 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorizing Comprehensively to Learn Adaptively: Unsupervised Cross-Domain Person Re-ID with Multi-level Memory
Jan 13, 2020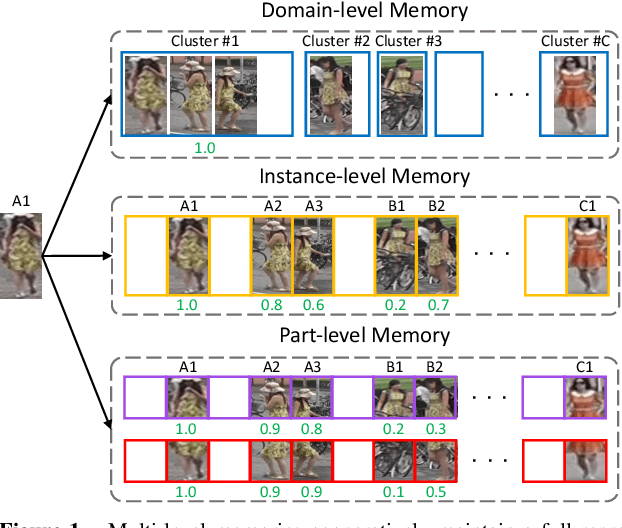
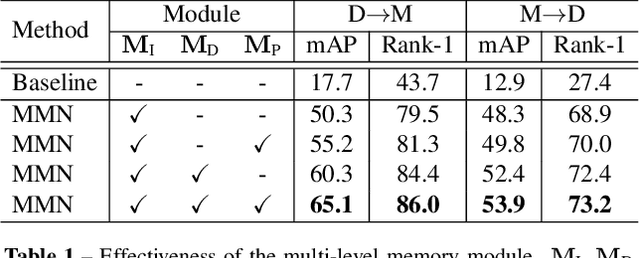
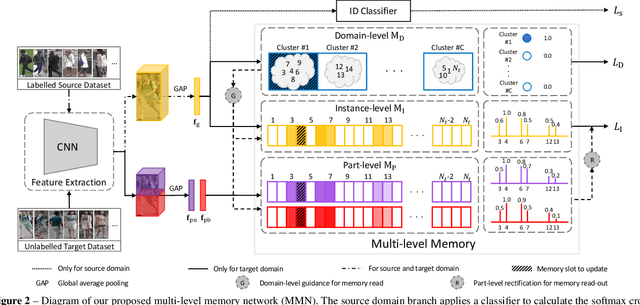
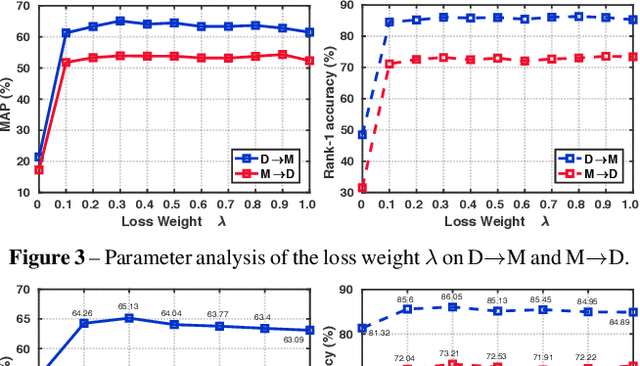
Unsupervised cross-domain person re-identification (Re-ID) aims to adapt the information from the labelled source domain to an unlabelled target domain. Due to the lack of supervision in the target domain, it is crucial to identify the underlying similarity-and-dissimilarity relationships among the unlabelled samples in the target domain. In order to use the whole data relationships efficiently in mini-batch training, we apply a series of memory modules to maintain an up-to-date representation of the entire dataset. Unlike the simple exemplar memory in previous works, we propose a novel multi-level memory network (MMN) to discover multi-level complementary information in the target domain, relying on three memory modules, i.e., part-level memory, instance-level memory, and domain-level memory. The proposed memory modules store multi-level representations of the target domain, which capture both the fine-grained differences between images and the global structure for the holistic target domain. The three memory modules complement each other and systematically integrate multi-level supervision from bottom to up. Experiments on three datasets demonstrate that the multi-level memory modules cooperatively boost the unsupervised cross-domain Re-ID task, and the proposed MMN achieves competitive results.
From Open Set to Closed Set: Supervised Spatial Divide-and-Conquer for Object Counting
Jan 07, 2020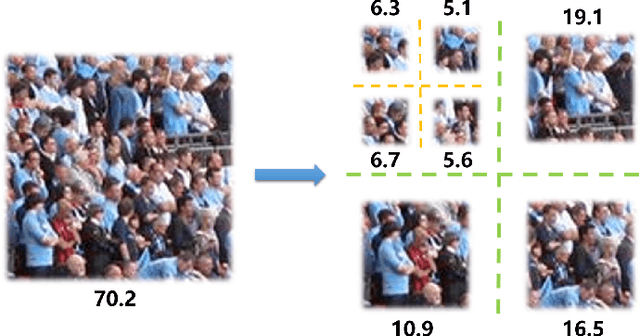

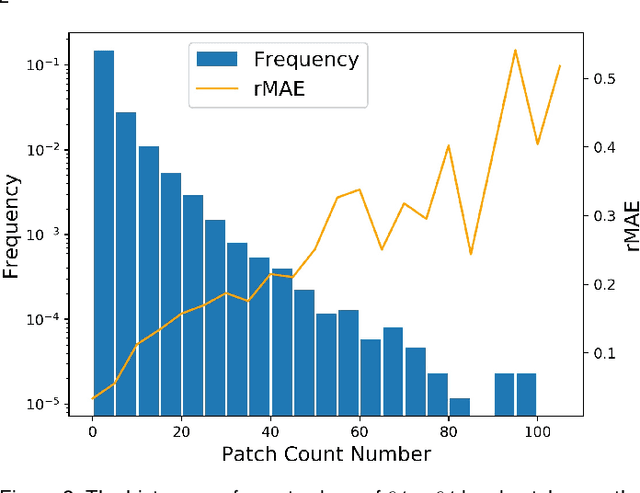
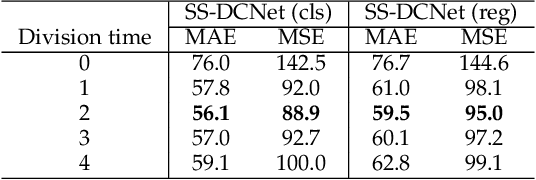
Visual counting, a task that aims to estimate the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in [0, inf) in theory. However, collected data and labeled instances are limited in reality, which means that only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are prone to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting has an interesting and exclusive property---spatially decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. We therefore introduce the idea of spatial divide-and-conquer (S-DC) that transforms open-set counting into a closed-set problem. This idea is implemented by a novel Supervised Spatial Divide-and-Conquer Network (SS-DCNet). Thus, SS-DCNet can only learn from a closed set but generalize well to open-set scenarios via S-DC. SS-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. We provide theoretical analyses as well as a controlled experiment on toy data, demonstrating why closed-set modeling makes sense. Extensive experiments show that SS-DCNet achieves the state-of-the-art performance. Code and models are available at: https://tinyurl.com/SS-DCNet.
Learning and Memorizing Representative Prototypes for 3D Point Cloud Semantic and Instance Segmentation
Jan 06, 2020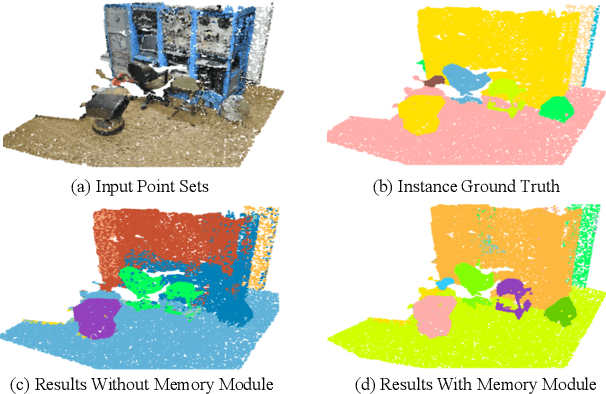
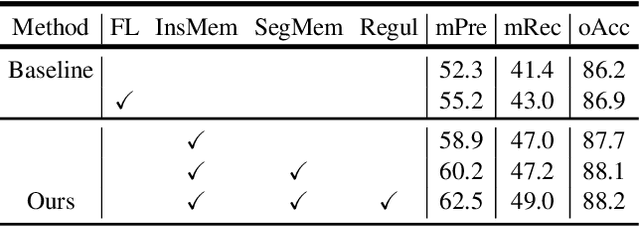
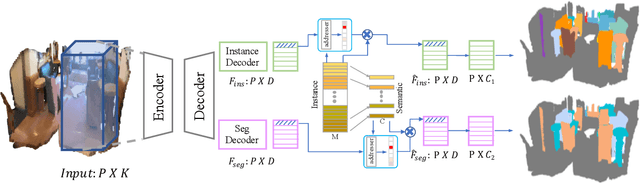
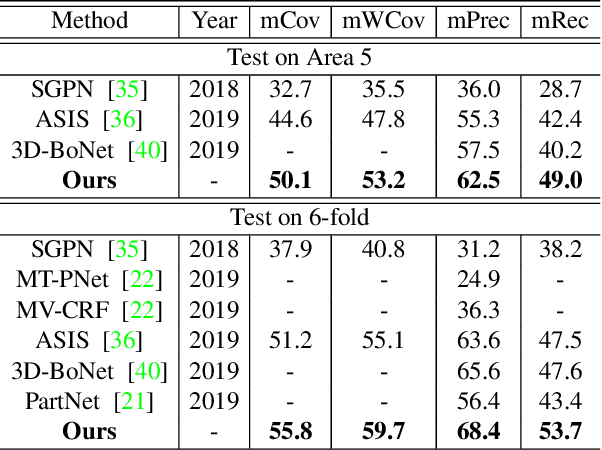
3D point cloud semantic and instance segmentation is crucial and fundamental for 3D scene understanding. Due to the complex structure, point sets are distributed off balance and diversely, which appears as both category imbalance and pattern imbalance. As a result, deep networks can easily forget the non-dominant cases during the learning process, resulting in unsatisfactory performance. Although re-weighting can reduce the influence of the well-classified examples, they cannot handle the non-dominant patterns during the dynamic training. In this paper, we propose a memory-augmented network to learn and memorize the representative prototypes that cover diverse samples universally. Specifically, a memory module is introduced to alleviate the forgetting issue by recording the patterns seen in mini-batch training. The learned memory items consistently reflect the interpretable and meaningful information for both dominant and non-dominant categories and cases. The distorted observations and rare cases can thus be augmented by retrieving the stored prototypes, leading to better performances and generalization. Exhaustive experiments on the benchmarks, i.e. S3DIS and ScanNetV2, reflect the superiority of our method on both effectiveness and efficiency. Not only the overall accuracy but also nondominant classes have improved substantially.
BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
Jan 02, 2020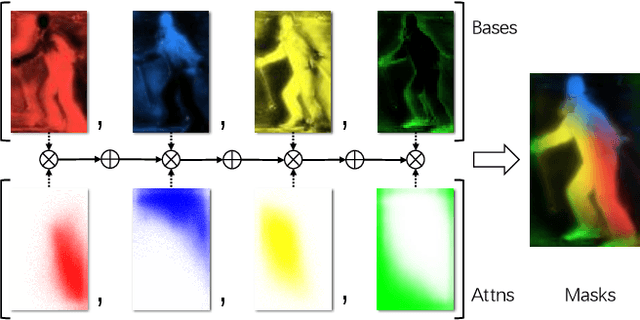
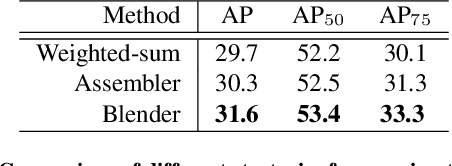
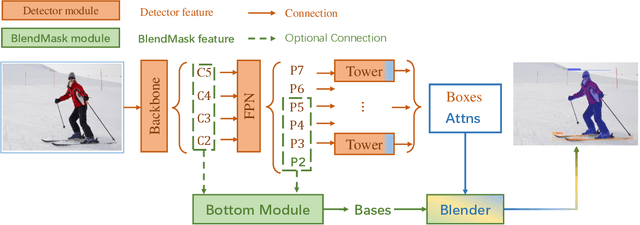
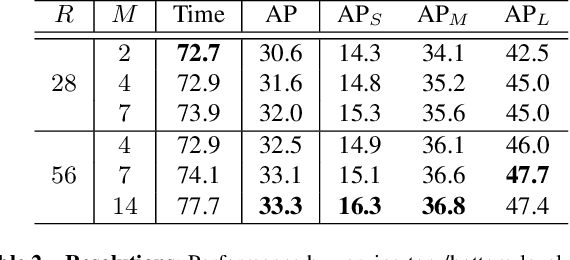
Instance segmentation is one of the fundamental vision tasks. Recently, fully convolutional instance segmentation methods have drawn much attention as they are often simpler and more efficient than two-stage approaches like Mask R-CNN. To date, almost all such approaches fall behind the two-stage Mask R-CNN method in mask precision when models have similar computation complexity, leaving great room for improvement. In this work, we achieve improved mask prediction by effectively combining instance-level information with semantic information with lower-level fine-granularity. Our main contribution is a blender module which draws inspiration from both top-down and bottom-up instance segmentation approaches. The proposed BlendMask can effectively predict dense per-pixel position-sensitive instance features with very few channels, and learn attention maps for each instance with merely one convolution layer, thus being fast in inference. BlendMask can be easily incorporated with the state-of-the-art one-stage detection frameworks and outperforms Mask R-CNN under the same training schedule while being 20% faster. A light-weight version of BlendMask achieves $ 34.2% $ mAP at 25 FPS evaluated on a single 1080Ti GPU card. Because of its simplicity and efficacy, we hope that our BlendMask could serve as a simple yet strong baseline for a wide range of instance-wise prediction tasks.
Ordered or Orderless: A Revisit for Video based Person Re-Identification
Dec 24, 2019
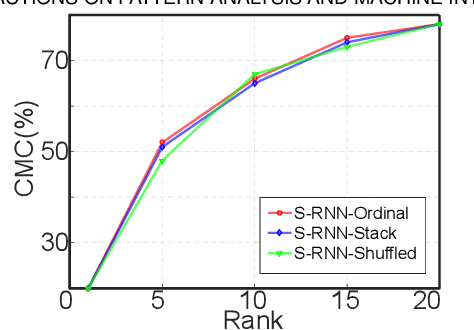
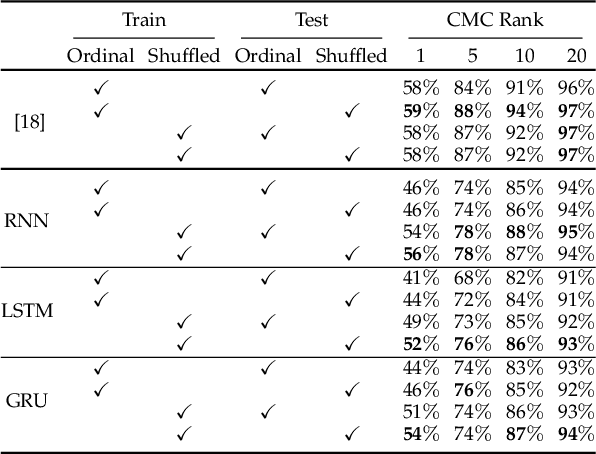
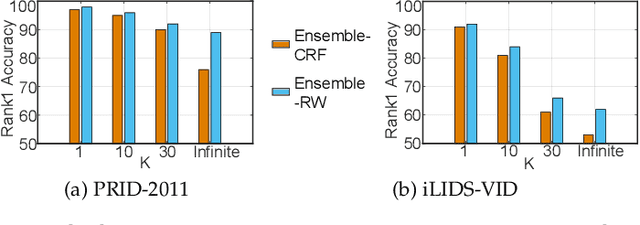
Is recurrent network really necessary for learning a good visual representation for video based person re-identification (VPRe-id)? In this paper, we first show that the common practice of employing recurrent neural networks (RNNs) to aggregate temporal spatial features may not be optimal. Specifically, with a diagnostic analysis, we show that the recurrent structure may not be effective to learn temporal dependencies than what we expected and implicitly yields an orderless representation. Based on this observation, we then present a simple yet surprisingly powerful approach for VPRe-id, where we treat VPRe-id as an efficient orderless ensemble of image based person re-identification problem. More specifically, we divide videos into individual images and re-identify person with ensemble of image based rankers. Under the i.i.d. assumption, we provide an error bound that sheds light upon how could we improve VPRe-id. Our work also presents a promising way to bridge the gap between video and image based person re-identification. Comprehensive experimental evaluations demonstrate that the proposed solution achieves state-of-the-art performances on multiple widely used datasets (iLIDS-VID, PRID 2011, and MARS).
Unsupervised Representation Learning by Predicting Random Distances
Dec 22, 2019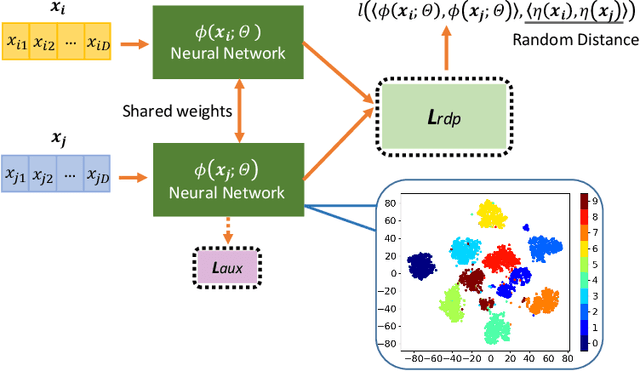
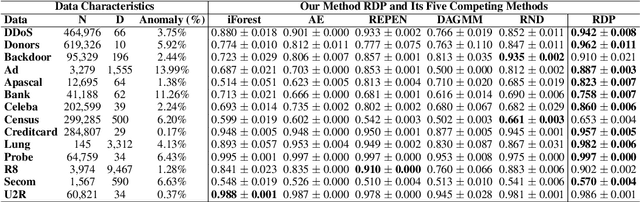

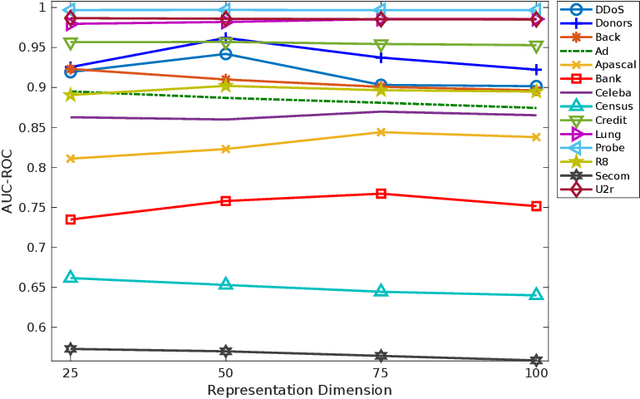
Deep neural networks have gained tremendous success in a broad range of machine learning tasks due to its remarkable capability to learn semantic-rich features from high-dimensional data. However, they often require large-scale labelled data to successfully learn such features, which significantly hinders their adaption into unsupervised learning tasks, such as anomaly detection and clustering, and limits their applications into critical domains where obtaining massive labelled data is prohibitively expensive. To enable downstream unsupervised learning on those domains, in this work we propose to learn features without using any labelled data by training neural networks to predict data distances in a randomly projected space. Random mapping is a theoretical proven approach to obtain approximately preserved distances. To well predict these random distances, the representation learner is optimised to learn genuine class structures that are implicitly embedded in the randomly projected space. Experimental results on 19 real-world datasets show our learned representations substantially outperform state-of-the-art competing methods in both anomaly detection and clustering tasks.
Exploring the Capacity of Sequential-free Box Discretization Network for Omnidirectional Scene Text Detection
Dec 20, 2019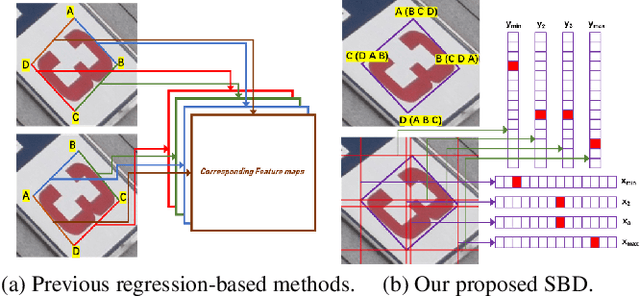

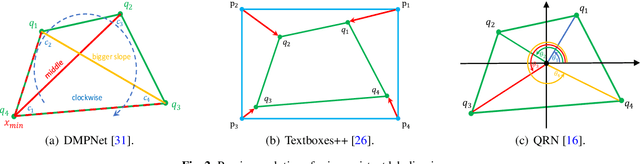

Omnidirectional scene text detection has received increasing research attention. Previous methods directly predict words or text lines of quadrilateral shapes. However, most methods neglect the significance of consistent labeling, which is important to maintain a stable training process, especially when a large amount of data are included. For the first time, we solve the problem in this paper by proposing a novel method termed Sequential-free Box Discretization (SBD). The proposed SBD first discretizes the quadrilateral box into several key edges, which contains all potential horizontal and vertical positions. In order to decode accurate vertex positions, a simple yet effective matching procedure is proposed to reconstruct the quadrilateral bounding boxes. It departs from the learning ambiguity which has a significant influence during the learning process. Exhaustive ablation studies have been conducted to quantitatively validate the effectiveness of our proposed method. More importantly, built upon SBD, we provide a detailed analysis of the impact of a collection of refinements, in the hope to inspire others to build state-of-the-art networks. Combining both SBD and these useful refinements, we achieve state-of-the-art performance on various benchmarks, including ICDAR 2015, and MLT. Our method also wins the first place in text detection task of the recent ICDAR2019 Robust Reading Challenge on Reading Chinese Text on Signboard, further demonstrating its powerful generalization ability. Code is available at https://tinyurl.com/sbdnet.
SOLO: Segmenting Objects by Locations
Dec 15, 2019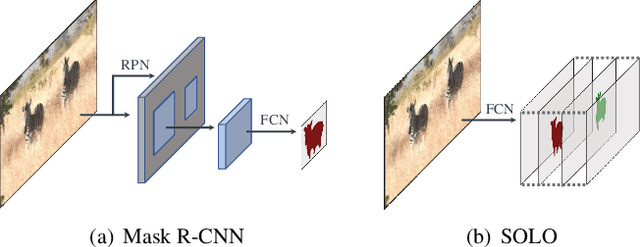
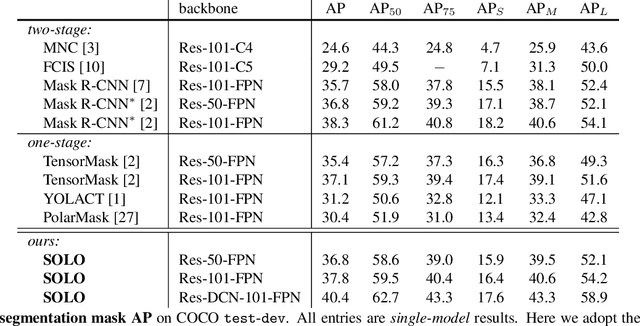
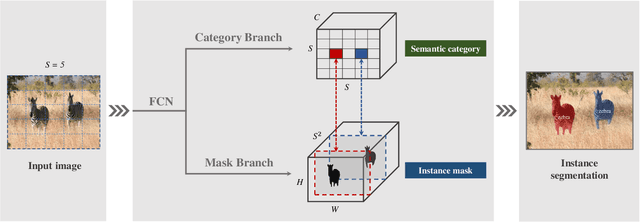
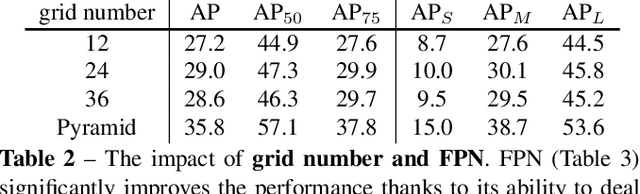
We present a new, embarrassingly simple approach to instance segmentation in images. Compared to many other dense prediction tasks, e.g., semantic segmentation, it is the arbitrary number of instances that have made instance segmentation much more challenging. In order to predict a mask for each instance, mainstream approaches either follow the 'detect-thensegment' strategy as used by Mask R-CNN, or predict category masks first then use clustering techniques to group pixels into individual instances. We view the task of instance segmentation from a completely new perspective by introducing the notion of "instance categories", which assigns categories to each pixel within an instance according to the instance's location and size, thus nicely converting instance mask segmentation into a classification-solvable problem. Now instance segmentation is decomposed into two classification tasks. We demonstrate a much simpler and flexible instance segmentation framework with strong performance, achieving on par accuracy with Mask R-CNN and outperforming recent singleshot instance segmenters in accuracy. We hope that this very simple and strong framework can serve as a baseline for many instance-level recognition tasks besides instance segmentation.
To Balance or Not to Balance: An Embarrassingly Simple Approach for Learning with Long-Tailed Distributions
Dec 10, 2019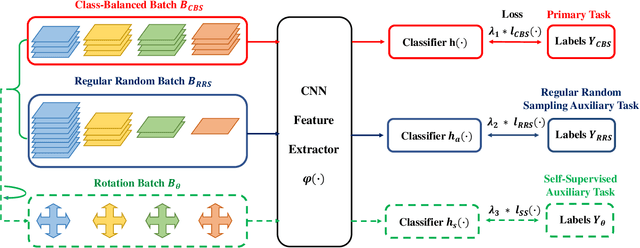
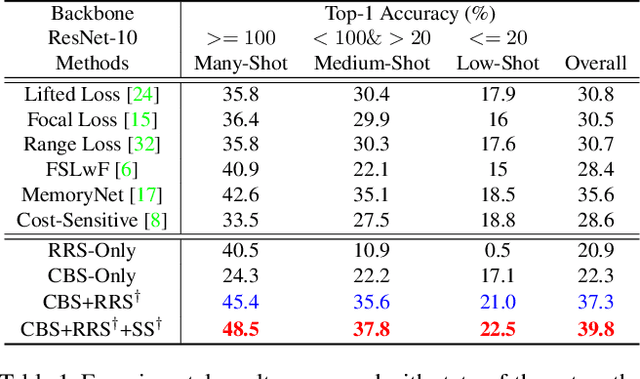
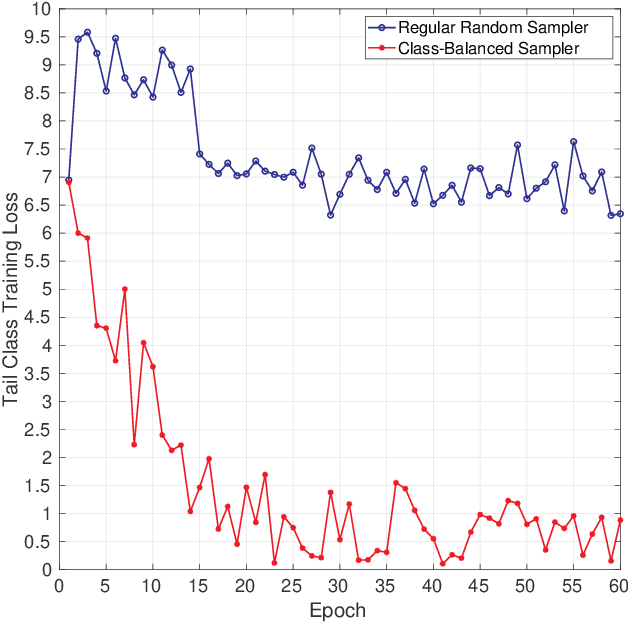
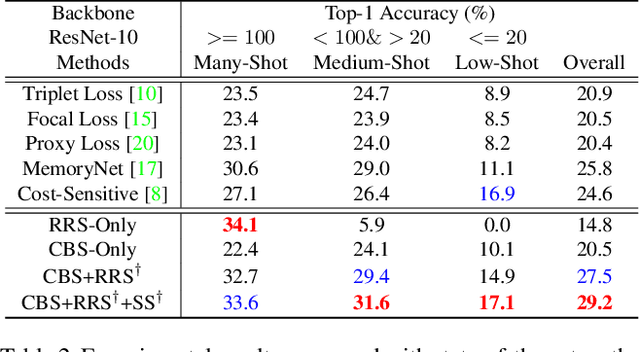
Real-world visual data often exhibits a long-tailed distribution, where some ''head'' classes have a large number of samples, yet only a few samples are available for the ''tail'' classes. Such imbalanced distribution causes a great challenge for learning a deep neural network, which can be boiled down into a dilemma: on the one hand, we prefer to increase the exposure of the tail class samples to avoid the excessive dominance of head classes in the classifier training. On the other hand, oversampling tail classes makes the network prone to over-fitting, since the head class samples are often consequently under-represented. To resolve this dilemma, in this paper, we propose an embarrassingly simple-yet-effective approach. The key idea is to split a network into a classifier part and a feature extractor part, and then employ different training strategies for each part. Specifically, to promote the awareness of tail-classes, a class-balanced sampling scheme is utilised for training both the classifier and the feature extractor. For the feature extractor, we also introduce an auxiliary training task, which is to train a classifier under the regular random sampling scheme. In this way, the feature extractor is jointly trained from both sampling strategies and thus can take advantage of all training data and avoid the over-fitting issue. Apart from this basic auxiliary task, we further explore the benefit of using self-supervised learning as the auxiliary task. Without using any bells and whistles, our model achieves superior performance over the state-of-the-art solutions.
DirectPose: Direct End-to-End Multi-Person Pose Estimation
Nov 24, 2019
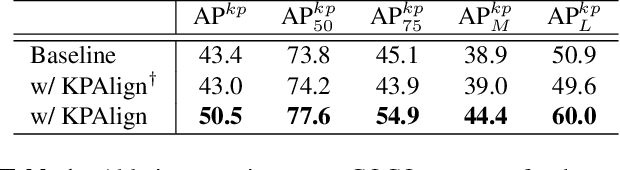
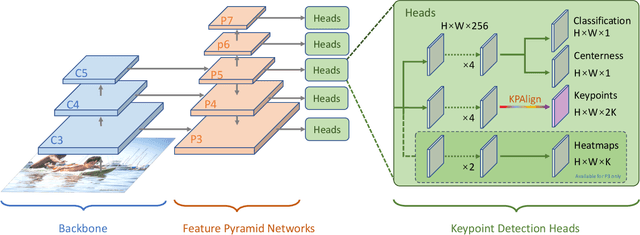
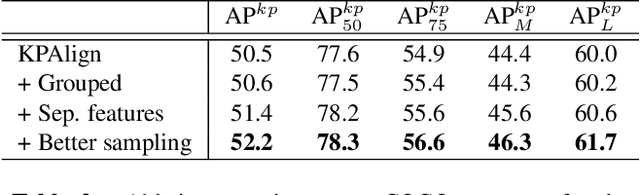
We propose the first direct end-to-end multi-person pose estimation framework, termed DirectPose. Inspired by recent anchor-free object detectors, which directly regress the two corners of target bounding-boxes, the proposed framework directly predicts instance-aware keypoints for all the instances from a raw input image, eliminating the need for heuristic grouping in bottom-up methods or bounding-box detection and RoI operations in top-down ones. We also propose a novel Keypoint Alignment (KPAlign) mechanism, which overcomes the main difficulty: lack of the alignment between the convolutional features and predictions in this end-to-end framework. KPAlign improves the framework's performance by a large margin while still keeping the framework end-to-end trainable. With the only postprocessing non-maximum suppression (NMS), our proposed framework can detect multi-person keypoints with or without bounding-boxes in a single shot. Experiments demonstrate that the end-to-end paradigm can achieve competitive or better performance than previous strong baselines, in both bottom-up and top-down methods. We hope that our end-to-end approach can provide a new perspective for the human pose estimation task.