 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Prior Denoising for Smooth Real-Time Chunking
May 25, 2026Real-time chunking (RTC) lets chunked action policies operate under inference delay by conditioning a newly generated action chunk on actions already committed by the previous chunk. Training-time RTC simulates this delay during learning and avoids expensive guidance at deployment, but its binary prefix mask treats all non-prefix tokens as fully unconstrained. This under-models asynchronous execution: early overlap actions are fixed, while later overlap actions remain editable but should still stay close to the previous plan. We propose Soft RTC, a training-time RTC generalization based on action-prior denoising. Soft RTC constructs corrupted overlap tokens from partially denoised states instead of pure noise and injects the aligned previous chunk as the same prior during inference through a lightweight token-wise blending rule. On the 12 released large Kinetix levels, a short soft window nearly matches hard training-time RTC in overall solve rate (0.809 vs. 0.815), while a medium window reduces high-delay action delta and jerk by 9.1% and 9.6% relative to hard RTC. Both variants keep near-naive runtime, unlike inference-time RTC baselines. A small preliminary real-robot sorting study provides additional evidence that training-time RTC can improve completion and that Soft RTC gives the lowest commanded-action finite-difference metrics among the tested policies.
Building informative materials datasets beyond targeted objectives
May 06, 2026Materials science data collection can be expensive, making the reuse and long-term utility of datasets critical important for future discovery campaigns. In practice, researchers prioritize a subset of properties due to research interests. However, ignoring a subset of outcomes in data collection campaigns potentially generate datasets poorly suited for future learning tasks. Here, we present a framework for dataset construction that maximizes informativeness for target properties of interest while preserving performance on untargeted ones. Our approach uses diversity-aware selection to ensure broad coverage of the materials space. In noisy experimental dataset construction, we find that without our diversity-aware framework, prediction performance on untargeted properties can degrade by up to 40% relative to random sampling, whereas applying our framework yields improvements of up to 10% . For targeted properties, performance can degrade with respect to random sampling by up to 12.5% without diversity, while our framework achieves gains of up to 25%. Incorporating diversity into dataset construction not only preserves informativeness for the targeted properties, but also improves materials coverage for potential future objectives. As a result, the constructed datasets remain broadly informative across considered and unconsidered outcomes, ensuring unbiased quality entries and mitigating cold-start limitations in subsequent modeling and discovery campaigns.
From Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
Two Teachers Better Than One: Hardware-Physics Co-Guided Distributed Scientific Machine Learning
Mar 10, 2026Scientific machine learning (SciML) is increasingly applied to in-field processing, controlling, and monitoring; however, wide-area sensing, real-time demands, and strict energy and reliability constraints make centralized SciML implementation impractical. Most SciML models assume raw data aggregation at a central node, incurring prohibitively high communication latency and energy costs; yet, distributing models developed for general-purpose ML often breaks essential physical principles, resulting in degraded performance. To address these challenges, we introduce EPIC, a hardware- and physics-co-guided distributed SciML framework, using full-waveform inversion (FWI) as a representative task. EPIC performs lightweight local encoding on end devices and physics-aware decoding at a central node. By transmitting compact latent features rather than high-volume raw data and by using cross-attention to capture inter-receiver wavefield coupling, EPIC significantly reduces communication cost while preserving physical fidelity. Evaluated on a distributed testbed with five end devices and one central node, and across 10 datasets from OpenFWI, EPIC reduces latency by 8.9$\times$ and communication energy by 33.8$\times$, while even improving reconstruction fidelity on 8 out of 10 datasets.
The Master-Slave Encoder Model for Improving Patent Text Summarization: A New Approach to Combining Specifications and Claims
Nov 21, 2024



In order to solve the problem of insufficient generation quality caused by traditional patent text abstract generation models only originating from patent specifications, the problem of new terminology OOV caused by rapid patent updates, and the problem of information redundancy caused by insufficient consideration of the high professionalism, accuracy, and uniqueness of patent texts, we proposes a patent text abstract generation model (MSEA) based on a master-slave encoder architecture; Firstly, the MSEA model designs a master-slave encoder, which combines the instructions in the patent text with the claims as input, and fully explores the characteristics and details between the two through the master-slave encoder; Then, the model enhances the consideration of new technical terms in the input sequence based on the pointer network, and further enhances the correlation with the input text by re weighing the "remembered" and "for-gotten" parts of the input sequence from the encoder; Finally, an enhanced repetition suppression mechanism for patent text was introduced to ensure accurate and non redundant abstracts generated. On a publicly available patent text dataset, compared to the state-of-the-art model, Improved Multi-Head Attention Mechanism (IMHAM), the MSEA model achieves an improvement of 0.006, 0.005, and 0.005 in Rouge-1, Rouge-2, and Rouge-L scores, respectively. MSEA leverages the characteristics of patent texts to effectively enhance the quality of patent text generation, demonstrating its advancement and effectiveness in the experiments.
Reward Shaping for User Satisfaction in a REINFORCE Recommender
Sep 30, 2022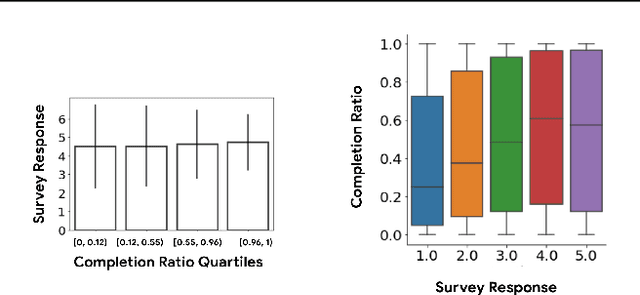
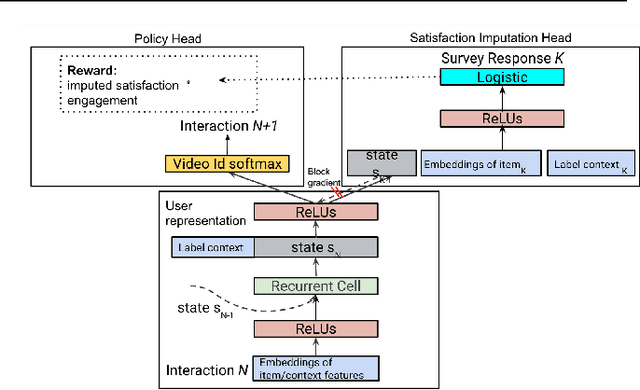
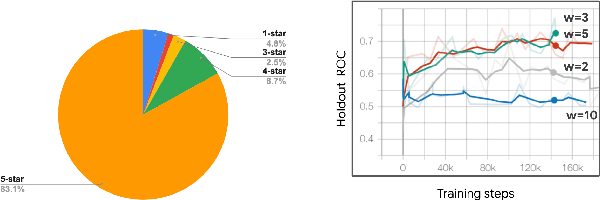
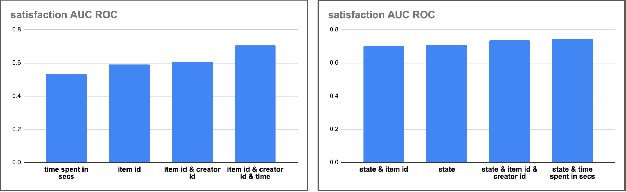
How might we design Reinforcement Learning (RL)-based recommenders that encourage aligning user trajectories with the underlying user satisfaction? Three research questions are key: (1) measuring user satisfaction, (2) combatting sparsity of satisfaction signals, and (3) adapting the training of the recommender agent to maximize satisfaction. For measurement, it has been found that surveys explicitly asking users to rate their experience with consumed items can provide valuable orthogonal information to the engagement/interaction data, acting as a proxy to the underlying user satisfaction. For sparsity, i.e, only being able to observe how satisfied users are with a tiny fraction of user-item interactions, imputation models can be useful in predicting satisfaction level for all items users have consumed. For learning satisfying recommender policies, we postulate that reward shaping in RL recommender agents is powerful for driving satisfying user experiences. Putting everything together, we propose to jointly learn a policy network and a satisfaction imputation network: The role of the imputation network is to learn which actions are satisfying to the user; while the policy network, built on top of REINFORCE, decides which items to recommend, with the reward utilizing the imputed satisfaction. We use both offline analysis and live experiments in an industrial large-scale recommendation platform to demonstrate the promise of our approach for satisfying user experiences.