 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwift Sampler: Efficient Learning of Sampler by 10 Parameters
Oct 08, 2024Data selection is essential for training deep learning models. An effective data sampler assigns proper sampling probability for training data and helps the model converge to a good local minimum with high performance. Previous studies in data sampling are mainly based on heuristic rules or learning through a huge amount of time-consuming trials. In this paper, we propose an automatic \textbf{swift sampler} search algorithm, \textbf{SS}, to explore automatically learning effective samplers efficiently. In particular, \textbf{SS} utilizes a novel formulation to map a sampler to a low dimension of hyper-parameters and uses an approximated local minimum to quickly examine the quality of a sampler. Benefiting from its low computational expense, \textbf{SS} can be applied on large-scale data sets with high efficiency. Comprehensive experiments on various tasks demonstrate that \textbf{SS} powered sampling can achieve obvious improvements (e.g., 1.5\% on ImageNet) and transfer among different neural networks. Project page: https://github.com/Alexander-Yao/Swift-Sampler.
A Perspective of Q-value Estimation on Offline-to-Online Reinforcement Learning
Dec 12, 2023



Offline-to-online Reinforcement Learning (O2O RL) aims to improve the performance of offline pretrained policy using only a few online samples. Built on offline RL algorithms, most O2O methods focus on the balance between RL objective and pessimism, or the utilization of offline and online samples. In this paper, from a novel perspective, we systematically study the challenges that remain in O2O RL and identify that the reason behind the slow improvement of the performance and the instability of online finetuning lies in the inaccurate Q-value estimation inherited from offline pretraining. Specifically, we demonstrate that the estimation bias and the inaccurate rank of Q-value cause a misleading signal for the policy update, making the standard offline RL algorithms, such as CQL and TD3-BC, ineffective in the online finetuning. Based on this observation, we address the problem of Q-value estimation by two techniques: (1) perturbed value update and (2) increased frequency of Q-value updates. The first technique smooths out biased Q-value estimation with sharp peaks, preventing early-stage policy exploitation of sub-optimal actions. The second one alleviates the estimation bias inherited from offline pretraining by accelerating learning. Extensive experiments on the MuJoco and Adroit environments demonstrate that the proposed method, named SO2, significantly alleviates Q-value estimation issues, and consistently improves the performance against the state-of-the-art methods by up to 83.1%.
Masked Pretraining for Multi-Agent Decision Making
Oct 18, 2023Building a single generalist agent with zero-shot capability has recently sparked significant advancements in decision-making. However, extending this capability to multi-agent scenarios presents challenges. Most current works struggle with zero-shot capabilities, due to two challenges particular to the multi-agent settings: a mismatch between centralized pretraining and decentralized execution, and varying agent numbers and action spaces, making it difficult to create generalizable representations across diverse downstream tasks. To overcome these challenges, we propose a \textbf{Mask}ed pretraining framework for \textbf{M}ulti-\textbf{a}gent decision making (MaskMA). This model, based on transformer architecture, employs a mask-based collaborative learning strategy suited for decentralized execution with partial observation. Moreover, MaskMA integrates a generalizable action representation by dividing the action space into actions toward self-information and actions related to other entities. This flexibility allows MaskMA to tackle tasks with varying agent numbers and thus different action spaces. Extensive experiments in SMAC reveal MaskMA, with a single model pretrained on 11 training maps, can achieve an impressive 77.8% zero-shot win rate on 60 unseen test maps by decentralized execution, while also performing effectively on other types of downstream tasks (\textit{e.g.,} varied policies collaboration and ad hoc team play).
Geometry-Guided Ray Augmentation for Neural Surface Reconstruction with Sparse Views
Oct 18, 2023In this paper, we propose a novel method for 3D scene and object reconstruction from sparse multi-view images. Different from previous methods that leverage extra information such as depth or generalizable features across scenes, our approach leverages the scene properties embedded in the multi-view inputs to create precise pseudo-labels for optimization without any prior training. Specifically, we introduce a geometry-guided approach that improves surface reconstruction accuracy from sparse views by leveraging spherical harmonics to predict the novel radiance while holistically considering all color observations for a point in the scene. Also, our pipeline exploits proxy geometry and correctly handles the occlusion in generating the pseudo-labels of radiance, which previous image-warping methods fail to avoid. Our method, dubbed Ray Augmentation (RayAug), achieves superior results on DTU and Blender datasets without requiring prior training, demonstrating its effectiveness in addressing the problem of sparse view reconstruction. Our pipeline is flexible and can be integrated into other implicit neural reconstruction methods for sparse views.
NDC-Scene: Boost Monocular 3D Semantic Scene Completion in Normalized Device Coordinates Space
Sep 27, 2023Monocular 3D Semantic Scene Completion (SSC) has garnered significant attention in recent years due to its potential to predict complex semantics and geometry shapes from a single image, requiring no 3D inputs. In this paper, we identify several critical issues in current state-of-the-art methods, including the Feature Ambiguity of projected 2D features in the ray to the 3D space, the Pose Ambiguity of the 3D convolution, and the Computation Imbalance in the 3D convolution across different depth levels. To address these problems, we devise a novel Normalized Device Coordinates scene completion network (NDC-Scene) that directly extends the 2D feature map to a Normalized Device Coordinates (NDC) space, rather than to the world space directly, through progressive restoration of the dimension of depth with deconvolution operations. Experiment results demonstrate that transferring the majority of computation from the target 3D space to the proposed normalized device coordinates space benefits monocular SSC tasks. Additionally, we design a Depth-Adaptive Dual Decoder to simultaneously upsample and fuse the 2D and 3D feature maps, further improving overall performance. Our extensive experiments confirm that the proposed method consistently outperforms state-of-the-art methods on both outdoor SemanticKITTI and indoor NYUv2 datasets. Our code are available at https://github.com/Jiawei-Yao0812/NDCScene.
Theoretically Guaranteed Policy Improvement Distilled from Model-Based Planning
Jul 24, 2023Model-based reinforcement learning (RL) has demonstrated remarkable successes on a range of continuous control tasks due to its high sample efficiency. To save the computation cost of conducting planning online, recent practices tend to distill optimized action sequences into an RL policy during the training phase. Although the distillation can incorporate both the foresight of planning and the exploration ability of RL policies, the theoretical understanding of these methods is yet unclear. In this paper, we extend the policy improvement step of Soft Actor-Critic (SAC) by developing an approach to distill from model-based planning to the policy. We then demonstrate that such an approach of policy improvement has a theoretical guarantee of monotonic improvement and convergence to the maximum value defined in SAC. We discuss effective design choices and implement our theory as a practical algorithm -- Model-based Planning Distilled to Policy (MPDP) -- that updates the policy jointly over multiple future time steps. Extensive experiments show that MPDP achieves better sample efficiency and asymptotic performance than both model-free and model-based planning algorithms on six continuous control benchmark tasks in MuJoCo.
ACE: Cooperative Multi-agent Q-learning with Bidirectional Action-Dependency
Dec 02, 2022



Multi-agent reinforcement learning (MARL) suffers from the non-stationarity problem, which is the ever-changing targets at every iteration when multiple agents update their policies at the same time. Starting from first principle, in this paper, we manage to solve the non-stationarity problem by proposing bidirectional action-dependent Q-learning (ACE). Central to the development of ACE is the sequential decision-making process wherein only one agent is allowed to take action at one time. Within this process, each agent maximizes its value function given the actions taken by the preceding agents at the inference stage. In the learning phase, each agent minimizes the TD error that is dependent on how the subsequent agents have reacted to their chosen action. Given the design of bidirectional dependency, ACE effectively turns a multiagent MDP into a single-agent MDP. We implement the ACE framework by identifying the proper network representation to formulate the action dependency, so that the sequential decision process is computed implicitly in one forward pass. To validate ACE, we compare it with strong baselines on two MARL benchmarks. Empirical experiments demonstrate that ACE outperforms the state-of-the-art algorithms on Google Research Football and StarCraft Multi-Agent Challenge by a large margin. In particular, on SMAC tasks, ACE achieves 100% success rate on almost all the hard and super-hard maps. We further study extensive research problems regarding ACE, including extension, generalization, and practicability. Code is made available to facilitate further research.
Residual Relaxation for Multi-view Representation Learning
Oct 28, 2021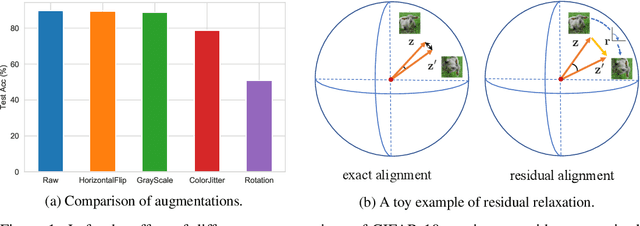
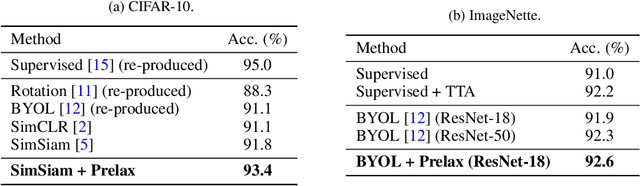
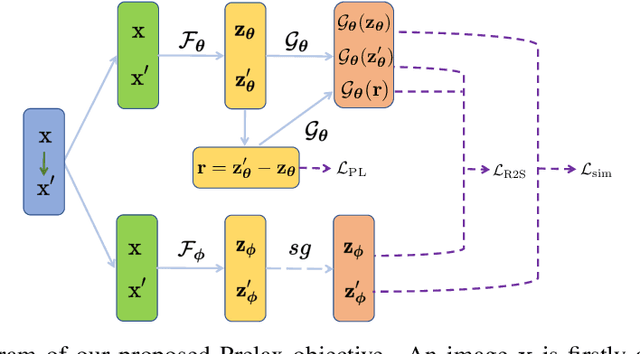
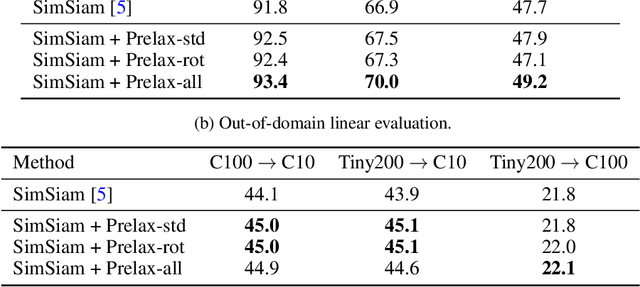
Multi-view methods learn representations by aligning multiple views of the same image and their performance largely depends on the choice of data augmentation. In this paper, we notice that some other useful augmentations, such as image rotation, are harmful for multi-view methods because they cause a semantic shift that is too large to be aligned well. This observation motivates us to relax the exact alignment objective to better cultivate stronger augmentations. Taking image rotation as a case study, we develop a generic approach, Pretext-aware Residual Relaxation (Prelax), that relaxes the exact alignment by allowing an adaptive residual vector between different views and encoding the semantic shift through pretext-aware learning. Extensive experiments on different backbones show that our method can not only improve multi-view methods with existing augmentations, but also benefit from stronger image augmentations like rotation.
BN-NAS: Neural Architecture Search with Batch Normalization
Aug 16, 2021
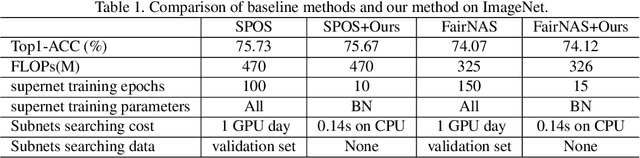
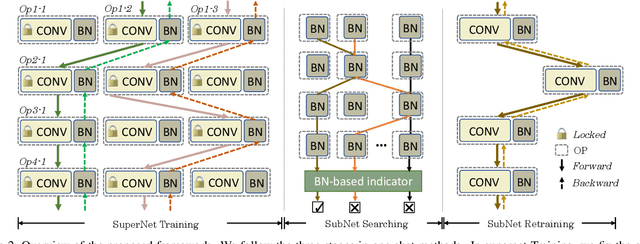
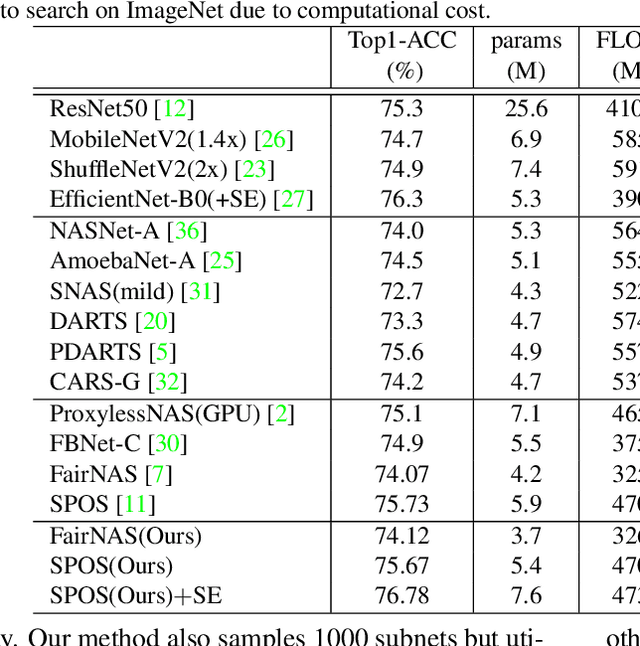
We present BN-NAS, neural architecture search with Batch Normalization (BN-NAS), to accelerate neural architecture search (NAS). BN-NAS can significantly reduce the time required by model training and evaluation in NAS. Specifically, for fast evaluation, we propose a BN-based indicator for predicting subnet performance at a very early training stage. The BN-based indicator further facilitates us to improve the training efficiency by only training the BN parameters during the supernet training. This is based on our observation that training the whole supernet is not necessary while training only BN parameters accelerates network convergence for network architecture search. Extensive experiments show that our method can significantly shorten the time of training supernet by more than 10 times and shorten the time of evaluating subnets by more than 600,000 times without losing accuracy.
PSViT: Better Vision Transformer via Token Pooling and Attention Sharing
Aug 07, 2021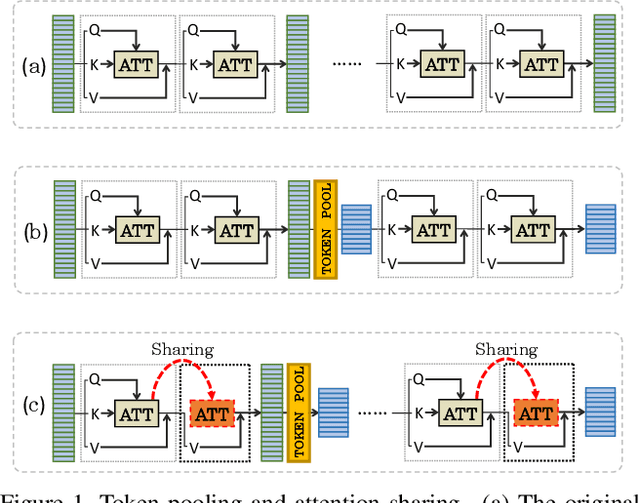
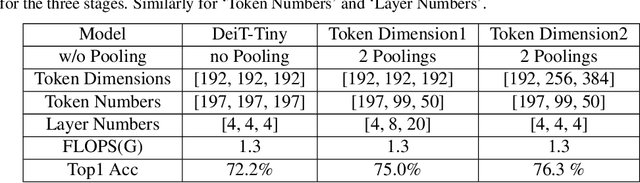
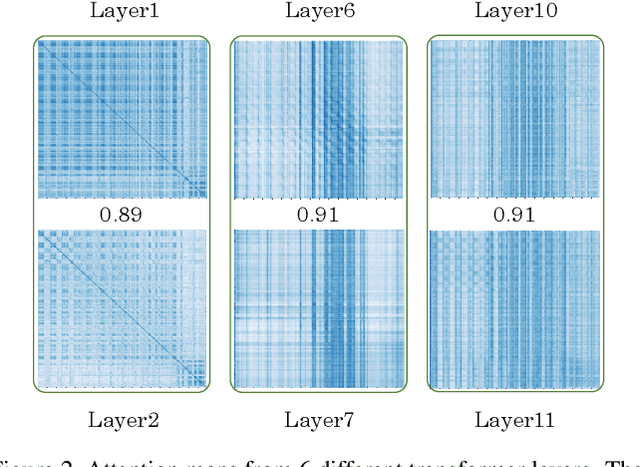
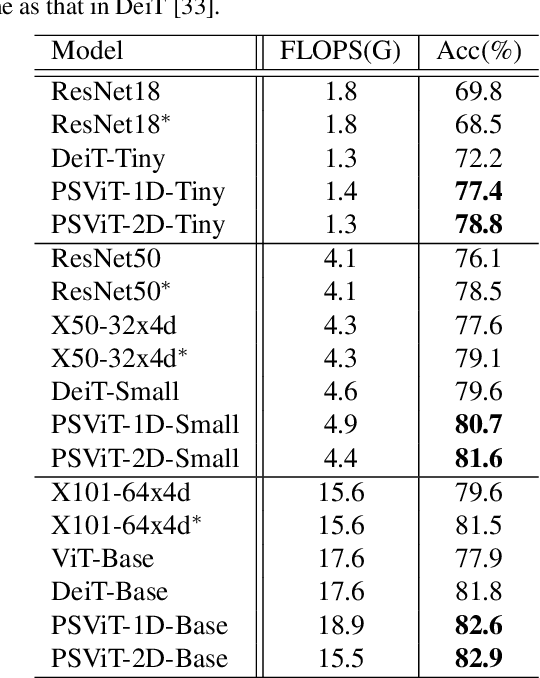
In this paper, we observe two levels of redundancies when applying vision transformers (ViT) for image recognition. First, fixing the number of tokens through the whole network produces redundant features at the spatial level. Second, the attention maps among different transformer layers are redundant. Based on the observations above, we propose a PSViT: a ViT with token Pooling and attention Sharing to reduce the redundancy, effectively enhancing the feature representation ability, and achieving a better speed-accuracy trade-off. Specifically, in our PSViT, token pooling can be defined as the operation that decreases the number of tokens at the spatial level. Besides, attention sharing will be built between the neighboring transformer layers for reusing the attention maps having a strong correlation among adjacent layers. Then, a compact set of the possible combinations for different token pooling and attention sharing mechanisms are constructed. Based on the proposed compact set, the number of tokens in each layer and the choices of layers sharing attention can be treated as hyper-parameters that are learned from data automatically. Experimental results show that the proposed scheme can achieve up to 6.6% accuracy improvement in ImageNet classification compared with the DeiT.