 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Provable Benefits of Unsupervised Data Sharing for Offline Reinforcement Learning
Feb 27, 2023



Self-supervised methods have become crucial for advancing deep learning by leveraging data itself to reduce the need for expensive annotations. However, the question of how to conduct self-supervised offline reinforcement learning (RL) in a principled way remains unclear. In this paper, we address this issue by investigating the theoretical benefits of utilizing reward-free data in linear Markov Decision Processes (MDPs) within a semi-supervised setting. Further, we propose a novel, Provable Data Sharing algorithm (PDS) to utilize such reward-free data for offline RL. PDS uses additional penalties on the reward function learned from labeled data to prevent overestimation, ensuring a conservative algorithm. Our results on various offline RL tasks demonstrate that PDS significantly improves the performance of offline RL algorithms with reward-free data. Overall, our work provides a promising approach to leveraging the benefits of unlabeled data in offline RL while maintaining theoretical guarantees. We believe our findings will contribute to developing more robust self-supervised RL methods.
A Survey on Transformers in Reinforcement Learning
Jan 08, 2023Transformer has been considered the dominating neural architecture in NLP and CV, mostly under a supervised setting. Recently, a similar surge of using Transformers has appeared in the domain of reinforcement learning (RL), but it is faced with unique design choices and challenges brought by the nature of RL. However, the evolution of Transformers in RL has not yet been well unraveled. Hence, in this paper, we seek to systematically review motivations and progress on using Transformers in RL, provide a taxonomy on existing works, discuss each sub-field, and summarize future prospects.
Flow to Control: Offline Reinforcement Learning with Lossless Primitive Discovery
Dec 02, 2022



Offline reinforcement learning (RL) enables the agent to effectively learn from logged data, which significantly extends the applicability of RL algorithms in real-world scenarios where exploration can be expensive or unsafe. Previous works have shown that extracting primitive skills from the recurring and temporally extended structures in the logged data yields better learning. However, these methods suffer greatly when the primitives have limited representation ability to recover the original policy space, especially in offline settings. In this paper, we give a quantitative characterization of the performance of offline hierarchical learning and highlight the importance of learning lossless primitives. To this end, we propose to use a \emph{flow}-based structure as the representation for low-level policies. This allows us to represent the behaviors in the dataset faithfully while keeping the expression ability to recover the whole policy space. We show that such lossless primitives can drastically improve the performance of hierarchical policies. The experimental results and extensive ablation studies on the standard D4RL benchmark show that our method has a good representation ability for policies and achieves superior performance in most tasks.
* 13pages
Low-Rank Modular Reinforcement Learning via Muscle Synergy
Oct 26, 2022



Modular Reinforcement Learning (RL) decentralizes the control of multi-joint robots by learning policies for each actuator. Previous work on modular RL has proven its ability to control morphologically different agents with a shared actuator policy. However, with the increase in the Degree of Freedom (DoF) of robots, training a morphology-generalizable modular controller becomes exponentially difficult. Motivated by the way the human central nervous system controls numerous muscles, we propose a Synergy-Oriented LeARning (SOLAR) framework that exploits the redundant nature of DoF in robot control. Actuators are grouped into synergies by an unsupervised learning method, and a synergy action is learned to control multiple actuators in synchrony. In this way, we achieve a low-rank control at the synergy level. We extensively evaluate our method on a variety of robot morphologies, and the results show its superior efficiency and generalizability, especially on robots with a large DoF like Humanoids++ and UNIMALs.
Non-Linear Coordination Graphs
Oct 26, 2022



Value decomposition multi-agent reinforcement learning methods learn the global value function as a mixing of each agent's individual utility functions. Coordination graphs (CGs) represent a higher-order decomposition by incorporating pairwise payoff functions and thus is supposed to have a more powerful representational capacity. However, CGs decompose the global value function linearly over local value functions, severely limiting the complexity of the value function class that can be represented. In this paper, we propose the first non-linear coordination graph by extending CG value decomposition beyond the linear case. One major challenge is to conduct greedy action selections in this new function class to which commonly adopted DCOP algorithms are no longer applicable. We study how to solve this problem when mixing networks with LeakyReLU activation are used. An enumeration method with a global optimality guarantee is proposed and motivates an efficient iterative optimization method with a local optimality guarantee. We find that our method can achieve superior performance on challenging multi-agent coordination tasks like MACO.
* Authors are listed in alphabetical order
CUP: Critic-Guided Policy Reuse
Oct 15, 2022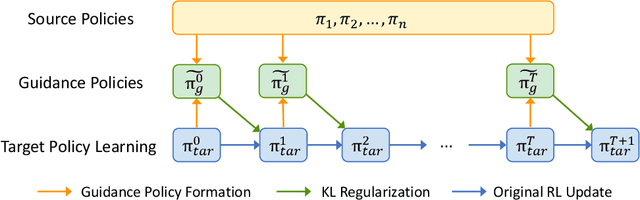
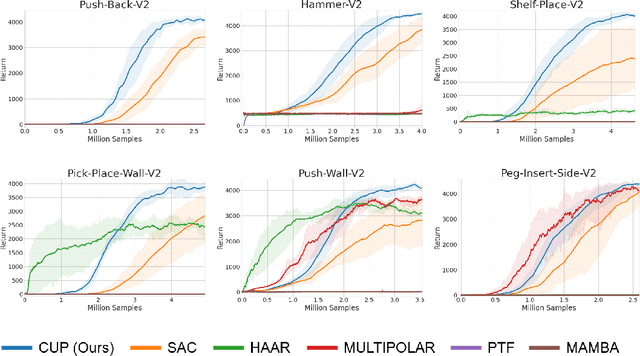
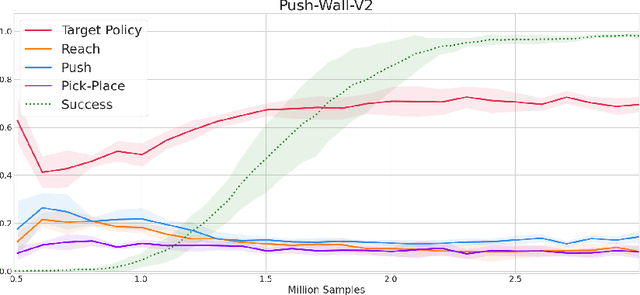
The ability to reuse previous policies is an important aspect of human intelligence. To achieve efficient policy reuse, a Deep Reinforcement Learning (DRL) agent needs to decide when to reuse and which source policies to reuse. Previous methods solve this problem by introducing extra components to the underlying algorithm, such as hierarchical high-level policies over source policies, or estimations of source policies' value functions on the target task. However, training these components induces either optimization non-stationarity or heavy sampling cost, significantly impairing the effectiveness of transfer. To tackle this problem, we propose a novel policy reuse algorithm called Critic-gUided Policy reuse (CUP), which avoids training any extra components and efficiently reuses source policies. CUP utilizes the critic, a common component in actor-critic methods, to evaluate and choose source policies. At each state, CUP chooses the source policy that has the largest one-step improvement over the current target policy, and forms a guidance policy. The guidance policy is theoretically guaranteed to be a monotonic improvement over the current target policy. Then the target policy is regularized to imitate the guidance policy to perform efficient policy search. Empirical results demonstrate that CUP achieves efficient transfer and significantly outperforms baseline algorithms.
On the Role of Discount Factor in Offline Reinforcement Learning
Jun 15, 2022
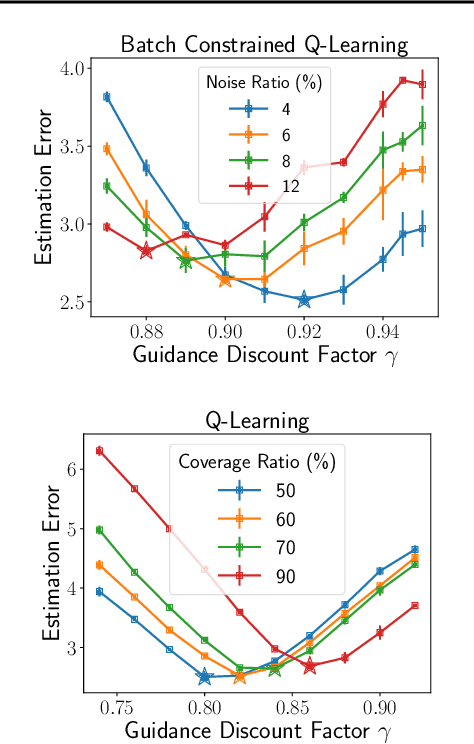
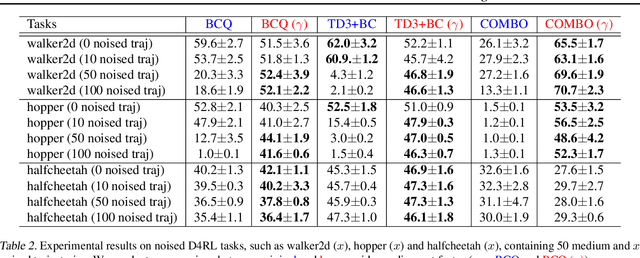
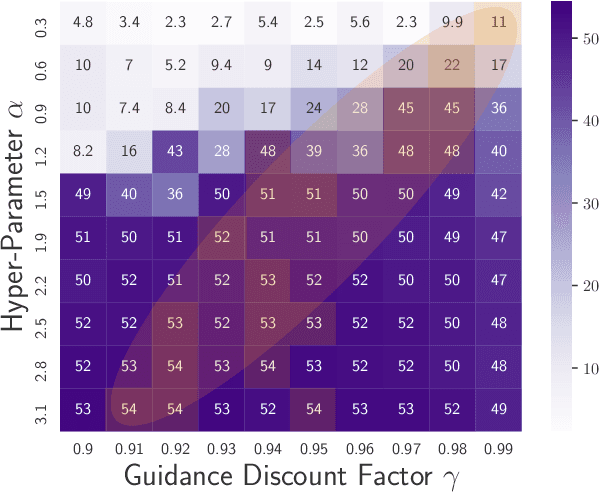
Offline reinforcement learning (RL) enables effective learning from previously collected data without exploration, which shows great promise in real-world applications when exploration is expensive or even infeasible. The discount factor, $\gamma$, plays a vital role in improving online RL sample efficiency and estimation accuracy, but the role of the discount factor in offline RL is not well explored. This paper examines two distinct effects of $\gamma$ in offline RL with theoretical analysis, namely the regularization effect and the pessimism effect. On the one hand, $\gamma$ is a regulator to trade-off optimality with sample efficiency upon existing offline techniques. On the other hand, lower guidance $\gamma$ can also be seen as a way of pessimism where we optimize the policy's performance in the worst possible models. We empirically verify the above theoretical observation with tabular MDPs and standard D4RL tasks. The results show that the discount factor plays an essential role in the performance of offline RL algorithms, both under small data regimes upon existing offline methods and in large data regimes without other conservative methods.
RORL: Robust Offline Reinforcement Learning via Conservative Smoothing
Jun 06, 2022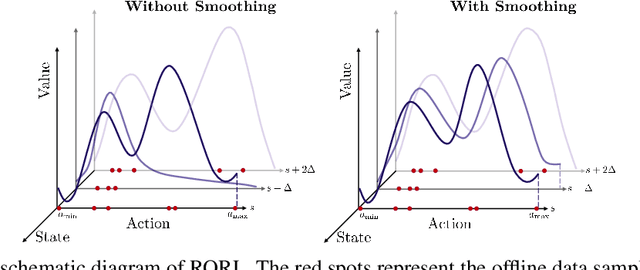
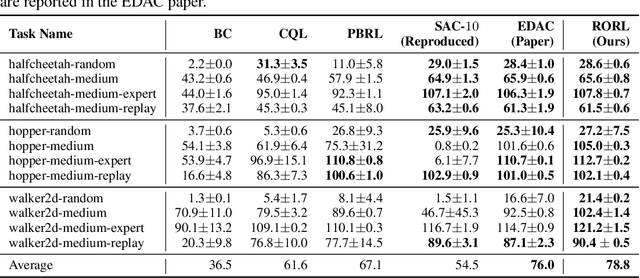
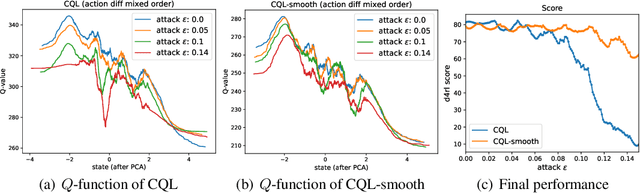
Offline reinforcement learning (RL) provides a promising direction to exploit the massive amount of offline data for complex decision-making tasks. Due to the distribution shift issue, current offline RL algorithms are generally designed to be conservative for value estimation and action selection. However, such conservatism impairs the robustness of learned policies, leading to a significant change even for a small perturbation on observations. To trade off robustness and conservatism, we propose Robust Offline Reinforcement Learning (RORL) with a novel conservative smoothing technique. In RORL, we explicitly introduce regularization on the policy and the value function for states near the dataset and additional conservative value estimation on these OOD states. Theoretically, we show RORL enjoys a tighter suboptimality bound than recent theoretical results in linear MDPs. We demonstrate that RORL can achieve the state-of-the-art performance on the general offline RL benchmark and is considerably robust to adversarial observation perturbation.
Latent-Variable Advantage-Weighted Policy Optimization for Offline RL
Mar 16, 2022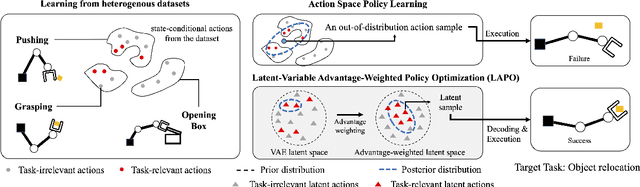
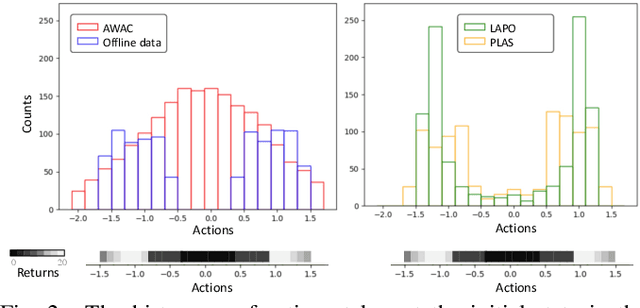

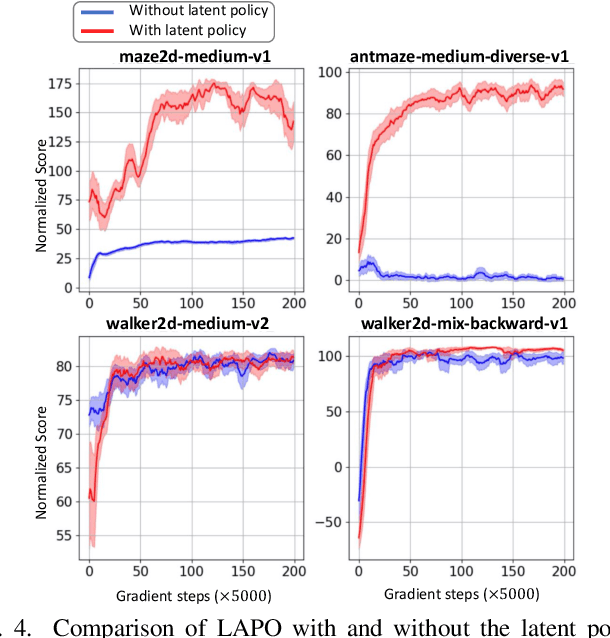
Offline reinforcement learning methods hold the promise of learning policies from pre-collected datasets without the need to query the environment for new transitions. This setting is particularly well-suited for continuous control robotic applications for which online data collection based on trial-and-error is costly and potentially unsafe. In practice, offline datasets are often heterogeneous, i.e., collected in a variety of scenarios, such as data from several human demonstrators or from policies that act with different purposes. Unfortunately, such datasets can exacerbate the distribution shift between the behavior policy underlying the data and the optimal policy to be learned, leading to poor performance. To address this challenge, we propose to leverage latent-variable policies that can represent a broader class of policy distributions, leading to better adherence to the training data distribution while maximizing reward via a policy over the latent variable. As we empirically show on a range of simulated locomotion, navigation, and manipulation tasks, our method referred to as latent-variable advantage-weighted policy optimization (LAPO), improves the average performance of the next best-performing offline reinforcement learning methods by 49% on heterogeneous datasets, and by 8% on datasets with narrow and biased distributions.
Multi-Agent Policy Transfer via Task Relationship Modeling
Mar 09, 2022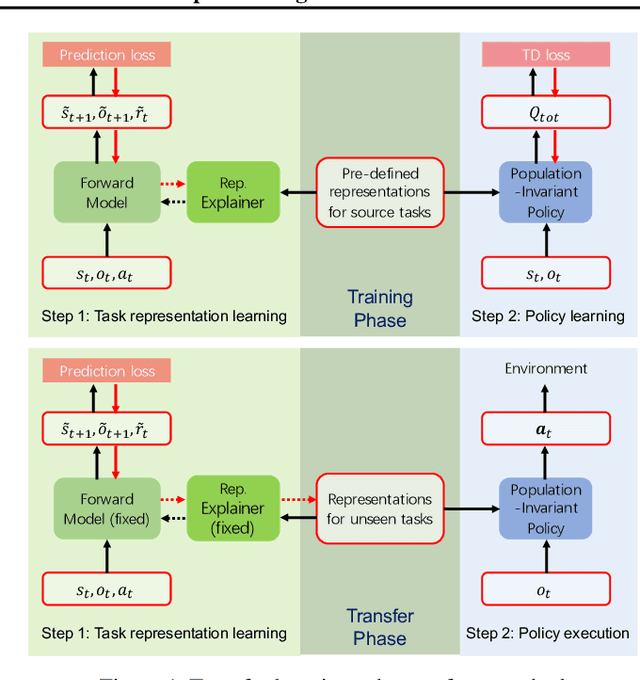
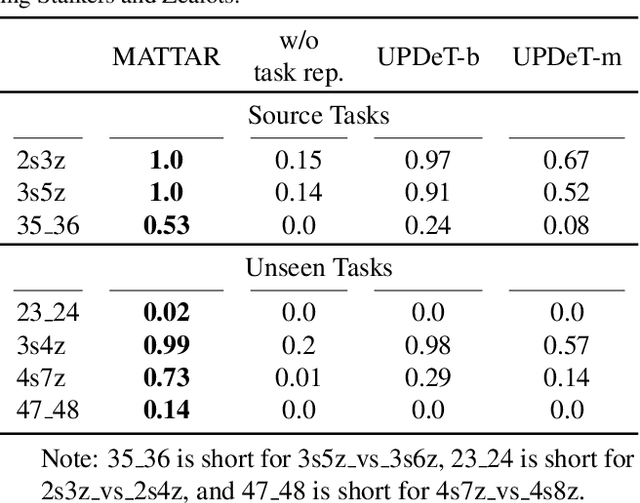
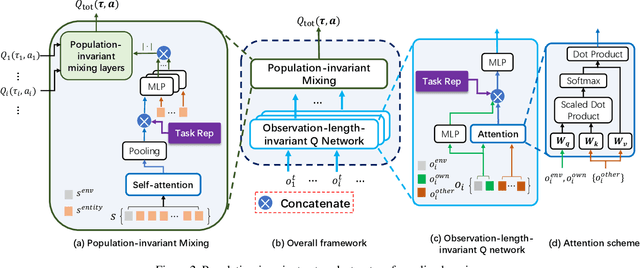
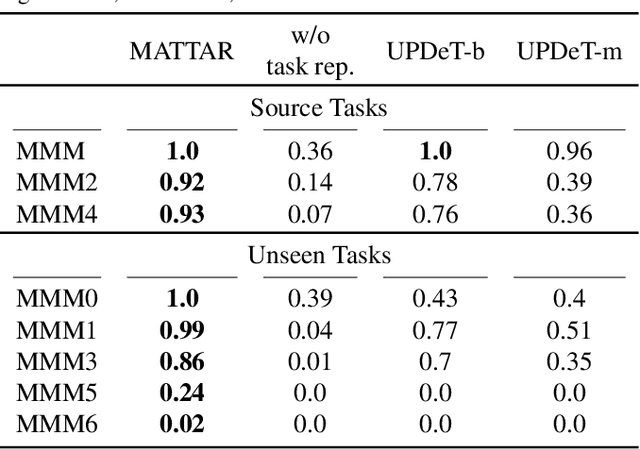
Team adaptation to new cooperative tasks is a hallmark of human intelligence, which has yet to be fully realized in learning agents. Previous work on multi-agent transfer learning accommodate teams of different sizes, heavily relying on the generalization ability of neural networks for adapting to unseen tasks. We believe that the relationship among tasks provides the key information for policy adaptation. In this paper, we try to discover and exploit common structures among tasks for more efficient transfer, and propose to learn effect-based task representations as a common space of tasks, using an alternatively fixed training scheme. We demonstrate that the task representation can capture the relationship among tasks, and can generalize to unseen tasks. As a result, the proposed method can help transfer learned cooperation knowledge to new tasks after training on a few source tasks. We also find that fine-tuning the transferred policies help solve tasks that are hard to learn from scratch.