 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Attribute Compression via Successive Subspace Graph Transform
Oct 29, 2020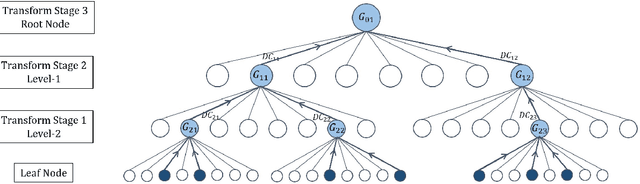
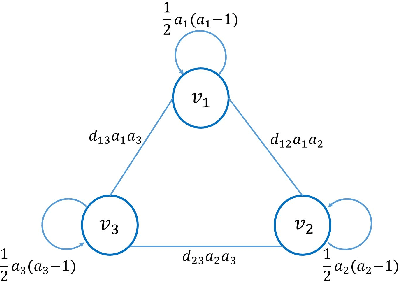
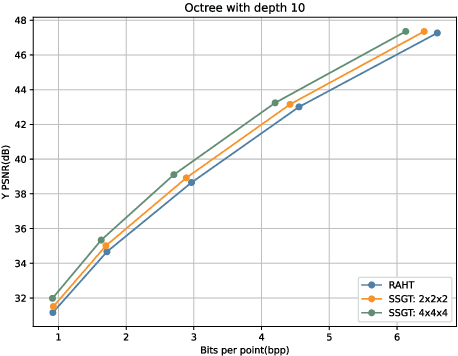

Inspired by the recently proposed successive subspace learning (SSL) principles, we develop a successive subspace graph transform (SSGT) to address point cloud attribute compression in this work. The octree geometry structure is utilized to partition the point cloud, where every node of the octree represents a point cloud subspace with a certain spatial size. We design a weighted graph with self-loop to describe the subspace and define a graph Fourier transform based on the normalized graph Laplacian. The transforms are applied to large point clouds from the leaf nodes to the root node of the octree recursively, while the represented subspace is expanded from the smallest one to the whole point cloud successively. It is shown by experimental results that the proposed SSGT method offers better R-D performances than the previous Region Adaptive Haar Transform (RAHT) method.
Constructing Multilayer Perceptrons as Piecewise Low-Order Polynomial Approximators: A Signal Processing Approach
Oct 15, 2020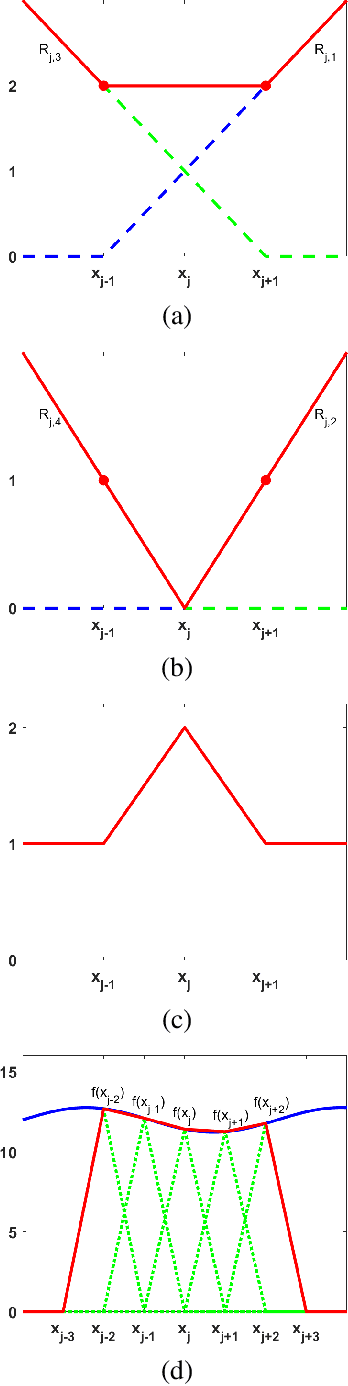
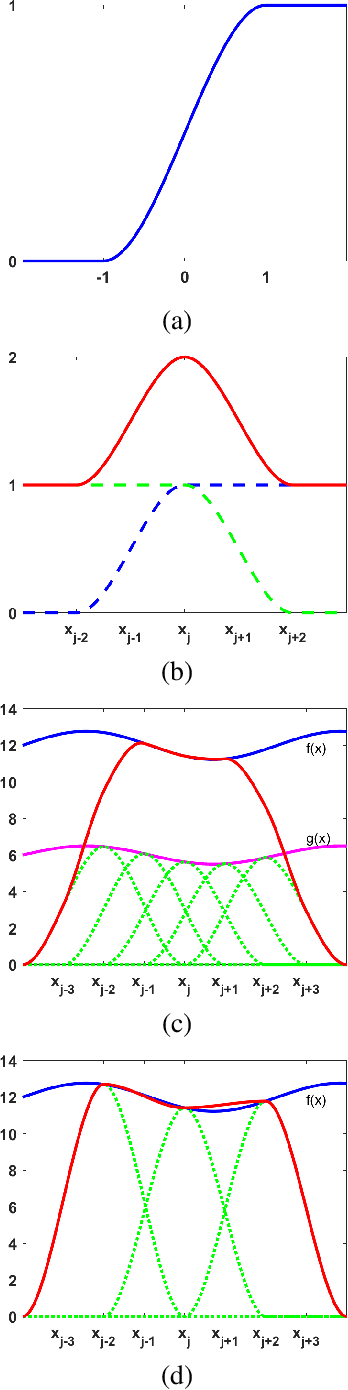
The construction of a multilayer perceptron (MLP) as a piecewise low-order polynomial approximator using a signal processing approach is presented in this work. The constructed MLP contains one input, one intermediate and one output layers. Its construction includes the specification of neuron numbers and all filter weights. Through the construction, a one-to-one correspondence between the approximation of an MLP and that of a piecewise low-order polynomial is established. Comparison between piecewise polynomial and MLP approximations is made. Since the approximation capability of piecewise low-order polynomials is well understood, our findings shed light on the universal approximation capability of an MLP.
Inductive Learning on Commonsense Knowledge Graph Completion
Sep 19, 2020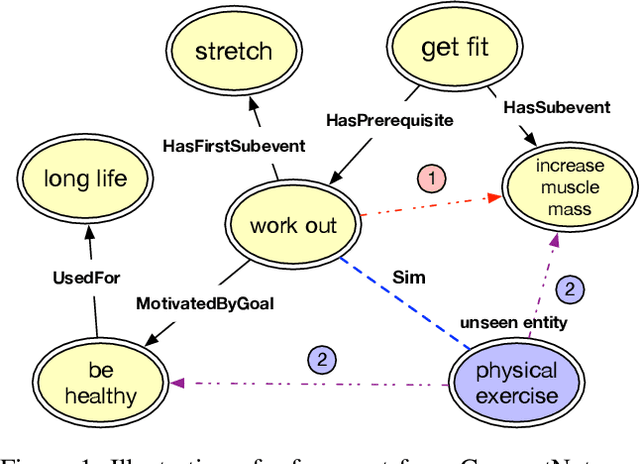

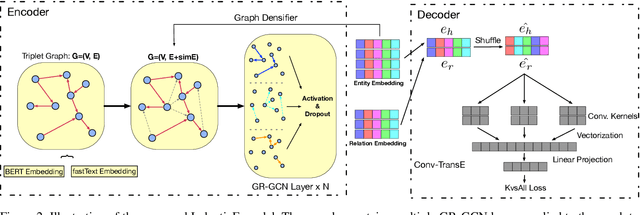
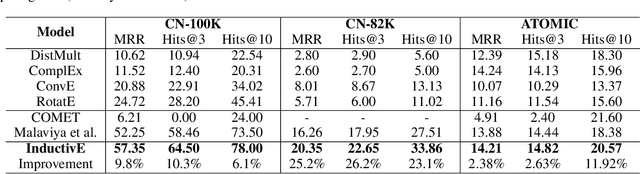
Commonsense knowledge graph (CKG) is a special type of knowledge graph (KG), where entities are composed of free-form text. However, most existing CKG completion methods focus on the setting where all the entities are presented at training time. Although this setting is standard for conventional KG completion, it has limitations for CKG completion. At test time, entities in CKGs can be unseen because they may have unseen text/names and entities may be disconnected from the training graph, since CKGs are generally very sparse. Here, we propose to study the inductive learning setting for CKG completion where unseen entities may present at test time. We develop a novel learning framework named InductivE. Different from previous approaches, InductiveE ensures the inductive learning capability by directly computing entity embeddings from raw entity attributes/text. InductiveE consists of a free-text encoder, a graph encoder, and a KG completion decoder. Specifically, the free-text encoder first extracts the textual representation of each entity based on the pre-trained language model and word embedding. The graph encoder is a gated relational graph convolutional neural network that learns from a densified graph for more informative entity representation learning. We develop a method that densifies CKGs by adding edges among semantic-related entities and provide more supportive information for unseen entities, leading to better generalization ability of entity embedding for unseen entities. Finally, inductiveE employs Conv-TransE as the CKG completion decoder. Experimental results show that InductiveE significantly outperforms state-of-the-art baselines in both standard and inductive settings on ATOMIC and ConceptNet benchmarks. InductivE performs especially well on inductive scenarios where it achieves above 48% improvement over present methods.
From Two-Class Linear Discriminant Analysis to Interpretable Multilayer Perceptron Design
Sep 09, 2020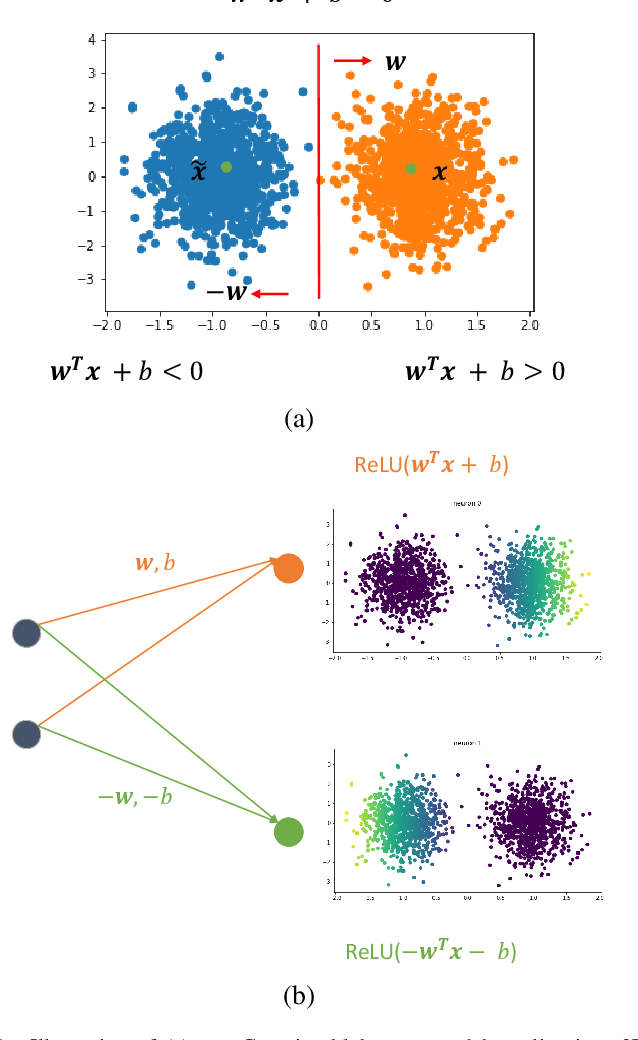
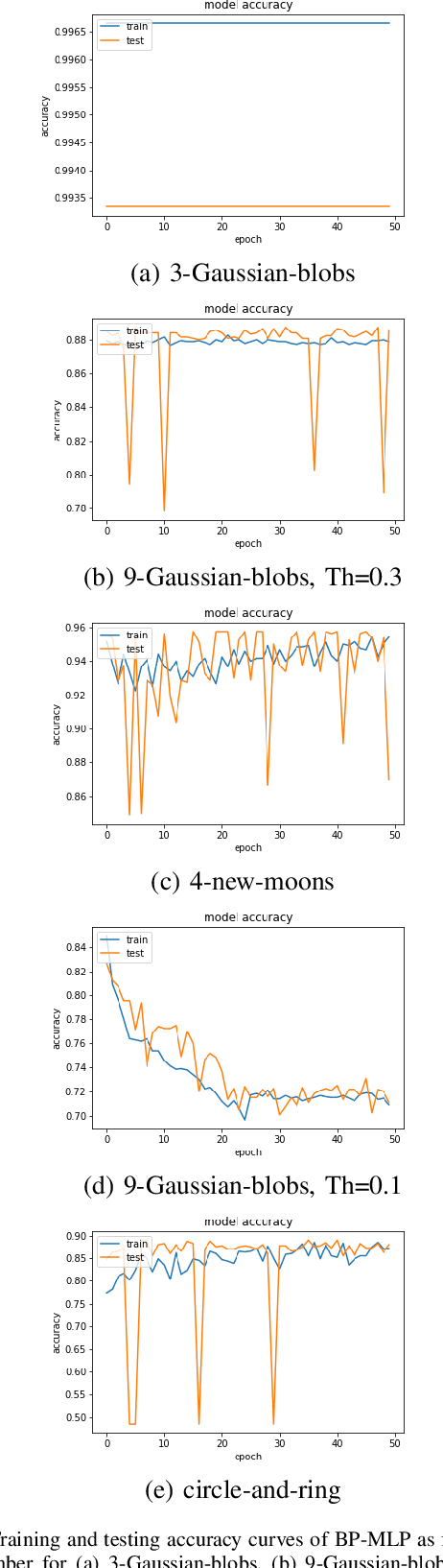
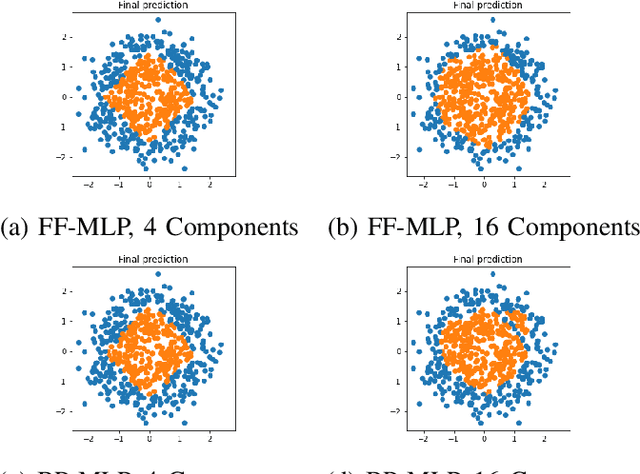
A closed-form solution exists in two-class linear discriminant analysis (LDA), which discriminates two Gaussian-distributed classes in a multi-dimensional feature space. In this work, we interpret the multilayer perceptron (MLP) as a generalization of a two-class LDA system so that it can handle an input composed by multiple Gaussian modalities belonging to multiple classes. Besides input layer $l_{in}$ and output layer $l_{out}$, the MLP of interest consists of two intermediate layers, $l_1$ and $l_2$. We propose a feedforward design that has three stages: 1) from $l_{in}$ to $l_1$: half-space partitionings accomplished by multiple parallel LDAs, 2) from $l_1$ to $l_2$: subspace isolation where one Gaussian modality is represented by one neuron, 3) from $l_2$ to $l_{out}$: class-wise subspace mergence, where each Gaussian modality is connected to its target class. Through this process, we present an automatic MLP design that can specify the network architecture (i.e., the layer number and the neuron number at a layer) and all filter weights in a feedforward one-pass fashion. This design can be generalized to an arbitrary distribution by leveraging the Gaussian mixture model (GMM). Experiments are conducted to compare the performance of the traditional backpropagation-based MLP (BP-MLP) and the new feedforward MLP (FF-MLP).
NITES: A Non-Parametric Interpretable Texture Synthesis Method
Sep 02, 2020



A non-parametric interpretable texture synthesis method, called the NITES method, is proposed in this work. Although automatic synthesis of visually pleasant texture can be achieved by deep neural networks nowadays, the associated generation models are mathematically intractable and their training demands higher computational cost. NITES offers a new texture synthesis solution to address these shortcomings. NITES is mathematically transparent and efficient in training and inference. The input is a single exemplary texture image. The NITES method crops out patches from the input and analyzes the statistical properties of these texture patches to obtain their joint spatial-spectral representations. Then, the probabilistic distributions of samples in the joint spatial-spectral spaces are characterized. Finally, numerous texture images that are visually similar to the exemplary texture image can be generated automatically. Experimental results are provided to show the superior quality of generated texture images and efficiency of the proposed NITES method in terms of both training and inference time.
Unsupervised Point Cloud Registration via Salient Points Analysis (SPA)
Sep 02, 2020



An unsupervised point cloud registration method, called salient points analysis (SPA), is proposed in this work. The proposed SPA method can register two point clouds effectively using only a small subset of salient points. It first applies the PointHop++ method to point clouds, finds corresponding salient points in two point clouds based on the local surface characteristics of points and performs registration by matching the corresponding salient points. The SPA method offers several advantages over the recent deep learning based solutions for registration. Deep learning methods such as PointNetLK and DCP train end-to-end networks and rely on full supervision (namely, ground truth transformation matrix and class label). In contrast, the SPA is completely unsupervised. Furthermore, SPA's training time and model size are much less. The effectiveness of the SPA method is demonstrated by experiments on seen and unseen classes and noisy point clouds from the ModelNet-40 dataset.
Unsupervised Feedforward Feature (UFF) Learning for Point Cloud Classification and Segmentation
Sep 02, 2020In contrast to supervised backpropagation-based feature learning in deep neural networks (DNNs), an unsupervised feedforward feature (UFF) learning scheme for joint classification and segmentation of 3D point clouds is proposed in this work. The UFF method exploits statistical correlations of points in a point cloud set to learn shape and point features in a one-pass feedforward manner through a cascaded encoder-decoder architecture. It learns global shape features through the encoder and local point features through the concatenated encoder-decoder architecture. The extracted features of an input point cloud are fed to classifiers for shape classification and part segmentation. Experiments are conducted to evaluate the performance of the UFF method. For shape classification, the UFF is superior to existing unsupervised methods and on par with state-of-the-art DNNs. For part segmentation, the UFF outperforms semi-supervised methods and performs slightly worse than DNNs.
FaceHop: A Light-Weight Low-Resolution Face Gender Classification Method
Jul 21, 2020
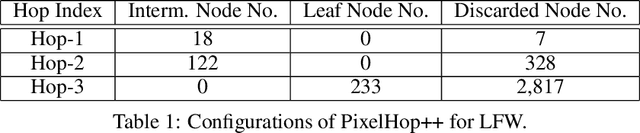
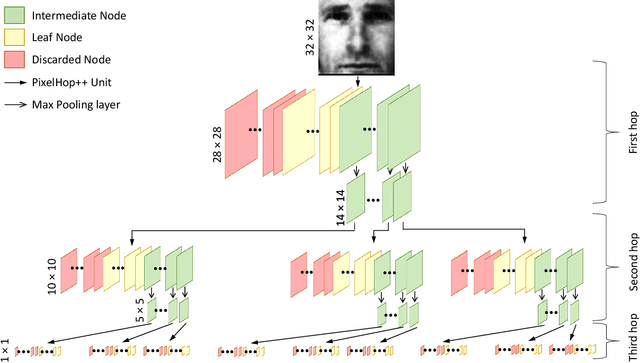
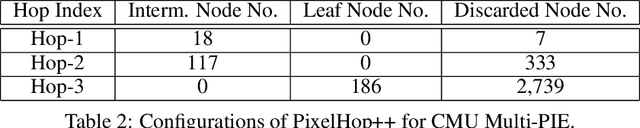
A light-weight low-resolution face gender classification method, called FaceHop, is proposed in this research. We have witnessed a rapid progress in face gender classification accuracy due to the adoption of deep learning (DL) technology. Yet, DL-based systems are not suitable for resource-constrained environments with limited networking and computing. FaceHop offers an interpretable non-parametric machine learning solution. It has desired characteristics such as a small model size, a small training data amount, low training complexity, and low resolution input images. FaceHop is developed with the successive subspace learning (SSL) principle and built upon the foundation of PixelHop++. The effectiveness of the FaceHop method is demonstrated by experiments. For gray-scale face images of resolution $32 \times 32$ in the LFW and the CMU Multi-PIE datasets, FaceHop achieves correct gender classification rates of 94.63\% and 95.12\% with model sizes of 16.9K and 17.6K parameters, respectively. It outperforms LeNet-5 in classification accuracy while LeNet-5 has a model size of 75.8K parameters.
Learning Color Compatibility in Fashion Outfits
Jul 05, 2020
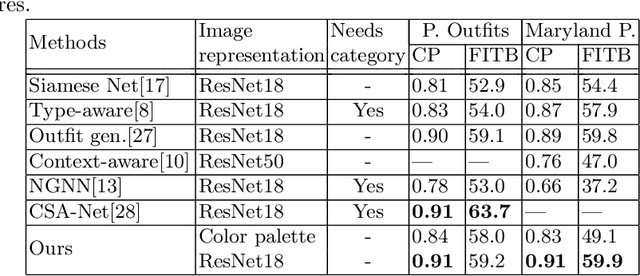
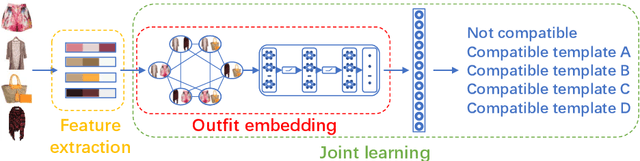
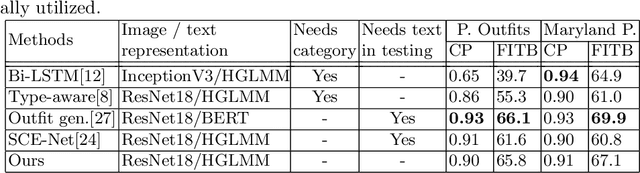
Color compatibility is important for evaluating the compatibility of a fashion outfit, yet it was neglected in previous studies. We bring this important problem to researchers' attention and present a compatibility learning framework as solution to various fashion tasks. The framework consists of a novel way to model outfit compatibility and an innovative learning scheme. Specifically, we model the outfits as graphs and propose a novel graph construction to better utilize the power of graph neural networks. Then we utilize both ground-truth labels and pseudo labels to train the compatibility model in a weakly-supervised manner.Extensive experimental results verify the importance of color compatibility alone with the effectiveness of our framework. With color information alone, our model's performance is already comparable to previous methods that use deep image features. Our full model combining the aforementioned contributions set the new state-of-the-art in fashion compatibility prediction.
Novel Human-Object Interaction Detection via Adversarial Domain Generalization
May 22, 2020
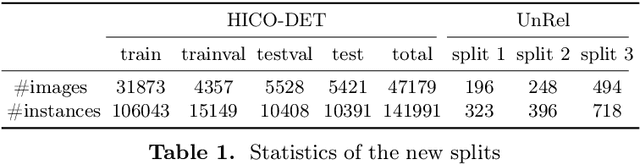
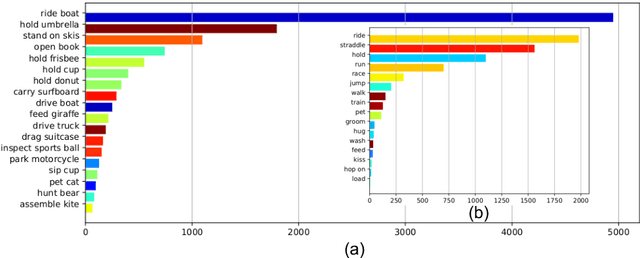
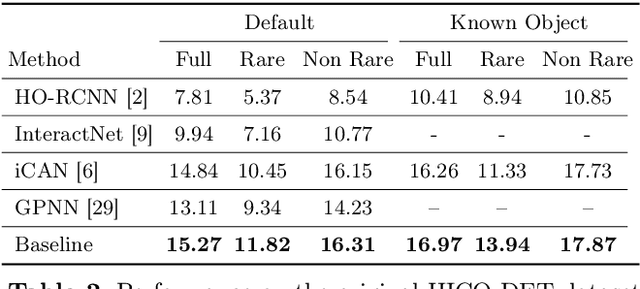
We study in this paper the problem of novel human-object interaction (HOI) detection, aiming at improving the generalization ability of the model to unseen scenarios. The challenge mainly stems from the large compositional space of objects and predicates, which leads to the lack of sufficient training data for all the object-predicate combinations. As a result, most existing HOI methods heavily rely on object priors and can hardly generalize to unseen combinations. To tackle this problem, we propose a unified framework of adversarial domain generalization to learn object-invariant features for predicate prediction. To measure the performance improvement, we create a new split of the HICO-DET dataset, where the HOIs in the test set are all unseen triplet categories in the training set. Our experiments show that the proposed framework significantly increases the performance by up to 50% on the new split of HICO-DET dataset and up to 125% on the UnRel dataset for auxiliary evaluation in detecting novel HOIs.