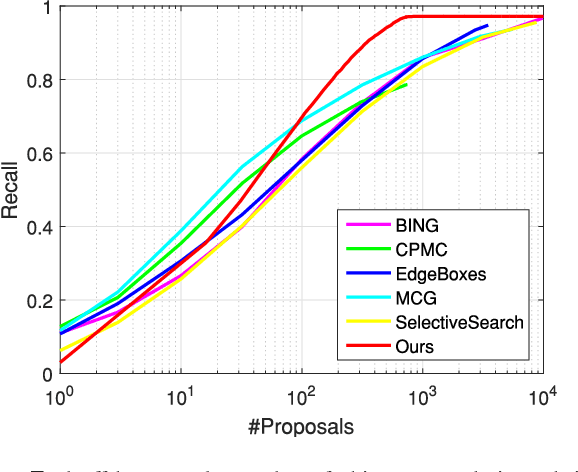
A New Target-specific Object Proposal Generation Method for Visual Tracking
Mar 27, 2018

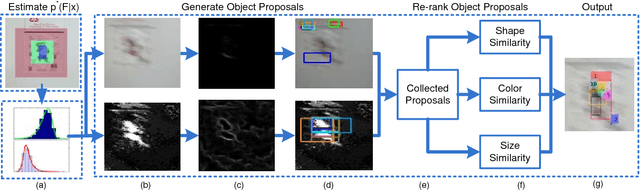

Object proposal generation methods have been widely applied to many computer vision tasks. However, existing object proposal generation methods often suffer from the problems of motion blur, low contrast, deformation, etc., when they are applied to video related tasks. In this paper, we propose an effective and highly accurate target-specific object proposal generation (TOPG) method, which takes full advantage of the context information of a video to alleviate these problems. Specifically, we propose to generate target-specific object proposals by integrating the information of two important objectness cues: colors and edges, which are complementary to each other for different challenging environments in the process of generating object proposals. As a result, the recall of the proposed TOPG method is significantly increased. Furthermore, we propose an object proposal ranking strategy to increase the rank accuracy of the generated object proposals. The proposed TOPG method has yielded significant recall gain (about 20%-60% higher) compared with several state-of-the-art object proposal methods on several challenging visual tracking datasets. Then, we apply the proposed TOPG method to the task of visual tracking and propose a TOPG-based tracker (called as TOPGT), where TOPG is used as a sample selection strategy to select a small number of high-quality target candidates from the generated object proposals. Since the object proposals generated by the proposed TOPG cover many hard negative samples and positive samples, these object proposals can not only be used for training an effective classifier, but also be used as target candidates for visual tracking. Experimental results show the superior performance of TOPGT for visual tracking compared with several other state-of-the-art visual trackers (about 3%-11% higher than the winner of the VOT2015 challenge in term of distance precision).
Automatic Image Cropping for Visual Aesthetic Enhancement Using Deep Neural Networks and Cascaded Regression
Jan 14, 2018
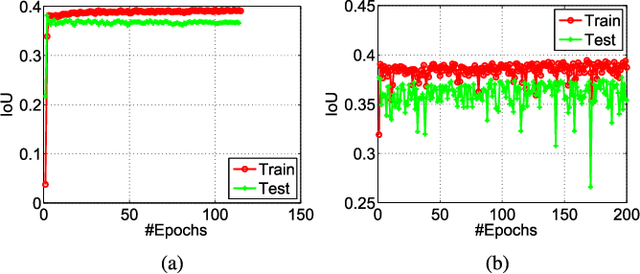
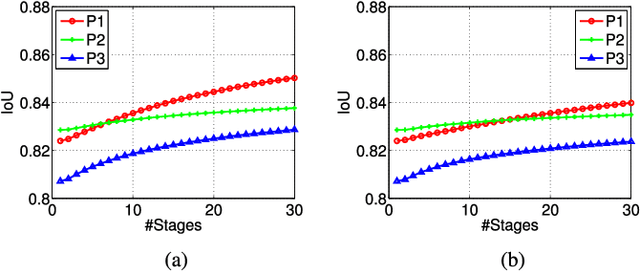

Despite recent progress, computational visual aesthetic is still challenging. Image cropping, which refers to the removal of unwanted scene areas, is an important step to improve the aesthetic quality of an image. However, it is challenging to evaluate whether cropping leads to aesthetically pleasing results because the assessment is typically subjective. In this paper, we propose a novel cascaded cropping regression (CCR) method to perform image cropping by learning the knowledge from professional photographers. The proposed CCR method improves the convergence speed of the cascaded method, which directly uses random-ferns regressors. In addition, a two-step learning strategy is proposed and used in the CCR method to address the problem of lacking labelled cropping data. Specifically, a deep convolutional neural network (CNN) classifier is first trained on large-scale visual aesthetic datasets. The deep CNN model is then designed to extract features from several image cropping datasets, upon which the cropping bounding boxes are predicted by the proposed CCR method. Experimental results on public image cropping datasets demonstrate that the proposed method significantly outperforms several state-of-the-art image cropping methods.
Object Discovery via Cohesion Measurement
Apr 28, 2017
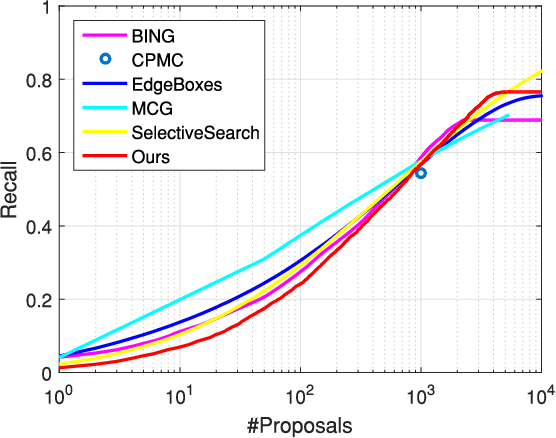

Color and intensity are two important components in an image. Usually, groups of image pixels, which are similar in color or intensity, are an informative representation for an object. They are therefore particularly suitable for computer vision tasks, such as saliency detection and object proposal generation. However, image pixels, which share a similar real-world color, may be quite different since colors are often distorted by intensity. In this paper, we reinvestigate the affinity matrices originally used in image segmentation methods based on spectral clustering. A new affinity matrix, which is robust to color distortions, is formulated for object discovery. Moreover, a Cohesion Measurement (CM) for object regions is also derived based on the formulated affinity matrix. Based on the new Cohesion Measurement, a novel object discovery method is proposed to discover objects latent in an image by utilizing the eigenvectors of the affinity matrix. Then we apply the proposed method to both saliency detection and object proposal generation. Experimental results on several evaluation benchmarks demonstrate that the proposed CM based method has achieved promising performance for these two tasks.
* 14 pages, 14 figures