 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh Manifold based Riemannian Motion Planning for Omnidirectional Micro Aerial Vehicles
Feb 20, 2021
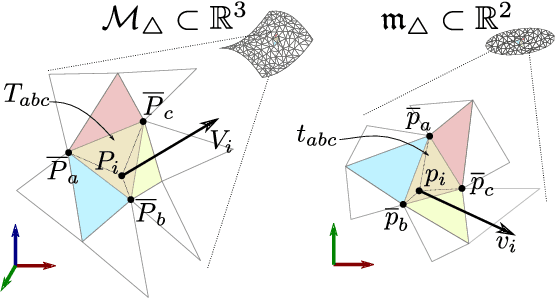

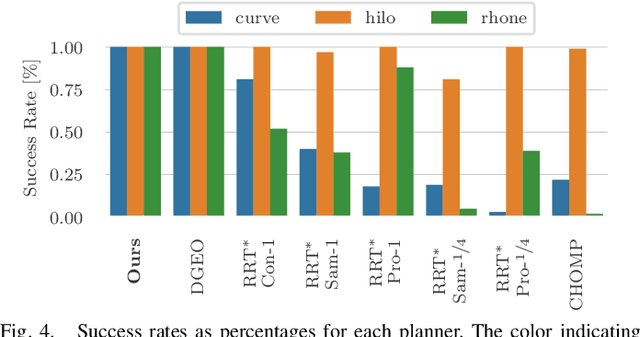
This paper presents a novel on-line path planning method that enables aerial robots to interact with surfaces. We present a solution to the problem of finding trajectories that drive a robot towards a surface and move along it. Triangular meshes are used as a surface map representation that is free of fixed discretization and allows for very large workspaces. We propose to leverage planar parametrization methods to obtain a lower-dimensional topologically equivalent representation of the original surface. Furthermore, we interpret the original surface and its lower-dimensional representation as manifold approximations that allow the use of Riemannian Motion Policies (RMPs), resulting in an efficient, versatile, and elegant motion generation framework. We compare against several Rapidly-exploring Random Tree (RRT) planners, a customized CHOMP variant, and the discrete geodesic algorithm. Using extensive simulations on real-world data we show that the proposed planner can reliably plan high-quality near-optimal trajectories at minimal computational cost. The accompanying multimedia attachment demonstrates feasibility on a real OMAV. The obtained paths show less than 10% deviation from the theoretical optimum while facilitating reactive re-planning at kHz refresh rates, enabling flying robots to perform motion planning for interaction with complex surfaces.
PHASER: a Robust and Correspondence-free Global Pointcloud Registration
Feb 03, 2021
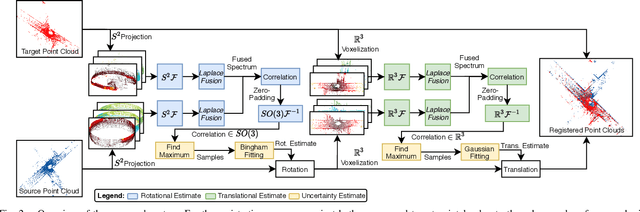
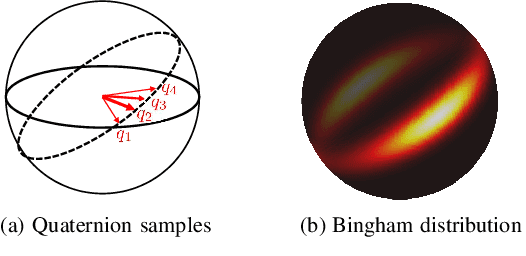
We propose PHASER, a correspondence-free global registration of sensor-centric pointclouds that is robust to noise, sparsity, and partial overlaps. Our method can seamlessly handle multimodal information and does not rely on keypoint nor descriptor preprocessing modules. By exploiting properties of Fourier analysis, PHASER operates directly on the sensor's signal, fusing the spectra of multiple channels and computing the 6-DoF transformation based on correlation. Our registration pipeline starts by finding the most likely rotation followed by computing the most likely translation. Both estimates are distributed according to a probability distribution that takes the underlying manifold into account, i.e., a Bingham and Gaussian distribution, respectively. This further allows our approach to consider the periodic-nature of rotations and naturally represent its uncertainty. We extensively compare PHASER against several well-known registration algorithms on both simulated datasets, and real-world data acquired using different sensor configurations. Our results show that PHASER can globally align pointclouds in less than 100ms with an average accuracy of 2cm and 0.5deg, is resilient against noise, and can handle partial overlap.
Multiple Hypothesis Semantic Mapping for Robust Data Association
Dec 08, 2020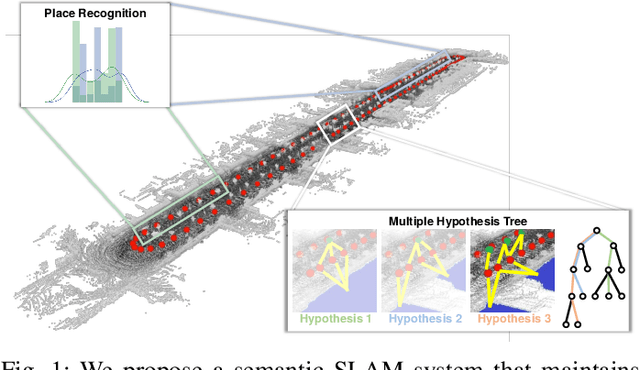
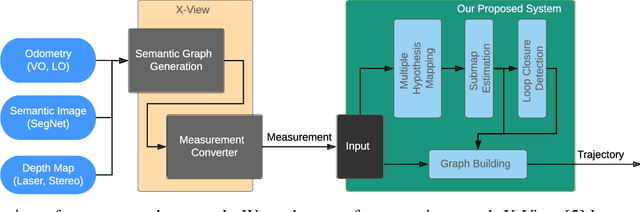
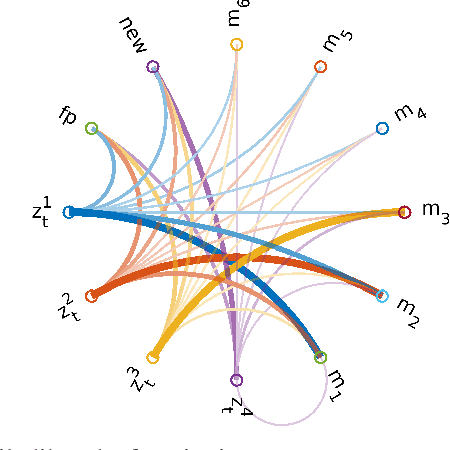
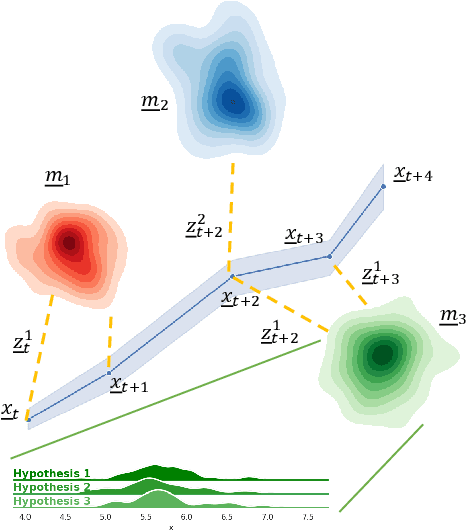
In this paper, we present a semantic mapping approach with multiple hypothesis tracking for data association. As semantic information has the potential to overcome ambiguity in measurements and place recognition, it forms an eminent modality for autonomous systems. This is particularly evident in urban scenarios with several similar looking surroundings. Nevertheless, it requires the handling of a non-Gaussian and discrete random variable coming from object detectors. Previous methods facilitate semantic information for global localization and data association to reduce the instance ambiguity between the landmarks. However, many of these approaches do not deal with the creation of complete globally consistent representations of the environment and typically do not scale well. We utilize multiple hypothesis trees to derive a probabilistic data association for semantic measurements by means of position, instance and class to create a semantic representation. We propose an optimized mapping method and make use of a pose graph to derive a novel semantic SLAM solution. Furthermore, we show that semantic covisibility graphs allow for a precise place recognition in urban environments. We verify our approach using real-world outdoor dataset and demonstrate an average drift reduction of 33 % w.r.t. the raw odometry source. Moreover, our approach produces 55 % less hypotheses on average than a regular multiple hypotheses approach.
Quantifying Aleatoric and Epistemic Uncertainty Using Density Estimation in Latent Space
Dec 05, 2020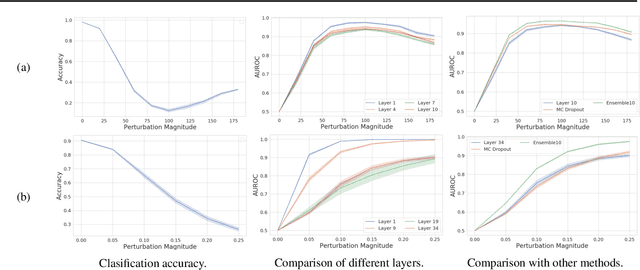
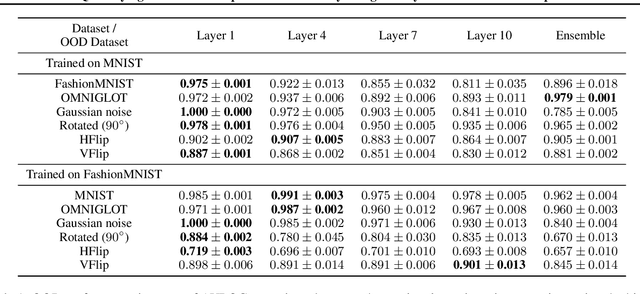

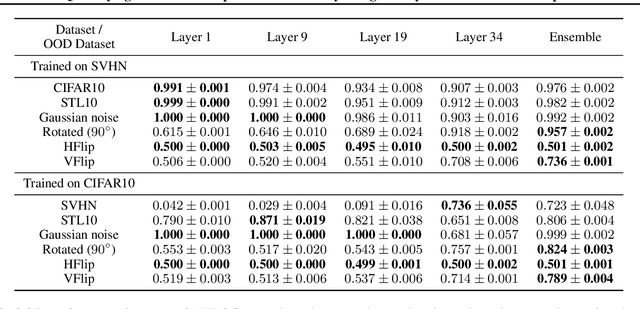
The distribution of a neural network's latent representations has been successfully used to detect Out-of-Distribution (OOD) data. Since OOD detection denotes a popular benchmark for epistemic uncertainty estimates, this raises the question of a deeper correlation. This work investigates whether the distribution of latent representations indeed contains information about the uncertainty associated with the predictions of a neural network. Prior work identifies epistemic uncertainty with the surprise, thus the negative log-likelihood, of observing a particular latent representation, which we verify empirically. Moreover, we demonstrate that the output-conditional distribution of hidden representations allows quantifying aleatoric uncertainty via the entropy of the predictive distribution. We analyze epistemic and aleatoric uncertainty inferred from the representations of different layers and conclude with the exciting finding that the hidden repesentations of a deterministic neural network indeed contain information about its uncertainty. We verify our findings on both classification and regression models.
Learning Trajectories for Visual-Inertial System Calibration via Model-based Heuristic Deep Reinforcement Learning
Nov 04, 2020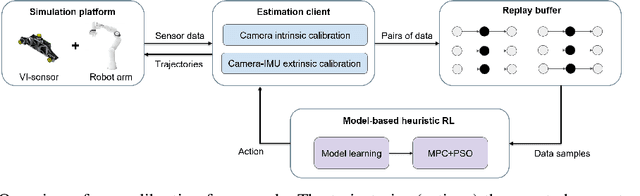
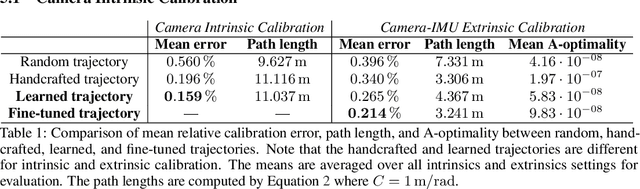
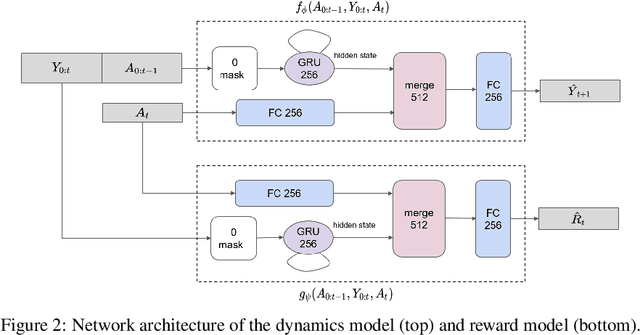
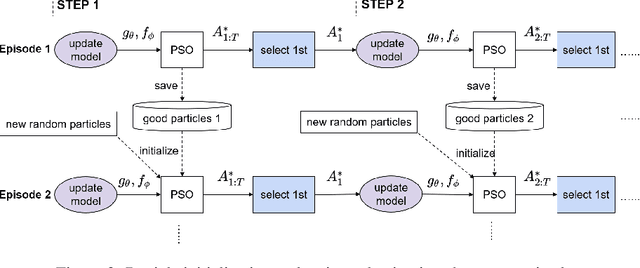
Visual-inertial systems rely on precise calibrations of both camera intrinsics and inter-sensor extrinsics, which typically require manually performing complex motions in front of a calibration target. In this work we present a novel approach to obtain favorable trajectories for visual-inertial system calibration, using model-based deep reinforcement learning. Our key contribution is to model the calibration process as a Markov decision process and then use model-based deep reinforcement learning with particle swarm optimization to establish a sequence of calibration trajectories to be performed by a robot arm. Our experiments show that while maintaining similar or shorter path lengths, the trajectories generated by our learned policy result in lower calibration errors compared to random or handcrafted trajectories.
Out-of-Distribution Detection for Automotive Perception
Nov 03, 2020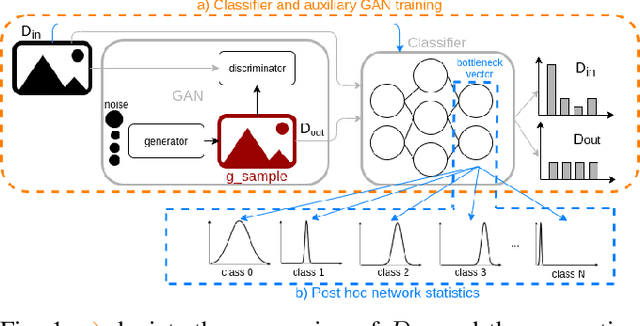
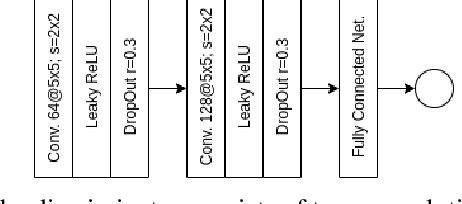
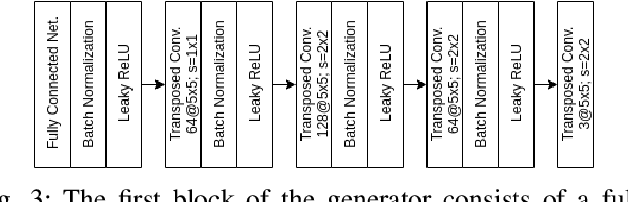
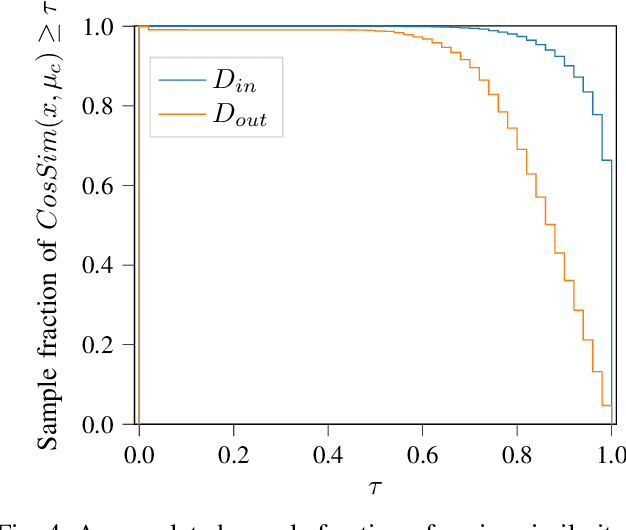
Neural networks (NNs) are widely used for object recognition tasks in autonomous driving. However, NNs can fail on input data not well represented by the training dataset, known as out-of-distribution (OOD) data. A mechanism to detect OOD samples is important in safety-critical applications, such as automotive perception, in order to trigger a safe fallback mode. NNs often rely on softmax normalization for confidence estimation, which can lead to high confidences being assigned to OOD samples, thus hindering the detection of failures. This paper presents a simple but effective method for determining whether inputs are OOD. We propose an OOD detection approach that combines auxiliary training techniques with post hoc statistics. Unlike other approaches, our proposed method does not require OOD data during training, and it does not increase the computational cost during inference. The latter property is especially important in automotive applications with limited computational resources and real-time constraints. Our proposed method outperforms state-of-the-art methods on real world automotive datasets.
Freetures: Localization in Signed Distance Function Maps
Oct 21, 2020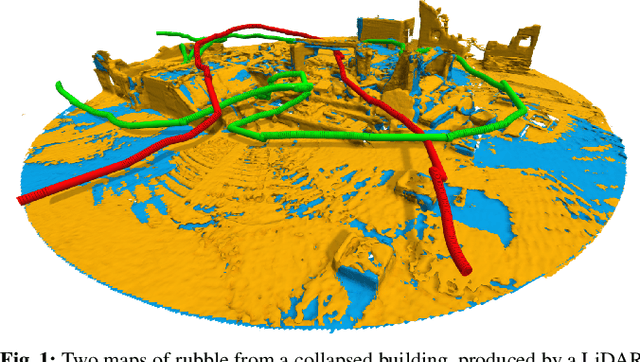
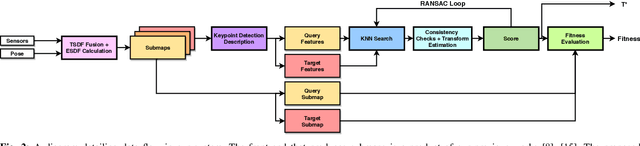


Localization of a robotic system within a previously mapped environment is important for reducing estimation drift and for reusing previously built maps. Existing techniques for geometry-based localization have focused on the description of local surface geometry, usually using pointclouds as the underlying representation. We propose a system for geometry-based localization that extracts features directly from an implicit surface representation: the Signed Distance Function (SDF). The SDF varies continuously through space, which allows the proposed system to extract and utilize features describing both surfaces and free-space. Through evaluations on public datasets, we demonstrate the flexibility of this approach, and show an increase in localization performance over state-of-the-art handcrafted surfaces-only descriptors. We achieve an average improvement of ~12% on an RGB-D dataset and ~18% on a LiDAR-based dataset. Finally, we demonstrate our system for localizing a LiDAR-equipped MAV within a previously built map of a search and rescue training ground.
A Unified Approach for Autonomous Volumetric Exploration of Large Scale Environments under Severe Odometry Drift
Oct 19, 2020
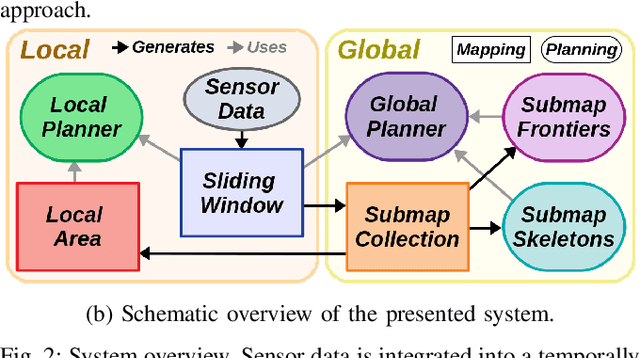
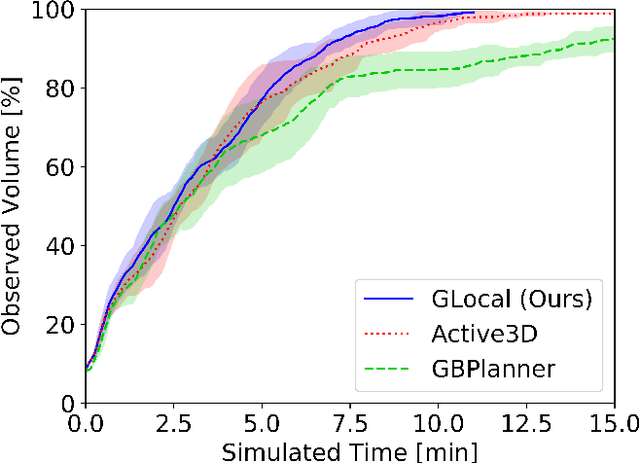
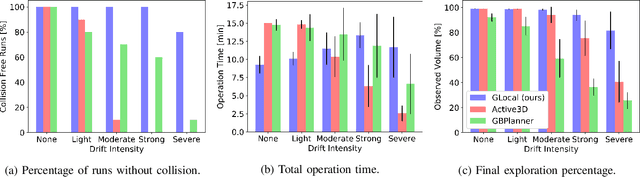
Exploration is a fundamental problem in robot autonomy. A major limitation, however, is that during exploration robots oftentimes have to rely on on-board systems alone for state estimation, accumulating significant drift over time in large environments. Drift can be detrimental to robot safety and exploration performance. In this work, a submap-based, multi-layer approach for both mapping and planning is proposed to enable safe and efficient volumetric exploration of large scale environments despite odometry drift. The central idea of our approach combines local (temporally and spatially) and global mapping to guarantee safety and efficiency. Similarly, our planning approach leverages the presented map to compute global volumetric frontiers in a changing global map and utilizes the nature of exploration dealing with partial information for efficient local and global planning. The presented system is thoroughly evaluated and shown to outperform state of the art methods even under drift-free conditions. Our system, termed GLoca}, will be made available open source.
Empty Cities: a Dynamic-Object-Invariant Space for Visual SLAM
Oct 15, 2020

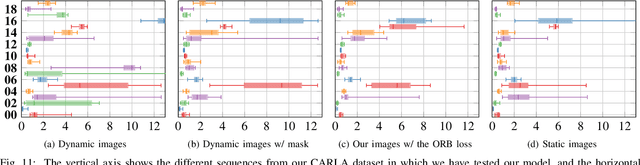
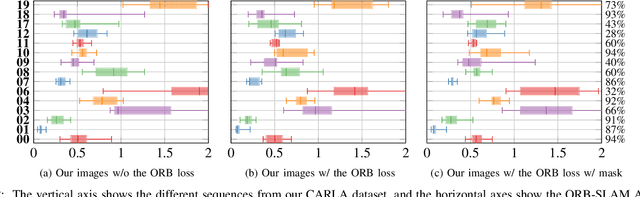
In this paper we present a data-driven approach to obtain the static image of a scene, eliminating dynamic objects that might have been present at the time of traversing the scene with a camera. The general objective is to improve vision-based localization and mapping tasks in dynamic environments, where the presence (or absence) of different dynamic objects in different moments makes these tasks less robust. We introduce an end-to-end deep learning framework to turn images of an urban environment that include dynamic content, such as vehicles or pedestrians, into realistic static frames suitable for localization and mapping. This objective faces two main challenges: detecting the dynamic objects, and inpainting the static occluded back-ground. The first challenge is addressed by the use of a convolutional network that learns a multi-class semantic segmentation of the image. The second challenge is approached with a generative adversarial model that, taking as input the original dynamic image and the computed dynamic/static binary mask, is capable of generating the final static image. This framework makes use of two new losses, one based on image steganalysis techniques, useful to improve the inpainting quality, and another one based on ORB features, designed to enhance feature matching between real and hallucinated image regions. To validate our approach, we perform an extensive evaluation on different tasks that are affected by dynamic entities, i.e., visual odometry, place recognition and multi-view stereo, with the hallucinated images. Code has been made available on https://github.com/bertabescos/EmptyCities_SLAM.
Deep Learning-based Human Detection for UAVs with Optical and Infrared Cameras: System and Experiments
Aug 10, 2020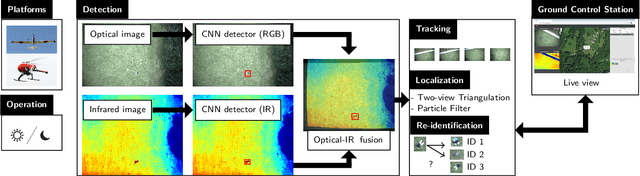
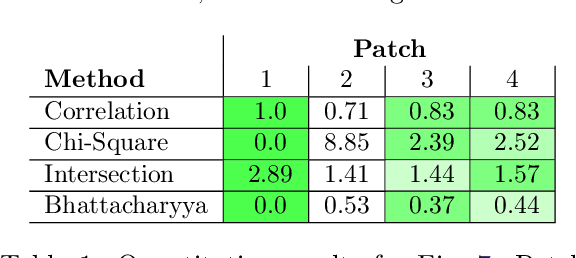

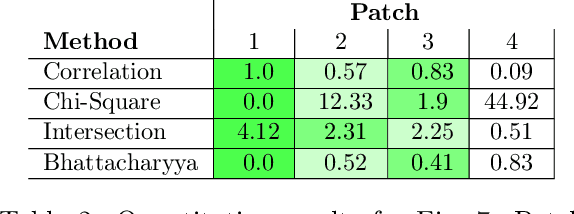
In this paper, we present our deep learning-based human detection system that uses optical (RGB) and long-wave infrared (LWIR) cameras to detect, track, localize, and re-identify humans from UAVs flying at high altitude. In each spectrum, a customized RetinaNet network with ResNet backbone provides human detections which are subsequently fused to minimize the overall false detection rate. We show that by optimizing the bounding box anchors and augmenting the image resolution the number of missed detections from high altitudes can be decreased by over 20 percent. Our proposed network is compared to different RetinaNet and YOLO variants, and to a classical optical-infrared human detection framework that uses hand-crafted features. Furthermore, along with the publication of this paper, we release a collection of annotated optical-infrared datasets recorded with different UAVs during search-and-rescue field tests and the source code of the implemented annotation tool.