 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Reward Specification in Deep Reinforcement Learning
Dec 10, 2024In the last decade, Deep Reinforcement Learning has evolved into a powerful tool for complex sequential decision-making problems. It combines deep learning's proficiency in processing rich input signals with reinforcement learning's adaptability across diverse control tasks. At its core, an RL agent seeks to maximize its cumulative reward, enabling AI algorithms to uncover novel solutions previously unknown to experts. However, this focus on reward maximization also introduces a significant difficulty: improper reward specification can result in unexpected, misaligned agent behavior and inefficient learning. The complexity of accurately specifying the reward function is further amplified by the sequential nature of the task, the sparsity of learning signals, and the multifaceted aspects of the desired behavior. In this thesis, we survey the literature on effective reward specification strategies, identify core challenges relating to each of these approaches, and propose original contributions addressing the issue of sample efficiency and alignment in deep reinforcement learning. Reward specification represents one of the most challenging aspects of applying reinforcement learning in real-world domains. Our work underscores the absence of a universal solution to this complex and nuanced challenge; solving it requires selecting the most appropriate tools for the specific requirements of each unique application.
Efficient Biological Data Acquisition through Inference Set Design
Oct 25, 2024



In drug discovery, highly automated high-throughput laboratories are used to screen a large number of compounds in search of effective drugs. These experiments are expensive, so we might hope to reduce their cost by experimenting on a subset of the compounds, and predicting the outcomes of the remaining experiments. In this work, we model this scenario as a sequential subset selection problem: we aim to select the smallest set of candidates in order to achieve some desired level of accuracy for the system as a whole. Our key observation is that, if there is heterogeneity in the difficulty of the prediction problem across the input space, selectively obtaining the labels for the hardest examples in the acquisition pool will leave only the relatively easy examples to remain in the inference set, leading to better overall system performance. We call this mechanism inference set design, and propose the use of an uncertainty-based active learning solution to prune out these challenging examples. Our algorithm includes an explicit stopping criterion that stops running the experiments when it is sufficiently confident that the system has reached the target performance. Our empirical studies on image and molecular datasets, as well as a real-world large-scale biological assay, show that deploying active learning for inference set design leads to significant reduction in experimental cost while obtaining high system performance.
SynFlowNet: Towards Molecule Design with Guaranteed Synthesis Pathways
May 02, 2024



Recent breakthroughs in generative modelling have led to a number of works proposing molecular generation models for drug discovery. While these models perform well at capturing drug-like motifs, they are known to often produce synthetically inaccessible molecules. This is because they are trained to compose atoms or fragments in a way that approximates the training distribution, but they are not explicitly aware of the synthesis constraints that come with making molecules in the lab. To address this issue, we introduce SynFlowNet, a GFlowNet model whose action space uses chemically validated reactions and reactants to sequentially build new molecules. We evaluate our approach using synthetic accessibility scores and an independent retrosynthesis tool. SynFlowNet consistently samples synthetically feasible molecules, while still being able to find diverse and high-utility candidates. Furthermore, we compare molecules designed with SynFlowNet to experimentally validated actives, and find that they show comparable properties of interest, such as molecular weight, SA score and predicted protein binding affinity.
Goal-conditioned GFlowNets for Controllable Multi-Objective Molecular Design
Jun 29, 2023In recent years, in-silico molecular design has received much attention from the machine learning community. When designing a new compound for pharmaceutical applications, there are usually multiple properties of such molecules that need to be optimised: binding energy to the target, synthesizability, toxicity, EC50, and so on. While previous approaches have employed a scalarization scheme to turn the multi-objective problem into a preference-conditioned single objective, it has been established that this kind of reduction may produce solutions that tend to slide towards the extreme points of the objective space when presented with a problem that exhibits a concave Pareto front. In this work we experiment with an alternative formulation of goal-conditioned molecular generation to obtain a more controllable conditional model that can uniformly explore solutions along the entire Pareto front.
Direct Behavior Specification via Constrained Reinforcement Learning
Jan 19, 2022
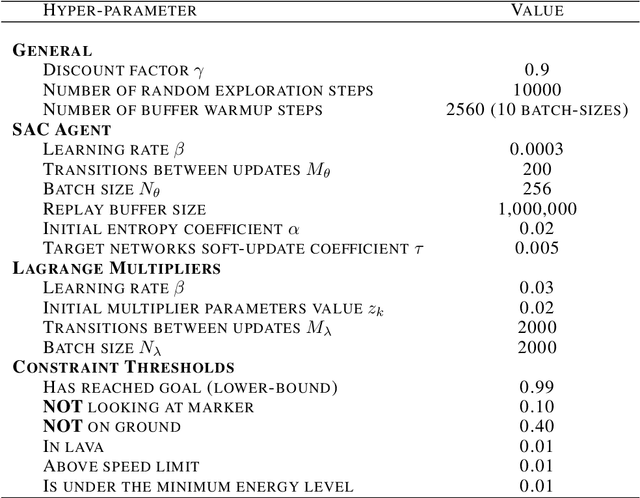
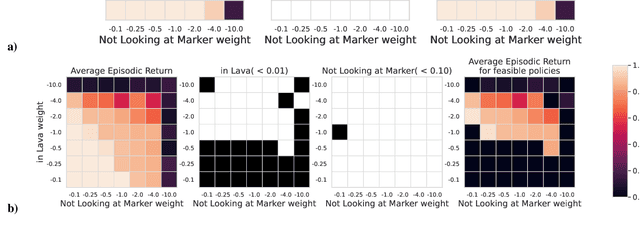

The standard formulation of Reinforcement Learning lacks a practical way of specifying what are admissible and forbidden behaviors. Most often, practitioners go about the task of behavior specification by manually engineering the reward function, a counter-intuitive process that requires several iterations and is prone to reward hacking by the agent. In this work, we argue that constrained RL, which has almost exclusively been used for safe RL, also has the potential to significantly reduce the amount of work spent for reward specification in applied RL projects. To this end, we propose to specify behavioral preferences in the CMDP framework and to use Lagrangian methods to automatically weigh each of these behavioral constraints. Specifically, we investigate how CMDPs can be adapted to solve goal-based tasks while adhering to several constraints simultaneously. We evaluate this framework on a set of continuous control tasks relevant to the application of Reinforcement Learning for NPC design in video games.
Adversarial Soft Advantage Fitting: Imitation Learning without Policy Optimization
Jun 23, 2020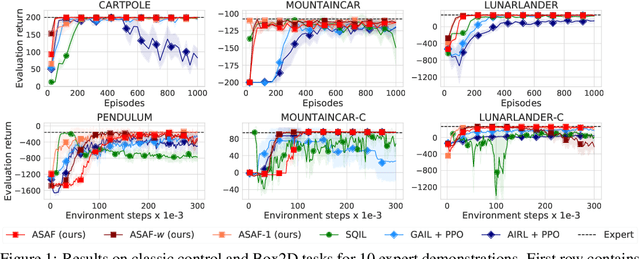
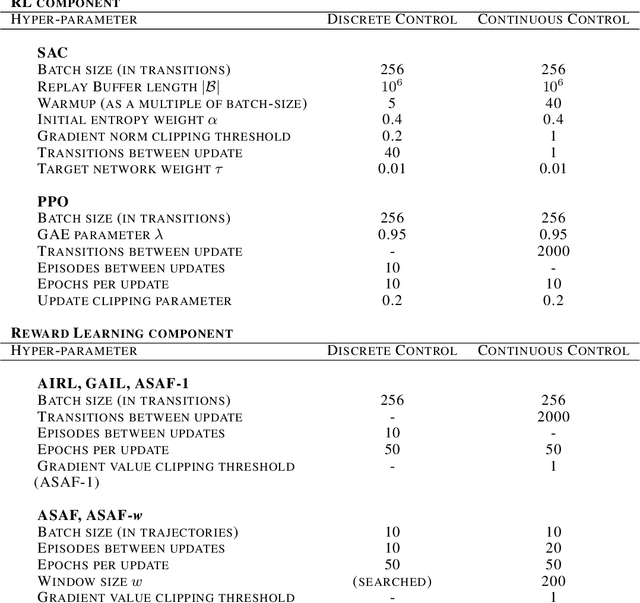
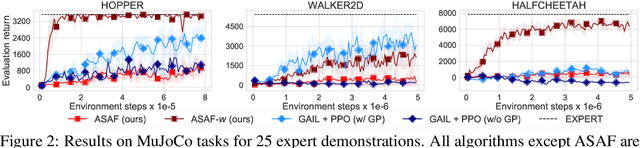
Adversarial imitation learning alternates between learning a discriminator -- which tells apart expert's demonstrations from generated ones -- and a generator's policy to produce trajectories that can fool this discriminator. This alternated optimization is known to be delicate in practice since it compounds unstable adversarial training with brittle and sample-inefficient reinforcement learning. We propose to remove the burden of the policy optimization steps by leveraging a novel discriminator formulation. Specifically, our discriminator is explicitly conditioned on two policies: the one from the previous generator's iteration and a learnable policy. When optimized, this discriminator directly learns the optimal generator's policy. Consequently, our discriminator's update solves the generator's optimization problem for free: learning a policy that imitates the expert does not require an additional optimization loop. This formulation effectively cuts by half the implementation and computational burden of adversarial imitation learning algorithms by removing the reinforcement learning phase altogether. We show on a variety of tasks that our simpler approach is competitive to prevalent imitation learning methods.
Option-critic in cooperative multi-agent systems
Jan 06, 2020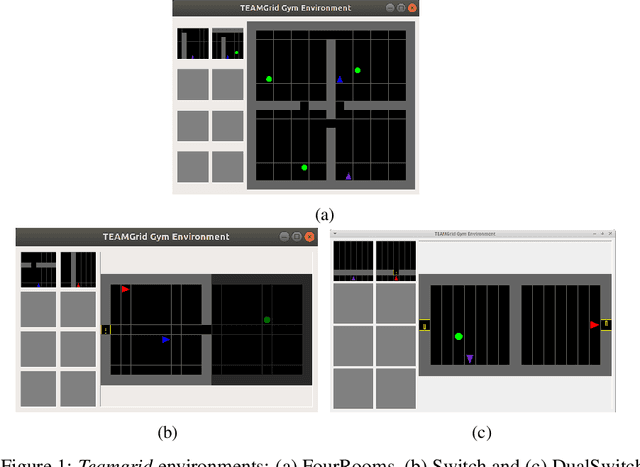
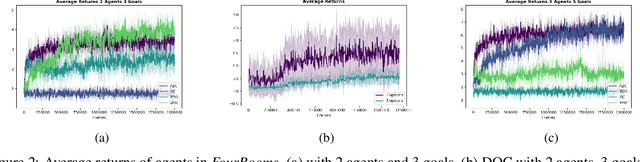
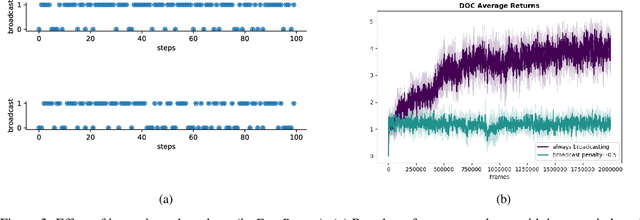
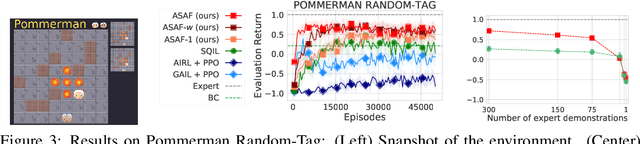
In this paper, we investigate learning temporal abstractions in cooperative multi-agent systems using the options framework (Sutton et al, 1999) and provide a model-free algorithm for this problem. First, we address the planning problem for the decentralized POMDP represented by the multi-agent system, by introducing a common information approach. We use common beliefs and broadcasting to solve an equivalent centralized POMDP problem. Then, we propose the Distributed Option Critic (DOC) algorithm, motivated by the work of Bacon et al (2017) in the single-agent setting. Our approach uses centralized option evaluation and decentralized intra-option improvement. We analyze theoretically the asymptotic convergence of DOC and validate its performance in grid-world environments, where we implement DOC using a deep neural network. Our experiments show that DOC performs competitively with state-of-the-art algorithms and that it is scalable when the number of agents increases.
Promoting Coordination through Policy Regularization in Multi-Agent Reinforcement Learning
Aug 06, 2019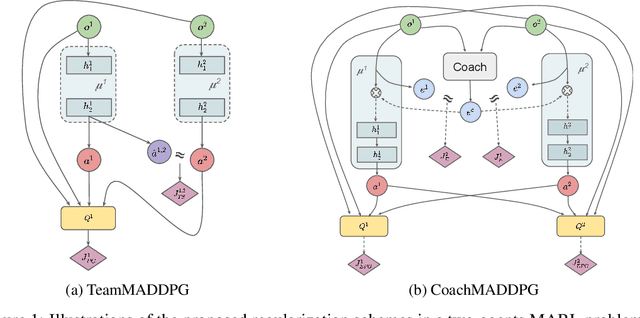
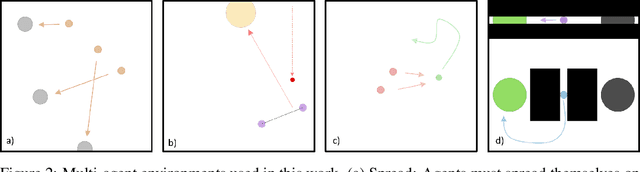
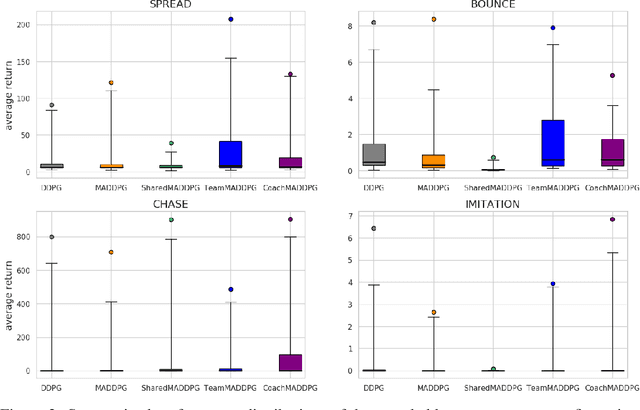
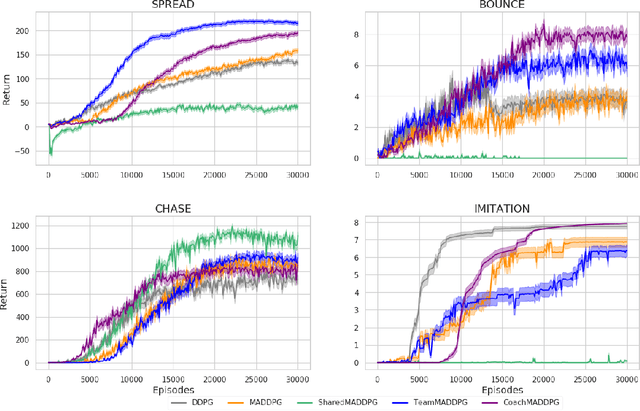
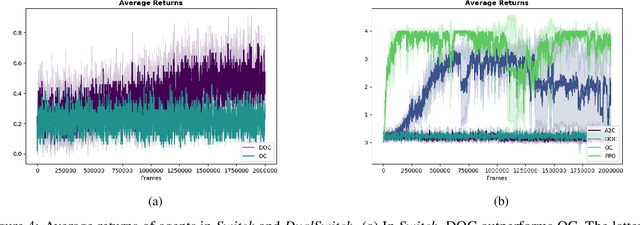
A central challenge in multi-agent reinforcement learning is the induction of coordination between agents of a team. In this work, we investigate how to promote inter-agent coordination and discuss two possible avenues based respectively on inter-agent modelling and guided synchronized sub-policies. We test each approach in four challenging continuous control tasks with sparse rewards and compare them against three variants of MADDPG, a state-of-the-art multi-agent reinforcement learning algorithm. To ensure a fair comparison, we rely on a thorough hyper-parameter selection and training methodology that allows a fixed hyper-parameter search budget for each algorithm and environment. We consequently assess both the hyper-parameter sensitivity, sample-efficiency and asymptotic performance of each learning method. Our experiments show that our proposed algorithms are more robust to the hyper-parameter choice and reliably lead to strong results.
Recurrent Semi-supervised Classification and Constrained Adversarial Generation with Motion Capture Data
Jul 11, 2018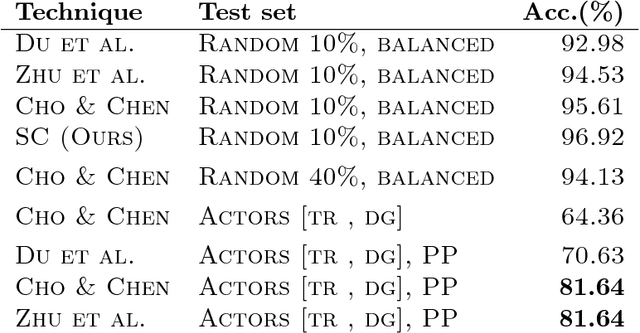
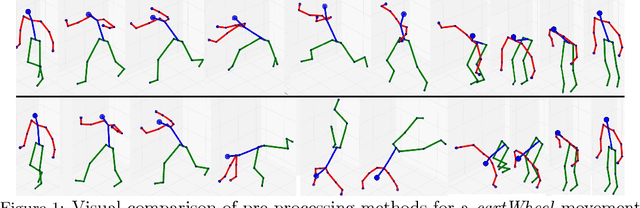
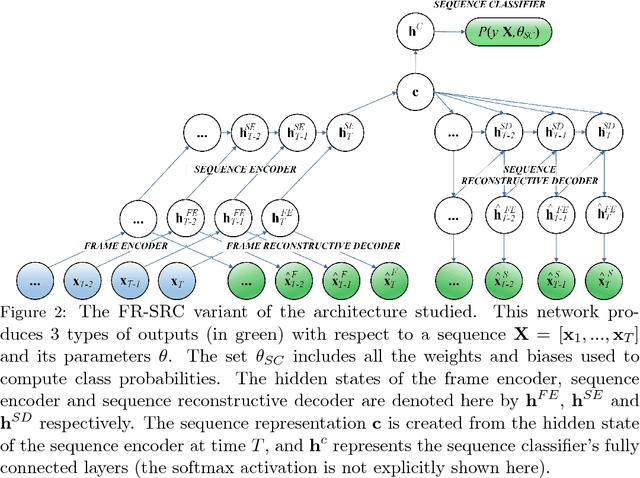
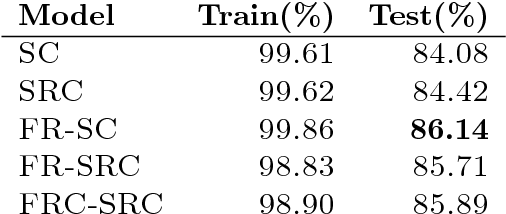
We explore recurrent encoder multi-decoder neural network architectures for semi-supervised sequence classification and reconstruction. We find that the use of multiple reconstruction modules helps models generalize in a classification task when only a small amount of labeled data is available, which is often the case in practice. Such models provide useful high-level representations of motions allowing clustering, searching and faster labeling of new sequences. We also propose a new, realistic partitioning of a well-known, high quality motion-capture dataset for better evaluations. We further explore a novel formulation for future-predicting decoders based on conditional recurrent generative adversarial networks, for which we propose both soft and hard constraints for transition generation derived from desired physical properties of synthesized future movements and desired animation goals. We find that using such constraints allow to stabilize the training of recurrent adversarial architectures for animation generation.