 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhased Instruction Fine-Tuning for Large Language Models
Jun 01, 2024



Instruction Fine-Tuning, a method enhancing pre-trained language models' capabilities from mere next-word prediction to complex instruction following, often employs a one-off training approach on diverse instruction dataset. However, this method may not effectively enhance models' adherence to instructions due to the simultaneous handling of varying instruction complexities. To address this, we propose a novel phased instruction fine-tuning (Phased IFT) method, grounded in the hypothesis of progressive alignment, which posits that the transition of a pre-trained language model from simple next-word prediction to sophisticated instruction following is a gradual learning process. Specifically, we obtain the score of difficulty for each instruction via GPT-4, stratify the instruction data into subsets of increasing difficulty, and sequentially uptrain on these subsets using the standard supervised loss. Through extensive experiments on the pre-trained models Llama-2 7B/13B, and Mistral-7B using the 52K Alpaca instruction data, we demonstrate that Phased IFT significantly surpasses traditional one-off instruction fine-tuning (One-off IFT) method in win rate, empirically validating the progressive alignment hypothesis. Our findings suggest that Phased IFT offers a simple yet effective pathway for elevating the instruction-following capabilities of pre-trained language models. Models and datasets from our experiments are freely available at https://github.com/xubuvd/PhasedSFT.
GNNEvaluator: Evaluating GNN Performance On Unseen Graphs Without Labels
Oct 26, 2023



Evaluating the performance of graph neural networks (GNNs) is an essential task for practical GNN model deployment and serving, as deployed GNNs face significant performance uncertainty when inferring on unseen and unlabeled test graphs, due to mismatched training-test graph distributions. In this paper, we study a new problem, GNN model evaluation, that aims to assess the performance of a specific GNN model trained on labeled and observed graphs, by precisely estimating its performance (e.g., node classification accuracy) on unseen graphs without labels. Concretely, we propose a two-stage GNN model evaluation framework, including (1) DiscGraph set construction and (2) GNNEvaluator training and inference. The DiscGraph set captures wide-range and diverse graph data distribution discrepancies through a discrepancy measurement function, which exploits the outputs of GNNs related to latent node embeddings and node class predictions. Under the effective training supervision from the DiscGraph set, GNNEvaluator learns to precisely estimate node classification accuracy of the to-be-evaluated GNN model and makes an accurate inference for evaluating GNN model performance. Extensive experiments on real-world unseen and unlabeled test graphs demonstrate the effectiveness of our proposed method for GNN model evaluation.
ID-MixGCL: Identity Mixup for Graph Contrastive Learning
Apr 20, 2023



Recently developed graph contrastive learning (GCL) approaches compare two different "views" of the same graph in order to learn node/graph representations. The core assumption of these approaches is that by graph augmentation, it is possible to generate several structurally different but semantically similar graph structures, and therefore, the identity labels of the original and augmented graph/nodes should be identical. However, in this paper, we observe that this assumption does not always hold, for example, any perturbation to nodes or edges in a molecular graph will change the graph labels to some degree. Therefore, we believe that augmenting the graph structure should be accompanied by an adaptation of the labels used for the contrastive loss. Based on this idea, we propose ID-MixGCL, which allows for simultaneous modulation of both the input graph and the corresponding identity labels, with a controllable degree of change, leading to the capture of fine-grained representations from unlabeled graphs. Experimental results demonstrate that ID-MixGCL improves performance on graph classification and node classification tasks, as demonstrated by significant improvements on the Cora, IMDB-B, and IMDB-M datasets compared to state-of-the-art techniques, by 3-29% absolute points.
Auto-HeG: Automated Graph Neural Network on Heterophilic Graphs
Feb 23, 2023



Graph neural architecture search (NAS) has gained popularity in automatically designing powerful graph neural networks (GNNs) with relieving human efforts. However, existing graph NAS methods mainly work under the homophily assumption and overlook another important graph property, i.e., heterophily, which exists widely in various real-world applications. To date, automated heterophilic graph learning with NAS is still a research blank to be filled in. Due to the complexity and variety of heterophilic graphs, the critical challenge of heterophilic graph NAS mainly lies in developing the heterophily-specific search space and strategy. Therefore, in this paper, we propose a novel automated graph neural network on heterophilic graphs, namely Auto-HeG, to automatically build heterophilic GNN models with expressive learning abilities. Specifically, Auto-HeG incorporates heterophily into all stages of automatic heterophilic graph learning, including search space design, supernet training, and architecture selection. Through the diverse message-passing scheme with joint micro-level and macro-level designs, we first build a comprehensive heterophilic GNN search space, enabling Auto-HeG to integrate complex and various heterophily of graphs. With a progressive supernet training strategy, we dynamically shrink the initial search space according to layer-wise variation of heterophily, resulting in a compact and efficient supernet. Taking a heterophily-aware distance criterion as the guidance, we conduct heterophilic architecture selection in the leave-one-out pattern, so that specialized and expressive heterophilic GNN architectures can be derived. Extensive experiments illustrate the superiority of Auto-HeG in developing excellent heterophilic GNNs to human-designed models and graph NAS models.
A Comprehensive Survey of Graph-level Learning
Jan 14, 2023



Graphs have a superior ability to represent relational data, like chemical compounds, proteins, and social networks. Hence, graph-level learning, which takes a set of graphs as input, has been applied to many tasks including comparison, regression, classification, and more. Traditional approaches to learning a set of graphs tend to rely on hand-crafted features, such as substructures. But while these methods benefit from good interpretability, they often suffer from computational bottlenecks as they cannot skirt the graph isomorphism problem. Conversely, deep learning has helped graph-level learning adapt to the growing scale of graphs by extracting features automatically and decoding graphs into low-dimensional representations. As a result, these deep graph learning methods have been responsible for many successes. Yet, there is no comprehensive survey that reviews graph-level learning starting with traditional learning and moving through to the deep learning approaches. This article fills this gap and frames the representative algorithms into a systematic taxonomy covering traditional learning, graph-level deep neural networks, graph-level graph neural networks, and graph pooling. To ensure a thoroughly comprehensive survey, the evolutions, interactions, and communications between methods from four different branches of development are also examined. This is followed by a brief review of the benchmark data sets, evaluation metrics, and common downstream applications. The survey concludes with 13 future directions of necessary research that will help to overcome the challenges facing this booming field.
DAGAD: Data Augmentation for Graph Anomaly Detection
Oct 18, 2022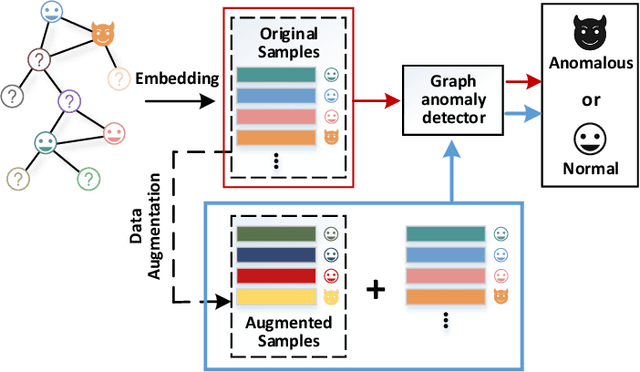
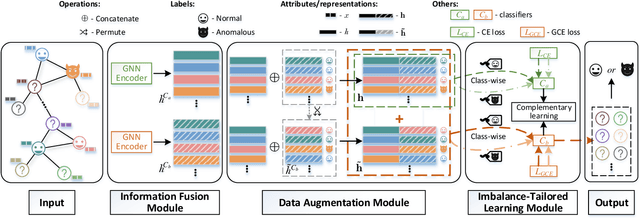
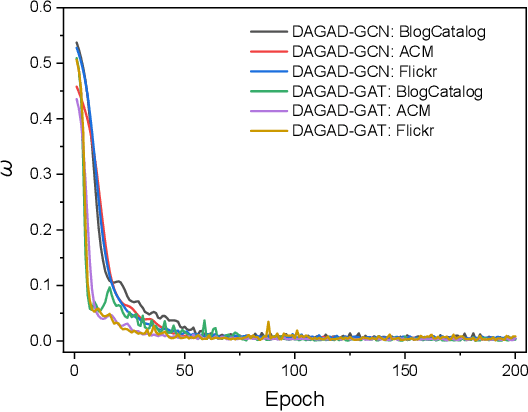
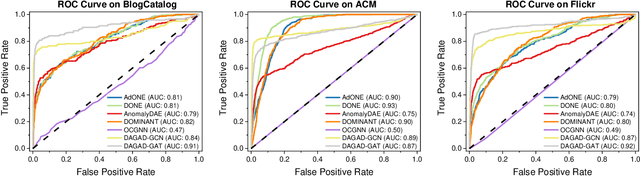
Graph anomaly detection in this paper aims to distinguish abnormal nodes that behave differently from the benign ones accounting for the majority of graph-structured instances. Receiving increasing attention from both academia and industry, yet existing research on this task still suffers from two critical issues when learning informative anomalous behavior from graph data. For one thing, anomalies are usually hard to capture because of their subtle abnormal behavior and the shortage of background knowledge about them, which causes severe anomalous sample scarcity. Meanwhile, the overwhelming majority of objects in real-world graphs are normal, bringing the class imbalance problem as well. To bridge the gaps, this paper devises a novel Data Augmentation-based Graph Anomaly Detection (DAGAD) framework for attributed graphs, equipped with three specially designed modules: 1) an information fusion module employing graph neural network encoders to learn representations, 2) a graph data augmentation module that fertilizes the training set with generated samples, and 3) an imbalance-tailored learning module to discriminate the distributions of the minority (anomalous) and majority (normal) classes. A series of experiments on three datasets prove that DAGAD outperforms ten state-of-the-art baseline detectors concerning various mostly-used metrics, together with an extensive ablation study validating the strength of our proposed modules.
Geometry Contrastive Learning on Heterogeneous Graphs
Jun 25, 2022
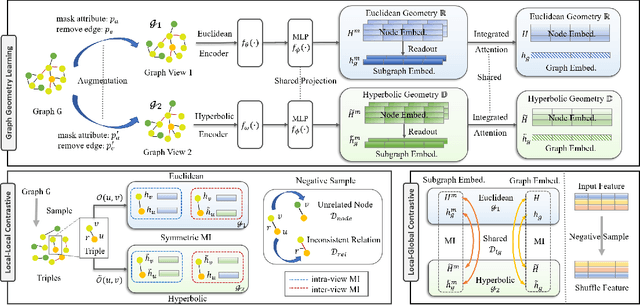

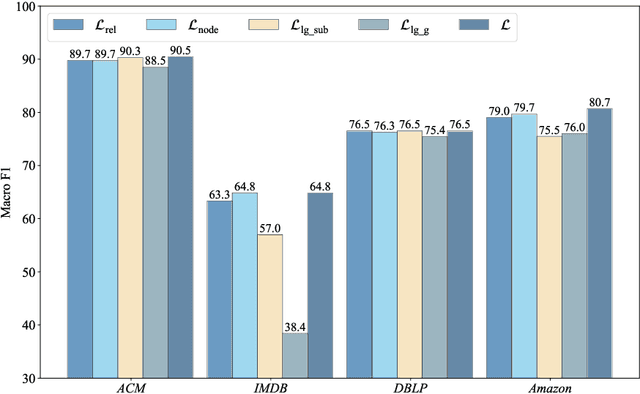
Self-supervised learning (especially contrastive learning) methods on heterogeneous graphs can effectively get rid of the dependence on supervisory data. Meanwhile, most existing representation learning methods embed the heterogeneous graphs into a single geometric space, either Euclidean or hyperbolic. This kind of single geometric view is usually not enough to observe the complete picture of heterogeneous graphs due to their rich semantics and complex structures. Under these observations, this paper proposes a novel self-supervised learning method, termed as Geometry Contrastive Learning (GCL), to better represent the heterogeneous graphs when supervisory data is unavailable. GCL views a heterogeneous graph from Euclidean and hyperbolic perspective simultaneously, aiming to make a strong merger of the ability of modeling rich semantics and complex structures, which is expected to bring in more benefits for downstream tasks. GCL maximizes the mutual information between two geometric views by contrasting representations at both local-local and local-global semantic levels. Extensive experiments on four benchmarks data sets show that the proposed approach outperforms the strong baselines, including both unsupervised methods and supervised methods, on three tasks, including node classification, node clustering and similarity search.
Ultrahyperbolic Knowledge Graph Embeddings
Jun 01, 2022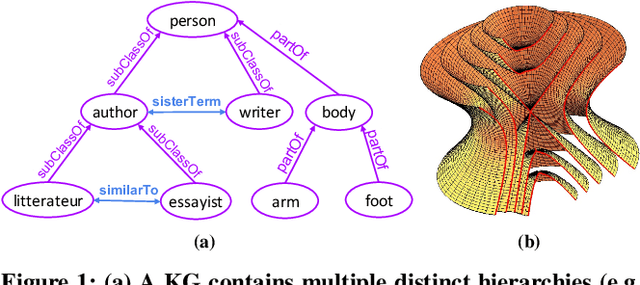
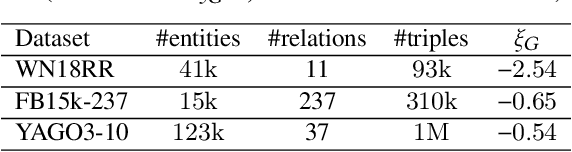
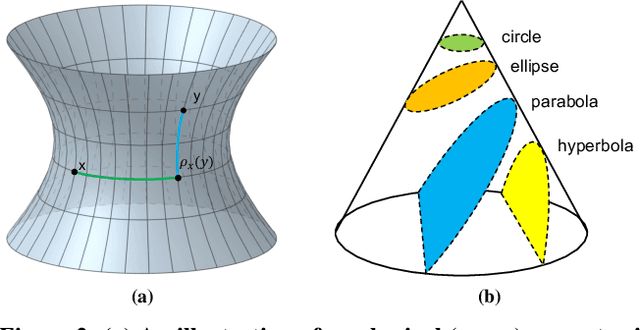
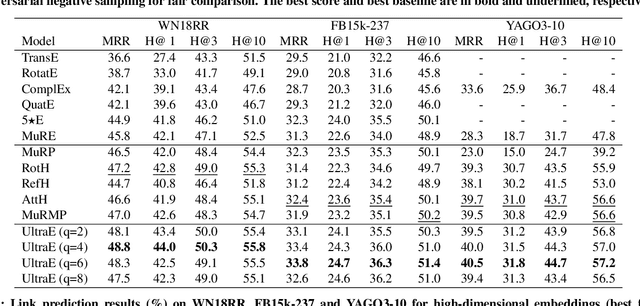
Recent knowledge graph (KG) embeddings have been advanced by hyperbolic geometry due to its superior capability for representing hierarchies. The topological structures of real-world KGs, however, are rather heterogeneous, i.e., a KG is composed of multiple distinct hierarchies and non-hierarchical graph structures. Therefore, a homogeneous (either Euclidean or hyperbolic) geometry is not sufficient for fairly representing such heterogeneous structures. To capture the topological heterogeneity of KGs, we present an ultrahyperbolic KG embedding (UltraE) in an ultrahyperbolic (or pseudo-Riemannian) manifold that seamlessly interleaves hyperbolic and spherical manifolds. In particular, we model each relation as a pseudo-orthogonal transformation that preserves the pseudo-Riemannian bilinear form. The pseudo-orthogonal transformation is decomposed into various operators (i.e., circular rotations, reflections and hyperbolic rotations), allowing for simultaneously modeling heterogeneous structures as well as complex relational patterns. Experimental results on three standard KGs show that UltraE outperforms previous Euclidean- and hyperbolic-based approaches.
Graph-level Neural Networks: Current Progress and Future Directions
May 31, 2022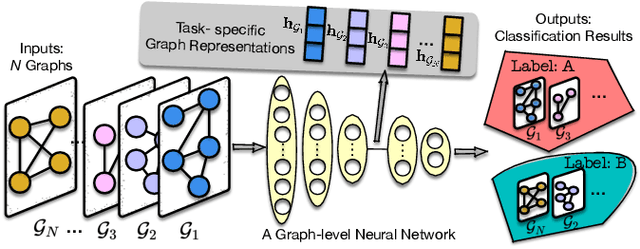

Graph-structured data consisting of objects (i.e., nodes) and relationships among objects (i.e., edges) are ubiquitous. Graph-level learning is a matter of studying a collection of graphs instead of a single graph. Traditional graph-level learning methods used to be the mainstream. However, with the increasing scale and complexity of graphs, Graph-level Neural Networks (GLNNs, deep learning-based graph-level learning methods) have been attractive due to their superiority in modeling high-dimensional data. Thus, a survey on GLNNs is necessary. To frame this survey, we propose a systematic taxonomy covering GLNNs upon deep neural networks, graph neural networks, and graph pooling. The representative and state-of-the-art models in each category are focused on this survey. We also investigate the reproducibility, benchmarks, and new graph datasets of GLNNs. Finally, we conclude future directions to further push forward GLNNs. The repository of this survey is available at https://github.com/GeZhangMQ/Awesome-Graph-level-Neural-Networks.
Projective Ranking-based GNN Evasion Attacks
Feb 25, 2022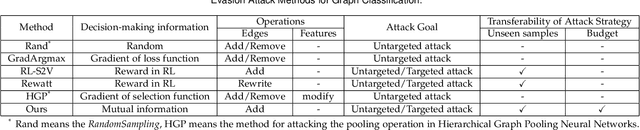
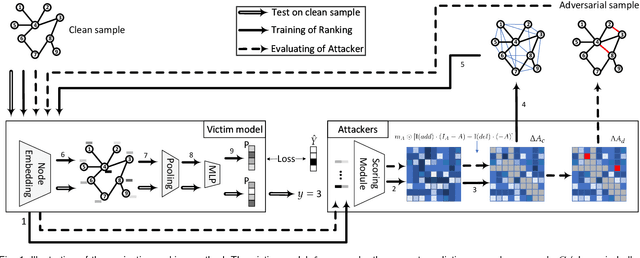
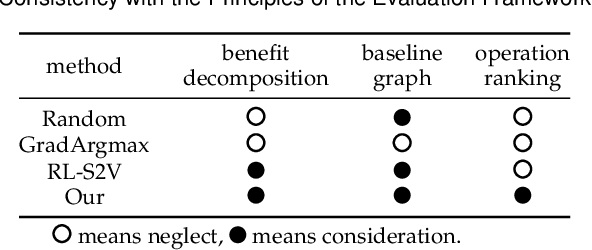
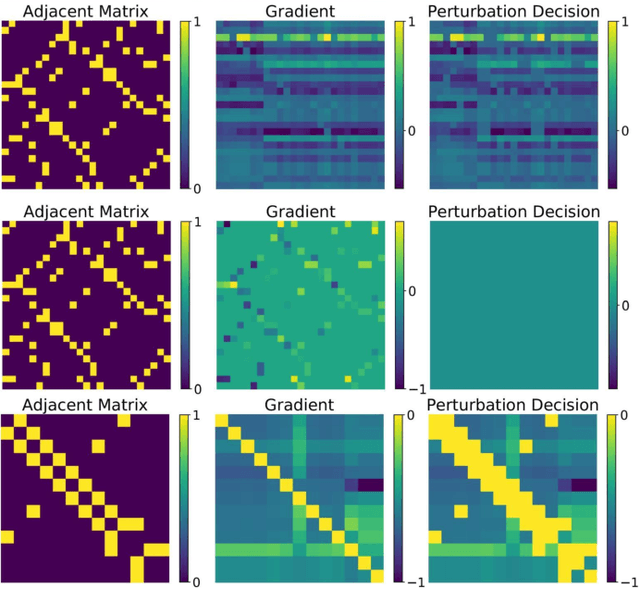
Graph neural networks (GNNs) offer promising learning methods for graph-related tasks. However, GNNs are at risk of adversarial attacks. Two primary limitations of the current evasion attack methods are highlighted: (1) The current GradArgmax ignores the "long-term" benefit of the perturbation. It is faced with zero-gradient and invalid benefit estimates in certain situations. (2) In the reinforcement learning-based attack methods, the learned attack strategies might not be transferable when the attack budget changes. To this end, we first formulate the perturbation space and propose an evaluation framework and the projective ranking method. We aim to learn a powerful attack strategy then adapt it as little as possible to generate adversarial samples under dynamic budget settings. In our method, based on mutual information, we rank and assess the attack benefits of each perturbation for an effective attack strategy. By projecting the strategy, our method dramatically minimizes the cost of learning a new attack strategy when the attack budget changes. In the comparative assessment with GradArgmax and RL-S2V, the results show our method owns high attack performance and effective transferability. The visualization of our method also reveals various attack patterns in the generation of adversarial samples.