 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Customer Trajectories with Reinforcement Learning for Practical Retail Insights
May 18, 2026Understanding customer movement within retail spaces is essential for optimizing store layouts. Real-world trajectory data can provide highly accurate insights, but collecting it is costly and often infeasible for many retailers. Heuristics such as Travelling Salesman Problem (TSP) and Probabilistic Nearest Neighbours (PNN) are commonly used as inexpensive approximations, but actual customer trajectories deviate by an average of 28% from shortest paths, highlighting a tradeoff between accuracy and practicality. We propose an agent-based modelling framework that casts customer trajectory prediction as a maximum entropy reinforcement learning (RL) problem, balancing reward maximization with stochasticity to better reflect customers with bounded rationality. Using real-world trajectory data from a convenience store, we show that RL-generated trajectories align more closely with customer behaviour than TSP and PNN, providing more accurate estimates of impulse purchase rates and shelf traffic densities. Furthermore, only RL-based predictions yield repositioning decisions for impulse products that align with those derived from actual trajectory data, resulting in comparable estimated profit gains. Our work demonstrates that RL provides a practical, behaviourally grounded alternative that bridges the gap between oversimplified heuristics and data-intensive approaches, making accurate layout optimization more accessible. To encourage further research, the source code is available on GitHub.
A Model-Based Solution to the Offline Multi-Agent Reinforcement Learning Coordination Problem
May 26, 2023



Training multiple agents to coordinate is an important problem with applications in robotics, game theory, economics, and social sciences. However, most existing Multi-Agent Reinforcement Learning (MARL) methods are online and thus impractical for real-world applications in which collecting new interactions is costly or dangerous. While these algorithms should leverage offline data when available, doing so gives rise to the offline coordination problem. Specifically, we identify and formalize the strategy agreement (SA) and the strategy fine-tuning (SFT) challenges, two coordination issues at which current offline MARL algorithms fail. To address this setback, we propose a simple model-based approach that generates synthetic interaction data and enables agents to converge on a strategy while fine-tuning their policies accordingly. Our resulting method, Model-based Offline Multi-Agent Proximal Policy Optimization (MOMA-PPO), outperforms the prevalent learning methods in challenging offline multi-agent MuJoCo tasks even under severe partial observability and with learned world models.
Learning to Guide and to Be Guided in the Architect-Builder Problem
Dec 19, 2021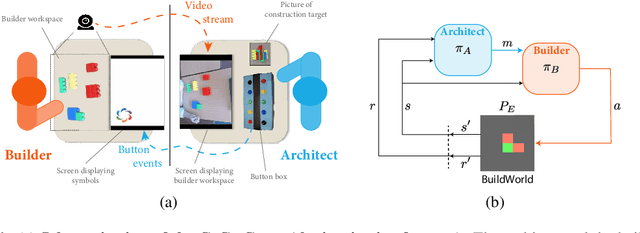
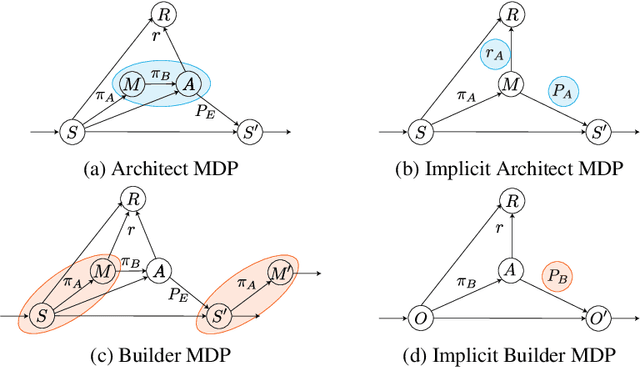
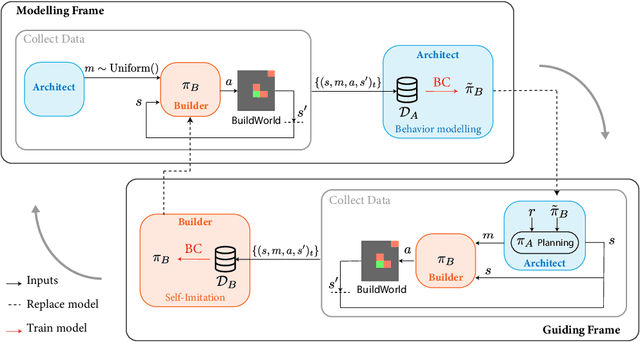
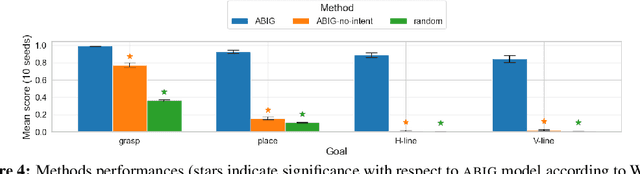
We are interested in interactive agents that learn to coordinate, namely, a $builder$ -- which performs actions but ignores the goal of the task -- and an $architect$ which guides the builder towards the goal of the task. We define and explore a formal setting where artificial agents are equipped with mechanisms that allow them to simultaneously learn a task while at the same time evolving a shared communication protocol. The field of Experimental Semiotics has shown the extent of human proficiency at learning from a priori unknown instructions meanings. Therefore, we take inspiration from it and present the Architect-Builder Problem (ABP): an asymmetrical setting in which an architect must learn to guide a builder towards constructing a specific structure. The architect knows the target structure but cannot act in the environment and can only send arbitrary messages to the builder. The builder on the other hand can act in the environment but has no knowledge about the task at hand and must learn to solve it relying only on the messages sent by the architect. Crucially, the meaning of messages is initially not defined nor shared between the agents but must be negotiated throughout learning. Under these constraints, we propose Architect-Builder Iterated Guiding (ABIG), a solution to the Architect-Builder Problem where the architect leverages a learned model of the builder to guide it while the builder uses self-imitation learning to reinforce its guided behavior. We analyze the key learning mechanisms of ABIG and test it in a 2-dimensional instantiation of the ABP where tasks involve grasping cubes, placing them at a given location, or building various shapes. In this environment, ABIG results in a low-level, high-frequency, guiding communication protocol that not only enables an architect-builder pair to solve the task at hand, but that can also generalize to unseen tasks.
Regularized Inverse Reinforcement Learning
Oct 07, 2020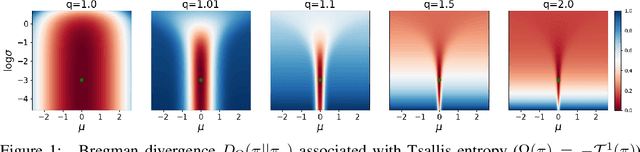


Inverse Reinforcement Learning (IRL) aims to facilitate a learner's ability to imitate expert behavior by acquiring reward functions that explain the expert's decisions. Regularized IRL applies convex regularizers to the learner's policy in order to avoid the expert's behavior being rationalized by arbitrary constant rewards, also known as degenerate solutions. We propose analytical solutions, and practical methods to obtain them, for regularized IRL. Current methods are restricted to the maximum-entropy IRL framework, limiting them to Shannon-entropy regularizers, as well as proposing functional-form solutions that are generally intractable. We present theoretical backing for our proposed IRL method's applicability to both discrete and continuous controls and empirically validate its performance on a variety of tasks.
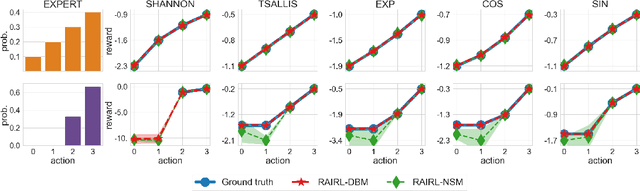
Adversarial Soft Advantage Fitting: Imitation Learning without Policy Optimization
Jun 23, 2020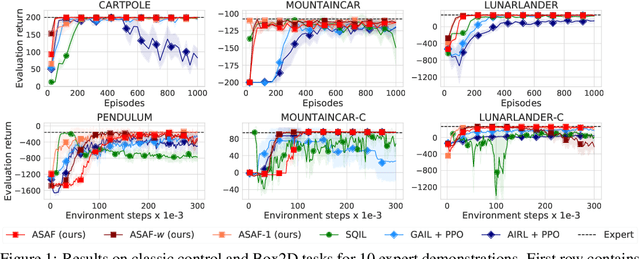
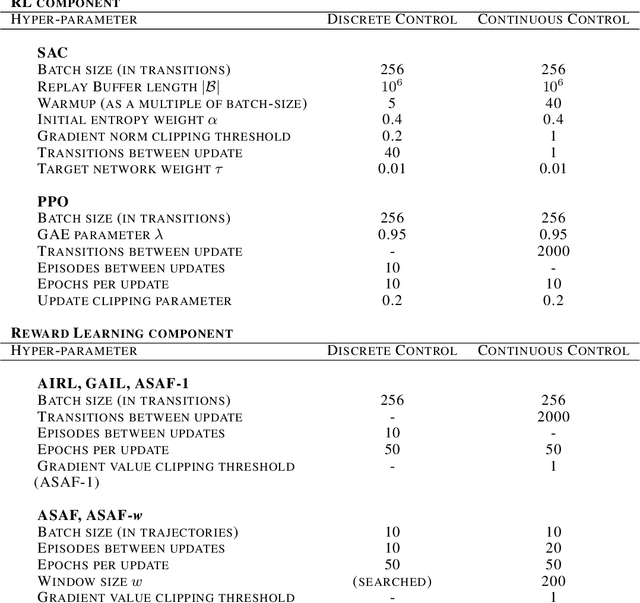
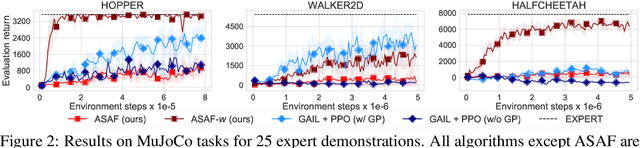
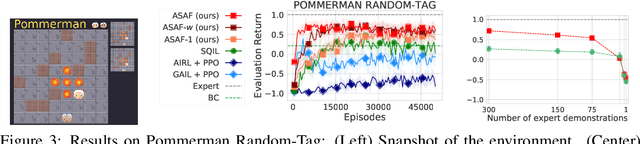
Adversarial imitation learning alternates between learning a discriminator -- which tells apart expert's demonstrations from generated ones -- and a generator's policy to produce trajectories that can fool this discriminator. This alternated optimization is known to be delicate in practice since it compounds unstable adversarial training with brittle and sample-inefficient reinforcement learning. We propose to remove the burden of the policy optimization steps by leveraging a novel discriminator formulation. Specifically, our discriminator is explicitly conditioned on two policies: the one from the previous generator's iteration and a learnable policy. When optimized, this discriminator directly learns the optimal generator's policy. Consequently, our discriminator's update solves the generator's optimization problem for free: learning a policy that imitates the expert does not require an additional optimization loop. This formulation effectively cuts by half the implementation and computational burden of adversarial imitation learning algorithms by removing the reinforcement learning phase altogether. We show on a variety of tasks that our simpler approach is competitive to prevalent imitation learning methods.
Scalable Multi-Agent Inverse Reinforcement Learning via Actor-Attention-Critic
Feb 24, 2020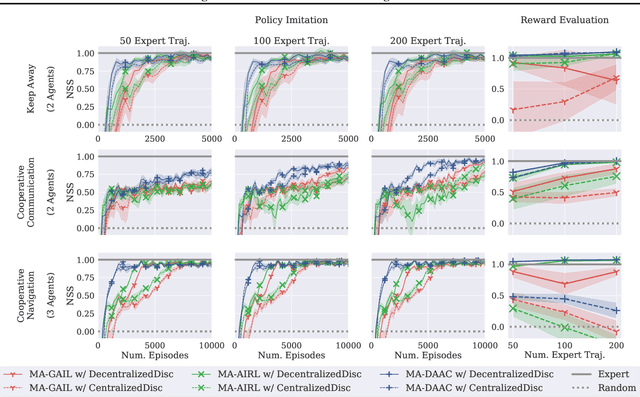
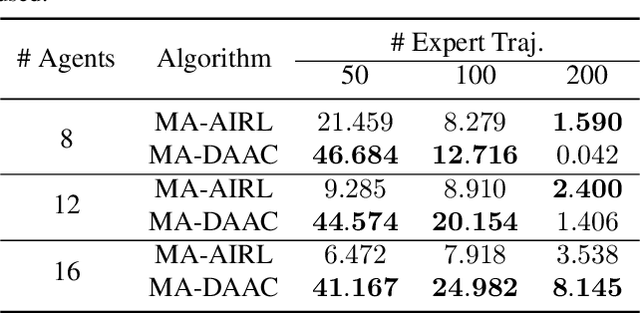
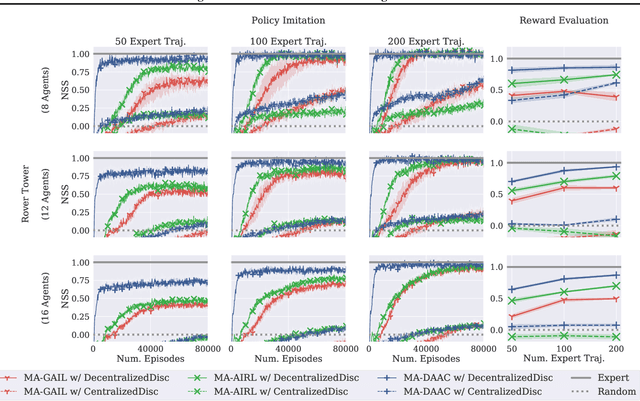
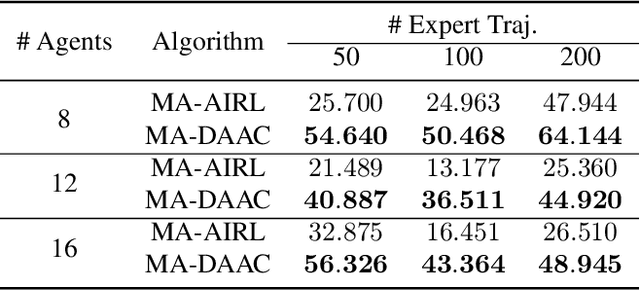
Multi-agent adversarial inverse reinforcement learning (MA-AIRL) is a recent approach that applies single-agent AIRL to multi-agent problems where we seek to recover both policies for our agents and reward functions that promote expert-like behavior. While MA-AIRL has promising results on cooperative and competitive tasks, it is sample-inefficient and has only been validated empirically for small numbers of agents -- its ability to scale to many agents remains an open question. We propose a multi-agent inverse RL algorithm that is more sample-efficient and scalable than previous works. Specifically, we employ multi-agent actor-attention-critic (MAAC) -- an off-policy multi-agent RL (MARL) method -- for the RL inner loop of the inverse RL procedure. In doing so, we are able to increase sample efficiency compared to state-of-the-art baselines, across both small- and large-scale tasks. Moreover, the RL agents trained on the rewards recovered by our method better match the experts than those trained on the rewards derived from the baselines. Finally, our method requires far fewer agent-environment interactions, particularly as the number of agents increases.
Promoting Coordination through Policy Regularization in Multi-Agent Reinforcement Learning
Aug 06, 2019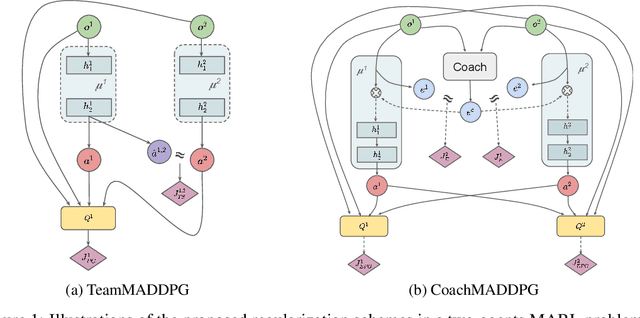
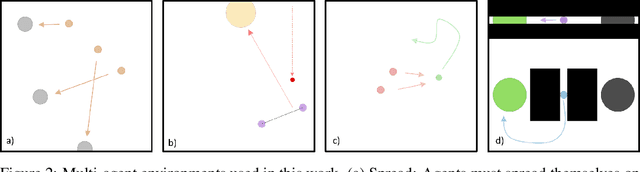
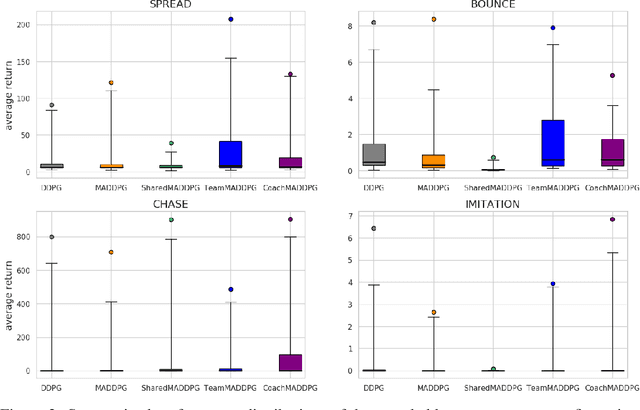
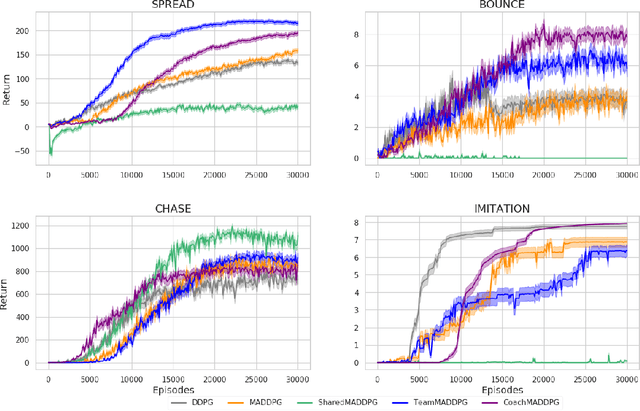
A central challenge in multi-agent reinforcement learning is the induction of coordination between agents of a team. In this work, we investigate how to promote inter-agent coordination and discuss two possible avenues based respectively on inter-agent modelling and guided synchronized sub-policies. We test each approach in four challenging continuous control tasks with sparse rewards and compare them against three variants of MADDPG, a state-of-the-art multi-agent reinforcement learning algorithm. To ensure a fair comparison, we rely on a thorough hyper-parameter selection and training methodology that allows a fixed hyper-parameter search budget for each algorithm and environment. We consequently assess both the hyper-parameter sensitivity, sample-efficiency and asymptotic performance of each learning method. Our experiments show that our proposed algorithms are more robust to the hyper-parameter choice and reliably lead to strong results.