 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation
Dec 15, 2022Human evaluation is the foundation upon which the evaluation of both summarization systems and automatic metrics rests. However, existing human evaluation protocols and benchmarks for summarization either exhibit low inter-annotator agreement or lack the scale needed to draw statistically significant conclusions, and an in-depth analysis of human evaluation is lacking. In this work, we address the shortcomings of existing summarization evaluation along the following axes: 1) We propose a modified summarization salience protocol, Atomic Content Units (ACUs), which relies on fine-grained semantic units and allows for high inter-annotator agreement. 2) We curate the Robust Summarization Evaluation (RoSE) benchmark, a large human evaluation dataset consisting of over 22k summary-level annotations over state-of-the-art systems on three datasets. 3) We compare our ACU protocol with three other human evaluation protocols, underscoring potential confounding factors in evaluation setups. 4) We evaluate existing automatic metrics using the collected human annotations across evaluation protocols and demonstrate how our benchmark leads to more statistically stable and significant results. Furthermore, our findings have important implications for evaluating large language models (LLMs), as we show that LLMs adjusted by human feedback (e.g., GPT-3.5) may overfit unconstrained human evaluation, which is affected by the annotators' prior, input-agnostic preferences, calling for more robust, targeted evaluation methods.
Improving Factual Consistency in Summarization with Compression-Based Post-Editing
Nov 11, 2022State-of-the-art summarization models still struggle to be factually consistent with the input text. A model-agnostic way to address this problem is post-editing the generated summaries. However, existing approaches typically fail to remove entity errors if a suitable input entity replacement is not available or may insert erroneous content. In our work, we focus on removing extrinsic entity errors, or entities not in the source, to improve consistency while retaining the summary's essential information and form. We propose to use sentence-compression data to train the post-editing model to take a summary with extrinsic entity errors marked with special tokens and output a compressed, well-formed summary with those errors removed. We show that this model improves factual consistency while maintaining ROUGE, improving entity precision by up to 30% on XSum, and that this model can be applied on top of another post-editor, improving entity precision by up to a total of 38%. We perform an extensive comparison of post-editing approaches that demonstrate trade-offs between factual consistency, informativeness, and grammaticality, and we analyze settings where post-editors show the largest improvements.
Discord Questions: A Computational Approach To Diversity Analysis in News Coverage
Nov 09, 2022



There are many potential benefits to news readers accessing diverse sources. Modern news aggregators do the hard work of organizing the news, offering readers a plethora of source options, but choosing which source to read remains challenging. We propose a new framework to assist readers in identifying source differences and gaining an understanding of news coverage diversity. The framework is based on the generation of Discord Questions: questions with a diverse answer pool, explicitly illustrating source differences. To assemble a prototype of the framework, we focus on two components: (1) discord question generation, the task of generating questions answered differently by sources, for which we propose an automatic scoring method, and create a model that improves performance from current question generation (QG) methods by 5%, (2) answer consolidation, the task of grouping answers to a question that are semantically similar, for which we collect data and repurpose a method that achieves 81% balanced accuracy on our realistic test set. We illustrate the framework's feasibility through a prototype interface. Even though model performance at discord QG still lags human performance by more than 15%, generated questions are judged to be more interesting than factoid questions and can reveal differences in the level of detail, sentiment, and reasoning of sources in news coverage.
Conformal Predictor for Improving Zero-shot Text Classification Efficiency
Oct 23, 2022



Pre-trained language models (PLMs) have been shown effective for zero-shot (0shot) text classification. 0shot models based on natural language inference (NLI) and next sentence prediction (NSP) employ cross-encoder architecture and infer by making a forward pass through the model for each label-text pair separately. This increases the computational cost to make inferences linearly in the number of labels. In this work, we improve the efficiency of such cross-encoder-based 0shot models by restricting the number of likely labels using another fast base classifier-based conformal predictor (CP) calibrated on samples labeled by the 0shot model. Since a CP generates prediction sets with coverage guarantees, it reduces the number of target labels without excluding the most probable label based on the 0shot model. We experiment with three intent and two topic classification datasets. With a suitable CP for each dataset, we reduce the average inference time for NLI- and NSP-based models by 25.6% and 22.2% respectively, without dropping performance below the predefined error rate of 1%.
Model ensemble instead of prompt fusion: a sample-specific knowledge transfer method for few-shot prompt tuning
Oct 23, 2022Prompt tuning approaches, which learn task-specific soft prompts for a downstream task conditioning on frozen pre-trained models, have attracted growing interest due to its parameter efficiency. With large language models and sufficient training data, prompt tuning performs comparably to full-model tuning. However, with limited training samples in few-shot settings, prompt tuning fails to match the performance of full-model fine-tuning. In this work, we focus on improving the few-shot performance of prompt tuning by transferring knowledge from soft prompts of source tasks. Recognizing the good generalization capabilities of ensemble methods in low-data regime, we first experiment and show that a simple ensemble of model predictions based on different source prompts, outperforms existing multi-prompt knowledge transfer approaches such as source prompt fusion in the few-shot setting. Motivated by this observation, we further investigate model ensembles and propose Sample-specific Ensemble of Source Models (SESoM). SESoM learns to adjust the contribution of each source model for each target sample separately when ensembling source model outputs. Through this way, SESoM inherits the superior generalization of model ensemble approaches and simultaneously captures the sample-specific competence of each source prompt. We conduct experiments across a diverse set of eight NLP tasks using models of different scales (T5-{base, large, XL}) and find that SESoM consistently outperforms the existing models of the same as well as larger parametric scale by a large margin.
Near-Negative Distinction: Giving a Second Life to Human Evaluation Datasets
May 13, 2022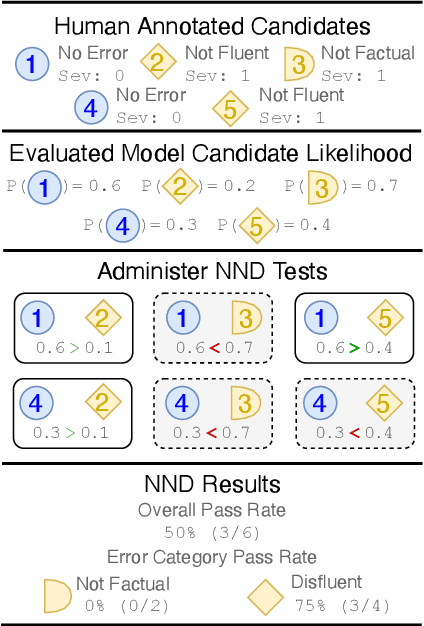
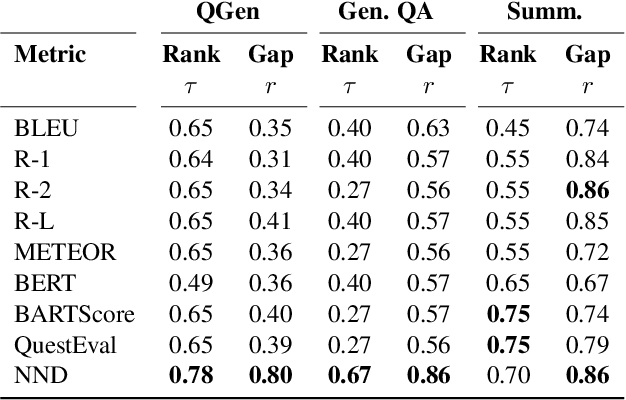
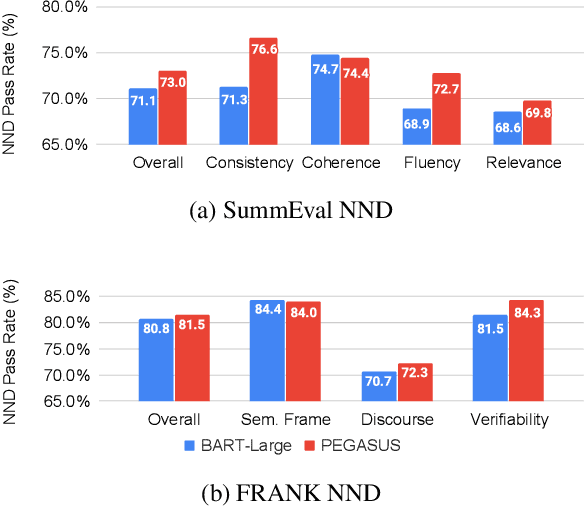
Precisely assessing the progress in natural language generation (NLG) tasks is challenging, and human evaluation to establish preference in a model's output over another is often necessary. However, human evaluation is usually costly, difficult to reproduce, and non-reusable. In this paper, we propose a new and simple automatic evaluation method for NLG called Near-Negative Distinction (NND) that repurposes prior human annotations into NND tests. In an NND test, an NLG model must place higher likelihood on a high-quality output candidate than on a near-negative candidate with a known error. Model performance is established by the number of NND tests a model passes, as well as the distribution over task-specific errors the model fails on. Through experiments on three NLG tasks (question generation, question answering, and summarization), we show that NND achieves higher correlation with human judgments than standard NLG evaluation metrics. We then illustrate NND evaluation in four practical scenarios, for example performing fine-grain model analysis, or studying model training dynamics. Our findings suggest NND can give a second life to human annotations and provide low-cost NLG evaluation.
Quiz Design Task: Helping Teachers Create Quizzes with Automated Question Generation
May 03, 2022
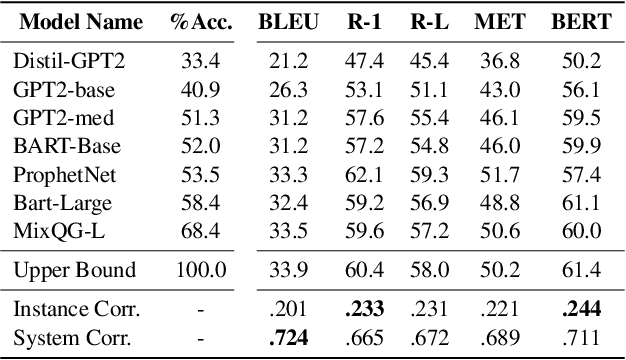
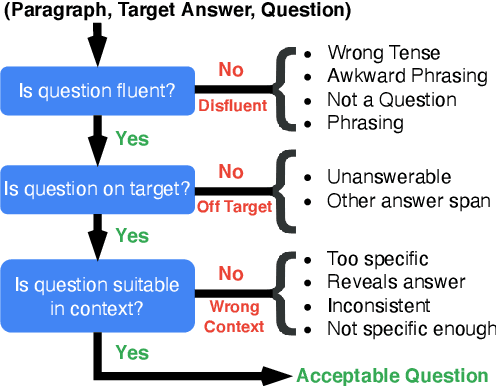
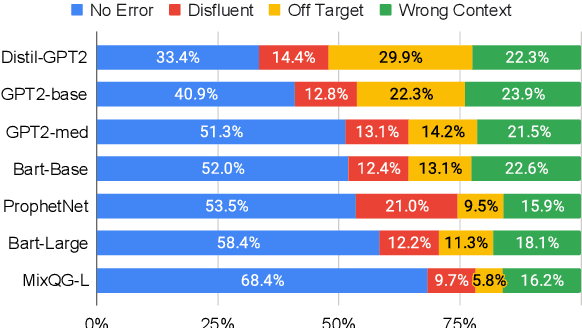
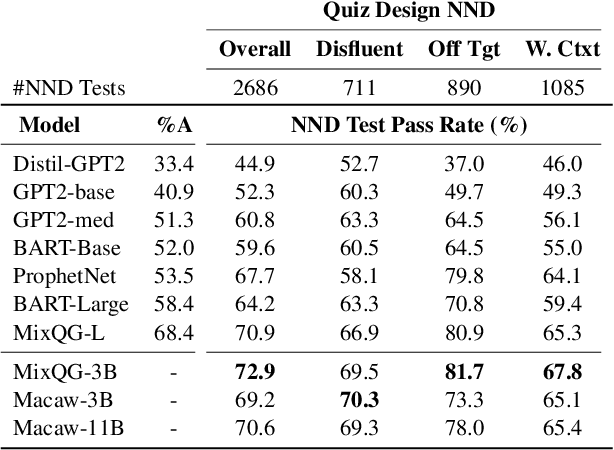
Question generation (QGen) models are often evaluated with standardized NLG metrics that are based on n-gram overlap. In this paper, we measure whether these metric improvements translate to gains in a practical setting, focusing on the use case of helping teachers automate the generation of reading comprehension quizzes. In our study, teachers building a quiz receive question suggestions, which they can either accept or refuse with a reason. Even though we find that recent progress in QGen leads to a significant increase in question acceptance rates, there is still large room for improvement, with the best model having only 68.4% of its questions accepted by the ten teachers who participated in our study. We then leverage the annotations we collected to analyze standard NLG metrics and find that model performance has reached projected upper-bounds, suggesting new automatic metrics are needed to guide QGen research forward.
Structure Extraction in Task-Oriented Dialogues with Slot Clustering
Mar 15, 2022
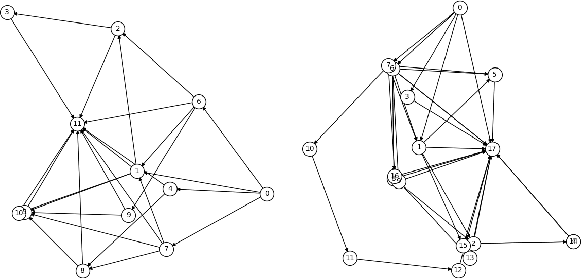


Extracting structure information from dialogue data can help us better understand user and system behaviors. In task-oriented dialogues, dialogue structure has often been considered as transition graphs among dialogue states. However, annotating dialogue states manually is expensive and time-consuming. In this paper, we propose a simple yet effective approach for structure extraction in task-oriented dialogues. We first detect and cluster possible slot tokens with a pre-trained model to approximate dialogue ontology for a target domain. Then we track the status of each identified token group and derive a state transition structure. Empirical results show that our approach outperforms unsupervised baseline models by far in dialogue structure extraction. In addition, we show that data augmentation based on extracted structures enriches the surface formats of training data and can achieve a significant performance boost in dialogue response generation.
UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
Jan 20, 2022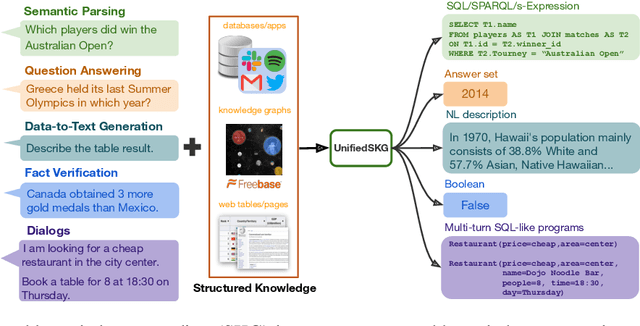
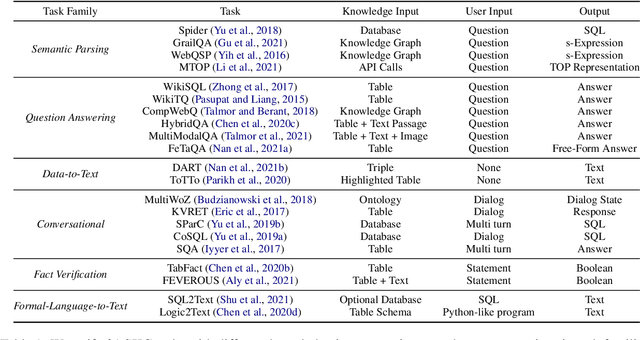
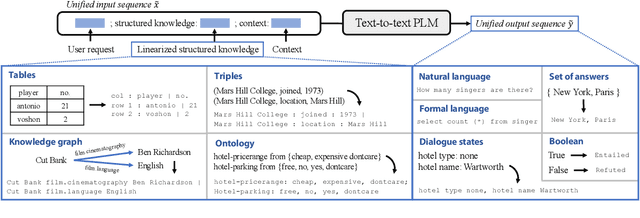
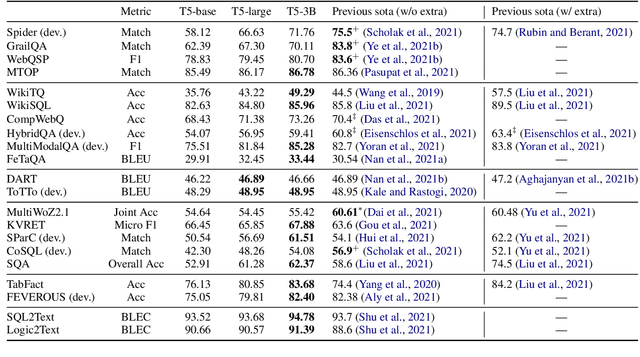
Structured knowledge grounding (SKG) leverages structured knowledge to complete user requests, such as semantic parsing over databases and question answering over knowledge bases. Since the inputs and outputs of SKG tasks are heterogeneous, they have been studied separately by different communities, which limits systematic and compatible research on SKG. In this paper, we overcome this limitation by proposing the SKG framework, which unifies 21 SKG tasks into a text-to-text format, aiming to promote systematic SKG research, instead of being exclusive to a single task, domain, or dataset. We use UnifiedSKG to benchmark T5 with different sizes and show that T5, with simple modifications when necessary, achieves state-of-the-art performance on almost all of the 21 tasks. We further demonstrate that multi-task prefix-tuning improves the performance on most tasks, largely improving the overall performance. UnifiedSKG also facilitates the investigation of zero-shot and few-shot learning, and we show that T0, GPT-3, and Codex struggle in zero-shot and few-shot learning for SKG. We also use UnifiedSKG to conduct a series of controlled experiments on structured knowledge encoding variants across SKG tasks. UnifiedSKG is easily extensible to more tasks, and it is open-sourced at https://github.com/hkunlp/unifiedskg Latest collections at https://unifiedskg.com.
QAFactEval: Improved QA-Based Factual Consistency Evaluation for Summarization
Dec 16, 2021
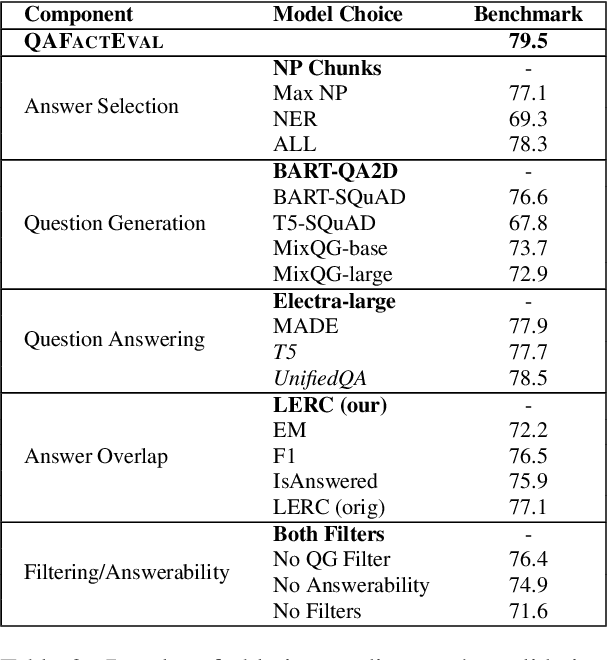
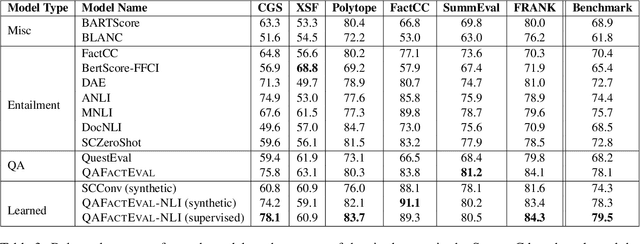

Factual consistency is an essential quality of text summarization models in practical settings. Existing work in evaluating this dimension can be broadly categorized into two lines of research, entailment-based metrics and question answering (QA)-based metrics. However, differing experimental setups presented in recent work lead to contrasting conclusions as to which paradigm performs best. In this work, we conduct an extensive comparison of entailment and QA-based metrics, demonstrating that carefully choosing the components of a QA-based metric is critical to performance. Building on those insights, we propose an optimized metric, which we call QAFactEval, that leads to a 15% average improvement over previous QA-based metrics on the SummaC factual consistency benchmark. Our solution improves upon the best-performing entailment-based metric and achieves state-of-the-art performance on this benchmark. Furthermore, we find that QA-based and entailment-based metrics offer complementary signals and combine the two into a single, learned metric for further performance boost. Through qualitative and quantitative analyses, we point to question generation and answerability classification as two critical components for future work in QA-based metrics.