 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Language Decision Transformers and Exponential Tilt for Interactive Text Environments
Feb 10, 2023



Text-based game environments are challenging because agents must deal with long sequences of text, execute compositional actions using text and learn from sparse rewards. We address these challenges by proposing Long-Context Language Decision Transformers (LLDTs), a framework that is based on long transformer language models and decision transformers (DTs). LLDTs extend DTs with 3 components: (1) exponential tilt to guide the agent towards high obtainable goals, (2) novel goal conditioning methods yielding significantly better results than the traditional return-to-go (sum of all future rewards), and (3) a model of future observations. Our ablation results show that predicting future observations improves agent performance. To the best of our knowledge, LLDTs are the first to address offline RL with DTs on these challenging games. Our experiments show that LLDTs achieve the highest scores among many different types of agents on some of the most challenging Jericho games, such as Enchanter.
Visual Question Answering From Another Perspective: CLEVR Mental Rotation Tests
Dec 03, 2022



Different types of mental rotation tests have been used extensively in psychology to understand human visual reasoning and perception. Understanding what an object or visual scene would look like from another viewpoint is a challenging problem that is made even harder if it must be performed from a single image. We explore a controlled setting whereby questions are posed about the properties of a scene if that scene was observed from another viewpoint. To do this we have created a new version of the CLEVR dataset that we call CLEVR Mental Rotation Tests (CLEVR-MRT). Using CLEVR-MRT we examine standard methods, show how they fall short, then explore novel neural architectures that involve inferring volumetric representations of a scene. These volumes can be manipulated via camera-conditioned transformations to answer the question. We examine the efficacy of different model variants through rigorous ablations and demonstrate the efficacy of volumetric representations.
Receptive Field Refinement for Convolutional Neural Networks Reliably Improves Predictive Performance
Nov 26, 2022Minimal changes to neural architectures (e.g. changing a single hyperparameter in a key layer), can lead to significant gains in predictive performance in Convolutional Neural Networks (CNNs). In this work, we present a new approach to receptive field analysis that can yield these types of theoretical and empirical performance gains across twenty well-known CNN architectures examined in our experiments. By further developing and formalizing the analysis of receptive field expansion in convolutional neural networks, we can predict unproductive layers in an automated manner before ever training a model. This allows us to optimize the parameter-efficiency of a given architecture at low cost. Our method is computationally simple and can be done in an automated manner or even manually with minimal effort for most common architectures. We demonstrate the effectiveness of this approach by increasing parameter efficiency across past and current top-performing CNN-architectures. Specifically, our approach is able to improve ImageNet1K performance across a wide range of well-known, state-of-the-art (SOTA) model classes, including: VGG Nets, MobileNetV1, MobileNetV3, NASNet A (mobile), MnasNet, EfficientNet, and ConvNeXt - leading to a new SOTA result for each model class.
Towards good validation metrics for generative models in offline model-based optimisation
Nov 19, 2022In this work we propose a principled evaluation framework for model-based optimisation to measure how well a generative model can extrapolate. We achieve this by interpreting the training and validation splits as draws from their respective `truncated' ground truth distributions, where examples in the validation set contain scores much larger than those in the training set. Model selection is performed on the validation set for some prescribed validation metric. A major research question however is in determining what validation metric correlates best with the expected value of generated candidates with respect to the ground truth oracle; work towards answering this question can translate to large economic gains since it is expensive to evaluate the ground truth oracle in the real world. We compare various validation metrics for generative adversarial networks using our framework. We also discuss limitations with our framework with respect to existing datasets and how progress can be made to mitigate them.
Attention-based Neural Cellular Automata
Nov 02, 2022Recent extensions of Cellular Automata (CA) have incorporated key ideas from modern deep learning, dramatically extending their capabilities and catalyzing a new family of Neural Cellular Automata (NCA) techniques. Inspired by Transformer-based architectures, our work presents a new class of $\textit{attention-based}$ NCAs formed using a spatially localized$\unicode{x2014}$yet globally organized$\unicode{x2014}$self-attention scheme. We introduce an instance of this class named $\textit{Vision Transformer Cellular Automata}$ (ViTCA). We present quantitative and qualitative results on denoising autoencoding across six benchmark datasets, comparing ViTCA to a U-Net, a U-Net-based CA baseline (UNetCA), and a Vision Transformer (ViT). When comparing across architectures configured to similar parameter complexity, ViTCA architectures yield superior performance across all benchmarks and for nearly every evaluation metric. We present an ablation study on various architectural configurations of ViTCA, an analysis of its effect on cell states, and an investigation on its inductive biases. Finally, we examine its learned representations via linear probes on its converged cell state hidden representations, yielding, on average, superior results when compared to our U-Net, ViT, and UNetCA baselines.
Using Graph Algorithms to Pretrain Graph Completion Transformers
Oct 14, 2022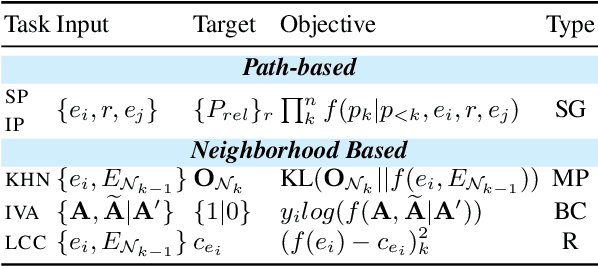
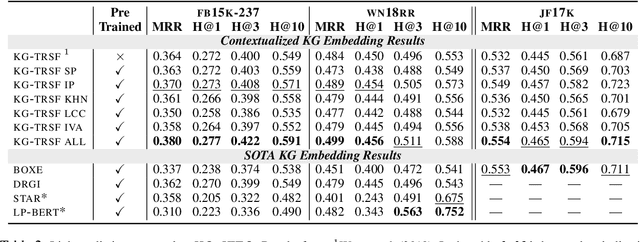


Recent work on Graph Neural Networks has demonstrated that self-supervised pretraining can further enhance performance on downstream graph, link, and node classification tasks. However, the efficacy of pretraining tasks has not been fully investigated for downstream large knowledge graph completion tasks. Using a contextualized knowledge graph embedding approach, we investigate five different pretraining signals, constructed using several graph algorithms and no external data, as well as their combination. We leverage the versatility of our Transformer-based model to explore graph structure generation pretraining tasks, typically inapplicable to most graph embedding methods. We further propose a new path-finding algorithm guided by information gain and find that it is the best-performing pretraining task across three downstream knowledge graph completion datasets. In a multitask setting that combines all pretraining tasks, our method surpasses some of the latest and strong performing knowledge graph embedding methods on all metrics for FB15K-237, on MRR and Hit@1 for WN18RR and on MRR and hit@10 for JF17K (a knowledge hypergraph dataset).
SMPL-IK: Learned Morphology-Aware Inverse Kinematics for AI Driven Artistic Workflows
Aug 16, 2022
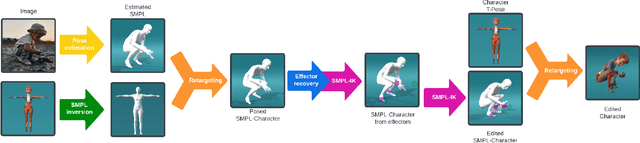


Inverse Kinematics (IK) systems are often rigid with respect to their input character, thus requiring user intervention to be adapted to new skeletons. In this paper we aim at creating a flexible, learned IK solver applicable to a wide variety of human morphologies. We extend a state-of-the-art machine learning IK solver to operate on the well known Skinned Multi-Person Linear model (SMPL). We call our model SMPL-IK, and show that when integrated into real-time 3D software, this extended system opens up opportunities for defining novel AI-assisted animation workflows. For example, pose authoring can be made more flexible with SMPL-IK by allowing users to modify gender and body shape while posing a character. Additionally, when chained with existing pose estimation algorithms, SMPL-IK accelerates posing by allowing users to bootstrap 3D scenes from 2D images while allowing for further editing. Finally, we propose a novel SMPL Shape Inversion mechanism (SMPL-SI) to map arbitrary humanoid characters to the SMPL space, allowing artists to leverage SMPL-IK on custom characters. In addition to qualitative demos showing proposed tools, we present quantitative SMPL-IK baselines on the H36M and AMASS datasets.
Improving Meta-Learning Generalization with Activation-Based Early-Stopping
Aug 03, 2022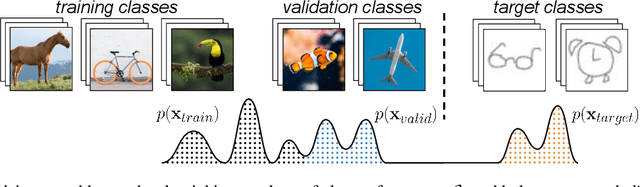

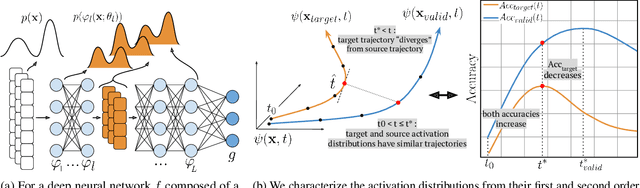
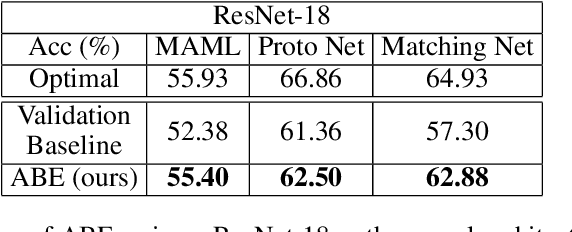
Meta-Learning algorithms for few-shot learning aim to train neural networks capable of generalizing to novel tasks using only a few examples. Early-stopping is critical for performance, halting model training when it reaches optimal generalization to the new task distribution. Early-stopping mechanisms in Meta-Learning typically rely on measuring the model performance on labeled examples from a meta-validation set drawn from the training (source) dataset. This is problematic in few-shot transfer learning settings, where the meta-test set comes from a different target dataset (OOD) and can potentially have a large distributional shift with the meta-validation set. In this work, we propose Activation Based Early-stopping (ABE), an alternative to using validation-based early-stopping for meta-learning. Specifically, we analyze the evolution, during meta-training, of the neural activations at each hidden layer, on a small set of unlabelled support examples from a single task of the target tasks distribution, as this constitutes a minimal and justifiably accessible information from the target problem. Our experiments show that simple, label agnostic statistics on the activations offer an effective way to estimate how the target generalization evolves over time. At each hidden layer, we characterize the activation distributions, from their first and second order moments, then further summarized along the feature dimensions, resulting in a compact yet intuitive characterization in a four-dimensional space. Detecting when, throughout training time, and at which layer, the target activation trajectory diverges from the activation trajectory of the source data, allows us to perform early-stopping and improve generalization in a large array of few-shot transfer learning settings, across different algorithms, source and target datasets.
MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation
May 30, 2022
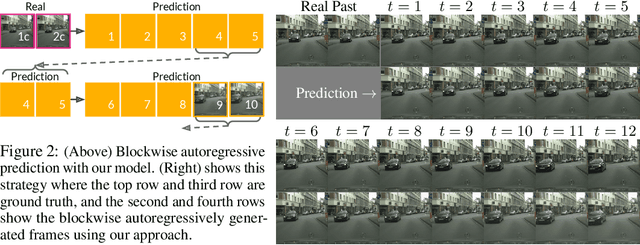
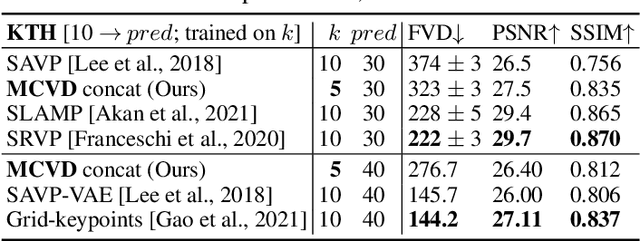
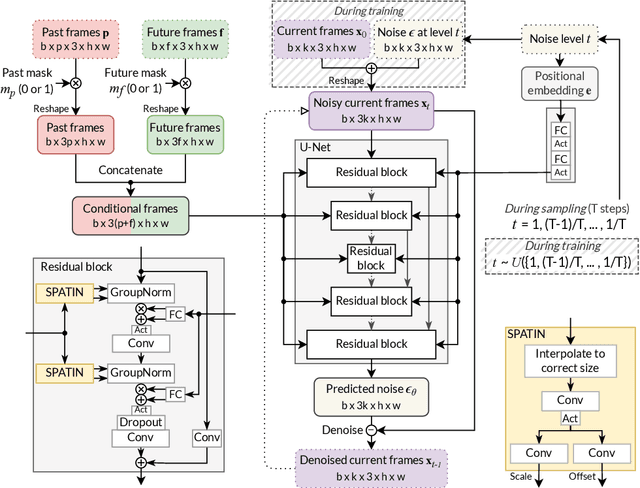
Video prediction is a challenging task. The quality of video frames from current state-of-the-art (SOTA) generative models tends to be poor and generalization beyond the training data is difficult. Furthermore, existing prediction frameworks are typically not capable of simultaneously handling other video-related tasks such as unconditional generation or interpolation. In this work, we devise a general-purpose framework called Masked Conditional Video Diffusion (MCVD) for all of these video synthesis tasks using a probabilistic conditional score-based denoising diffusion model, conditioned on past and/or future frames. We train the model in a manner where we randomly and independently mask all the past frames or all the future frames. This novel but straightforward setup allows us to train a single model that is capable of executing a broad range of video tasks, specifically: future/past prediction -- when only future/past frames are masked; unconditional generation -- when both past and future frames are masked; and interpolation -- when neither past nor future frames are masked. Our experiments show that this approach can generate high-quality frames for diverse types of videos. Our MCVD models are built from simple non-recurrent 2D-convolutional architectures, conditioning on blocks of frames and generating blocks of frames. We generate videos of arbitrary lengths autoregressively in a block-wise manner. Our approach yields SOTA results across standard video prediction and interpolation benchmarks, with computation times for training models measured in 1-12 days using $\le$ 4 GPUs. Project page: https://mask-cond-video-diffusion.github.io ; Code : https://github.com/voletiv/mcvd-pytorch
Challenges in leveraging GANs for few-shot data augmentation
Mar 30, 2022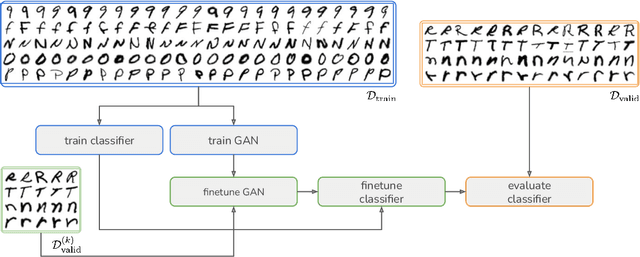
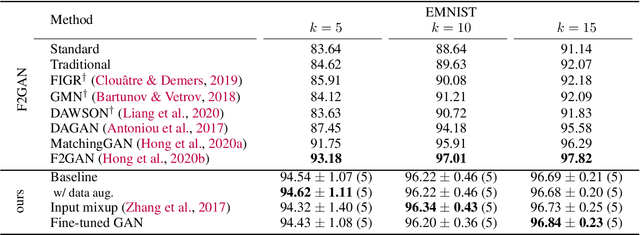
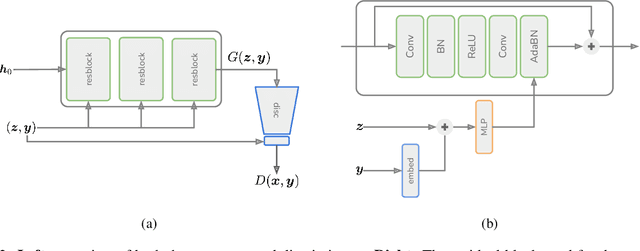

In this paper, we explore the use of GAN-based few-shot data augmentation as a method to improve few-shot classification performance. We perform an exploration into how a GAN can be fine-tuned for such a task (one of which is in a class-incremental manner), as well as a rigorous empirical investigation into how well these models can perform to improve few-shot classification. We identify issues related to the difficulty of training such generative models under a purely supervised regime with very few examples, as well as issues regarding the evaluation protocols of existing works. We also find that in this regime, classification accuracy is highly sensitive to how the classes of the dataset are randomly split. Therefore, we propose a semi-supervised fine-tuning approach as a more pragmatic way forward to address these problems.