 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitch Spaces: Learning Product Spaces with Sparse Gating
Feb 17, 2021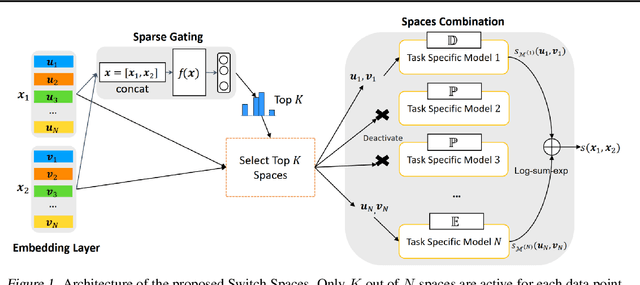
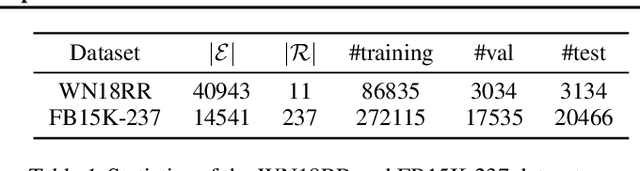
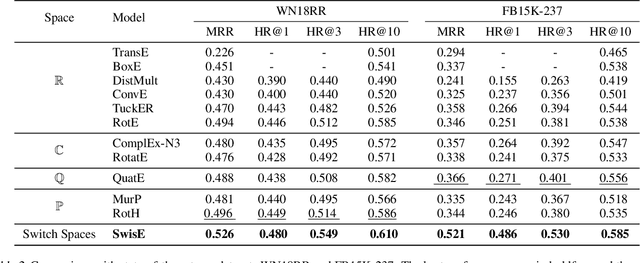
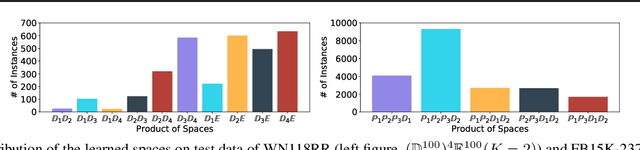
Learning embedding spaces of suitable geometry is critical for representation learning. In order for learned representations to be effective and efficient, it is ideal that the geometric inductive bias aligns well with the underlying structure of the data. In this paper, we propose Switch Spaces, a data-driven approach for learning representations in product space. Specifically, product spaces (or manifolds) are spaces of mixed curvature, i.e., a combination of multiple euclidean and non-euclidean (hyperbolic, spherical) manifolds. To this end, we introduce sparse gating mechanisms that learn to choose, combine and switch spaces, allowing them to be switchable depending on the input data with specialization. Additionally, the proposed method is also efficient and has a constant computational complexity regardless of the model size. Experiments on knowledge graph completion and item recommendations show that the proposed switch space achieves new state-of-the-art performances, outperforming pure product spaces and recently proposed task-specific models.
Decoding EEG Brain Activity for Multi-Modal Natural Language Processing
Feb 17, 2021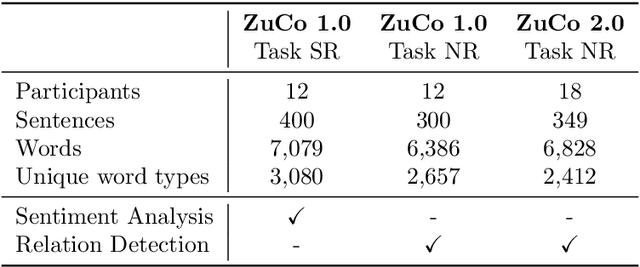
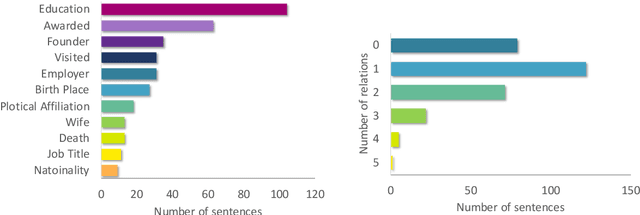
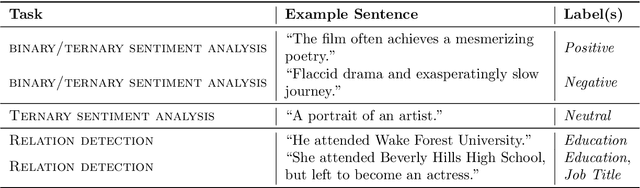
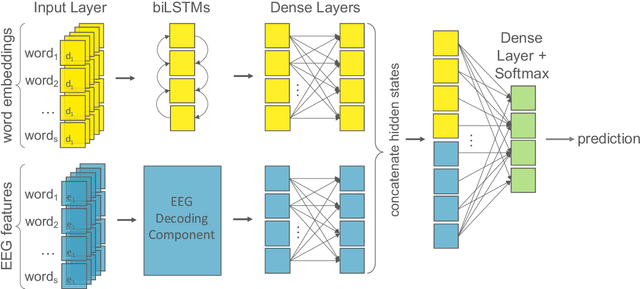
Until recently, human behavioral data from reading has mainly been of interest to researchers to understand human cognition. However, these human language processing signals can also be beneficial in machine learning-based natural language processing tasks. Using EEG brain activity to this purpose is largely unexplored as of yet. In this paper, we present the first large-scale study of systematically analyzing the potential of EEG brain activity data for improving natural language processing tasks, with a special focus on which features of the signal are most beneficial. We present a multi-modal machine learning architecture that learns jointly from textual input as well as from EEG features. We find that filtering the EEG signals into frequency bands is more beneficial than using the broadband signal. Moreover, for a range of word embedding types, EEG data improves binary and ternary sentiment classification and outperforms multiple baselines. For more complex tasks such as relation detection, further research is needed. Finally, EEG data shows to be particularly promising when limited training data is available.
A Data Quality-Driven View of MLOps
Feb 15, 2021

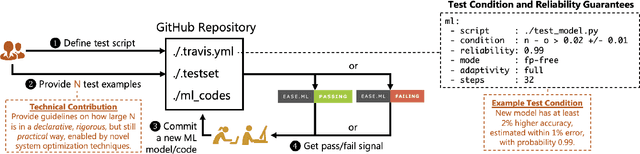
Developing machine learning models can be seen as a process similar to the one established for traditional software development. A key difference between the two lies in the strong dependency between the quality of a machine learning model and the quality of the data used to train or perform evaluations. In this work, we demonstrate how different aspects of data quality propagate through various stages of machine learning development. By performing a joint analysis of the impact of well-known data quality dimensions and the downstream machine learning process, we show that different components of a typical MLOps pipeline can be efficiently designed, providing both a technical and theoretical perspective.
1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed
Feb 04, 2021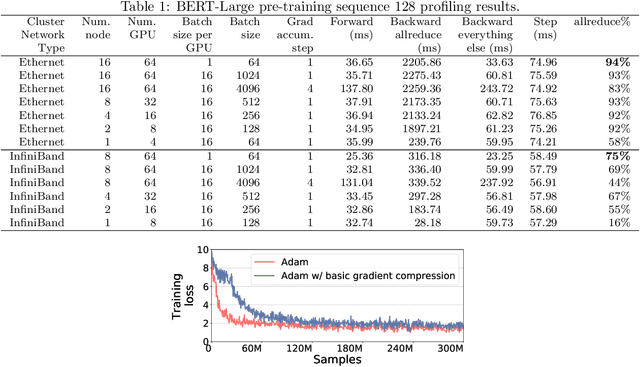
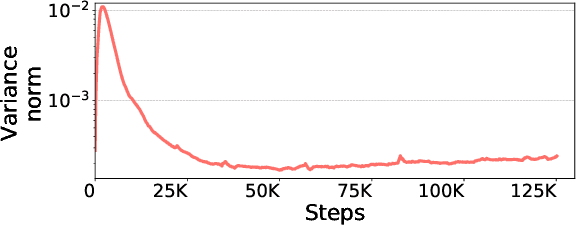
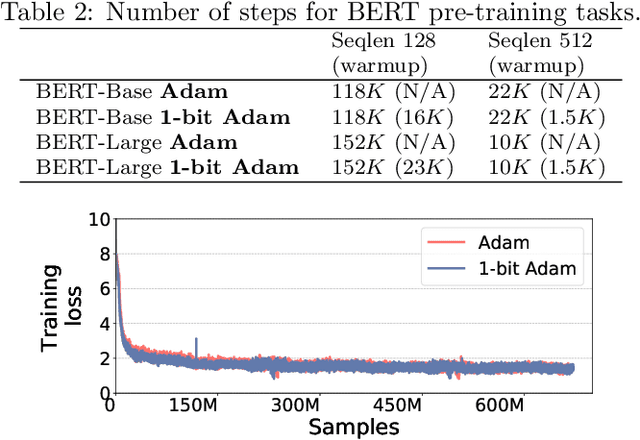

Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective methods is error-compensated compression, which offers robust convergence speed even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to $5\times$, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance (non-linear term) becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). Experiments on up to 256 GPUs show that 1-bit Adam enables up to $3.3\times$ higher throughput for BERT-Large pre-training and up to $2.9\times$ higher throughput for SQuAD fine-tuning. In addition, we provide theoretical analysis for our proposed work.
EEG-Inception: An Accurate and Robust End-to-End Neural Network for EEG-based Motor Imagery Classification
Feb 01, 2021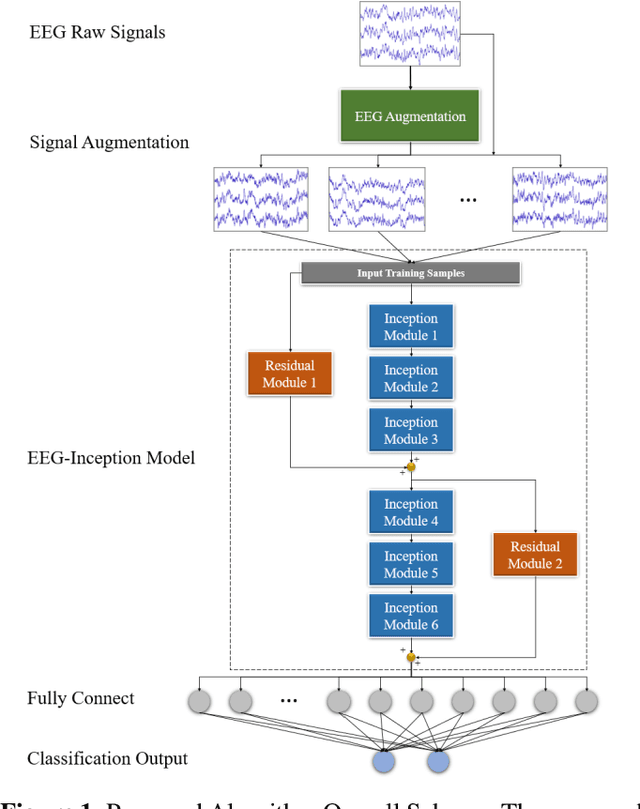

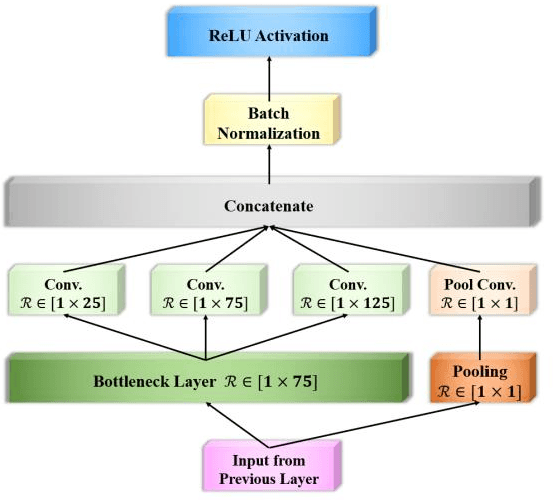
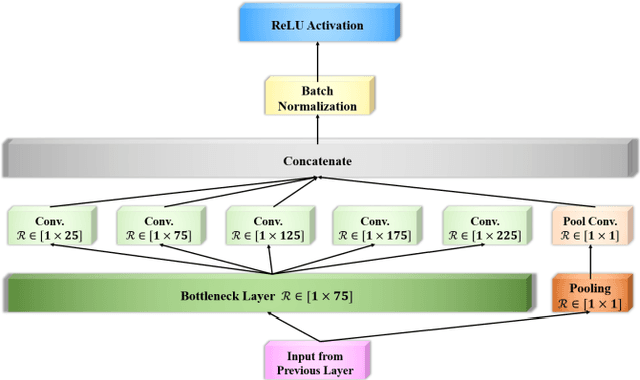
Classification of EEG-based motor imagery (MI) is a crucial non-invasive application in brain-computer interface (BCI) research. This paper proposes a novel convolutional neural network (CNN) architecture for accurate and robust EEG-based MI classification that outperforms the state-of-the-art methods. The proposed CNN model, namely EEG-Inception, is built on the backbone of the Inception-Time network, which showed to be highly efficient and accurate for time-series classification. Also, the proposed network is an end-to-end classification, as it takes the raw EEG signals as the input and does not require complex EEG signal-preprocessing. Furthermore, this paper proposes a novel data augmentation method for EEG signals to enhance the accuracy, at least by 3%, and reduce overfitting with limited BCI datasets. The proposed model outperforms all the state-of-the-art methods by achieving the average accuracy of 88.4% and 88.6% on the 2008 BCI Competition IV 2a (four-classes) and 2b datasets (binary-classes), respectively. Furthermore, it takes less than 0.025 seconds to test a sample suitable for real-time processing. Moreover, the classification standard deviation for nine different subjects achieves the lowest value of 5.5 for the 2b dataset and 7.1 for the 2a dataset, which validates that the proposed method is highly robust. From the experiment results, it can be inferred that the EEG-Inception network exhibits a strong potential as a subject-independent classifier for EEG-based MI tasks.
Suspicious Massive Registration Detection via Dynamic Heterogeneous Graph Neural Networks
Dec 20, 2020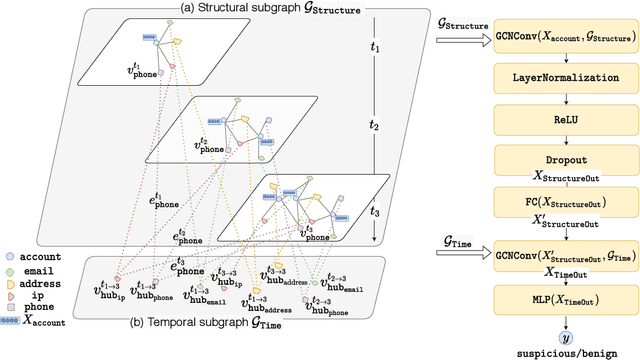



Massive account registration has raised concerns on risk management in e-commerce companies, especially when registration increases rapidly within a short time frame. To monitor these registrations constantly and minimize the potential loss they might incur, detecting massive registration and predicting their riskiness are necessary. In this paper, we propose a Dynamic Heterogeneous Graph Neural Network framework to capture suspicious massive registrations (DHGReg). We first construct a dynamic heterogeneous graph from the registration data, which is composed of a structural subgraph and a temporal subgraph. Then, we design an efficient architecture to predict suspicious/benign accounts. Our proposed model outperforms the baseline models and is computationally efficient in processing a dynamic heterogeneous graph constructed from a real-world dataset. In practice, the DHGReg framework would benefit the detection of suspicious registration behaviors at an early stage.
Efficient Automatic CASH via Rising Bandits
Dec 08, 2020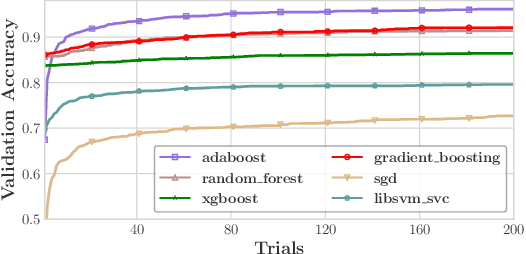
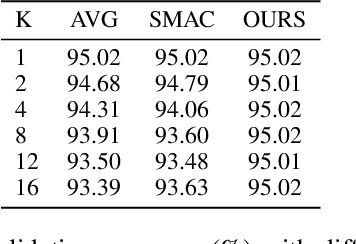

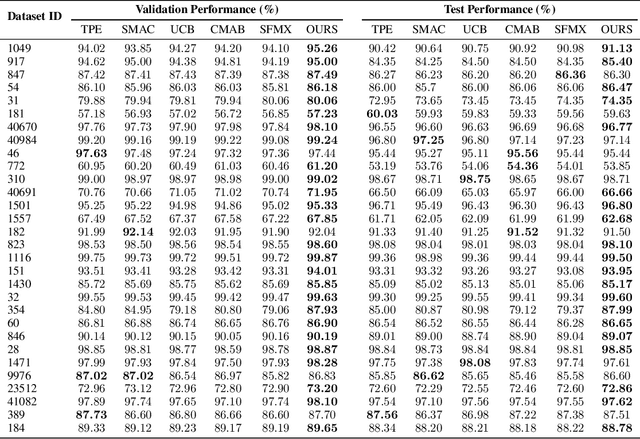
The Combined Algorithm Selection and Hyperparameter optimization (CASH) is one of the most fundamental problems in Automatic Machine Learning (AutoML). The existing Bayesian optimization (BO) based solutions turn the CASH problem into a Hyperparameter Optimization (HPO) problem by combining the hyperparameters of all machine learning (ML) algorithms, and use BO methods to solve it. As a result, these methods suffer from the low-efficiency problem due to the huge hyperparameter space in CASH. To alleviate this issue, we propose the alternating optimization framework, where the HPO problem for each ML algorithm and the algorithm selection problem are optimized alternately. In this framework, the BO methods are used to solve the HPO problem for each ML algorithm separately, incorporating a much smaller hyperparameter space for BO methods. Furthermore, we introduce Rising Bandits, a CASH-oriented Multi-Armed Bandits (MAB) variant, to model the algorithm selection in CASH. This framework can take the advantages of both BO in solving the HPO problem with a relatively small hyperparameter space and the MABs in accelerating the algorithm selection. Moreover, we further develop an efficient online algorithm to solve the Rising Bandits with provably theoretical guarantees. The extensive experiments on 30 OpenML datasets demonstrate the superiority of the proposed approach over the competitive baselines.
MFES-HB: Efficient Hyperband with Multi-Fidelity Quality Measurements
Dec 05, 2020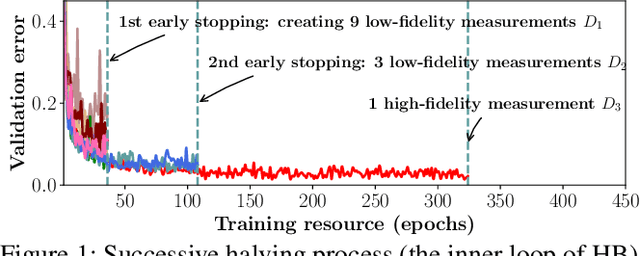
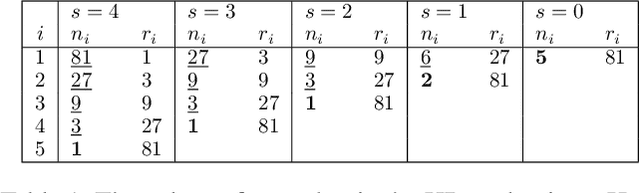
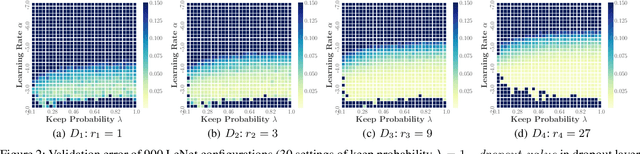

Hyperparameter optimization (HPO) is a fundamental problem in automatic machine learning (AutoML). However, due to the expensive evaluation cost of models (e.g., training deep learning models or training models on large datasets), vanilla Bayesian optimization (BO) is typically computationally infeasible. To alleviate this issue, Hyperband (HB) utilizes the early stopping mechanism to speed up configuration evaluations by terminating those badly-performing configurations in advance. This leads to two kinds of quality measurements: (1) many low-fidelity measurements for configurations that get early-stopped, and (2) few high-fidelity measurements for configurations that are evaluated without being early stopped. The state-of-the-art HB-style method, BOHB, aims to combine the benefits of both BO and HB. Instead of sampling configurations randomly in HB, BOHB samples configurations based on a BO surrogate model, which is constructed with the high-fidelity measurements only. However, the scarcity of high-fidelity measurements greatly hampers the efficiency of BO to guide the configuration search. In this paper, we present MFES-HB, an efficient Hyperband method that is capable of utilizing both the high-fidelity and low-fidelity measurements to accelerate the convergence of HPO tasks. Designing MFES-HB is not trivial as the low-fidelity measurements can be biased yet informative to guide the configuration search. Thus we propose to build a Multi- Fidelity Ensemble Surrogate (MFES) based on the generalized Product of Experts framework, which can integrate useful information from multi-fidelity measurements effectively. The empirical studies on the real-world AutoML tasks demonstrate that MFES-HB can achieve 3.3-8.9x speedups over the state-of-the-art approach - BOHB.
Multi-stage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images
Dec 01, 2020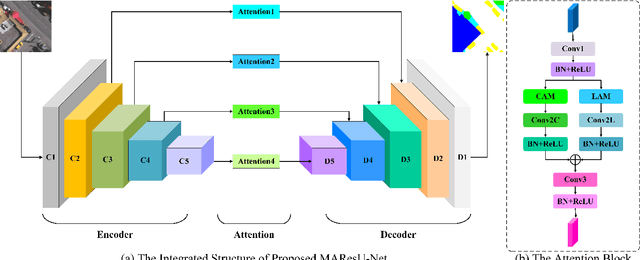
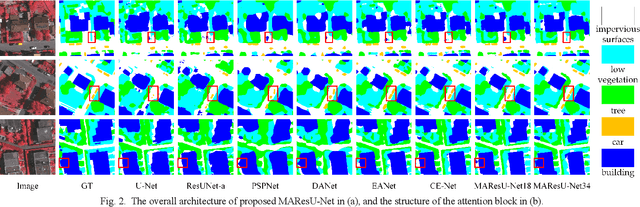
The attention mechanism can refine the extracted feature maps and boost the classification performance of the deep network, which has become an essential technique in computer vision and natural language processing. However, the memory and computational costs of the dot-product attention mechanism increase quadratically with the spatio-temporal size of the input. Such growth hinders the usage of attention mechanisms considerably in application scenarios with large-scale inputs. In this Letter, we propose a Linear Attention Mechanism (LAM) to address this issue, which is approximately equivalent to dot-product attention with computational efficiency. Such a design makes the incorporation between attention mechanisms and deep networks much more flexible and versatile. Based on the proposed LAM, we re-factor the skip connections in the raw U-Net and design a Multi-stage Attention ResU-Net (MAResU-Net) for semantic segmentation from fine-resolution remote sensing images. Experiments conducted on the Vaihingen dataset demonstrated the effectiveness and efficiency of our MAResU-Net. Open-source code is available at https://github.com/lironui/Multistage-Attention-ResU-Net.
xFraud: Explainable Fraud Transaction Detection on Heterogeneous Graphs
Nov 24, 2020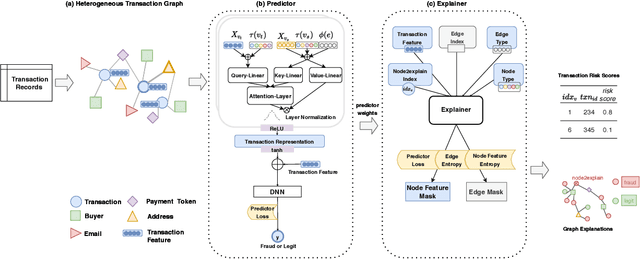


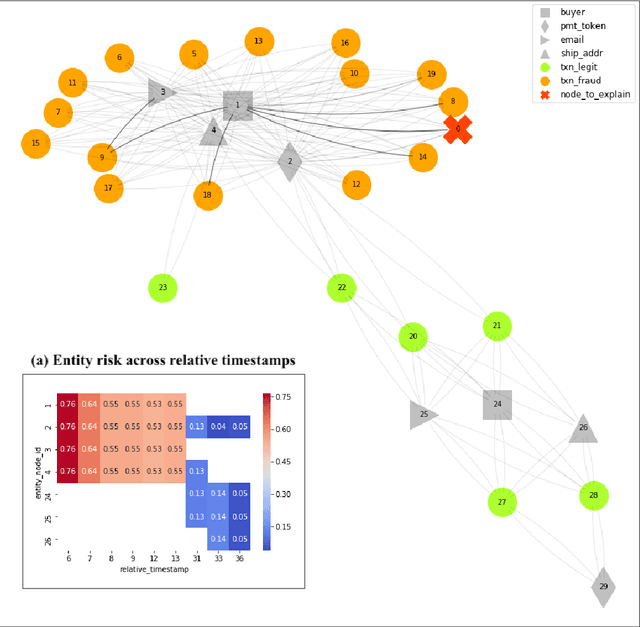
At online retail platforms, it is crucial to actively detect risks of fraudulent transactions to improve our customer experience, minimize loss, and prevent unauthorized chargebacks. Traditional rule-based methods and simple feature-based models are either inefficient or brittle and uninterpretable. The graph structure that exists among the heterogeneous typed entities of the transaction logs is informative and difficult to fake. To utilize the heterogeneous graph relationships and enrich the explainability, we present xFraud, an explainable Fraud transaction prediction system. xFraud is composed of a predictor which learns expressive representations for malicious transaction detection from the heterogeneous transaction graph via a self-attentive heterogeneous graph neural network, and an explainer that generates meaningful and human understandable explanations from graphs to facilitate further process in business unit. In our experiments with xFraud on two real transaction networks with up to ten millions transactions, we are able to achieve an area under a curve (AUC) score that outperforms baseline models and graph embedding methods. In addition, we show how the explainer could benefit the understanding towards model predictions and enhance model trustworthiness for real-world fraud transaction cases.