 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDSDF: Hybrid Directional and Signed Distance Functions for Fast Inverse Rendering
Mar 30, 2022

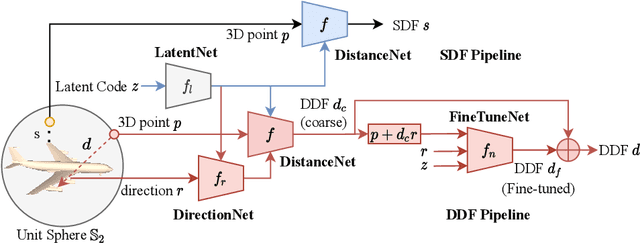
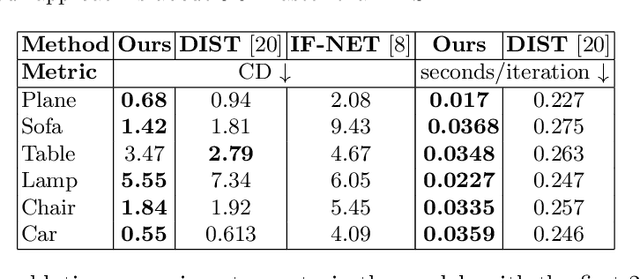
Implicit neural representations of 3D shapes form strong priors that are useful for various applications, such as single and multiple view 3D reconstruction. A downside of existing neural representations is that they require multiple network evaluations for rendering, which leads to high computational costs. This limitation forms a bottleneck particularly in the context of inverse problems, such as image-based 3D reconstruction. To address this issue, in this paper (i) we propose a novel hybrid 3D object representation based on a signed distance function (SDF) that we augment with a directional distance function (DDF), so that we can predict distances to the object surface from any point on a sphere enclosing the object. Moreover, (ii) using the proposed hybrid representation we address the multi-view consistency problem common in existing DDF representations. We evaluate our novel hybrid representation on the task of single-view depth reconstruction and show that our method is several times faster compared to competing methods, while at the same time achieving better reconstruction accuracy.
Disentangled3D: Learning a 3D Generative Model with Disentangled Geometry and Appearance from Monocular Images
Mar 29, 2022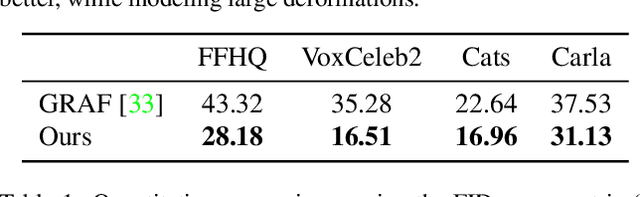
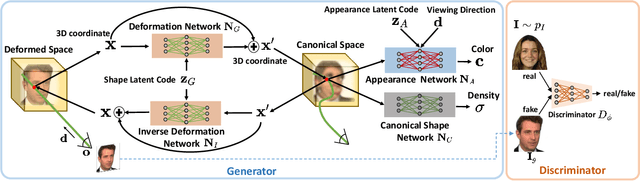


Learning 3D generative models from a dataset of monocular images enables self-supervised 3D reasoning and controllable synthesis. State-of-the-art 3D generative models are GANs which use neural 3D volumetric representations for synthesis. Images are synthesized by rendering the volumes from a given camera. These models can disentangle the 3D scene from the camera viewpoint in any generated image. However, most models do not disentangle other factors of image formation, such as geometry and appearance. In this paper, we design a 3D GAN which can learn a disentangled model of objects, just from monocular observations. Our model can disentangle the geometry and appearance variations in the scene, i.e., we can independently sample from the geometry and appearance spaces of the generative model. This is achieved using a novel non-rigid deformable scene formulation. A 3D volume which represents an object instance is computed as a non-rigidly deformed canonical 3D volume. Our method learns the canonical volume, as well as its deformations, jointly during training. This formulation also helps us improve the disentanglement between the 3D scene and the camera viewpoints using a novel pose regularization loss defined on the 3D deformation field. In addition, we further model the inverse deformations, enabling the computation of dense correspondences between images generated by our model. Finally, we design an approach to embed real images into the latent space of our disentangled generative model, enabling editing of real images.
φ-SfT: Shape-from-Template with a Physics-Based Deformation Model
Mar 22, 2022
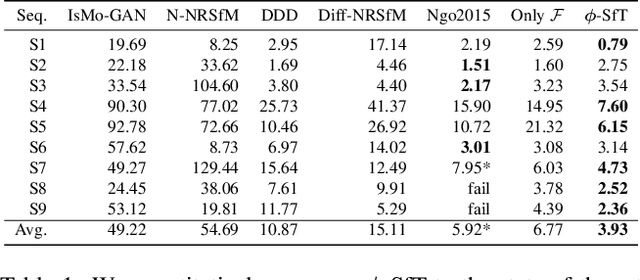
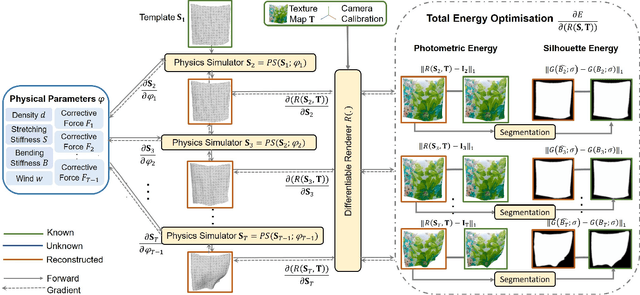
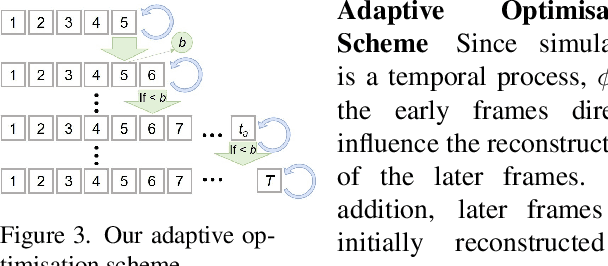
Shape-from-Template (SfT) methods estimate 3D surface deformations from a single monocular RGB camera while assuming a 3D state known in advance (a template). This is an important yet challenging problem due to the under-constrained nature of the monocular setting. Existing SfT techniques predominantly use geometric and simplified deformation models, which often limits their reconstruction abilities. In contrast to previous works, this paper proposes a new SfT approach explaining 2D observations through physical simulations accounting for forces and material properties. Our differentiable physics simulator regularises the surface evolution and optimises the material elastic properties such as bending coefficients, stretching stiffness and density. We use a differentiable renderer to minimise the dense reprojection error between the estimated 3D states and the input images and recover the deformation parameters using an adaptive gradient-based optimisation. For the evaluation, we record with an RGB-D camera challenging real surfaces exposed to physical forces with various material properties and textures. Our approach significantly reduces the 3D reconstruction error compared to multiple competing methods. For the source code and data, see https://4dqv.mpi-inf.mpg.de/phi-SfT/.
Playable Environments: Video Manipulation in Space and Time
Mar 15, 2022

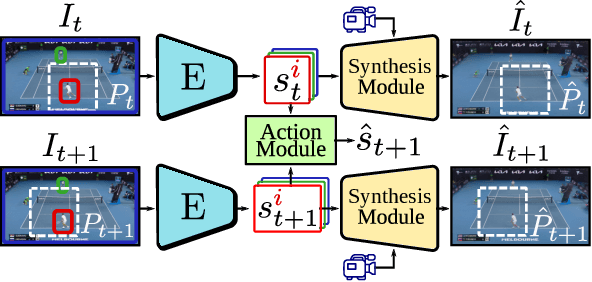
We present Playable Environments - a new representation for interactive video generation and manipulation in space and time. With a single image at inference time, our novel framework allows the user to move objects in 3D while generating a video by providing a sequence of desired actions. The actions are learnt in an unsupervised manner. The camera can be controlled to get the desired viewpoint. Our method builds an environment state for each frame, which can be manipulated by our proposed action module and decoded back to the image space with volumetric rendering. To support diverse appearances of objects, we extend neural radiance fields with style-based modulation. Our method trains on a collection of various monocular videos requiring only the estimated camera parameters and 2D object locations. To set a challenging benchmark, we introduce two large scale video datasets with significant camera movements. As evidenced by our experiments, playable environments enable several creative applications not attainable by prior video synthesis works, including playable 3D video generation, stylization and manipulation. Further details, code and examples are available at https://willi-menapace.github.io/playable-environments-website
Estimating Egocentric 3D Human Pose in the Wild with External Weak Supervision
Jan 20, 2022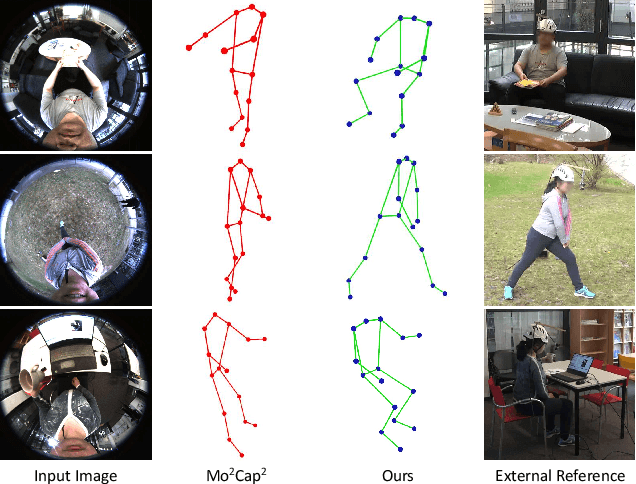

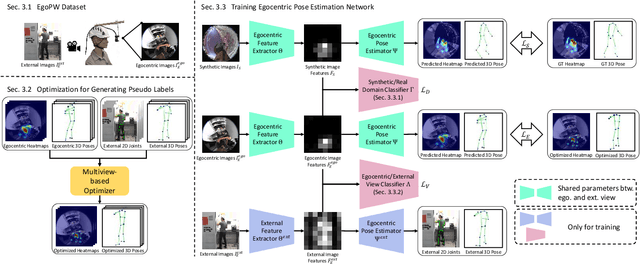
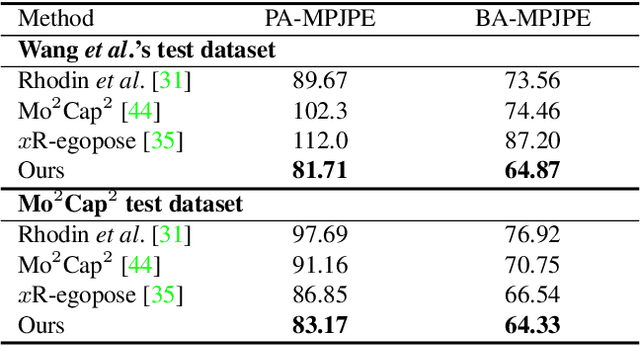
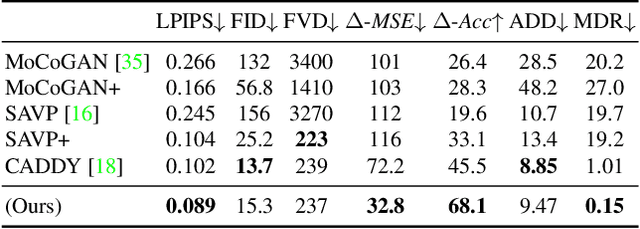
Egocentric 3D human pose estimation with a single fisheye camera has drawn a significant amount of attention recently. However, existing methods struggle with pose estimation from in-the-wild images, because they can only be trained on synthetic data due to the unavailability of large-scale in-the-wild egocentric datasets. Furthermore, these methods easily fail when the body parts are occluded by or interacting with the surrounding scene. To address the shortage of in-the-wild data, we collect a large-scale in-the-wild egocentric dataset called Egocentric Poses in the Wild (EgoPW). This dataset is captured by a head-mounted fisheye camera and an auxiliary external camera, which provides an additional observation of the human body from a third-person perspective during training. We present a new egocentric pose estimation method, which can be trained on the new dataset with weak external supervision. Specifically, we first generate pseudo labels for the EgoPW dataset with a spatio-temporal optimization method by incorporating the external-view supervision. The pseudo labels are then used to train an egocentric pose estimation network. To facilitate the network training, we propose a novel learning strategy to supervise the egocentric features with the high-quality features extracted by a pretrained external-view pose estimation model. The experiments show that our method predicts accurate 3D poses from a single in-the-wild egocentric image and outperforms the state-of-the-art methods both quantitatively and qualitatively.
CityNeRF: Building NeRF at City Scale
Dec 17, 2021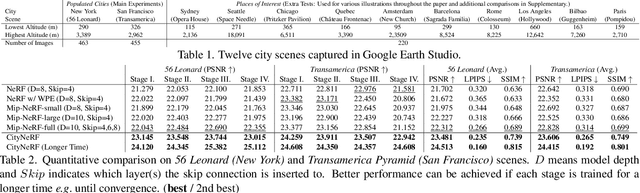
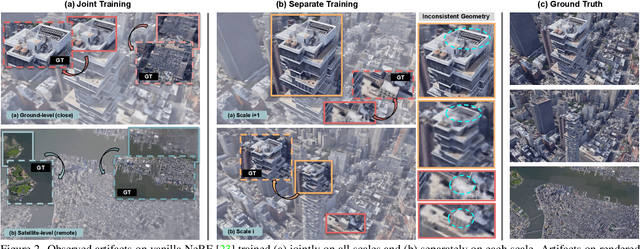


Neural Radiance Field (NeRF) has achieved outstanding performance in modeling 3D objects and controlled scenes, usually under a single scale. In this work, we make the first attempt to bring NeRF to city-scale, with views ranging from satellite-level that captures the overview of a city, to ground-level imagery showing complex details of an architecture. The wide span of camera distance to the scene yields multi-scale data with different levels of detail and spatial coverage, which casts great challenges to vanilla NeRF and biases it towards compromised results. To address these issues, we introduce CityNeRF, a progressive learning paradigm that grows the NeRF model and training set synchronously. Starting from fitting distant views with a shallow base block, as training progresses, new blocks are appended to accommodate the emerging details in the increasingly closer views. The strategy effectively activates high-frequency channels in the positional encoding and unfolds more complex details as the training proceeds. We demonstrate the superiority of CityNeRF in modeling diverse city-scale scenes with drastically varying views, and its support for rendering views in different levels of detail.
Neural Radiance Fields for Outdoor Scene Relighting
Dec 09, 2021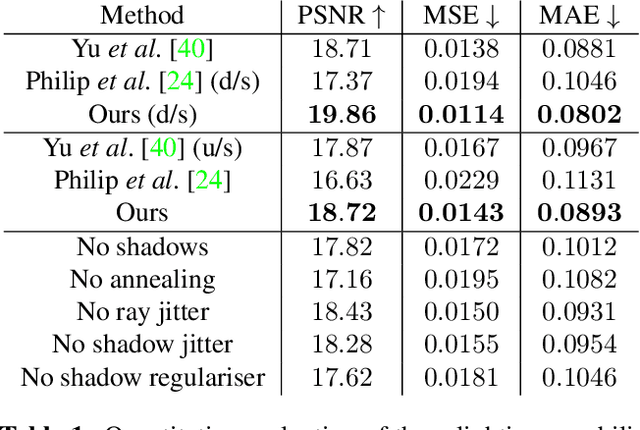
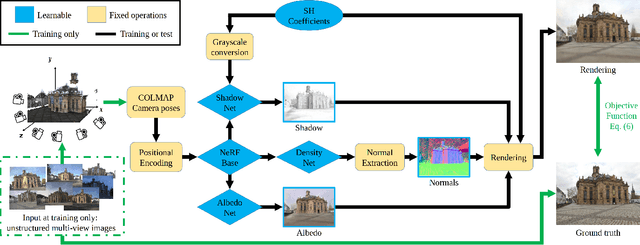
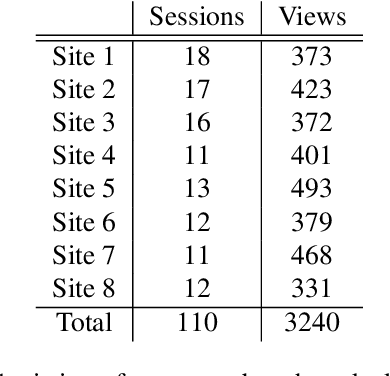

Photorealistic editing of outdoor scenes from photographs requires a profound understanding of the image formation process and an accurate estimation of the scene geometry, reflectance and illumination. A delicate manipulation of the lighting can then be performed while keeping the scene albedo and geometry unaltered. We present NeRF-OSR, i.e., the first approach for outdoor scene relighting based on neural radiance fields. In contrast to the prior art, our technique allows simultaneous editing of both scene illumination and camera viewpoint using only a collection of outdoor photos shot in uncontrolled settings. Moreover, it enables direct control over the scene illumination, as defined through a spherical harmonics model. It also includes a dedicated network for shadow reproduction, which is crucial for high-quality outdoor scene relighting. To evaluate the proposed method, we collect a new benchmark dataset of several outdoor sites, where each site is photographed from multiple viewpoints and at different timings. For each timing, a 360 degrees environment map is captured together with a colour-calibration chequerboard to allow accurate numerical evaluations on real data against ground truth. Comparisons against state of the art show that NeRF-OSR enables controllable lighting and viewpoint editing at higher quality and with realistic self-shadowing reproduction. Our method and the dataset will be made publicly available at https://4dqv.mpi-inf.mpg.de/NeRF-OSR/.
EgoRenderer: Rendering Human Avatars from Egocentric Camera Images
Nov 24, 2021
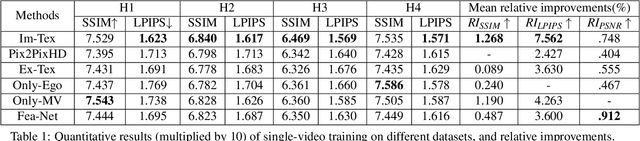
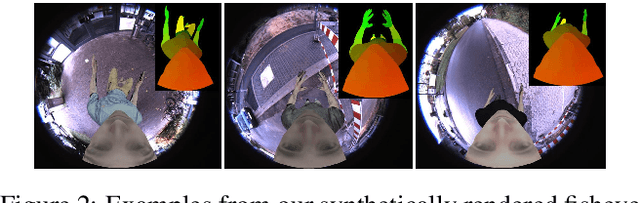
We present EgoRenderer, a system for rendering full-body neural avatars of a person captured by a wearable, egocentric fisheye camera that is mounted on a cap or a VR headset. Our system renders photorealistic novel views of the actor and her motion from arbitrary virtual camera locations. Rendering full-body avatars from such egocentric images come with unique challenges due to the top-down view and large distortions. We tackle these challenges by decomposing the rendering process into several steps, including texture synthesis, pose construction, and neural image translation. For texture synthesis, we propose Ego-DPNet, a neural network that infers dense correspondences between the input fisheye images and an underlying parametric body model, and to extract textures from egocentric inputs. In addition, to encode dynamic appearances, our approach also learns an implicit texture stack that captures detailed appearance variation across poses and viewpoints. For correct pose generation, we first estimate body pose from the egocentric view using a parametric model. We then synthesize an external free-viewpoint pose image by projecting the parametric model to the user-specified target viewpoint. We next combine the target pose image and the textures into a combined feature image, which is transformed into the output color image using a neural image translation network. Experimental evaluations show that EgoRenderer is capable of generating realistic free-viewpoint avatars of a person wearing an egocentric camera. Comparisons to several baselines demonstrate the advantages of our approach.
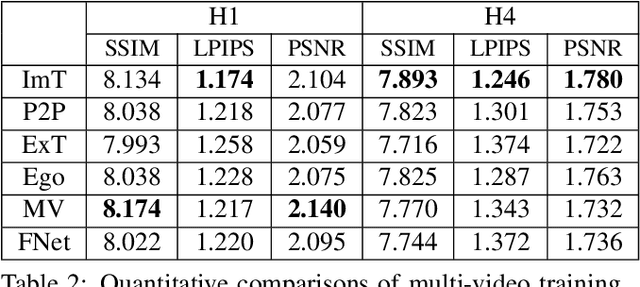
A Deeper Look into DeepCap
Nov 20, 2021
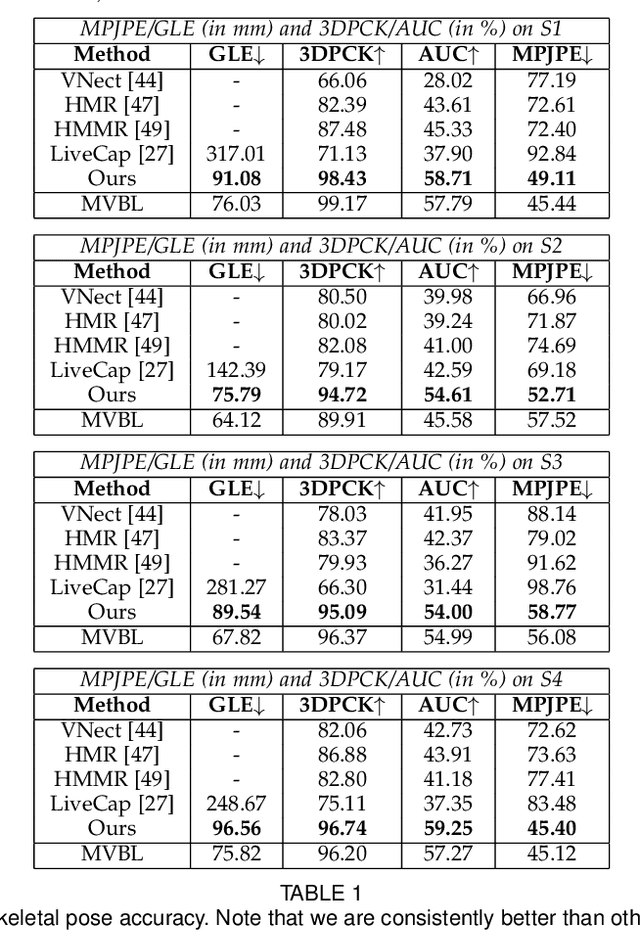
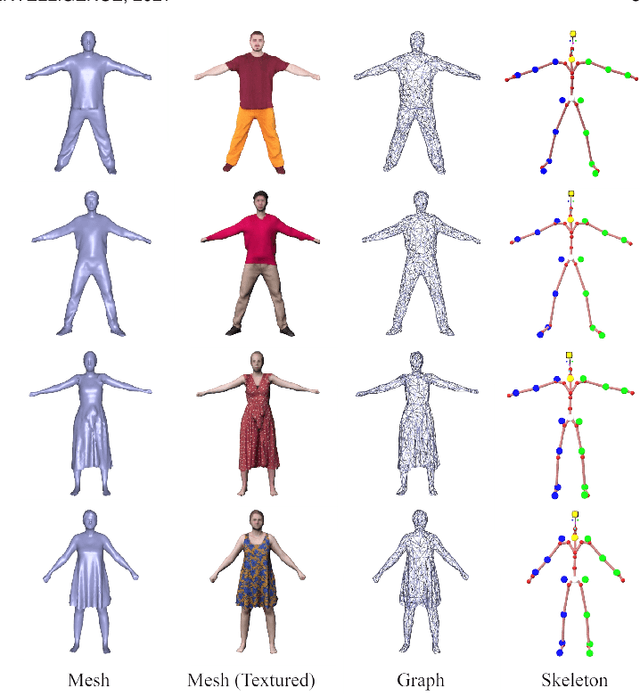
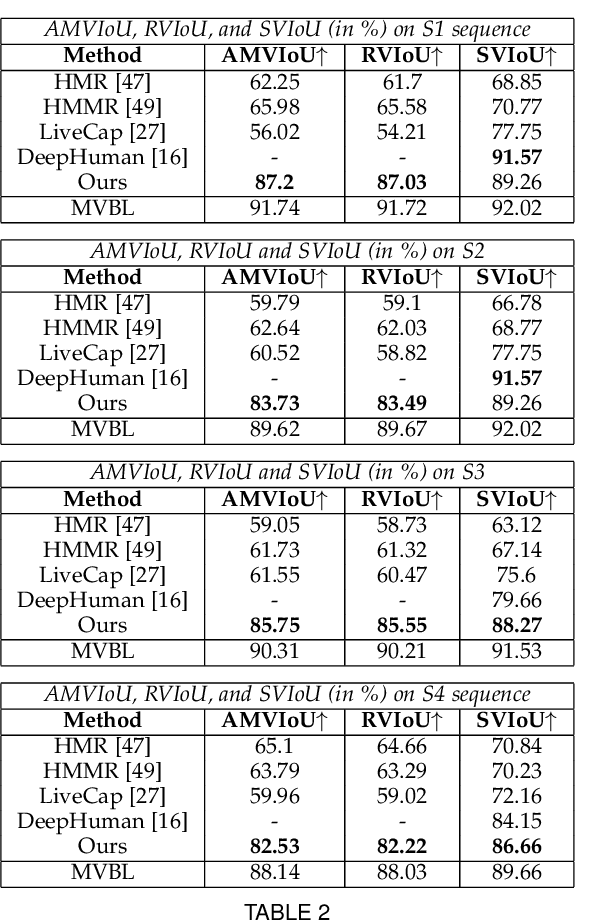
Human performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups or did not recover dense space-time coherent geometry with frame-to-frame correspondences. We propose a novel deep learning approach for monocular dense human performance capture. Our method is trained in a weakly supervised manner based on multi-view supervision completely removing the need for training data with 3D ground truth annotations. The network architecture is based on two separate networks that disentangle the task into a pose estimation and a non-rigid surface deformation step. Extensive qualitative and quantitative evaluations show that our approach outperforms the state of the art in terms of quality and robustness. This work is an extended version of DeepCap where we provide more detailed explanations, comparisons and results as well as applications.
Advances in Neural Rendering
Nov 10, 2021Synthesizing photo-realistic images and videos is at the heart of computer graphics and has been the focus of decades of research. Traditionally, synthetic images of a scene are generated using rendering algorithms such as rasterization or ray tracing, which take specifically defined representations of geometry and material properties as input. Collectively, these inputs define the actual scene and what is rendered, and are referred to as the scene representation (where a scene consists of one or more objects). Example scene representations are triangle meshes with accompanied textures (e.g., created by an artist), point clouds (e.g., from a depth sensor), volumetric grids (e.g., from a CT scan), or implicit surface functions (e.g., truncated signed distance fields). The reconstruction of such a scene representation from observations using differentiable rendering losses is known as inverse graphics or inverse rendering. Neural rendering is closely related, and combines ideas from classical computer graphics and machine learning to create algorithms for synthesizing images from real-world observations. Neural rendering is a leap forward towards the goal of synthesizing photo-realistic image and video content. In recent years, we have seen immense progress in this field through hundreds of publications that show different ways to inject learnable components into the rendering pipeline. This state-of-the-art report on advances in neural rendering focuses on methods that combine classical rendering principles with learned 3D scene representations, often now referred to as neural scene representations. A key advantage of these methods is that they are 3D-consistent by design, enabling applications such as novel viewpoint synthesis of a captured scene. In addition to methods that handle static scenes, we cover neural scene representations for modeling non-rigidly deforming objects...