 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNDGGNET-A Node Independent Gate based Graph Neural Networks
May 11, 2022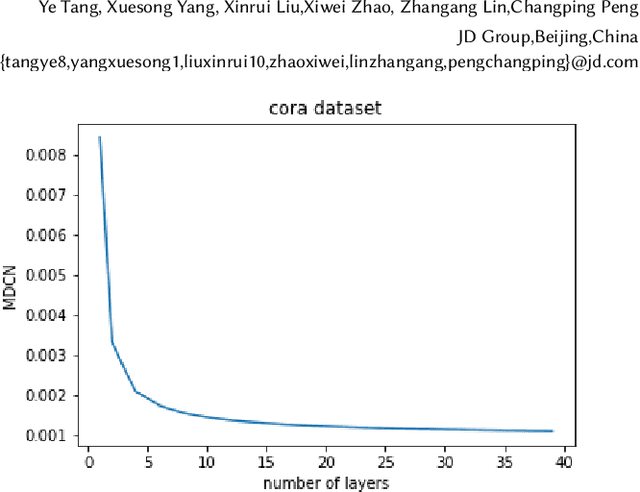
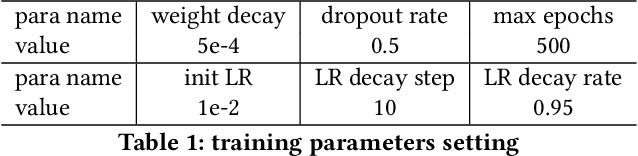
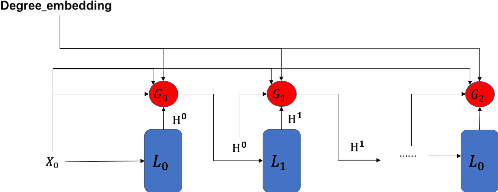
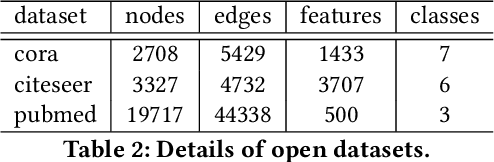
Graph Neural Networks (GNNs) is an architecture for structural data, and has been adopted in a mass of tasks and achieved fabulous results, such as link prediction, node classification, graph classification and so on. Generally, for a certain node in a given graph, a traditional GNN layer can be regarded as an aggregation from one-hop neighbors, thus a set of stacked layers are able to fetch and update node status within multi-hops. For nodes with sparse connectivity, it is difficult to obtain enough information through a single GNN layer as not only there are only few nodes directly connected to them but also can not propagate the high-order neighbor information. However, as the number of layer increases, the GNN model is prone to over-smooth for nodes with the dense connectivity, which resulting in the decrease of accuracy. To tackle this issue, in this thesis, we define a novel framework that allows the normal GNN model to accommodate more layers. Specifically, a node-degree based gate is employed to adjust weight of layers dynamically, that try to enhance the information aggregation ability and reduce the probability of over-smoothing. Experimental results show that our proposed model can effectively increase the model depth and perform well on several datasets.
Gating-adapted Wavelet Multiresolution Analysis for Exposure Sequence Modeling in CTR prediction
Apr 29, 2022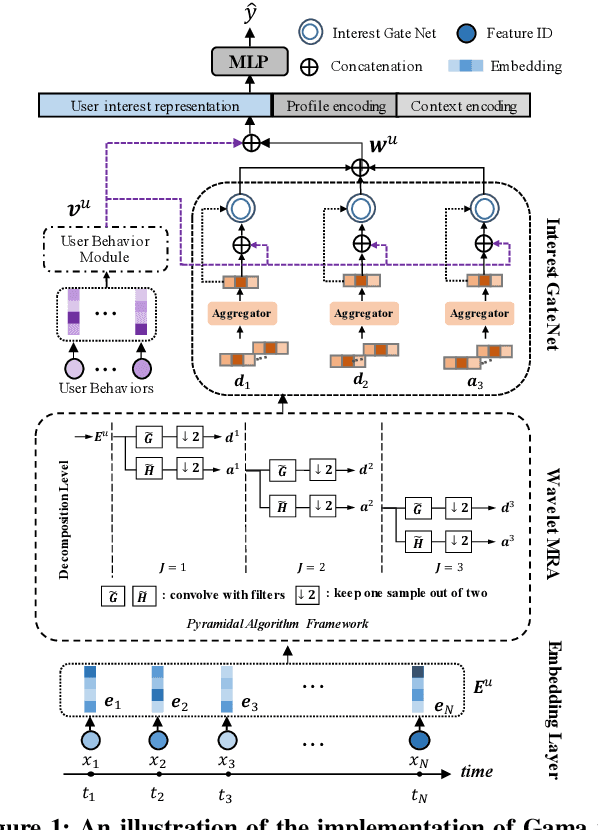

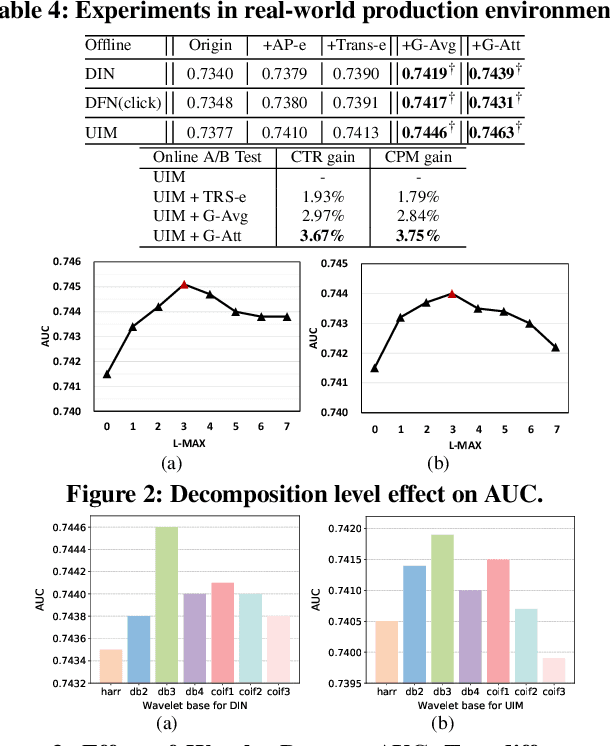
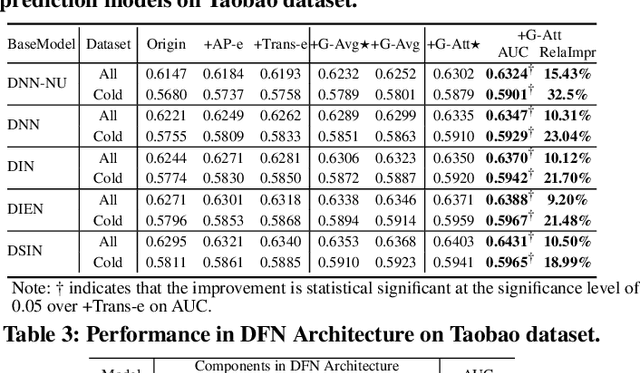
The exposure sequence is being actively studied for user interest modeling in Click-Through Rate (CTR) prediction. However, the existing methods for exposure sequence modeling bring extensive computational burden and neglect noise problems, resulting in an excessively latency and the limited performance in online recommenders. In this paper, we propose to address the high latency and noise problems via Gating-adapted wavelet multiresolution analysis (Gama), which can effectively denoise the extremely long exposure sequence and adaptively capture the implied multi-dimension user interest with linear computational complexity. This is the first attempt to integrate non-parametric multiresolution analysis technique into deep neural networks to model user exposure sequence. Extensive experiments on large scale benchmark dataset and real production dataset confirm the effectiveness of Gama for exposure sequence modeling, especially in cold-start scenarios. Benefited from its low latency and high effecitveness, Gama has been deployed in our real large-scale industrial recommender, successfully serving over hundreds of millions users.
IA-GCN: Interactive Graph Convolutional Network for Recommendation
Apr 08, 2022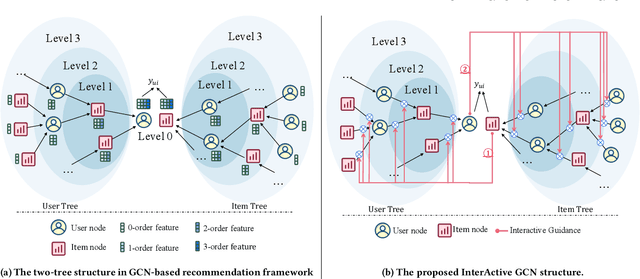

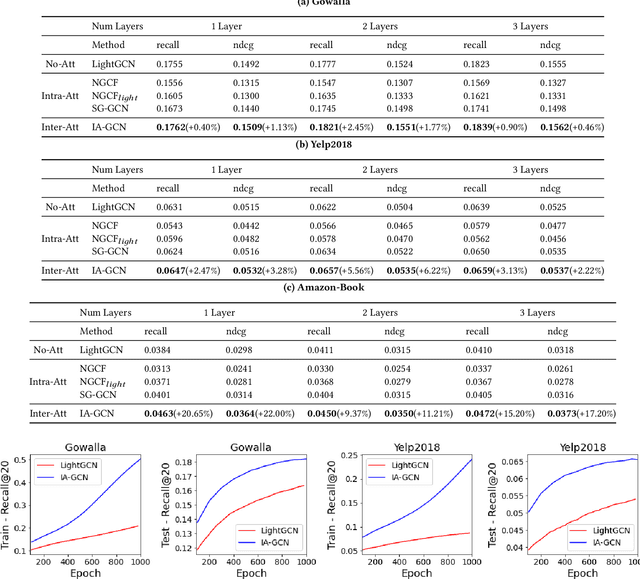
Recently, Graph Convolutional Network (GCN) has become a novel state-of-art for Collaborative Filtering (CF) based Recommender Systems (RS). It is a common practice to learn informative user and item representations by performing embedding propagation on a user-item bipartite graph, and then provide the users with personalized item suggestions based on the representations. Despite effectiveness, existing algorithms neglect precious interactive features between user-item pairs in the embedding process. When predicting a user's preference for different items, they still aggregate the user tree in the same way, without emphasizing target-related information in the user neighborhood. Such a uniform aggregation scheme easily leads to suboptimal user and item representations, limiting the model expressiveness to some extent. In this work, we address this problem by building bilateral interactive guidance between each user-item pair and proposing a new model named IA-GCN (short for InterActive GCN). Specifically, when learning the user representation from its neighborhood, we assign higher attention weights to those neighbors similar to the target item. Correspondingly, when learning the item representation, we pay more attention to those neighbors resembling the target user. This leads to interactive and interpretable features, effectively distilling target-specific information through each graph convolutional operation. Our model is built on top of LightGCN, a state-of-the-art GCN model for CF, and can be combined with various GCN-based CF architectures in an end-to-end fashion. Extensive experiments on three benchmark datasets demonstrate the effectiveness and robustness of IA-GCN.
Rethinking Position Bias Modeling with Knowledge Distillation for CTR Prediction
Apr 01, 2022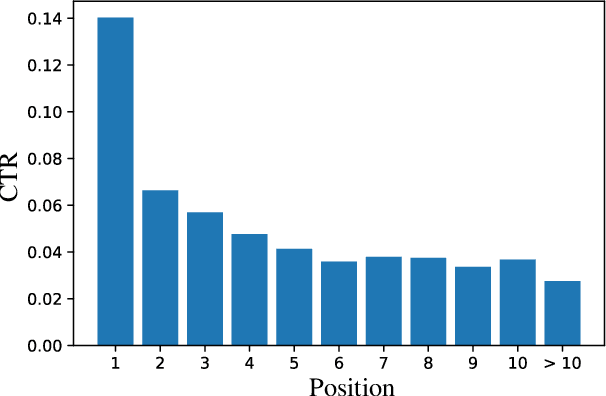
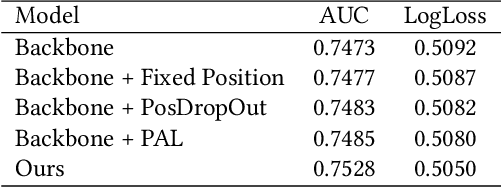
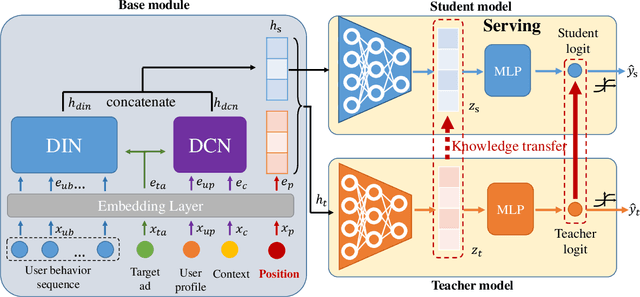
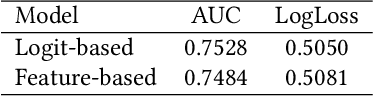
Click-through rate (CTR) Prediction is of great importance in real-world online ads systems. One challenge for the CTR prediction task is to capture the real interest of users from their clicked items, which is inherently biased by presented positions of items, i.e., more front positions tend to obtain higher CTR values. A popular line of existing works focuses on explicitly estimating position bias by result randomization which is expensive and inefficient, or by inverse propensity weighting (IPW) which relies heavily on the quality of the propensity estimation. Another common solution is modeling position as features during offline training and simply adopting fixed value or dropout tricks when serving. However, training-inference inconsistency can lead to sub-optimal performance. Furthermore, post-click information such as position values is informative while less exploited in CTR prediction. This work proposes a simple yet efficient knowledge distillation framework to alleviate the impact of position bias and leverage position information to improve CTR prediction. We demonstrate the performance of our proposed method on a real-world production dataset and online A/B tests, achieving significant improvements over competing baseline models. The proposed method has been deployed in the real world online ads systems, serving main traffic on one of the world's largest e-commercial platforms.
Concept Drift Adaptation for CTR Prediction in Online Advertising Systems
Apr 01, 2022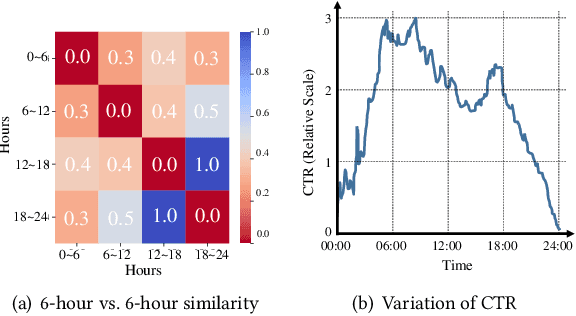
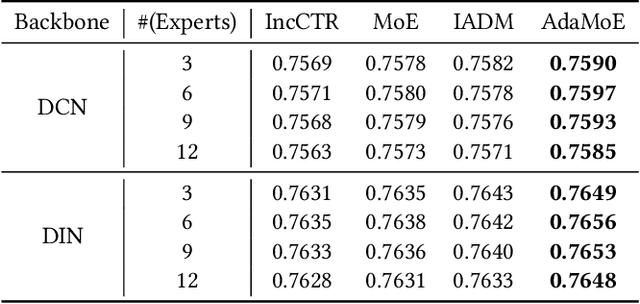
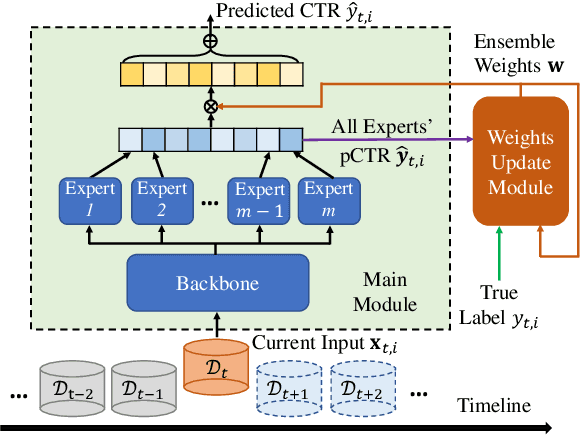
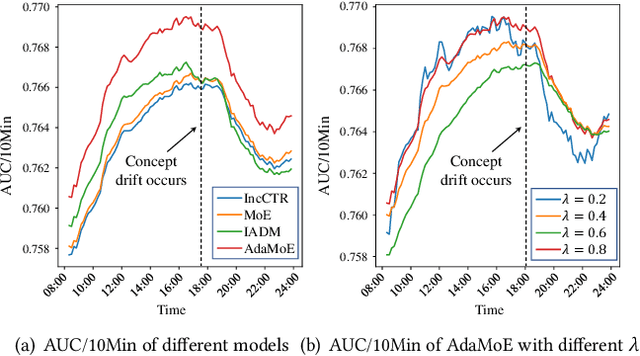
Click-through rate (CTR) prediction is a crucial task in web search, recommender systems, and online advertisement displaying. In practical application, CTR models often serve with high-speed user-generated data streams, whose underlying distribution rapidly changing over time. The concept drift problem inevitably exists in those streaming data, which can lead to performance degradation due to the timeliness issue. To ensure model freshness, incremental learning has been widely adopted in real-world production systems. However, it is hard for the incremental update to achieve the balance of the CTR models between the adaptability to capture the fast-changing trends and generalization ability to retain common knowledge. In this paper, we propose adaptive mixture of experts (AdaMoE), a new framework to alleviate the concept drift problem by adaptive filtering in the data stream of CTR prediction. The extensive experiments on the offline industrial dataset and online A/B tests show that our AdaMoE significantly outperforms all incremental learning frameworks considered.
Alleviating Cold-start Problem in CTR Prediction with A Variational Embedding Learning Framework
Jan 17, 2022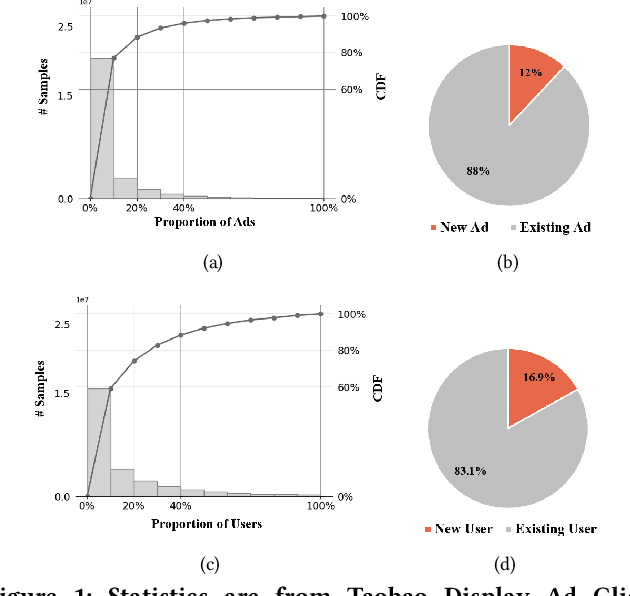

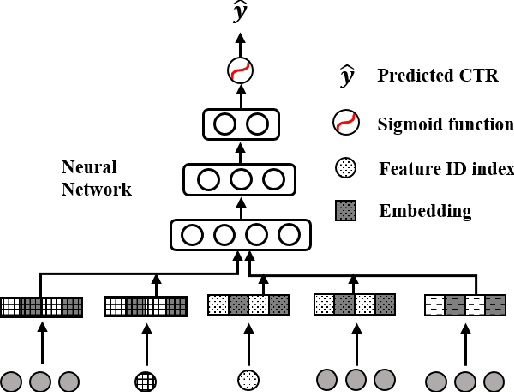
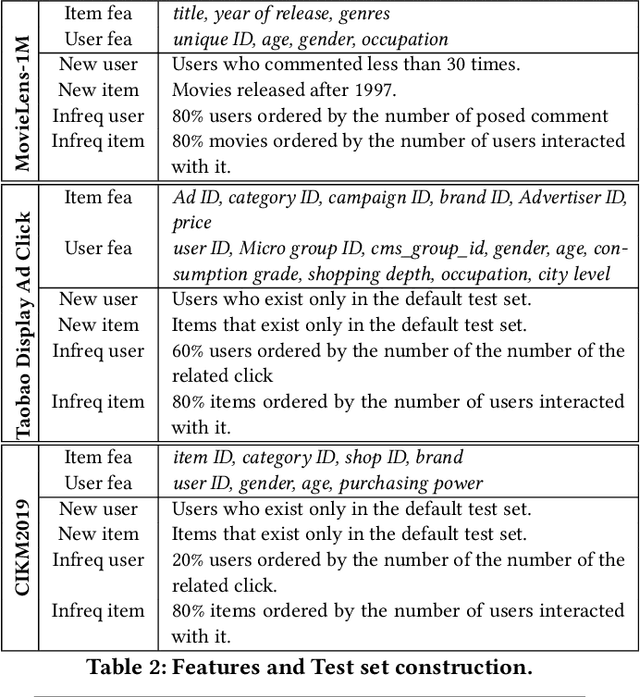
We propose a general Variational Embedding Learning Framework (VELF) for alleviating the severe cold-start problem in CTR prediction. VELF addresses the cold start problem via alleviating over-fits caused by data-sparsity in two ways: learning probabilistic embedding, and incorporating trainable and regularized priors which utilize the rich side information of cold start users and advertisements (Ads). The two techniques are naturally integrated into a variational inference framework, forming an end-to-end training process. Abundant empirical tests on benchmark datasets well demonstrate the advantages of our proposed VELF. Besides, extended experiments confirmed that our parameterized and regularized priors provide more generalization capability than traditional fixed priors.
Dynamic Parameterized Network for CTR Prediction
Nov 09, 2021
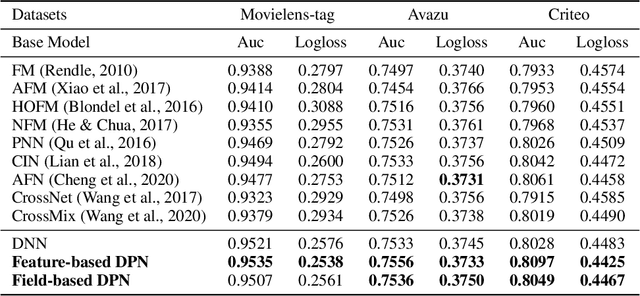
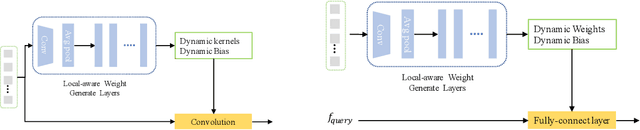
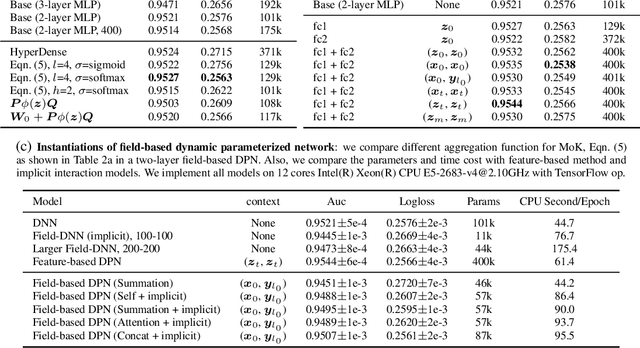
Learning to capture feature relations effectively and efficiently is essential in click-through rate (CTR) prediction of modern recommendation systems. Most existing CTR prediction methods model such relations either through tedious manually-designed low-order interactions or through inflexible and inefficient high-order interactions, which both require extra DNN modules for implicit interaction modeling. In this paper, we proposed a novel plug-in operation, Dynamic Parameterized Operation (DPO), to learn both explicit and implicit interaction instance-wisely. We showed that the introduction of DPO into DNN modules and Attention modules can respectively benefit two main tasks in CTR prediction, enhancing the adaptiveness of feature-based modeling and improving user behavior modeling with the instance-wise locality. Our Dynamic Parameterized Networks significantly outperforms state-of-the-art methods in the offline experiments on the public dataset and real-world production dataset, together with an online A/B test. Furthermore, the proposed Dynamic Parameterized Networks has been deployed in the ranking system of one of the world's largest e-commerce companies, serving the main traffic of hundreds of millions of active users.
Blending Advertising with Organic Content in E-Commerce: A Virtual Bids Optimization Approach
May 28, 2021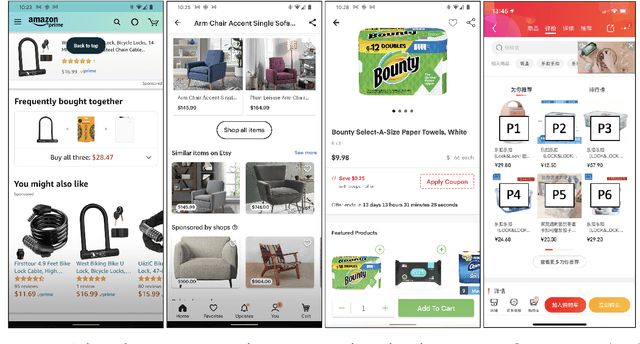
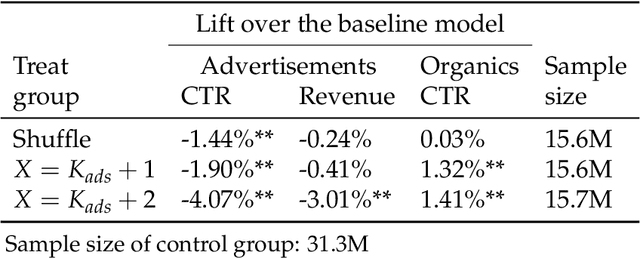
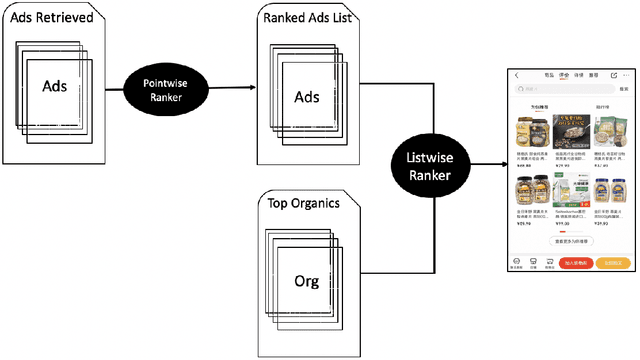
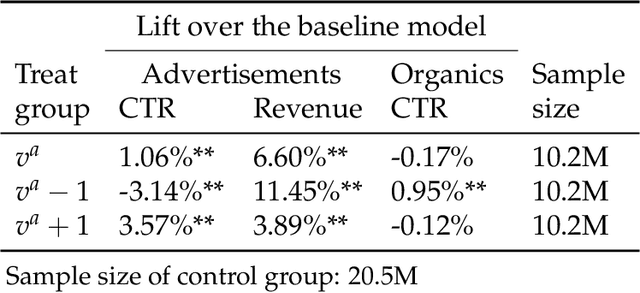
In e-commerce platforms, sponsored and non-sponsored content are jointly displayed to users and both may interactively influence their engagement behavior. The former content helps advertisers achieve their marketing goals and provides a stream of ad revenue to the platform. The latter content contributes to users' engagement with the platform, which is key to its long-term health. A burning issue for e-commerce platform design is how to blend advertising with content in a way that respects these interactions and balances these multiple business objectives. This paper describes a system developed for this purpose in the context of blending personalized sponsored content with non-sponsored content on the product detail pages of JD.COM, an e-commerce company. This system has three key features: (1) Optimization of multiple competing business objectives through a new virtual bids approach and the expressiveness of the latent, implicit valuation of the platform for the multiple objectives via these virtual bids. (2) Modeling of users' click behavior as a function of their characteristics, the individual characteristics of each sponsored content and the influence exerted by other sponsored and non-sponsored content displayed alongside through a deep learning approach; (3) Consideration of externalities in the allocation of ads, thereby making it directly compatible with a Vickrey-Clarke-Groves (VCG) auction scheme for the computation of payments in the presence of these externalities. The system is currently deployed and serving all traffic through JD.COM's mobile application. Experiments demonstrating the performance and advantages of the system are presented.