 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Information Interaction Framework for Incomplete Utterance Rewriting
Dec 19, 2023Recent approaches in Incomplete Utterance Rewriting (IUR) fail to capture the source of important words, which is crucial to edit the incomplete utterance, and introduce words from irrelevant utterances. We propose a novel and effective multi-task information interaction framework including context selection, edit matrix construction, and relevance merging to capture the multi-granularity of semantic information. Benefiting from fetching the relevant utterance and figuring out the important words, our approach outperforms existing state-of-the-art models on two benchmark datasets Restoration-200K and CANAND in this field. Code will be provided on \url{https://github.com/yanmenxue/QR}.
External Knowledge Augmented Polyphone Disambiguation Using Large Language Model
Dec 19, 2023One of the key issues in Mandarin Chinese text-to-speech (TTS) systems is polyphone disambiguation when doing grapheme-to-phoneme (G2P) conversion. In this paper, we introduce a novel method to solve the problem as a generation task. Following the trending research of large language models (LLM) and prompt learning, the proposed method consists of three modules. Retrieval module incorporates external knowledge which is a multi-level semantic dictionary of Chinese polyphonic characters to format the sentence into a prompt. Generation module adopts the decoder-only Transformer architecture to induce the target text. Postprocess module corrects the generated text into a valid result if needed. Experimental results show that our method outperforms the existing methods on a public dataset called CPP. We also empirically study the impacts of different templates of the prompt, different sizes of training data, and whether to incorporate external knowledge.
Relation-Aware Question Answering for Heterogeneous Knowledge Graphs
Dec 19, 2023Multi-hop Knowledge Base Question Answering(KBQA) aims to find the answer entity in a knowledge graph (KG), which requires multiple steps of reasoning. Existing retrieval-based approaches solve this task by concentrating on the specific relation at different hops and predicting the intermediate entity within the reasoning path. During the reasoning process of these methods, the representation of relations are fixed but the initial relation representation may not be optimal. We claim they fail to utilize information from head-tail entities and the semantic connection between relations to enhance the current relation representation, which undermines the ability to capture information of relations in KGs. To address this issue, we construct a \textbf{dual relation graph} where each node denotes a relation in the original KG (\textbf{primal entity graph}) and edges are constructed between relations sharing same head or tail entities. Then we iteratively do primal entity graph reasoning, dual relation graph information propagation, and interaction between these two graphs. In this way, the interaction between entity and relation is enhanced, and we derive better entity and relation representations. Experiments on two public datasets, WebQSP and CWQ, show that our approach achieves a significant performance gain over the prior state-of-the-art. Our code is available on \url{https://github.com/yanmenxue/RAH-KBQA}.
How to Determine the Most Powerful Pre-trained Language Model without Brute Force Fine-tuning? An Empirical Survey
Dec 08, 2023



Transferability estimation has been attached to great attention in the computer vision fields. Researchers try to estimate with low computational cost the performance of a model when transferred from a source task to a given target task. Considering the effectiveness of such estimations, the communities of natural language processing also began to study similar problems for the selection of pre-trained language models. However, there is a lack of a comprehensive comparison between these estimation methods yet. Also, the differences between vision and language scenarios make it doubtful whether previous conclusions can be established across fields. In this paper, we first conduct a thorough survey of existing transferability estimation methods being able to find the most suitable model, then we conduct a detailed empirical study for the surveyed methods based on the GLUE benchmark. From qualitative and quantitative analyses, we demonstrate the strengths and weaknesses of existing methods and show that H-Score generally performs well with superiorities in effectiveness and efficiency. We also outline the difficulties of consideration of training details, applicability to text generation, and consistency to certain metrics which shed light on future directions.
Noise Adaptor in Spiking Neural Networks
Dec 08, 2023Recent strides in low-latency spiking neural network (SNN) algorithms have drawn significant interest, particularly due to their event-driven computing nature and fast inference capability. One of the most efficient ways to construct a low-latency SNN is by converting a pre-trained, low-bit artificial neural network (ANN) into an SNN. However, this conversion process faces two main challenges: First, converting SNNs from low-bit ANNs can lead to ``occasional noise" -- the phenomenon where occasional spikes are generated in spiking neurons where they should not be -- during inference, which significantly lowers SNN accuracy. Second, although low-latency SNNs initially show fast improvements in accuracy with time steps, these accuracy growths soon plateau, resulting in their peak accuracy lagging behind both full-precision ANNs and traditional ``long-latency SNNs'' that prioritize precision over speed. In response to these two challenges, this paper introduces a novel technique named ``noise adaptor.'' Noise adaptor can model occasional noise during training and implicitly optimize SNN accuracy, particularly at high simulation times $T$. Our research utilizes the ResNet model for a comprehensive analysis of the impact of the noise adaptor on low-latency SNNs. The results demonstrate that our method outperforms the previously reported quant-ANN-to-SNN conversion technique. We achieved an accuracy of 95.95\% within 4 time steps on CIFAR-10 using ResNet-18, and an accuracy of 74.37\% within 64 time steps on ImageNet using ResNet-50. Remarkably, these results were obtained without resorting to any noise correction methods during SNN inference, such as negative spikes or two-stage SNN simulations. Our approach significantly boosts the peak accuracy of low-latency SNNs, bringing them on par with the accuracy of full-precision ANNs. Code will be open source.
NeuSG: Neural Implicit Surface Reconstruction with 3D Gaussian Splatting Guidance
Dec 01, 2023



Existing neural implicit surface reconstruction methods have achieved impressive performance in multi-view 3D reconstruction by leveraging explicit geometry priors such as depth maps or point clouds as regularization. However, the reconstruction results still lack fine details because of the over-smoothed depth map or sparse point cloud. In this work, we propose a neural implicit surface reconstruction pipeline with guidance from 3D Gaussian Splatting to recover highly detailed surfaces. The advantage of 3D Gaussian Splatting is that it can generate dense point clouds with detailed structure. Nonetheless, a naive adoption of 3D Gaussian Splatting can fail since the generated points are the centers of 3D Gaussians that do not necessarily lie on the surface. We thus introduce a scale regularizer to pull the centers close to the surface by enforcing the 3D Gaussians to be extremely thin. Moreover, we propose to refine the point cloud from 3D Gaussians Splatting with the normal priors from the surface predicted by neural implicit models instead of using a fixed set of points as guidance. Consequently, the quality of surface reconstruction improves from the guidance of the more accurate 3D Gaussian splatting. By jointly optimizing the 3D Gaussian Splatting and the neural implicit model, our approach benefits from both representations and generates complete surfaces with intricate details. Experiments on Tanks and Temples verify the effectiveness of our proposed method.
Vision-Language Instruction Tuning: A Review and Analysis
Nov 25, 2023
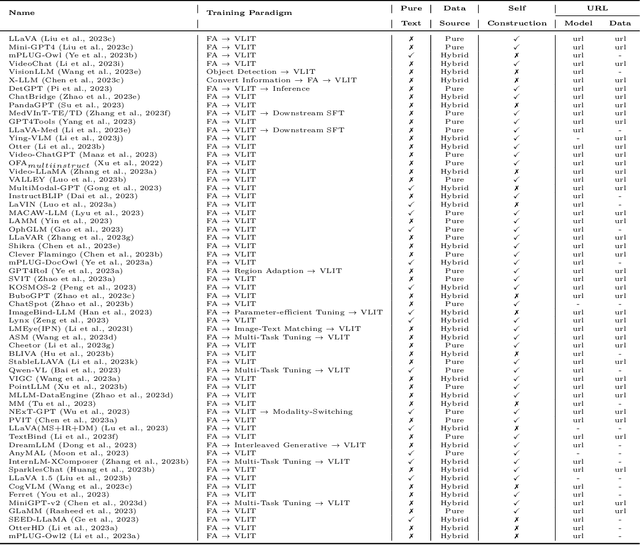

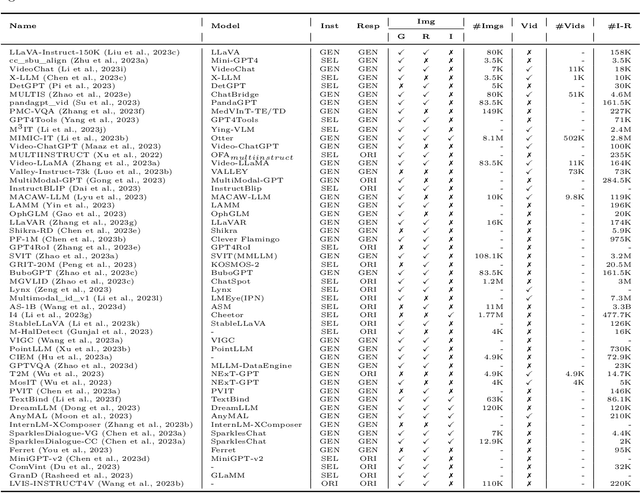
Instruction tuning is a crucial supervised training phase in Large Language Models (LLMs), aiming to enhance the LLM's ability to generalize instruction execution and adapt to user preferences. With the increasing integration of multi-modal data into LLMs, there is growing interest in Vision-Language Instruction Tuning (VLIT), which presents more complex characteristics compared to pure text instruction tuning. In this paper, we systematically review the latest VLIT settings and corresponding datasets in multi-modal LLMs and provide insights into the intrinsic motivations behind their design. For the first time, we offer a detailed multi-perspective categorization for existing VLIT datasets and identify the characteristics that high-quality VLIT data should possess. By incorporating these characteristics as guiding principles into the existing VLIT data construction process, we conduct extensive experiments and verify their positive impact on the performance of tuned multi-modal LLMs. Furthermore, we discuss the current challenges and future research directions of VLIT, providing insights for the continuous development of this field. The code and dataset related to this paper have been open-sourced at https://github.com/palchenli/VL-Instruction-Tuning.
Optimal Power Flow in Highly Renewable Power System Based on Attention Neural Networks
Nov 23, 2023The Optimal Power Flow (OPF) problem is pivotal for power system operations, guiding generator output and power distribution to meet demand at minimized costs, while adhering to physical and engineering constraints. The integration of renewable energy sources, like wind and solar, however, poses challenges due to their inherent variability. This variability, driven largely by changing weather conditions, demands frequent recalibrations of power settings, thus necessitating recurrent OPF resolutions. This task is daunting using traditional numerical methods, particularly for extensive power systems. In this work, we present a cutting-edge, physics-informed machine learning methodology, trained using imitation learning and historical European weather datasets. Our approach directly correlates electricity demand and weather patterns with power dispatch and generation, circumventing the iterative requirements of traditional OPF solvers. This offers a more expedient solution apt for real-time applications. Rigorous evaluations on aggregated European power systems validate our method's superiority over existing data-driven techniques in OPF solving. By presenting a quick, robust, and efficient solution, this research sets a new standard in real-time OPF resolution, paving the way for more resilient power systems in the era of renewable energy.
Formulating Discrete Probability Flow Through Optimal Transport
Nov 07, 2023



Continuous diffusion models are commonly acknowledged to display a deterministic probability flow, whereas discrete diffusion models do not. In this paper, we aim to establish the fundamental theory for the probability flow of discrete diffusion models. Specifically, we first prove that the continuous probability flow is the Monge optimal transport map under certain conditions, and also present an equivalent evidence for discrete cases. In view of these findings, we are then able to define the discrete probability flow in line with the principles of optimal transport. Finally, drawing upon our newly established definitions, we propose a novel sampling method that surpasses previous discrete diffusion models in its ability to generate more certain outcomes. Extensive experiments on the synthetic toy dataset and the CIFAR-10 dataset have validated the effectiveness of our proposed discrete probability flow. Code is released at: https://github.com/PangzeCheung/Discrete-Probability-Flow.
FP8-LM: Training FP8 Large Language Models
Oct 27, 2023



In this paper, we explore FP8 low-bit data formats for efficient training of large language models (LLMs). Our key insight is that most variables, such as gradients and optimizer states, in LLM training can employ low-precision data formats without compromising model accuracy and requiring no changes to hyper-parameters. Specifically, we propose a new FP8 automatic mixed-precision framework for training LLMs. This framework offers three levels of FP8 utilization to streamline mixed-precision and distributed parallel training for LLMs. It gradually incorporates 8-bit gradients, optimizer states, and distributed learning in an incremental manner. Experiment results show that, during the training of GPT-175B model on H100 GPU platform, our FP8 mixed-precision training framework not only achieved a remarkable 42% reduction in real memory usage but also ran 64% faster than the widely adopted BF16 framework (i.e., Megatron-LM), surpassing the speed of Nvidia Transformer Engine by 17%. This largely reduces the training costs for large foundation models. Furthermore, our FP8 mixed-precision training methodology is generic. It can be seamlessly applied to other tasks such as LLM instruction tuning and reinforcement learning with human feedback, offering savings in fine-tuning expenses. Our FP8 low-precision training framework is open-sourced at {https://github.com/Azure/MS-AMP}{aka.ms/MS.AMP}.