 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
Apr 18, 2021
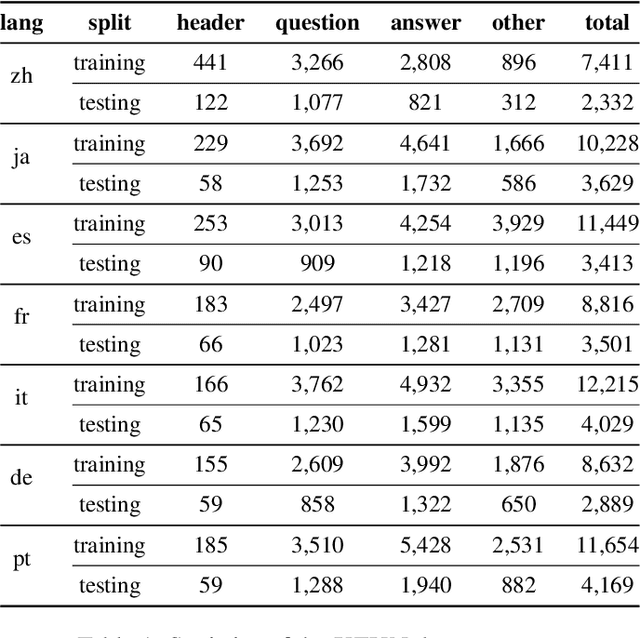
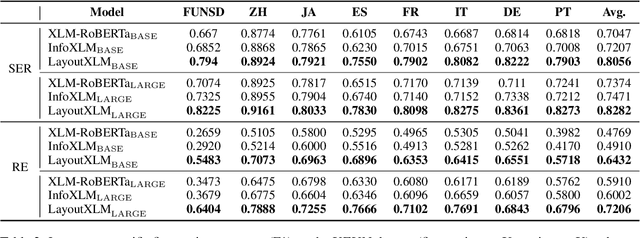
Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA cross-lingual pre-trained models on the XFUN dataset. The pre-trained LayoutXLM model and the XFUN dataset will be publicly available at https://aka.ms/layoutxlm.
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
Dec 29, 2020
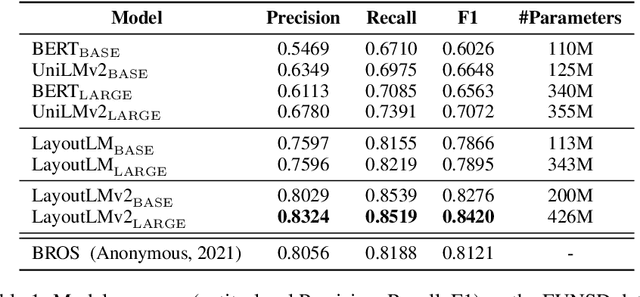
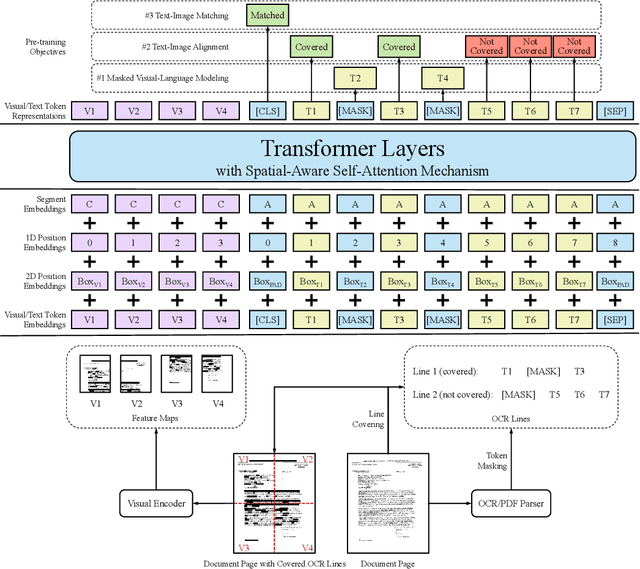
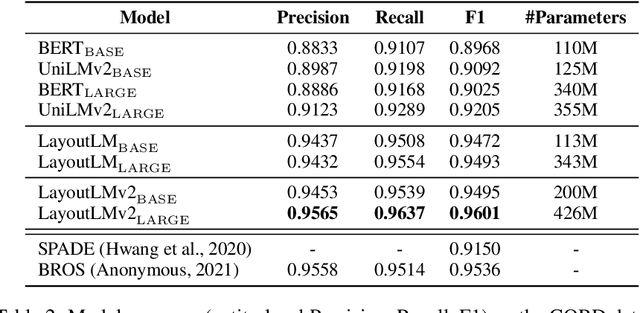
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this paper, we present \textbf{LayoutLMv2} by pre-training text, layout and image in a multi-modal framework, where new model architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention mechanism into the Transformer architecture, so that the model can fully understand the relative positional relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852), RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672).
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption
Dec 08, 2020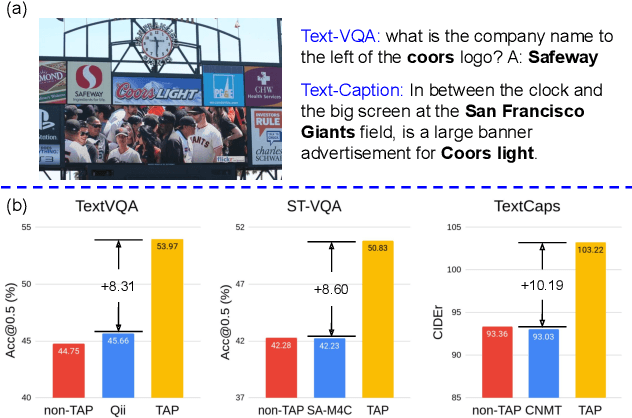
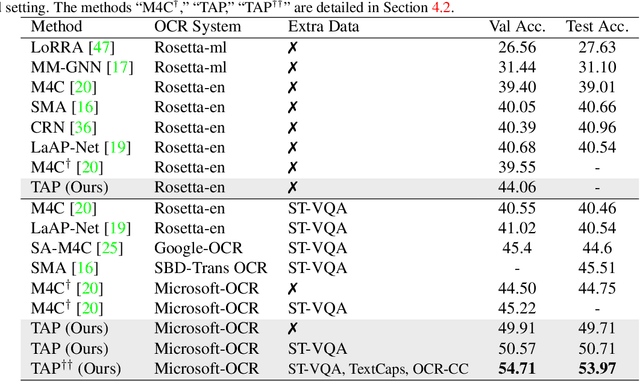
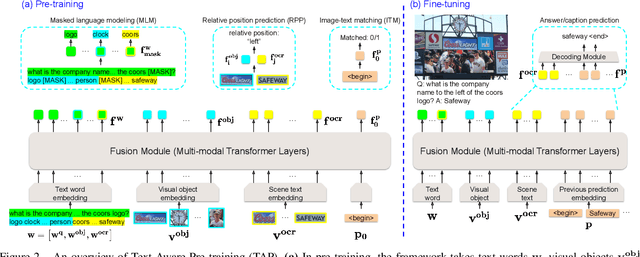
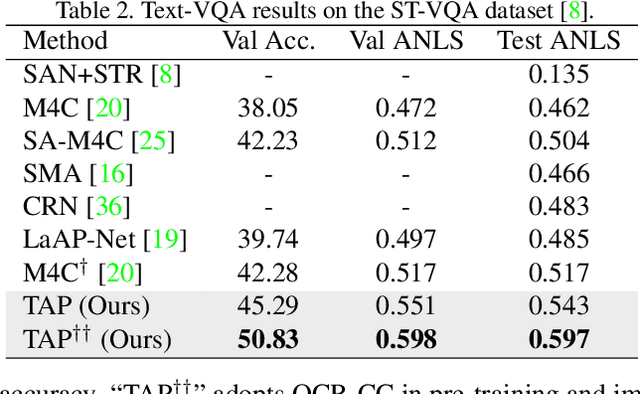
In this paper, we propose Text-Aware Pre-training (TAP) for Text-VQA and Text-Caption tasks. These two tasks aim at reading and understanding scene text in images for question answering and image caption generation, respectively. In contrast to the conventional vision-language pre-training that fails to capture scene text and its relationship with the visual and text modalities, TAP explicitly incorporates scene text (generated from OCR engines) in pre-training. With three pre-training tasks, including masked language modeling (MLM), image-text (contrastive) matching (ITM), and relative (spatial) position prediction (RPP), TAP effectively helps the model learn a better aligned representation among the three modalities: text word, visual object, and scene text. Due to this aligned representation learning, even pre-trained on the same downstream task dataset, TAP already boosts the absolute accuracy on the TextVQA dataset by +5.4%, compared with a non-TAP baseline. To further improve the performance, we build a large-scale dataset based on the Conceptual Caption dataset, named OCR-CC, which contains 1.4 million scene text-related image-text pairs. Pre-trained on this OCR-CC dataset, our approach outperforms the state of the art by large margins on multiple tasks, i.e., +8.3% accuracy on TextVQA, +8.6% accuracy on ST-VQA, and +10.2 CIDEr score on TextCaps.
Multimodal active speaker detection and virtual cinematography for video conferencing
Feb 12, 2020
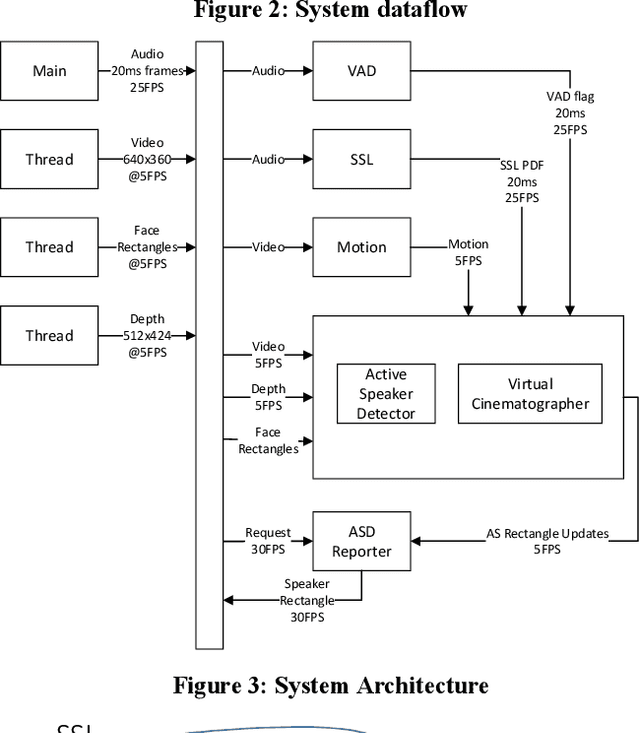
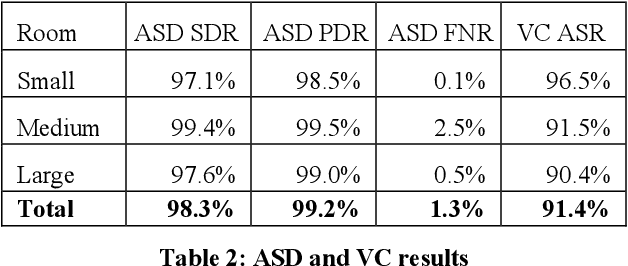
Active speaker detection (ASD) and virtual cinematography (VC) can significantly improve the remote user experience of a video conference by automatically panning, tilting and zooming of a video conferencing camera: users subjectively rate an expert video cinematographer's video significantly higher than unedited video. We describe a new automated ASD and VC that performs within 0.3 MOS of an expert cinematographer based on subjective ratings with a 1-5 scale. This system uses a 4K wide-FOV camera, a depth camera, and a microphone array; it extracts features from each modality and trains an ASD using an AdaBoost machine learning system that is very efficient and runs in real-time. A VC is similarly trained using machine learning to optimize the subjective quality of the overall experience. To avoid distracting the room participants and reduce switching latency the system has no moving parts -- the VC works by cropping and zooming the 4K wide-FOV video stream. The system was tuned and evaluated using extensive crowdsourcing techniques and evaluated on a dataset with N=100 meetings, each 2-5 minutes in length.
Improving the Adversarial Robustness of Transfer Learning via Noisy Feature Distillation
Feb 07, 2020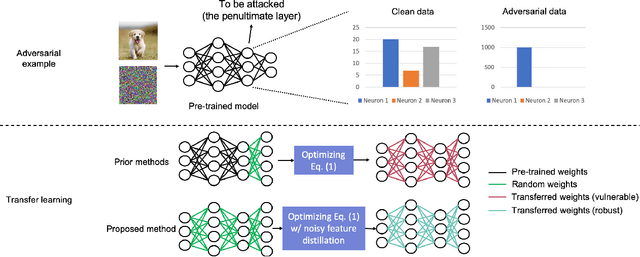

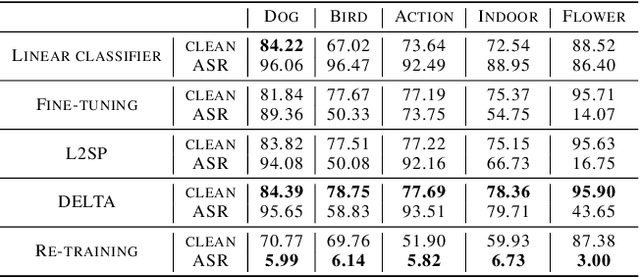
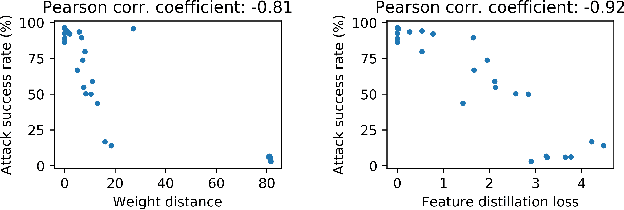
Fine-tuning through knowledge transfer from a pre-trained model on a large-scale dataset is a widely spread approach to effectively build models on small-scale datasets. However, recent literature has shown that such a fine-tuning approach is vulnerable to adversarial examples based on the pre-trained model, which raises security concerns for many industrial applications. In contrast, models trained with random initialization are much more robust to such attacks, although these models often exhibit much lower accuracy. In this work, we propose noisy feature distillation, a new transfer learning method that trains a network from random initialization while achieving clean-data performance competitive with fine-tuning. In addition, the method is shown empirically to significantly improve the robustness compared to fine-tuning with 15x reduction in attack success rate for ResNet-50, from 66% to 4.4% averaged across Stanford 120 Dogs, Caltech-UCSD 200 Birds, Stanford 40 Actions, MIT 67 Indoor Scenes, and Oxford 102 Flowers datasets. Code is available at https://github.com/cmu-enyac/Renofeation.
LeGR: Filter Pruning via Learned Global Ranking
Apr 28, 2019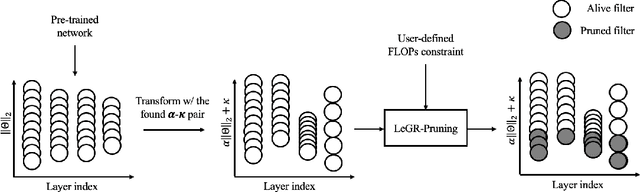
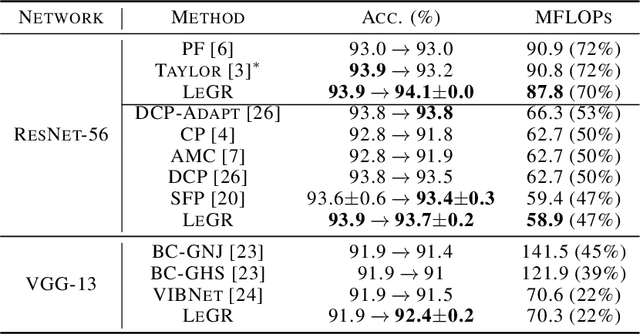
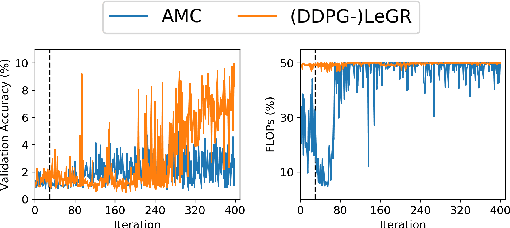

Filter pruning has shown to be effective for learning resource-constrained convolutional neural networks (CNNs). However, prior methods for resource-constrained filter pruning have some limitations that hinder their effectiveness and efficiency. When searching for constraint-satisfying CNNs, prior methods either alter the optimization objective or adopt local search algorithms with heuristic parameterization, which are sub-optimal, especially in low-resource regime. From the efficiency perspective, prior methods are often costly to search for constraint-satisfying CNNs. In this work, we propose learned global ranking, dubbed LeGR, which improves upon prior art in the two aforementioned dimensions. Inspired by theoretical analysis, LeGR is parameterized to learn layer-wise affine transformations over the filter norms to construct a learned global ranking. With global ranking, resource-constrained filter pruning at various constraint levels can be done efficiently. We conduct extensive empirical analyses to demonstrate the effectiveness of the proposed algorithm with ResNet and MobileNetV2 networks on CIFAR-10, CIFAR-100, Bird-200, and ImageNet datasets. Code is publicly available at https://github.com/cmu-enyac/LeGR.
RePr: Improved Training of Convolutional Filters
Nov 26, 2018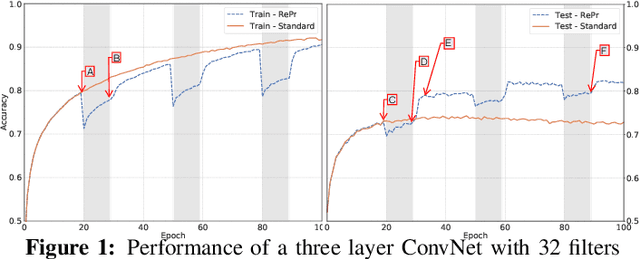
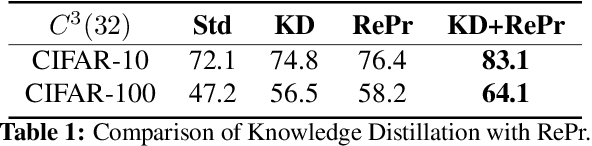
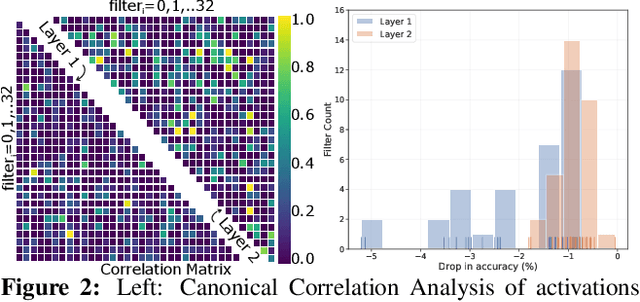
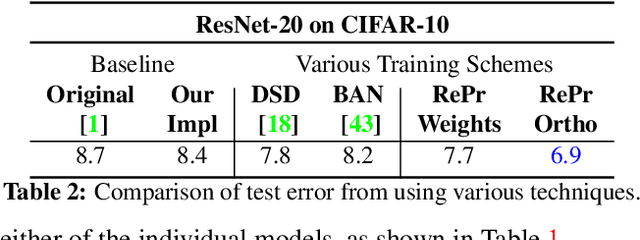
A well-trained Convolutional Neural Network can easily be pruned without significant loss of performance. This is because of unnecessary overlap in the features captured by the network's filters. Innovations in network architecture such as skip/dense connections and Inception units have mitigated this problem to some extent, but these improvements come with increased computation and memory requirements at run-time. We attempt to address this problem from another angle - not by changing the network structure but by altering the training method. We show that by temporarily pruning and then restoring a subset of the model's filters, and repeating this process cyclically, overlap in the learned features is reduced, producing improved generalization. We show that the existing model-pruning criteria are not optimal for selecting filters to prune in this context and introduce inter-filter orthogonality as the ranking criteria to determine under-expressive filters. Our method is applicable both to vanilla convolutional networks and more complex modern architectures, and improves the performance across a variety of tasks, especially when applied to smaller networks.
Layer-compensated Pruning for Resource-constrained Convolutional Neural Networks
Oct 18, 2018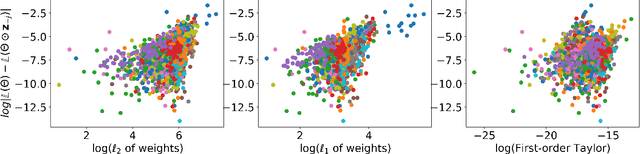
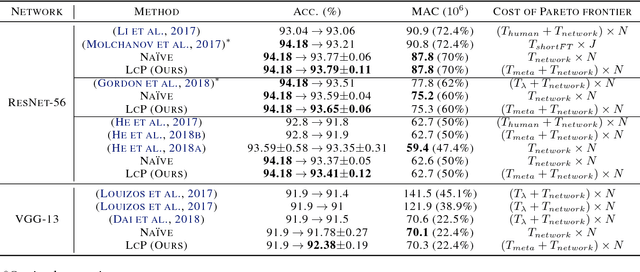
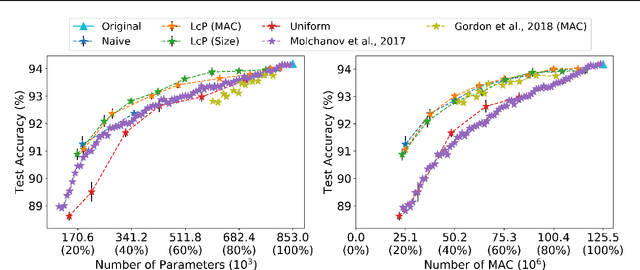
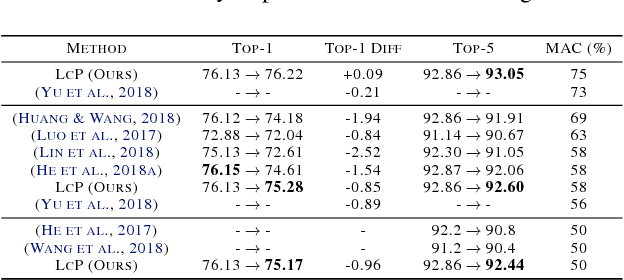
Resource-efficient convolution neural networks enable not only the intelligence on edge devices but also opportunities in system-level optimization such as scheduling. In this work, we aim to improve the performance of resource-constrained filter pruning by merging two sub-problems commonly considered, i.e., (i) how many filters to prune for each layer and (ii) which filters to prune given a per-layer pruning budget, into a global filter ranking problem. Our framework entails a novel algorithm, dubbed layer-compensated pruning, where meta-learning is involved to determine better solutions. We show empirically that the proposed algorithm is superior to prior art in both effectiveness and efficiency. Specifically, we reduce the accuracy gap between the pruned and original networks from 0.9% to 0.7% with 8x reduction in time needed for meta-learning, i.e., from 1 hour down to 7 minutes. To this end, we demonstrate the effectiveness of our algorithm using ResNet and MobileNetV2 networks under CIFAR-10, ImageNet, and Bird-200 datasets.
Orthogonal and Idempotent Transformations for Learning Deep Neural Networks
Jul 19, 2017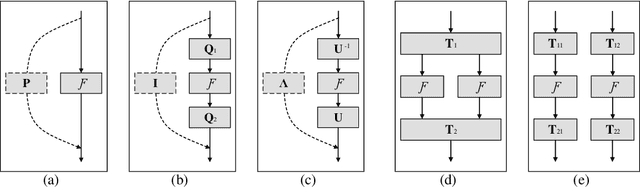
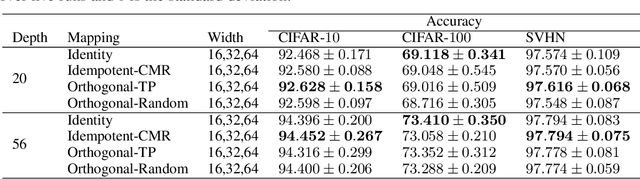
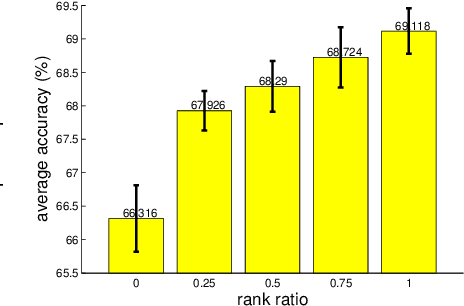
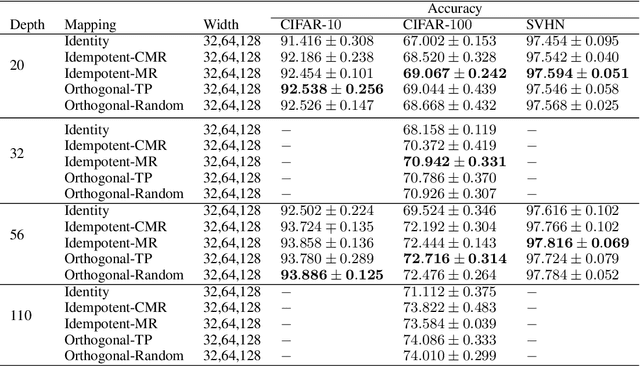
Identity transformations, used as skip-connections in residual networks, directly connect convolutional layers close to the input and those close to the output in deep neural networks, improving information flow and thus easing the training. In this paper, we introduce two alternative linear transforms, orthogonal transformation and idempotent transformation. According to the definition and property of orthogonal and idempotent matrices, the product of multiple orthogonal (same idempotent) matrices, used to form linear transformations, is equal to a single orthogonal (idempotent) matrix, resulting in that information flow is improved and the training is eased. One interesting point is that the success essentially stems from feature reuse and gradient reuse in forward and backward propagation for maintaining the information during flow and eliminating the gradient vanishing problem because of the express way through skip-connections. We empirically demonstrate the effectiveness of the proposed two transformations: similar performance in single-branch networks and even superior in multi-branch networks in comparison to identity transformations.
Training Deep Networks for Facial Expression Recognition with Crowd-Sourced Label Distribution
Sep 24, 2016
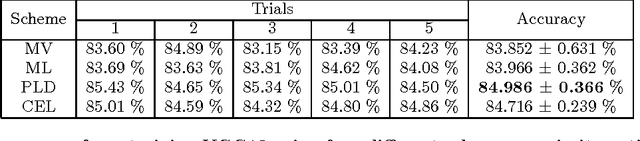
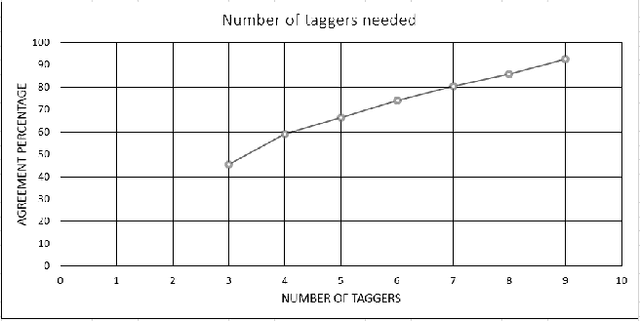

Crowd sourcing has become a widely adopted scheme to collect ground truth labels. However, it is a well-known problem that these labels can be very noisy. In this paper, we demonstrate how to learn a deep convolutional neural network (DCNN) from noisy labels, using facial expression recognition as an example. More specifically, we have 10 taggers to label each input image, and compare four different approaches to utilizing the multiple labels: majority voting, multi-label learning, probabilistic label drawing, and cross-entropy loss. We show that the traditional majority voting scheme does not perform as well as the last two approaches that fully leverage the label distribution. An enhanced FER+ data set with multiple labels for each face image will also be shared with the research community.