 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal and Multi-Agent Systems Meet Rationality: A Survey
Jun 01, 2024Rationality is the quality of being guided by reason, characterized by logical thinking and decision-making that align with evidence and logical rules. This quality is essential for effective problem-solving, as it ensures that solutions are well-founded and systematically derived. Despite the advancements of large language models (LLMs) in generating human-like text with remarkable accuracy, they present biases inherited from the training data, inconsistency across different contexts, and difficulty understanding complex scenarios involving multiple layers of context. Therefore, recent research attempts to leverage the strength of multiple agents working collaboratively with various types of data and tools for enhanced consistency and reliability. To that end, this paper aims to understand whether multi-modal and multi-agent systems are advancing toward rationality by surveying the state-of-the-art works, identifying advancements over single-agent and single-modal systems in terms of rationality, and discussing open problems and future directions. We maintain an open repository at https://github.com/bowen-upenn/MMMA_Rationality.
Multi-Agent VQA: Exploring Multi-Agent Foundation Models in Zero-Shot Visual Question Answering
Mar 21, 2024



This work explores the zero-shot capabilities of foundation models in Visual Question Answering (VQA) tasks. We propose an adaptive multi-agent system, named Multi-Agent VQA, to overcome the limitations of foundation models in object detection and counting by using specialized agents as tools. Unlike existing approaches, our study focuses on the system's performance without fine-tuning it on specific VQA datasets, making it more practical and robust in the open world. We present preliminary experimental results under zero-shot scenarios and highlight some failure cases, offering new directions for future research.
EV-Catcher: High-Speed Object Catching Using Low-latency Event-based Neural Networks
Apr 14, 2023



Event-based sensors have recently drawn increasing interest in robotic perception due to their lower latency, higher dynamic range, and lower bandwidth requirements compared to standard CMOS-based imagers. These properties make them ideal tools for real-time perception tasks in highly dynamic environments. In this work, we demonstrate an application where event cameras excel: accurately estimating the impact location of fast-moving objects. We introduce a lightweight event representation called Binary Event History Image (BEHI) to encode event data at low latency, as well as a learning-based approach that allows real-time inference of a confidence-enabled control signal to the robot. To validate our approach, we present an experimental catching system in which we catch fast-flying ping-pong balls. We show that the system is capable of achieving a success rate of 81% in catching balls targeted at different locations, with a velocity of up to 13 m/s even on compute-constrained embedded platforms such as the Nvidia Jetson NX.
Scene Graph Generation from Hierarchical Relationship Reasoning
Mar 13, 2023This paper describes a novel approach to deducing relationships between objects in a visual scene. It explicitly exploits an informative hierarchical structure that can be imposed to divide the object and relationship categories into disjoint super-categories. Specifically, our proposed scheme implements a Bayes prediction head to jointly predict the super-category or type of relationship between the two objects, along with the detailed relationship within that super-category. This design reduces the impact of class imbalance problems. We present experimental results on the Visual Genome and OpenImage V6 datasets showing that this factorized approach allows a relatively simple model to achieve competitive performance, especially on predicate classification and zero-shot tasks.
Active Metric-Semantic Mapping by Multiple Aerial Robots
Sep 24, 2022
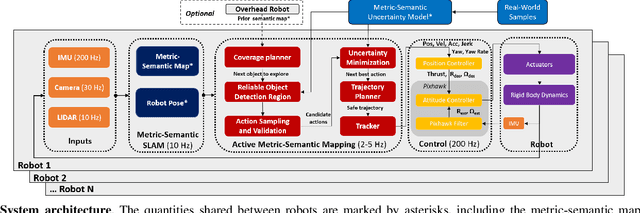
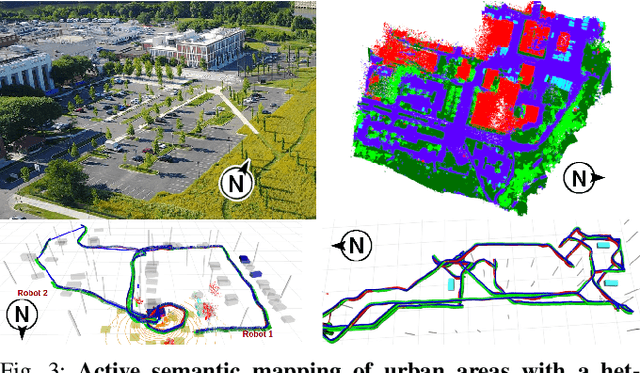
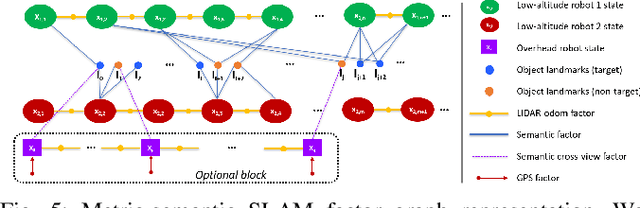
Traditional approaches for active mapping focus on building geometric maps. For most real-world applications, however, actionable information is related to semantically meaningful objects in the environment. We propose an approach to the active metric-semantic mapping problem that enables multiple heterogeneous robots to collaboratively build a map of the environment. The robots actively explore to minimize the uncertainties in both semantic (object classification) and geometric (object modeling) information. We represent the environment using informative but sparse object models, each consisting of a basic shape and a semantic class label, and characterize uncertainties empirically using a large amount of real-world data. Given a prior map, we use this model to select actions for each robot to minimize uncertainties. The performance of our algorithm is demonstrated through multi-robot experiments in diverse real-world environments. The proposed framework is applicable to a wide range of real-world problems, such as precision agriculture, infrastructure inspection, and asset mapping in factories. A demo video can be found at https://youtu.be/S86SgXi54oU.
DSOL: A Fast Direct Sparse Odometry Scheme
Mar 15, 2022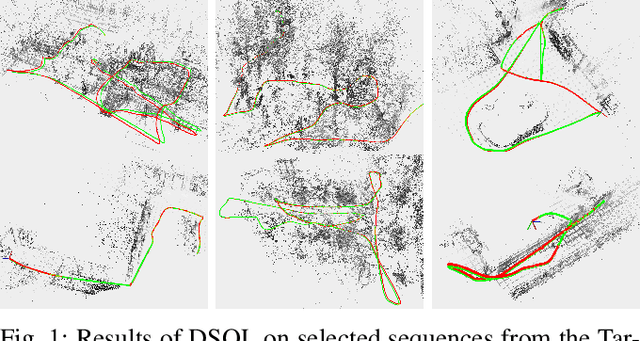


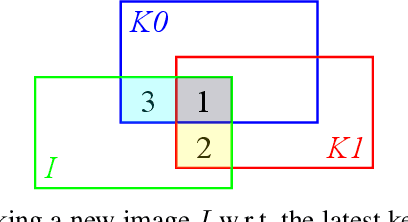
In this paper, we describe Direct Sparse Odometry Lite (DSOL), an improved version of Direct Sparse Odometry (DSO). We propose several algorithmic and implementation enhancements which speed up computation by a significant factor (on average 5x) even on resource constrained platforms. The increase in speed allows us to process images at higher frame rates, which in turn provides better results on rapid motions. Our open-source implementation is available at https://github.com/versatran01/dsol.
LLOL: Low-Latency Odometry for Spinning Lidars
Oct 04, 2021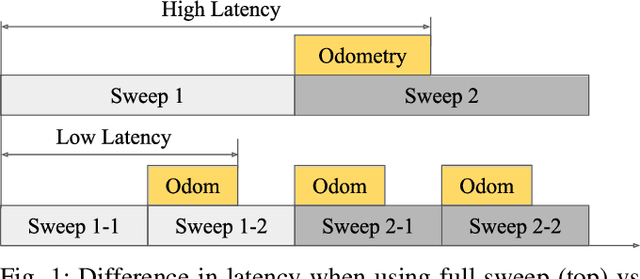


In this paper, we present a low-latency odometry system designed for spinning lidars. Many existing lidar odometry methods wait for an entire sweep from the lidar before processing the data. This introduces a large delay between the first laser firing and its pose estimate. To reduce this latency, we treat the spinning lidar as a streaming sensor and process packets as they arrive. This effectively distributes expensive operations across time, resulting in a very fast and lightweight system with much higher throughput and lower latency. Our open-source implementation is available at \url{https://github.com/versatran01/llol}.
Large-scale Autonomous Flight with Real-time Semantic SLAM under Dense Forest Canopy
Sep 19, 2021

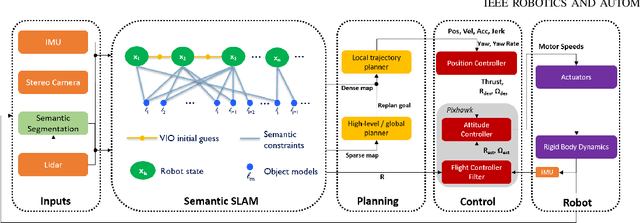
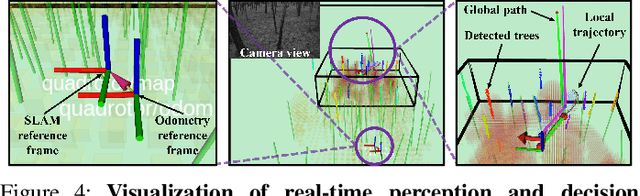
In this letter, we propose an integrated autonomous flight and semantic SLAM system that can perform long-range missions and real-time semantic mapping in highly cluttered, unstructured, and GPS-denied under-canopy environments. First, tree trunks and ground planes are detected from LIDAR scans. We use a neural network and an instance extraction algorithm to enable semantic segmentation in real time onboard the UAV. Second, detected tree trunk instances are modeled as cylinders and associated across the whole LIDAR sequence. This semantic data association constraints both robot poses as well as trunk landmark models. The output of semantic SLAM is used in state estimation, planning, and control algorithms in real time. The global planner relies on a sparse map to plan the shortest path to the global goal, and the local trajectory planner uses a small but finely discretized robot-centric map to plan a dynamically feasible and collision-free trajectory to the local goal. Both the global path and local trajectory lead to drift-corrected goals, thus helping the UAV execute its mission accurately and safely.
Bayesian Deep Basis Fitting for Depth Completion with Uncertainty
Mar 29, 2021
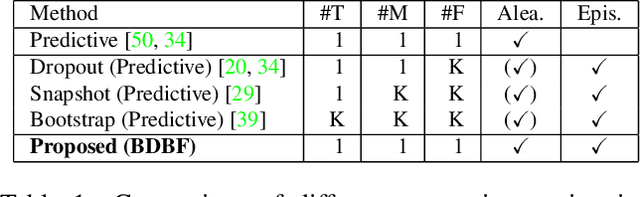
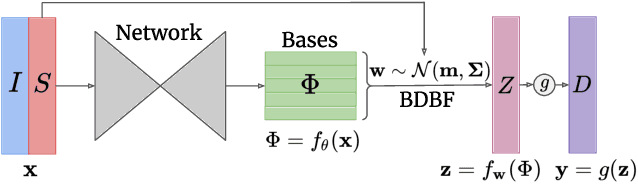

In this work we investigate the problem of uncertainty estimation for image-guided depth completion. We extend Deep Basis Fitting (DBF) for depth completion within a Bayesian evidence framework to provide calibrated per-pixel variance. The DBF approach frames the depth completion problem in terms of a network that produces a set of low-dimensional depth bases and a differentiable least squares fitting module that computes the basis weights using the sparse depths. By adopting a Bayesian treatment, our Bayesian Deep Basis Fitting (BDBF) approach is able to 1) predict high-quality uncertainty estimates and 2) enable depth completion with few or no sparse measurements. We conduct controlled experiments to compare BDBF against commonly used techniques for uncertainty estimation under various scenarios. Results show that our method produces better uncertainty estimates with accurate depth prediction.
PennSyn2Real: Training Object Recognition Models without Human Labeling
Oct 16, 2020

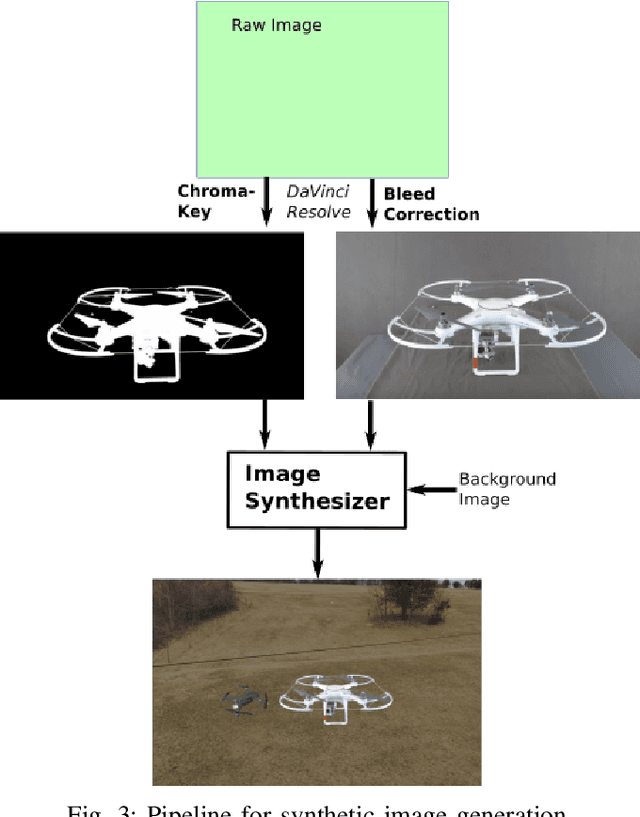
Scalable training data generation is a critical problem in deep learning. We propose PennSyn2Real - a photo-realistic synthetic dataset consisting of more than 100,000 4K images of more than 20 types of micro aerial vehicles (MAVs). The dataset can be used to generate arbitrary numbers of training images for high-level computer vision tasks such as MAV detection and classification. Our data generation framework bootstraps chroma-keying, a mature cinematography technique with a motion tracking system, providing artifact-free and curated annotated images where object orientations and lighting are controlled. This framework is easy to set up and can be applied to a broad range of objects, reducing the gap between synthetic and real-world data. We show that synthetic data generated using this framework can be directly used to train CNN models for common object recognition tasks such as detection and segmentation. We demonstrate competitive performance in comparison with training using only real images. Furthermore, bootstrapping the generated synthetic data in few-shot learning can significantly improve the overall performance, reducing the number of required training data samples to achieve the desired accuracy.