 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning with Random-projection Quantizer for Speech Recognition
Feb 03, 2022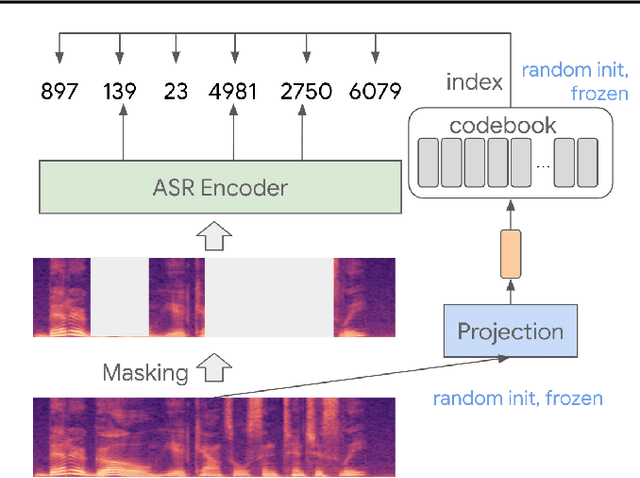

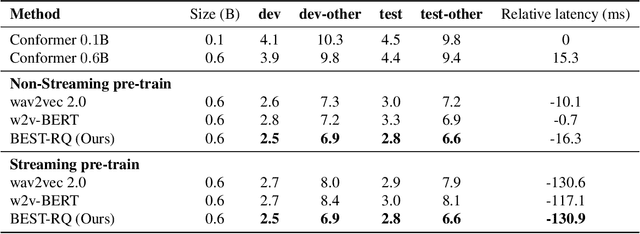
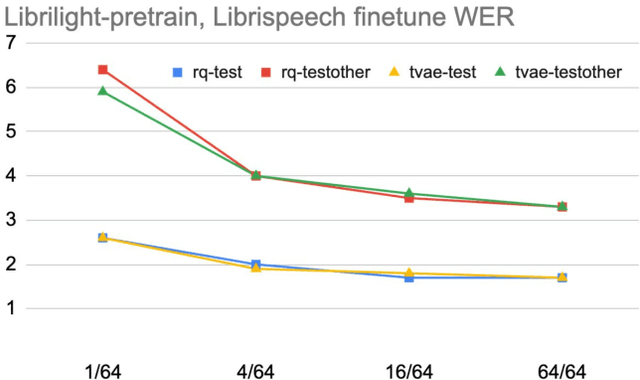
We present a simple and effective self-supervised learning approach for speech recognition. The approach learns a model to predict the masked speech signals, in the form of discrete labels generated with a random-projection quantizer. In particular the quantizer projects speech inputs with a randomly initialized matrix, and does a nearest-neighbor lookup in a randomly-initialized codebook. Neither the matrix nor the codebook is updated during self-supervised learning. Since the random-projection quantizer is not trained and is separated from the speech recognition model, the design makes the approach flexible and is compatible with universal speech recognition architecture. On LibriSpeech our approach achieves similar word-error-rates as previous work using self-supervised learning with non-streaming models, and provides lower word-error-rates and latency than wav2vec 2.0 and w2v-BERT with streaming models. On multilingual tasks the approach also provides significant improvement over wav2vec 2.0 and w2v-BERT.
Cross-attention conformer for context modeling in speech enhancement for ASR
Oct 30, 2021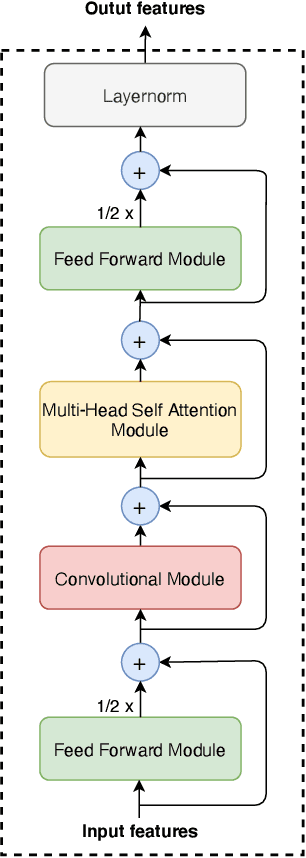
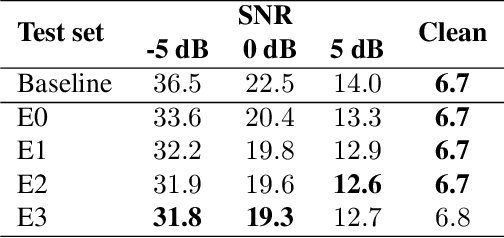
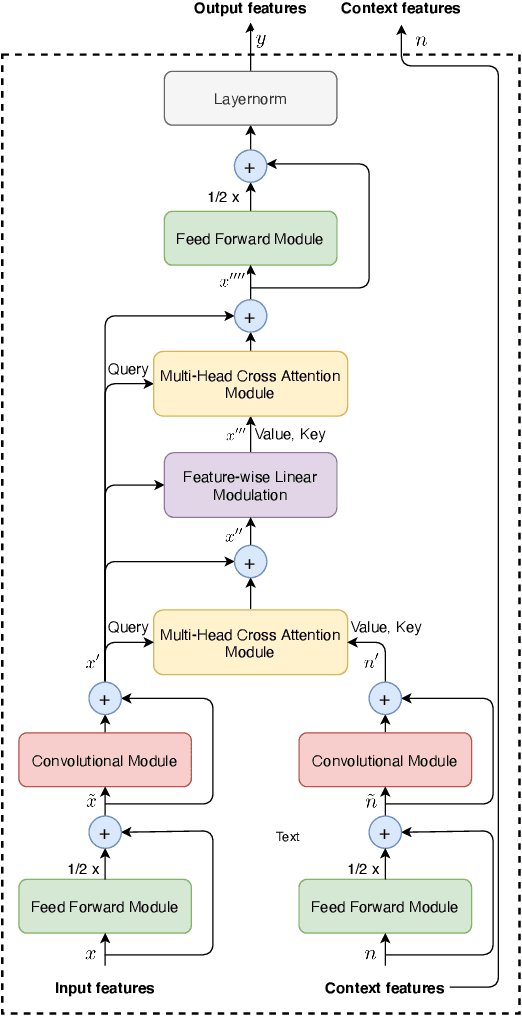
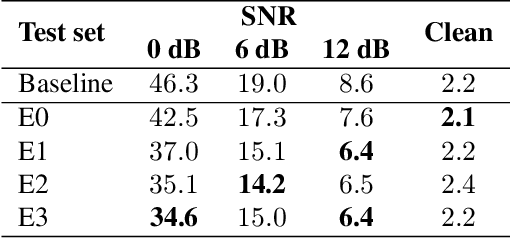
This work introduces \emph{cross-attention conformer}, an attention-based architecture for context modeling in speech enhancement. Given that the context information can often be sequential, and of different length as the audio that is to be enhanced, we make use of cross-attention to summarize and merge contextual information with input features. Building upon the recently proposed conformer model that uses self attention layers as building blocks, the proposed cross-attention conformer can be used to build deep contextual models. As a concrete example, we show how noise context, i.e., short noise-only audio segment preceding an utterance, can be used to build a speech enhancement feature frontend using cross-attention conformer layers for improving noise robustness of automatic speech recognition.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021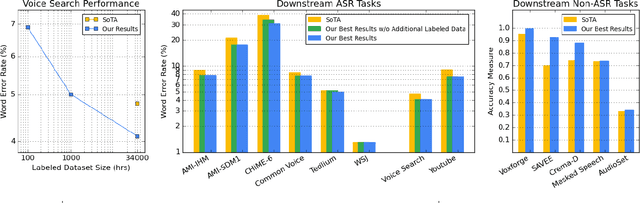
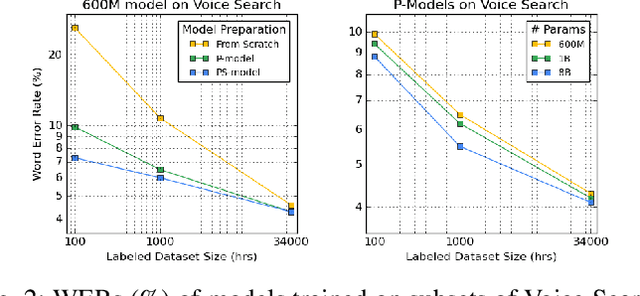
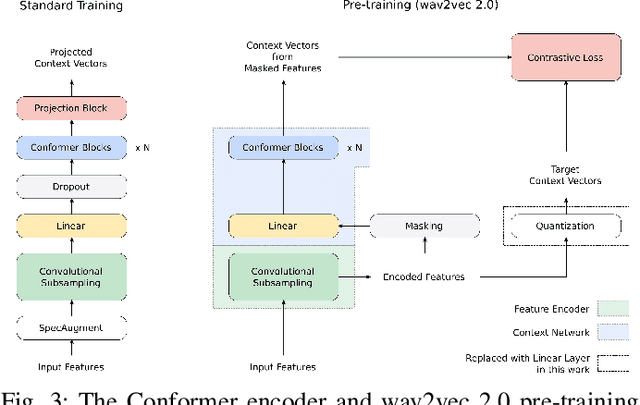
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training
Aug 07, 2021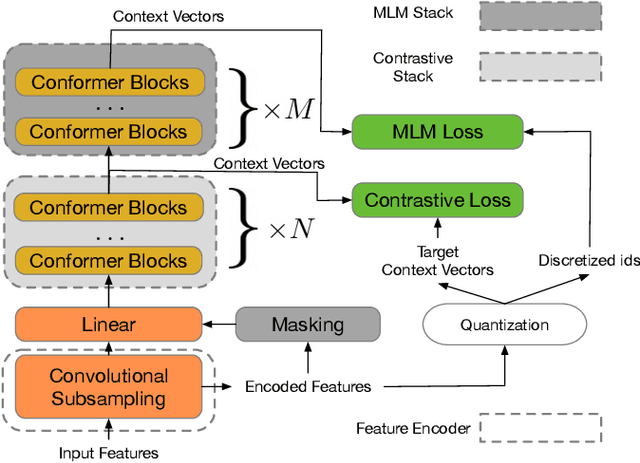

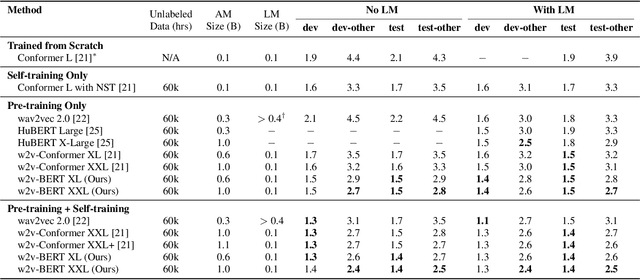
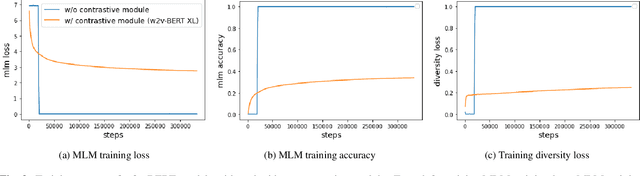
Motivated by the success of masked language modeling~(MLM) in pre-training natural language processing models, we propose w2v-BERT that explores MLM for self-supervised speech representation learning. w2v-BERT is a framework that combines contrastive learning and MLM, where the former trains the model to discretize input continuous speech signals into a finite set of discriminative speech tokens, and the latter trains the model to learn contextualized speech representations via solving a masked prediction task consuming the discretized tokens. In contrast to existing MLM-based speech pre-training frameworks such as HuBERT, which relies on an iterative re-clustering and re-training process, or vq-wav2vec, which concatenates two separately trained modules, w2v-BERT can be optimized in an end-to-end fashion by solving the two self-supervised tasks~(the contrastive task and MLM) simultaneously. Our experiments show that w2v-BERT achieves competitive results compared to current state-of-the-art pre-trained models on the LibriSpeech benchmarks when using the Libri-Light~60k corpus as the unsupervised data. In particular, when compared to published models such as conformer-based wav2vec~2.0 and HuBERT, our model shows~5\% to~10\% relative WER reduction on the test-clean and test-other subsets. When applied to the Google's Voice Search traffic dataset, w2v-BERT outperforms our internal conformer-based wav2vec~2.0 by more than~30\% relatively.
Bridging the gap between streaming and non-streaming ASR systems bydistilling ensembles of CTC and RNN-T models
Apr 25, 2021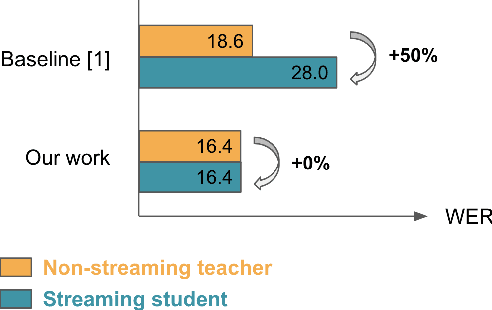
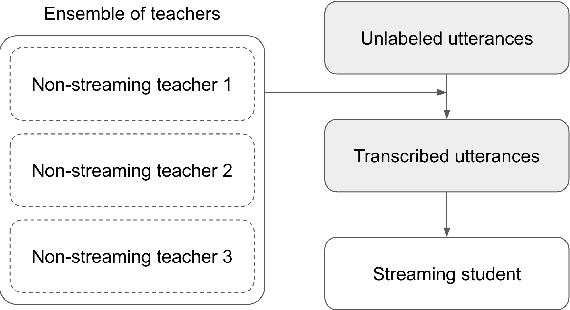

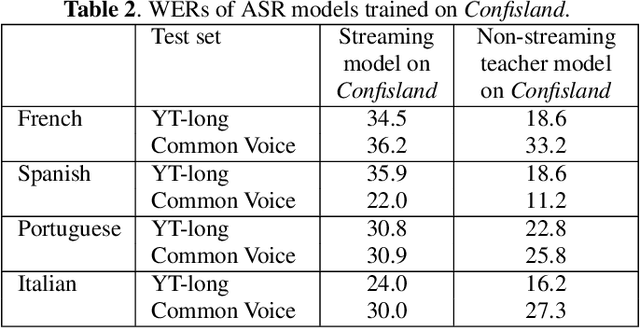
Streaming end-to-end automatic speech recognition (ASR) systems are widely used in everyday applications that require transcribing speech to text in real-time. Their minimal latency makes them suitable for such tasks. Unlike their non-streaming counterparts, streaming models are constrained to be causal with no future context and suffer from higher word error rates (WER). To improve streaming models, a recent study [1] proposed to distill a non-streaming teacher model on unsupervised utterances, and then train a streaming student using the teachers' predictions. However, the performance gap between teacher and student WERs remains high. In this paper, we aim to close this gap by using a diversified set of non-streaming teacher models and combining them using Recognizer Output Voting Error Reduction (ROVER). In particular, we show that, despite being weaker than RNN-T models, CTC models are remarkable teachers. Further, by fusing RNN-T and CTC models together, we build the strongest teachers. The resulting student models drastically improve upon streaming models of previous work [1]: the WER decreases by 41% on Spanish, 27% on Portuguese, and 13% on French.
Pushing the Limits of Non-Autoregressive Speech Recognition
Apr 12, 2021



We combine recent advancements in end-to-end speech recognition to non-autoregressive automatic speech recognition. We push the limits of non-autoregressive state-of-the-art results for multiple datasets: LibriSpeech, Fisher+Switchboard and Wall Street Journal. Key to our recipe, we leverage CTC on giant Conformer neural network architectures with SpecAugment and wav2vec2 pre-training. We achieve 1.8%/3.6% WER on LibriSpeech test/test-other sets, 5.1%/9.8% WER on Switchboard, and 3.4% on the Wall Street Journal, all without a language model.
Cascaded encoders for unifying streaming and non-streaming ASR
Oct 27, 2020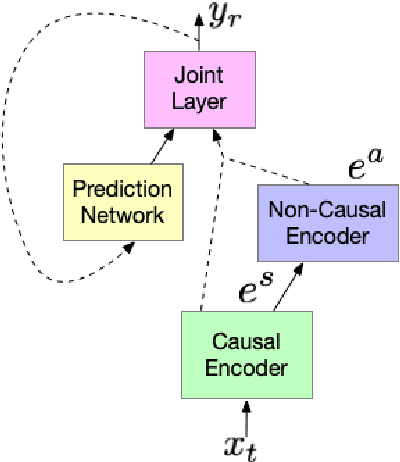
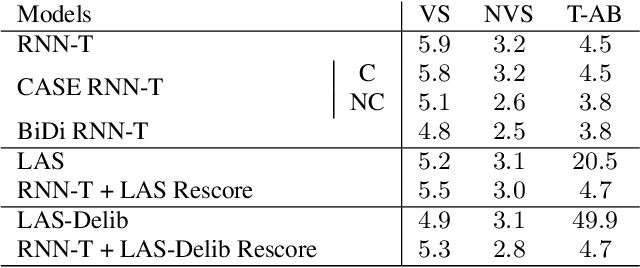
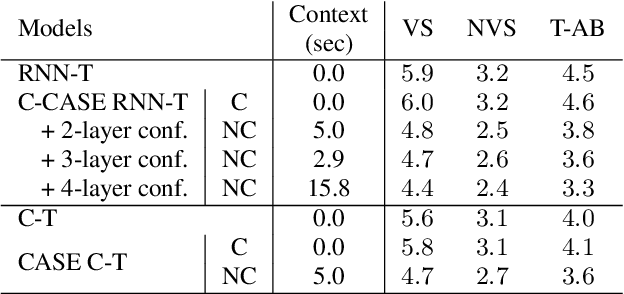
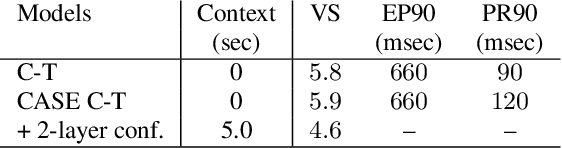
End-to-end (E2E) automatic speech recognition (ASR) models, by now, have shown competitive performance on several benchmarks. These models are structured to either operate in streaming or non-streaming mode. This work presents cascaded encoders for building a single E2E ASR model that can operate in both these modes simultaneously. The proposed model consists of streaming and non-streaming encoders. Input features are first processed by the streaming encoder; the non-streaming encoder operates exclusively on the output of the streaming encoder. A single decoder then learns to decode either using the output of the streaming or the non-streaming encoder. Results show that this model achieves similar word error rates (WER) as a standalone streaming model when operating in streaming mode, and obtains 10% -- 27% relative improvement when operating in non-streaming mode. Our results also show that the proposed approach outperforms existing E2E two-pass models, especially on long-form speech.
Improving Streaming Automatic Speech Recognition With Non-Streaming Model Distillation On Unsupervised Data
Oct 22, 2020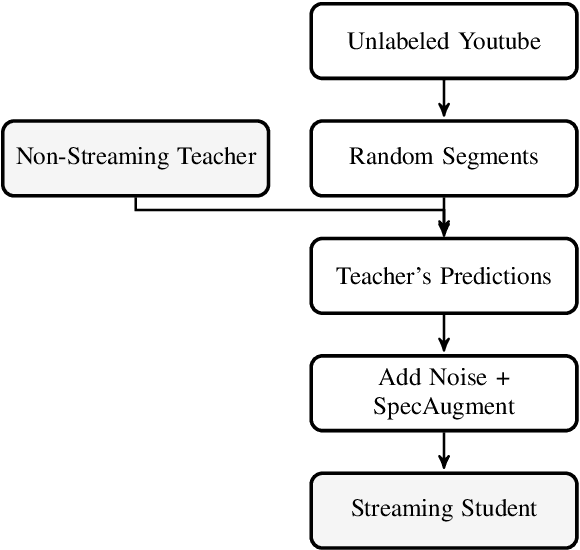
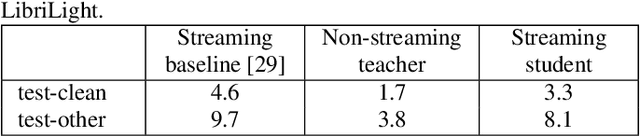
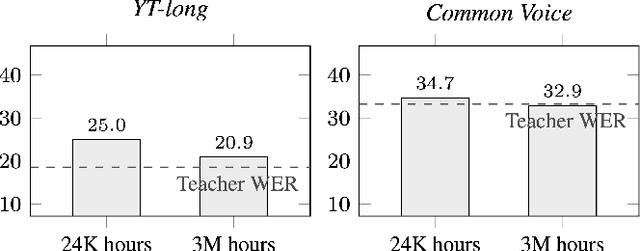
Streaming end-to-end automatic speech recognition (ASR) models are widely used on smart speakers and on-device applications. Since these models are expected to transcribe speech with minimal latency, they are constrained to be causal with no future context, compared to their non-streaming counterparts. Consequently, streaming models usually perform worse than non-streaming models. We propose a novel and effective learning method by leveraging a non-streaming ASR model as a teacher to generate transcripts on an arbitrarily large data set, which is then used to distill knowledge into streaming ASR models. This way, we scale the training of streaming models to up to 3 million hours of YouTube audio. Experiments show that our approach can significantly reduce the word error rate (WER) of RNNT models not only on LibriSpeech but also on YouTube data in four languages. For example, in French, we are able to reduce the WER by 16.4% relatively to a baseline streaming model by leveraging a non-streaming teacher model trained on the same amount of labeled data as the baseline.
FastEmit: Low-latency Streaming ASR with Sequence-level Emission Regularization
Oct 21, 2020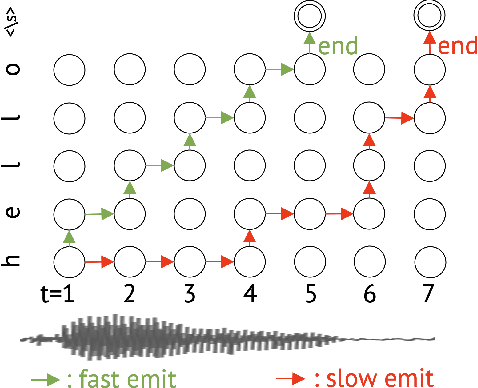
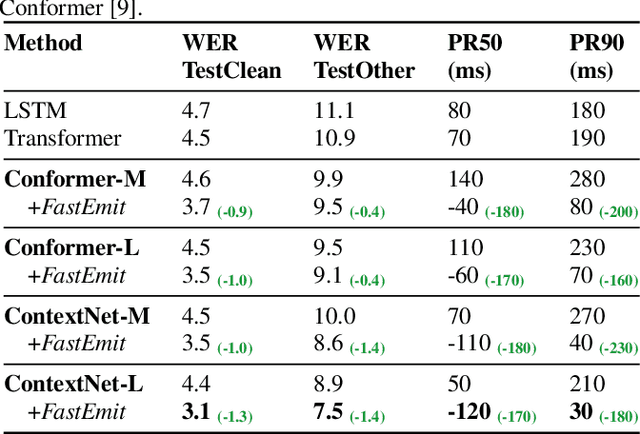

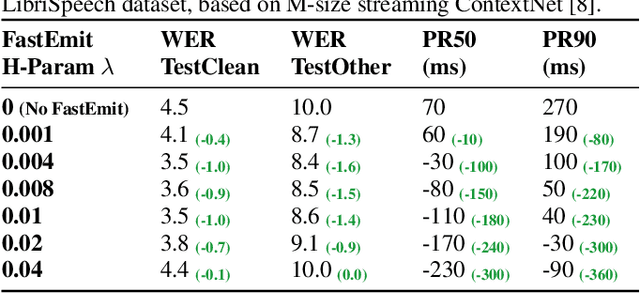
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible. However, emitting fast without degrading quality, as measured by word error rate (WER), is highly challenging. Existing approaches including Early and Late Penalties and Constrained Alignments penalize emission delay by manipulating per-token or per-frame probability prediction in sequence transducer models. While being successful in reducing delay, these approaches suffer from significant accuracy regression and also require additional word alignment information from an existing model. In this work, we propose a sequence-level emission regularization method, named FastEmit, that applies latency regularization directly on per-sequence probability in training transducer models, and does not require any alignment. We demonstrate that FastEmit is more suitable to the sequence-level optimization of transducer models for streaming ASR by applying it on various end-to-end streaming ASR networks including RNN-Transducer, Transformer-Transducer, ConvNet-Transducer and Conformer-Transducer. We achieve 150-300 ms latency reduction with significantly better accuracy over previous techniques on a Voice Search test set. FastEmit also improves streaming ASR accuracy from 4.4%/8.9% to 3.1%/7.5% WER, meanwhile reduces 90th percentile latency from 210 ms to only 30 ms on LibriSpeech.
Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition
Oct 20, 2020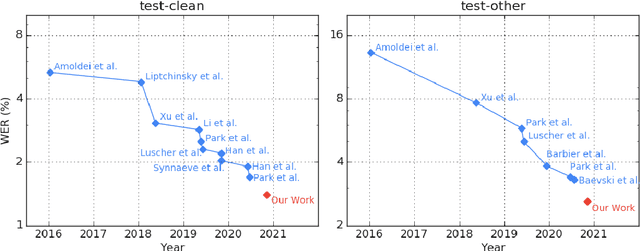

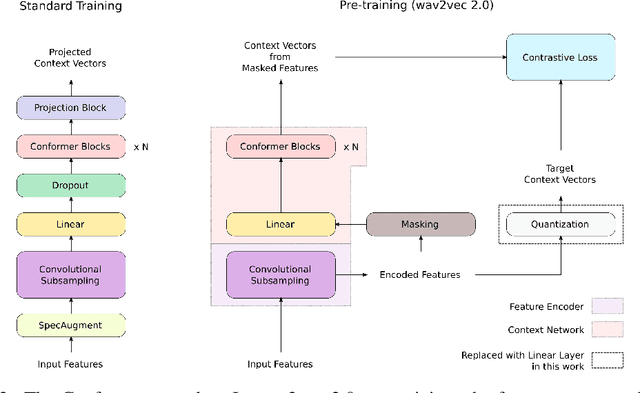
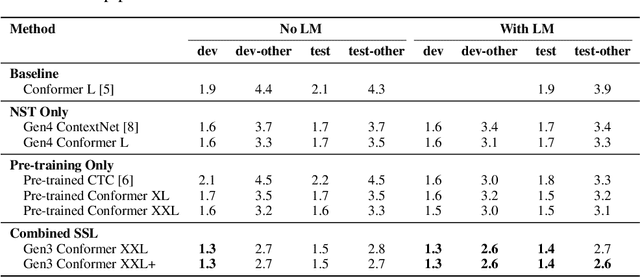
We employ a combination of recent developments in semi-supervised learning for automatic speech recognition to obtain state-of-the-art results on LibriSpeech utilizing the unlabeled audio of the Libri-Light dataset. More precisely, we carry out noisy student training with SpecAugment using giant Conformer models pre-trained using wav2vec 2.0 pre-training. By doing so, we are able to achieve word-error-rates (WERs) 1.4%/2.6% on the LibriSpeech test/test-other sets against the current state-of-the-art WERs 1.7%/3.3%.