 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Multi-Modal Sequential Recommendation
Apr 26, 2023



With the increasing development of e-commerce and online services, personalized recommendation systems have become crucial for enhancing user satisfaction and driving business revenue. Traditional sequential recommendation methods that rely on explicit item IDs encounter challenges in handling item cold start and domain transfer problems. Recent approaches have attempted to use modal features associated with items as a replacement for item IDs, enabling the transfer of learned knowledge across different datasets. However, these methods typically calculate the correlation between the model's output and item embeddings, which may suffer from inconsistencies between high-level feature vectors and low-level feature embeddings, thereby hindering further model learning. To address this issue, we propose a dual-tower retrieval architecture for sequence recommendation. In this architecture, the predicted embedding from the user encoder is used to retrieve the generated embedding from the item encoder, thereby alleviating the issue of inconsistent feature levels. Moreover, in order to further improve the retrieval performance of the model, we also propose a self-supervised multi-modal pretraining method inspired by the consistency property of contrastive learning. This pretraining method enables the model to align various feature combinations of items, thereby effectively generalizing to diverse datasets with different item features. We evaluate the proposed method on five publicly available datasets and conduct extensive experiments. The results demonstrate significant performance improvement of our method.
WizardLM: Empowering Large Language Models to Follow Complex Instructions
Apr 24, 2023



Training large language models (LLM) with open-domain instruction following data brings colossal success. However, manually creating such instruction data is very time-consuming and labor-intensive. Moreover, humans may struggle to produce high-complexity instructions. In this paper, we show an avenue for creating large amounts of instruction data with varying levels of complexity using LLM instead of humans. Starting with an initial set of instructions, we use our proposed Evol-Instruct to rewrite them step by step into more complex instructions. Then, we mix all generated instruction data to fine-tune LLaMA. We call the resulting model WizardLM. Human evaluations on a complexity-balanced test bed show that instructions from Evol-Instruct are superior to human-created ones. By analyzing the human evaluation results of the high complexity part, we demonstrate that outputs from our WizardLM model are preferred to outputs from OpenAI ChatGPT. Even though WizardLM still lags behind ChatGPT in some aspects, our findings suggest that fine-tuning with AI-evolved instructions is a promising direction for enhancing large language models. Our codes and generated data are public at https://github.com/nlpxucan/WizardLM
LexLIP: Lexicon-Bottlenecked Language-Image Pre-Training for Large-Scale Image-Text Retrieval
Feb 06, 2023Image-text retrieval (ITR) is a task to retrieve the relevant images/texts, given the query from another modality. The conventional dense retrieval paradigm relies on encoding images and texts into dense representations using dual-stream encoders, however, it faces challenges with low retrieval speed in large-scale retrieval scenarios. In this work, we propose the lexicon-weighting paradigm, where sparse representations in vocabulary space are learned for images and texts to take advantage of the bag-of-words models and efficient inverted indexes, resulting in significantly reduced retrieval latency. A crucial gap arises from the continuous nature of image data, and the requirement for a sparse vocabulary space representation. To bridge this gap, we introduce a novel pre-training framework, Lexicon-Bottlenecked Language-Image Pre-Training (LexLIP), that learns importance-aware lexicon representations. This framework features lexicon-bottlenecked modules between the dual-stream encoders and weakened text decoders, allowing for constructing continuous bag-of-words bottlenecks to learn lexicon-importance distributions. Upon pre-training with same-scale data, our LexLIP achieves state-of-the-art performance on two benchmark ITR datasets, MSCOCO and Flickr30k. Furthermore, in large-scale retrieval scenarios, LexLIP outperforms CLIP with a 5.5 ~ 221.3X faster retrieval speed and 13.2 ~ 48.8X less index storage memory.
Fine-Grained Distillation for Long Document Retrieval
Dec 20, 2022



Long document retrieval aims to fetch query-relevant documents from a large-scale collection, where knowledge distillation has become de facto to improve a retriever by mimicking a heterogeneous yet powerful cross-encoder. However, in contrast to passages or sentences, retrieval on long documents suffers from the scope hypothesis that a long document may cover multiple topics. This maximizes their structure heterogeneity and poses a granular-mismatch issue, leading to an inferior distillation efficacy. In this work, we propose a new learning framework, fine-grained distillation (FGD), for long-document retrievers. While preserving the conventional dense retrieval paradigm, it first produces global-consistent representations crossing different fine granularity and then applies multi-granular aligned distillation merely during training. In experiments, we evaluate our framework on two long-document retrieval benchmarks, which show state-of-the-art performance.
Adam: Dense Retrieval Distillation with Adaptive Dark Examples
Dec 20, 2022To improve the performance of the dual-encoder retriever, one effective approach is knowledge distillation from the cross-encoder ranker. Existing works construct the candidate passages following the supervised learning setting where a query is paired with a positive passage and a batch of negatives. However, through empirical observation, we find that even the hard negatives from advanced methods are still too trivial for the teacher to distinguish, preventing the teacher from transferring abundant dark knowledge to the student through its soft label. To alleviate this issue, we propose ADAM, a knowledge distillation framework that can better transfer the dark knowledge held in the teacher with Adaptive Dark exAMples. Different from previous works that only rely on one positive and hard negatives as candidate passages, we create dark examples that all have moderate relevance to the query through mixing-up and masking in discrete space. Furthermore, as the quality of knowledge held in different training instances varies as measured by the teacher's confidence score, we propose a self-paced distillation strategy that adaptively concentrates on a subset of high-quality instances to conduct our dark-example-based knowledge distillation to help the student learn better. We conduct experiments on two widely-used benchmarks and verify the effectiveness of our method.
Latent User Intent Modeling for Sequential Recommenders
Nov 17, 2022Sequential recommender models are essential components of modern industrial recommender systems. These models learn to predict the next items a user is likely to interact with based on his/her interaction history on the platform. Most sequential recommenders however lack a higher-level understanding of user intents, which often drive user behaviors online. Intent modeling is thus critical for understanding users and optimizing long-term user experience. We propose a probabilistic modeling approach and formulate user intent as latent variables, which are inferred based on user behavior signals using variational autoencoders (VAE). The recommendation policy is then adjusted accordingly given the inferred user intent. We demonstrate the effectiveness of the latent user intent modeling via offline analyses as well as live experiments on a large-scale industrial recommendation platform.
MMDialog: A Large-scale Multi-turn Dialogue Dataset Towards Multi-modal Open-domain Conversation
Nov 16, 2022



Responding with multi-modal content has been recognized as an essential capability for an intelligent conversational agent. In this paper, we introduce the MMDialog dataset to better facilitate multi-modal conversation. MMDialog is composed of a curated set of 1.08 million real-world dialogues with 1.53 million unique images across 4,184 topics. MMDialog has two main and unique advantages. First, it is the largest multi-modal conversation dataset by the number of dialogues by 88x. Second, it contains massive topics to generalize the open-domain. To build engaging dialogue system with this dataset, we propose and normalize two response producing tasks based on retrieval and generative scenarios. In addition, we build two baselines for above tasks with state-of-the-art techniques and report their experimental performance. We also propose a novel evaluation metric MM-Relevance to measure the multi-modal responses. Our dataset and scripts are available in https://github.com/victorsungo/MMDialog.
Reward Shaping for User Satisfaction in a REINFORCE Recommender
Sep 30, 2022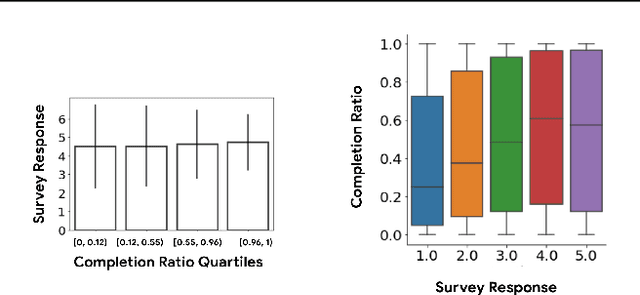
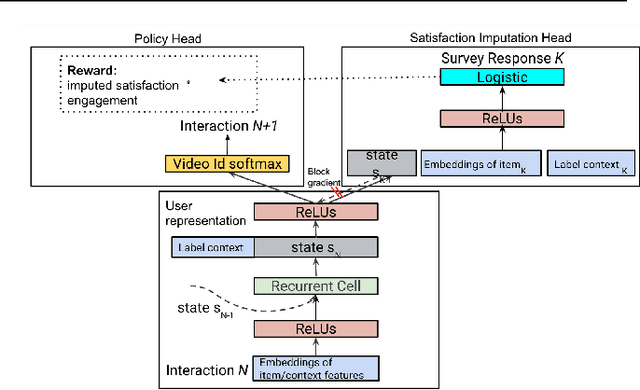
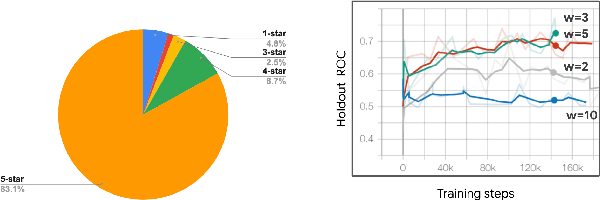
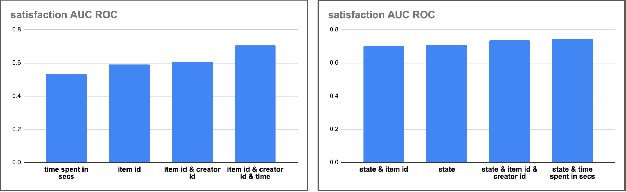
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.
LexMAE: Lexicon-Bottlenecked Pretraining for Large-Scale Retrieval
Aug 31, 2022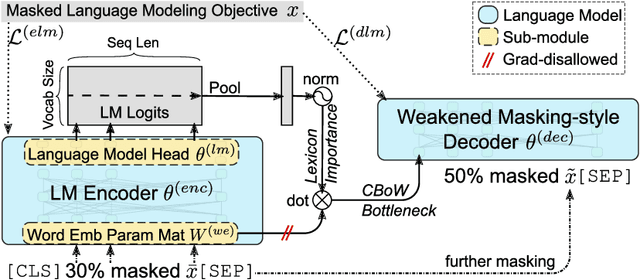
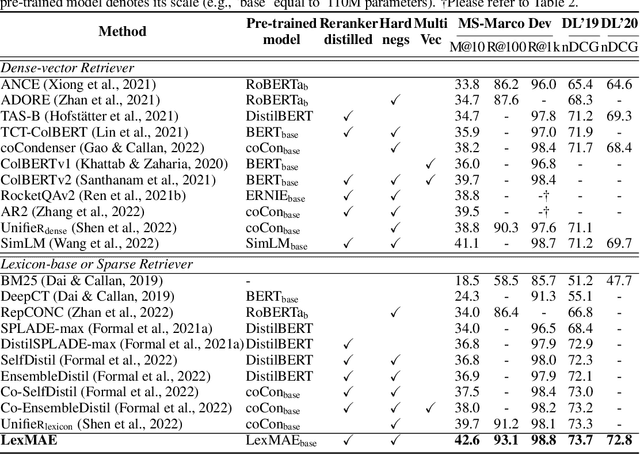
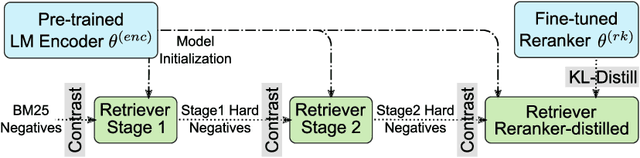
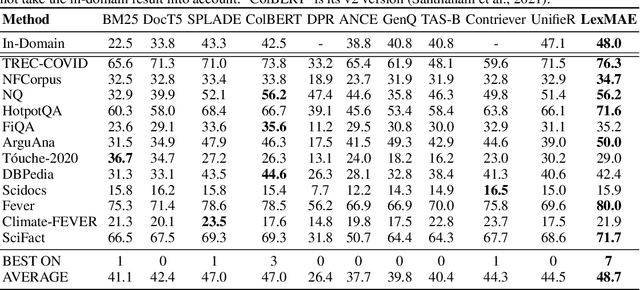
In large-scale retrieval, the lexicon-weighting paradigm, learning weighted sparse representations in vocabulary space, has shown promising results with high quality and low latency. Despite it deeply exploiting the lexicon-representing capability of pre-trained language models, a crucial gap remains between language modeling and lexicon-weighting retrieval -- the former preferring certain or low-entropy words whereas the latter favoring pivot or high-entropy words -- becoming the main barrier to lexicon-weighting performance for large-scale retrieval. To bridge this gap, we propose a brand-new pre-training framework, lexicon-bottlenecked masked autoencoder (LexMAE), to learn importance-aware lexicon representations. Essentially, we present a lexicon-bottlenecked module between a normal language modeling encoder and a weakened decoder, where a continuous bag-of-words bottleneck is constructed to learn a lexicon-importance distribution in an unsupervised fashion. The pre-trained LexMAE is readily transferred to the lexicon-weighting retrieval via fine-tuning, achieving 42.6\% MRR@10 with 45.83 QPS on a CPU machine for the passage retrieval benchmark, MS-Marco. And LexMAE shows state-of-the-art zero-shot transfer capability on BEIR benchmark with 12 datasets.
LED: Lexicon-Enlightened Dense Retriever for Large-Scale Retrieval
Aug 29, 2022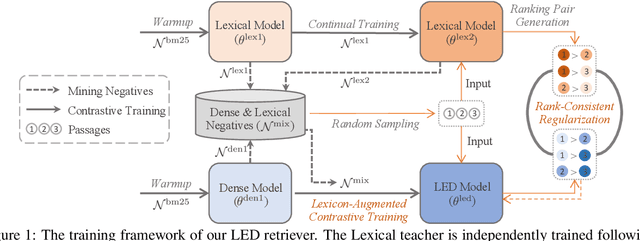
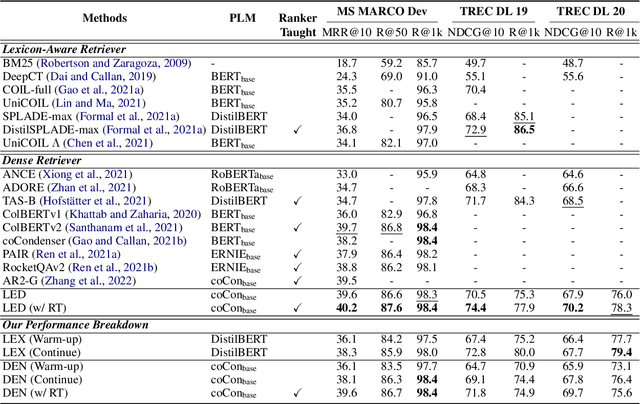
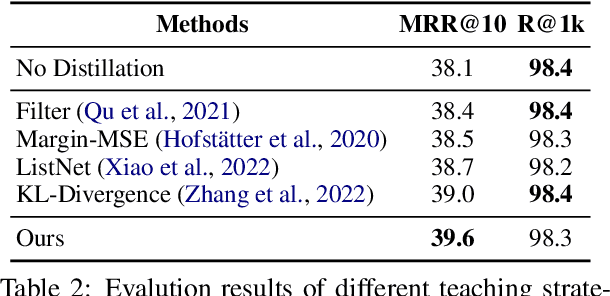
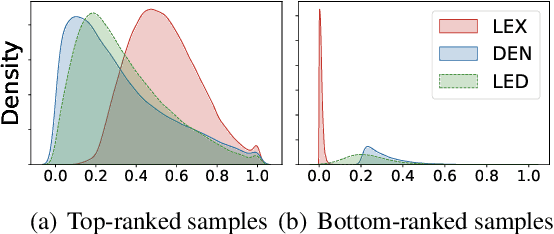
Retrieval models based on dense representations in semantic space have become an indispensable branch for first-stage retrieval. These retrievers benefit from surging advances in representation learning towards compressive global sequence-level embeddings. However, they are prone to overlook local salient phrases and entity mentions in texts, which usually play pivot roles in first-stage retrieval. To mitigate this weakness, we propose to make a dense retriever align a well-performing lexicon-aware representation model. The alignment is achieved by weakened knowledge distillations to enlighten the retriever via two aspects -- 1) a lexicon-augmented contrastive objective to challenge the dense encoder and 2) a pair-wise rank-consistent regularization to make dense model's behavior incline to the other. We evaluate our model on three public benchmarks, which shows that with a comparable lexicon-aware retriever as the teacher, our proposed dense one can bring consistent and significant improvements, and even outdo its teacher. In addition, we found our improvement on the dense retriever is complementary to the standard ranker distillation, which can further lift state-of-the-art performance.