 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMA: Simple yet Effective Learning for Multi-Turn Jailbreak Attacks
Feb 06, 2026Multi-turn jailbreaks capture the real threat model for safety-aligned chatbots, where single-turn attacks are merely a special case. Yet existing approaches break under exploration complexity and intent drift. We propose SEMA, a simple yet effective framework that trains a multi-turn attacker without relying on any existing strategies or external data. SEMA comprises two stages. Prefilling self-tuning enables usable rollouts by fine-tuning on non-refusal, well-structured, multi-turn adversarial prompts that are self-generated with a minimal prefix, thereby stabilizing subsequent learning. Reinforcement learning with intent-drift-aware reward trains the attacker to elicit valid multi-turn adversarial prompts while maintaining the same harmful objective. We anchor harmful intent in multi-turn jailbreaks via an intent-drift-aware reward that combines intent alignment, compliance risk, and level of detail. Our open-loop attack regime avoids dependence on victim feedback, unifies single- and multi-turn settings, and reduces exploration complexity. Across multiple datasets, victim models, and jailbreak judges, our method achieves state-of-the-art (SOTA) attack success rates (ASR), outperforming all single-turn baselines, manually scripted and template-driven multi-turn baselines, as well as our SFT (Supervised Fine-Tuning) and DPO (Direct Preference Optimization) variants. For instance, SEMA performs an average $80.1\%$ ASR@1 across three closed-source and open-source victim models on AdvBench, 33.9% over SOTA. The approach is compact, reproducible, and transfers across targets, providing a stronger and more realistic stress test for large language model (LLM) safety and enabling automatic redteaming to expose and localize failure modes. Our code is available at: https://github.com/fmmarkmq/SEMA.
Omni-Judge: Can Omni-LLMs Serve as Human-Aligned Judges for Text-Conditioned Audio-Video Generation?
Feb 02, 2026State-of-the-art text-to-video generation models such as Sora 2 and Veo 3 can now produce high-fidelity videos with synchronized audio directly from a textual prompt, marking a new milestone in multi-modal generation. However, evaluating such tri-modal outputs remains an unsolved challenge. Human evaluation is reliable but costly and difficult to scale, while traditional automatic metrics, such as FVD, CLAP, and ViCLIP, focus on isolated modality pairs, struggle with complex prompts, and provide limited interpretability. Omni-modal large language models (omni-LLMs) present a promising alternative: they naturally process audio, video, and text, support rich reasoning, and offer interpretable chain-of-thought feedback. Driven by this, we introduce Omni-Judge, a study assessing whether omni-LLMs can serve as human-aligned judges for text-conditioned audio-video generation. Across nine perceptual and alignment metrics, Omni-Judge achieves correlation comparable to traditional metrics and excels on semantically demanding tasks such as audio-text alignment, video-text alignment, and audio-video-text coherence. It underperforms on high-FPS perceptual metrics, including video quality and audio-video synchronization, due to limited temporal resolution. Omni-Judge provides interpretable explanations that expose semantic or physical inconsistencies, enabling practical downstream uses such as feedback-based refinement. Our findings highlight both the potential and current limitations of omni-LLMs as unified evaluators for multi-modal generation.
Statistical Estimation of Adversarial Risk in Large Language Models under Best-of-N Sampling
Jan 30, 2026Large Language Models (LLMs) are typically evaluated for safety under single-shot or low-budget adversarial prompting, which underestimates real-world risk. In practice, attackers can exploit large-scale parallel sampling to repeatedly probe a model until a harmful response is produced. While recent work shows that attack success increases with repeated sampling, principled methods for predicting large-scale adversarial risk remain limited. We propose a scaling-aware Best-of-N estimation of risk, SABER, for modeling jailbreak vulnerability under Best-of-N sampling. We model sample-level success probabilities using a Beta distribution, the conjugate prior of the Bernoulli distribution, and derive an analytic scaling law that enables reliable extrapolation of large-N attack success rates from small-budget measurements. Using only n=100 samples, our anchored estimator predicts ASR@1000 with a mean absolute error of 1.66, compared to 12.04 for the baseline, which is an 86.2% reduction in estimation error. Our results reveal heterogeneous risk scaling profiles and show that models appearing robust under standard evaluation can experience rapid nonlinear risk amplification under parallel adversarial pressure. This work provides a low-cost, scalable methodology for realistic LLM safety assessment. We will release our code and evaluation scripts upon publication to future research.
Semantic visually-guided acoustic highlighting with large vision-language models
Jan 12, 2026Balancing dialogue, music, and sound effects with accompanying video is crucial for immersive storytelling, yet current audio mixing workflows remain largely manual and labor-intensive. While recent advancements have introduced the visually guided acoustic highlighting task, which implicitly rebalances audio sources using multimodal guidance, it remains unclear which visual aspects are most effective as conditioning signals.We address this gap through a systematic study of whether deep video understanding improves audio remixing. Using textual descriptions as a proxy for visual analysis, we prompt large vision-language models to extract six types of visual-semantic aspects, including object and character appearance, emotion, camera focus, tone, scene background, and inferred sound-related cues. Through extensive experiments, camera focus, tone, and scene background consistently yield the largest improvements in perceptual mix quality over state-of-the-art baselines. Our findings (i) identify which visual-semantic cues most strongly support coherent and visually aligned audio remixing, and (ii) outline a practical path toward automating cinema-grade sound design using lightweight guidance derived from large vision-language models.
When to Think and When to Look: Uncertainty-Guided Lookback
Nov 19, 2025



Test-time thinking (that is, generating explicit intermediate reasoning chains) is known to boost performance in large language models and has recently shown strong gains for large vision language models (LVLMs). However, despite these promising results, there is still no systematic analysis of how thinking actually affects visual reasoning. We provide the first such analysis with a large scale, controlled comparison of thinking for LVLMs, evaluating ten variants from the InternVL3.5 and Qwen3-VL families on MMMU-val under generous token budgets and multi pass decoding. We show that more thinking is not always better; long chains often yield long wrong trajectories that ignore the image and underperform the same models run in standard instruct mode. A deeper analysis reveals that certain short lookback phrases, which explicitly refer back to the image, are strongly enriched in successful trajectories and correlate with better visual grounding. Building on this insight, we propose uncertainty guided lookback, a training free decoding strategy that combines an uncertainty signal with adaptive lookback prompts and breadth search. Our method improves overall MMMU performance, delivers the largest gains in categories where standard thinking is weak, and outperforms several strong decoding baselines, setting a new state of the art under fixed model families and token budgets. We further show that this decoding strategy generalizes, yielding consistent improvements on five additional benchmarks, including two broad multimodal suites and math focused visual reasoning datasets.
PromptReverb: Multimodal Room Impulse Response Generation Through Latent Rectified Flow Matching
Oct 25, 2025Room impulse response (RIR) generation remains a critical challenge for creating immersive virtual acoustic environments. Current methods suffer from two fundamental limitations: the scarcity of full-band RIR datasets and the inability of existing models to generate acoustically accurate responses from diverse input modalities. We present PromptReverb, a two-stage generative framework that addresses these challenges. Our approach combines a variational autoencoder that upsamples band-limited RIRs to full-band quality (48 kHz), and a conditional diffusion transformer model based on rectified flow matching that generates RIRs from descriptions in natural language. Empirical evaluation demonstrates that PromptReverb produces RIRs with superior perceptual quality and acoustic accuracy compared to existing methods, achieving 8.8% mean RT60 error compared to -37% for widely used baselines and yielding more realistic room-acoustic parameters. Our method enables practical applications in virtual reality, architectural acoustics, and audio production where flexible, high-quality RIR synthesis is essential.
Diagnosing Visual Reasoning: Challenges, Insights, and a Path Forward
Oct 23, 2025Multimodal large language models (MLLMs) that integrate visual and textual reasoning leverage chain-of-thought (CoT) prompting to tackle complex visual tasks, yet continue to exhibit visual hallucinations and an over-reliance on textual priors. We present a systematic diagnosis of state-of-the-art vision-language models using a three-stage evaluation framework, uncovering key failure modes. To address these, we propose an agent-based architecture that combines LLM reasoning with lightweight visual modules, enabling fine-grained analysis and iterative refinement of reasoning chains. Our results highlight future visual reasoning models should focus on integrating a broader set of specialized tools for analyzing visual content. Our system achieves significant gains (+10.3 on MMMU, +6.0 on MathVista over a 7B baseline), matching or surpassing much larger models. We will release our framework and evaluation suite to facilitate future research.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025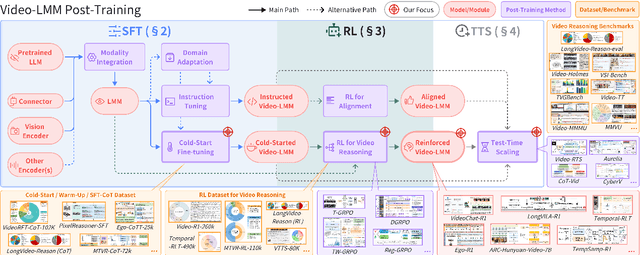
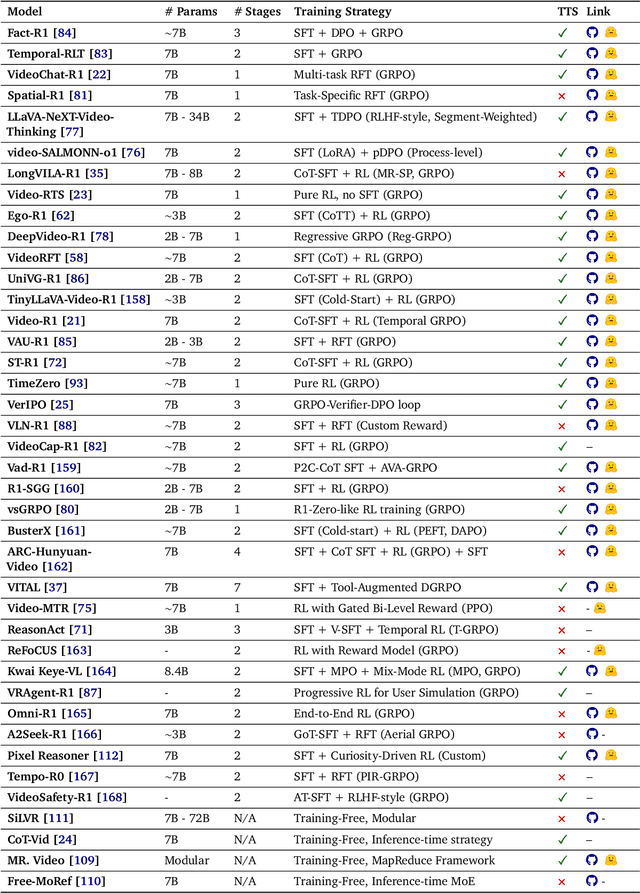
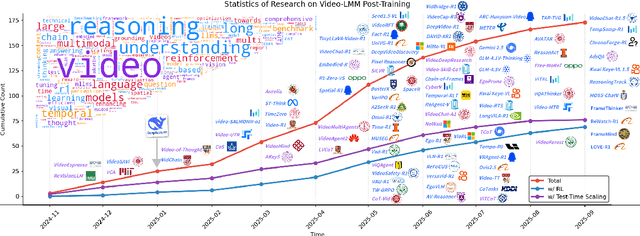
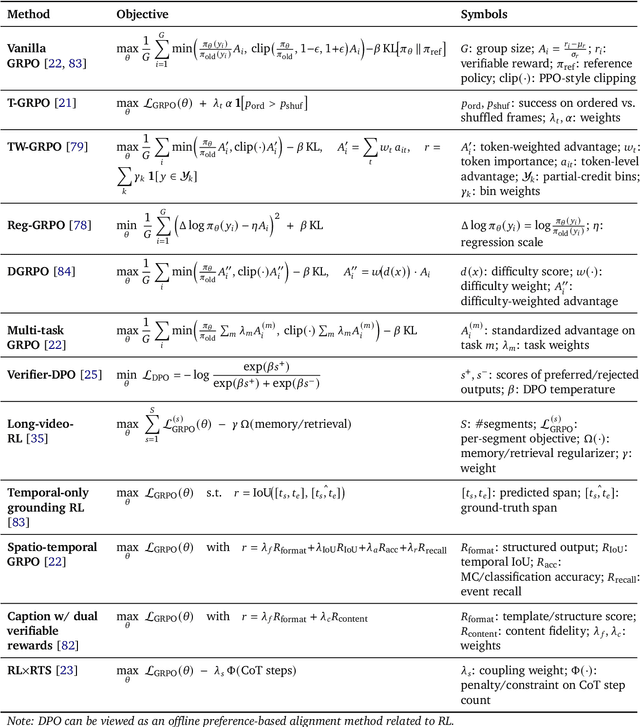
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025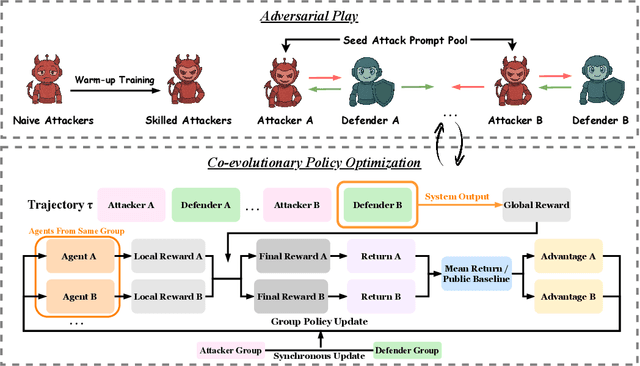

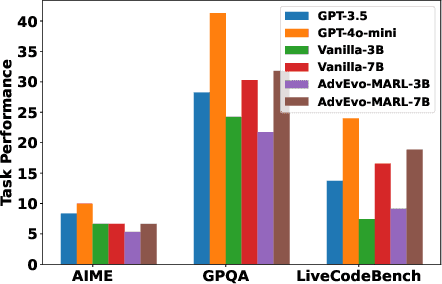
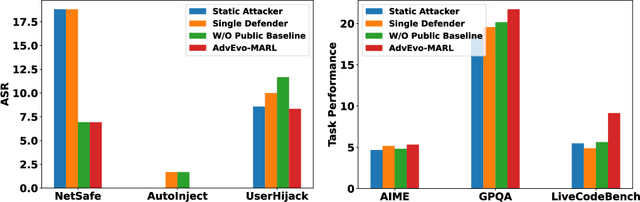
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
High-Quality Sound Separation Across Diverse Categories via Visually-Guided Generative Modeling
Sep 26, 2025We propose DAVIS, a Diffusion-based Audio-VIsual Separation framework that solves the audio-visual sound source separation task through generative learning. Existing methods typically frame sound separation as a mask-based regression problem, achieving significant progress. However, they face limitations in capturing the complex data distribution required for high-quality separation of sounds from diverse categories. In contrast, DAVIS circumvents these issues by leveraging potent generative modeling paradigms, specifically Denoising Diffusion Probabilistic Models (DDPM) and the more recent Flow Matching (FM), integrated within a specialized Separation U-Net architecture. Our framework operates by synthesizing the desired separated sound spectrograms directly from a noise distribution, conditioned concurrently on the mixed audio input and associated visual information. The inherent nature of its generative objective makes DAVIS particularly adept at producing high-quality sound separations for diverse sound categories. We present comparative evaluations of DAVIS, encompassing both its DDPM and Flow Matching variants, against leading methods on the standard AVE and MUSIC datasets. The results affirm that both variants surpass existing approaches in separation quality, highlighting the efficacy of our generative framework for tackling the audio-visual source separation task.