 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time 3D Semantic Scene Completion Via Feature Aggregation and Conditioned Prediction
Mar 25, 2023Semantic Scene Completion (SSC) aims to simultaneously predict the volumetric occupancy and semantic category of a 3D scene. In this paper, we propose a real-time semantic scene completion method with a feature aggregation strategy and conditioned prediction module. Feature aggregation fuses feature with different receptive fields and gathers context to improve scene completion performance. And the conditioned prediction module adopts a two-step prediction scheme that takes volumetric occupancy as a condition to enhance semantic completion prediction. We conduct experiments on three recognized benchmarks NYU, NYUCAD, and SUNCG. Our method achieves competitive performance at a speed of 110 FPS on one GTX 1080 Ti GPU.
Malleable 2.5D Convolution: Learning Receptive Fields along the Depth-axis for RGB-D Scene Parsing
Jul 18, 2020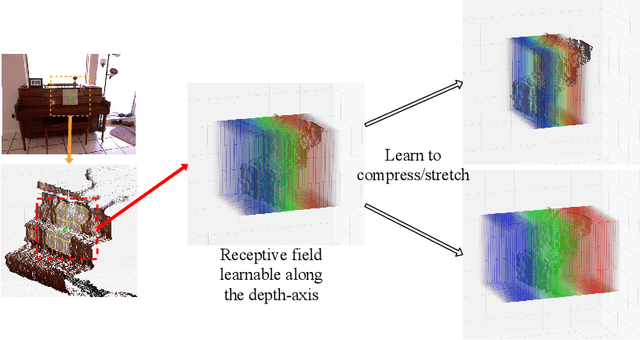
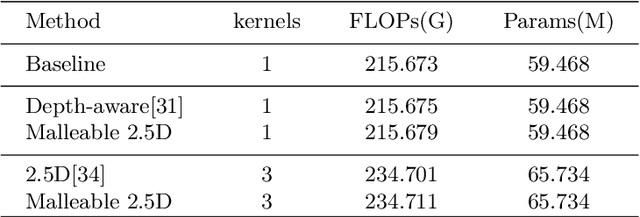
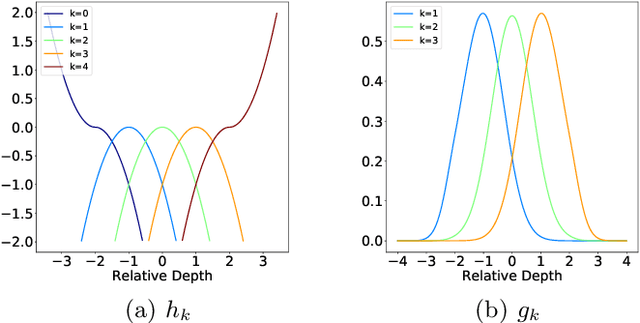
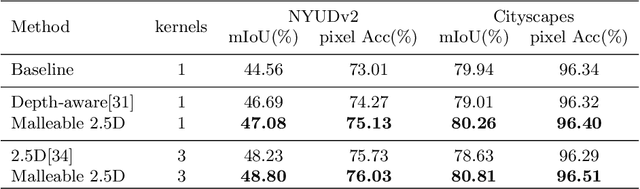
Depth data provide geometric information that can bring progress in RGB-D scene parsing tasks. Several recent works propose RGB-D convolution operators that construct receptive fields along the depth-axis to handle 3D neighborhood relations between pixels. However, these methods pre-define depth receptive fields by hyperparameters, making them rely on parameter selection. In this paper, we propose a novel operator called malleable 2.5D convolution to learn the receptive field along the depth-axis. A malleable 2.5D convolution has one or more 2D convolution kernels. Our method assigns each pixel to one of the kernels or none of them according to their relative depth differences, and the assigning process is formulated as a differentiable form so that it can be learnt by gradient descent. The proposed operator runs on standard 2D feature maps and can be seamlessly incorporated into pre-trained CNNs. We conduct extensive experiments on two challenging RGB-D semantic segmentation dataset NYUDv2 and Cityscapes to validate the effectiveness and the generalization ability of our method.
Orthogonal and Idempotent Transformations for Learning Deep Neural Networks
Jul 19, 2017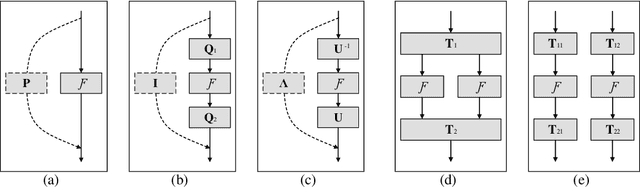
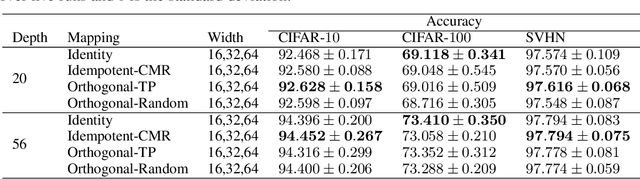
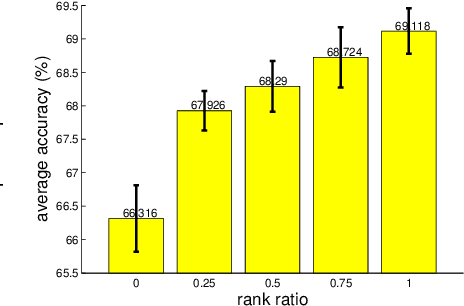
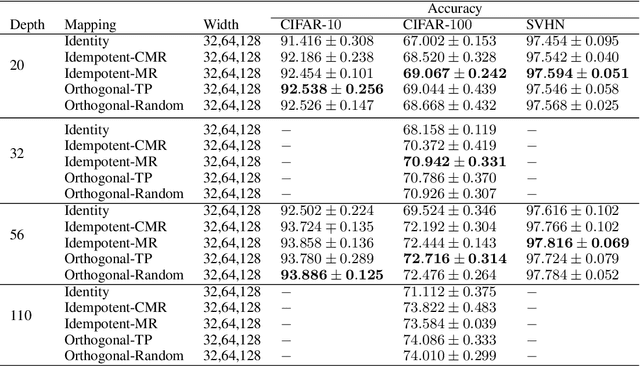
Identity transformations, used as skip-connections in residual networks, directly connect convolutional layers close to the input and those close to the output in deep neural networks, improving information flow and thus easing the training. In this paper, we introduce two alternative linear transforms, orthogonal transformation and idempotent transformation. According to the definition and property of orthogonal and idempotent matrices, the product of multiple orthogonal (same idempotent) matrices, used to form linear transformations, is equal to a single orthogonal (idempotent) matrix, resulting in that information flow is improved and the training is eased. One interesting point is that the success essentially stems from feature reuse and gradient reuse in forward and backward propagation for maintaining the information during flow and eliminating the gradient vanishing problem because of the express way through skip-connections. We empirically demonstrate the effectiveness of the proposed two transformations: similar performance in single-branch networks and even superior in multi-branch networks in comparison to identity transformations.