 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Safety Concerns of Deploying LLMs/VLMs in Robotics: Highlighting the Risks and Vulnerabilities
Feb 24, 2024



In this paper, we highlight the critical issues of robustness and safety associated with integrating large language models (LLMs) and vision-language models (VLMs) into robotics applications. Recent works have focused on using LLMs and VLMs to improve the performance of robotics tasks, such as manipulation, navigation, etc. However, such integration can introduce significant vulnerabilities, in terms of their susceptibility to adversarial attacks due to the language models, potentially leading to catastrophic consequences. By examining recent works at the interface of LLMs/VLMs and robotics, we show that it is easy to manipulate or misguide the robot's actions, leading to safety hazards. We define and provide examples of several plausible adversarial attacks, and conduct experiments on three prominent robot frameworks integrated with a language model, including KnowNo VIMA, and Instruct2Act, to assess their susceptibility to these attacks. Our empirical findings reveal a striking vulnerability of LLM/VLM-robot integrated systems: simple adversarial attacks can significantly undermine the effectiveness of LLM/VLM-robot integrated systems. Specifically, our data demonstrate an average performance deterioration of 21.2% under prompt attacks and a more alarming 30.2% under perception attacks. These results underscore the critical need for robust countermeasures to ensure the safe and reliable deployment of the advanced LLM/VLM-based robotic systems.
On the Hidden Biases of Policy Mirror Ascent in Continuous Action Spaces
Jan 31, 2022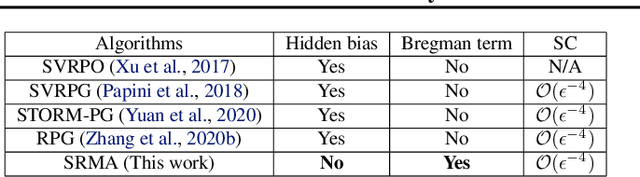

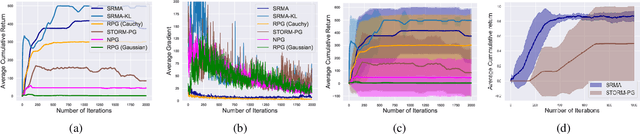
We focus on parameterized policy search for reinforcement learning over continuous action spaces. Typically, one assumes the score function associated with a policy is bounded, which fails to hold even for Gaussian policies. To properly address this issue, one must introduce an exploration tolerance parameter to quantify the region in which it is bounded. Doing so incurs a persistent bias that appears in the attenuation rate of the expected policy gradient norm, which is inversely proportional to the radius of the action space. To mitigate this hidden bias, heavy-tailed policy parameterizations may be used, which exhibit a bounded score function, but doing so can cause instability in algorithmic updates. To address these issues, in this work, we study the convergence of policy gradient algorithms under heavy-tailed parameterizations, which we propose to stabilize with a combination of mirror ascent-type updates and gradient tracking. Our main theoretical contribution is the establishment that this scheme converges with constant step and batch sizes, whereas prior works require these parameters to respectively shrink to null or grow to infinity. Experimentally, this scheme under a heavy-tailed policy parameterization yields improved reward accumulation across a variety of settings as compared with standard benchmarks.
Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases
Dec 13, 2020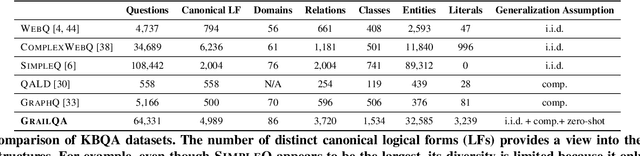
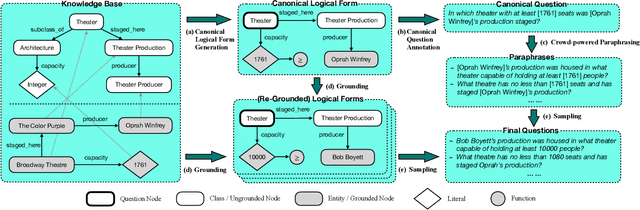

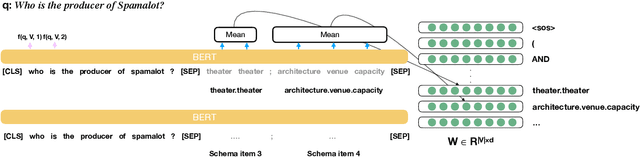
Existing studies on question answering on knowledge bases (KBQA) mainly operate with the standard i.i.d assumption, i.e., training distribution over questions is the same as the test distribution. However, i.i.d may be neither reasonably achievable nor desirable on large-scale KBs because 1) true user distribution is hard to capture and 2) randomly sample training examples from the enormous space would be highly data-inefficient. Instead, we suggest that KBQA models should have three levels of built-in generalization: i.i.d, compositional, and zero-shot. To facilitate the development of KBQA models with stronger generalization, we construct and release a new large-scale, high-quality dataset with 64,331 questions, GrailQA, and provide evaluation settings for all three levels of generalization. In addition, we propose a novel BERT-based KBQA model. The combination of our dataset and model enables us to thoroughly examine and demonstrate, for the first time, the key role of pre-trained contextual embeddings like BERT in the generalization of KBQA.
Deep Multimodal Transfer-Learned Regression in Data-Poor Domains
Jun 16, 2020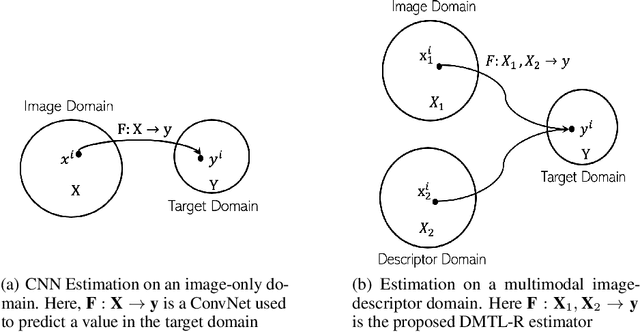
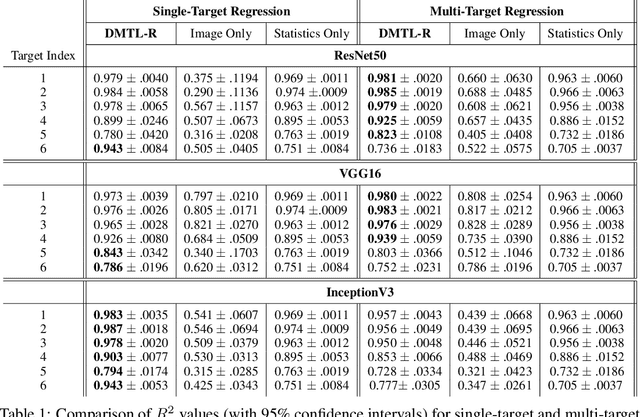
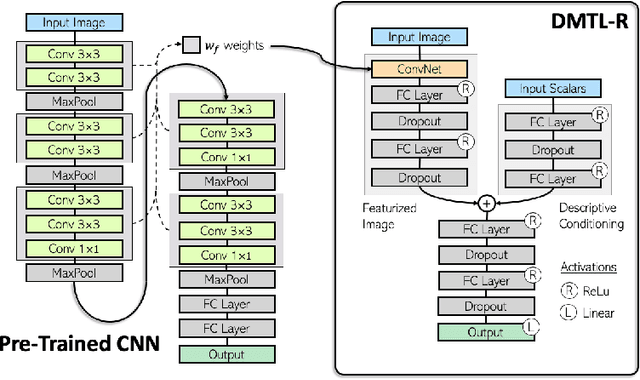

In many real-world applications of deep learning, estimation of a target may rely on various types of input data modes, such as audio-video, image-text, etc. This task can be further complicated by a lack of sufficient data. Here we propose a Deep Multimodal Transfer-Learned Regressor (DMTL-R) for multimodal learning of image and feature data in a deep regression architecture effective at predicting target parameters in data-poor domains. Our model is capable of fine-tuning a given set of pre-trained CNN weights on a small amount of training image data, while simultaneously conditioning on feature information from a complimentary data mode during network training, yielding more accurate single-target or multi-target regression than can be achieved using the images or the features alone. We present results using phase-field simulation microstructure images with an accompanying set of physical features, using pre-trained weights from various well-known CNN architectures, which demonstrate the efficacy of the proposed multimodal approach.
Mining Entity Synonyms with Efficient Neural Set Generation
Nov 16, 2018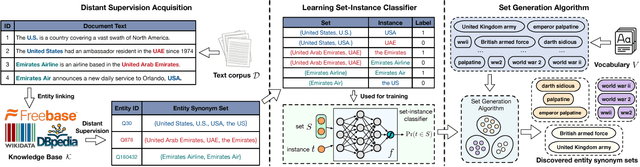
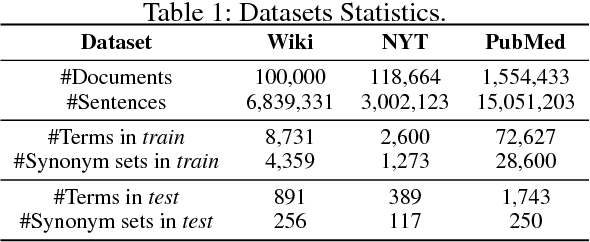
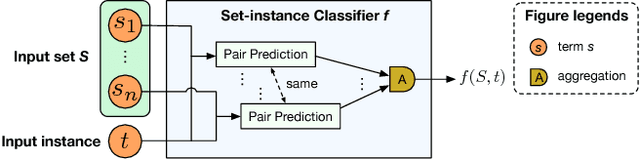

Mining entity synonym sets (i.e., sets of terms referring to the same entity) is an important task for many entity-leveraging applications. Previous work either rank terms based on their similarity to a given query term, or treats the problem as a two-phase task (i.e., detecting synonymy pairs, followed by organizing these pairs into synonym sets). However, these approaches fail to model the holistic semantics of a set and suffer from the error propagation issue. Here we propose a new framework, named SynSetMine, that efficiently generates entity synonym sets from a given vocabulary, using example sets from external knowledge bases as distant supervision. SynSetMine consists of two novel modules: (1) a set-instance classifier that jointly learns how to represent a permutation invariant synonym set and whether to include a new instance (i.e., a term) into the set, and (2) a set generation algorithm that enumerates the vocabulary only once and applies the learned set-instance classifier to detect all entity synonym sets in it. Experiments on three real datasets from different domains demonstrate both effectiveness and efficiency of SynSetMine for mining entity synonym sets.
Interactive Semantic Parsing for If-Then Recipes via Hierarchical Reinforcement Learning
Aug 21, 2018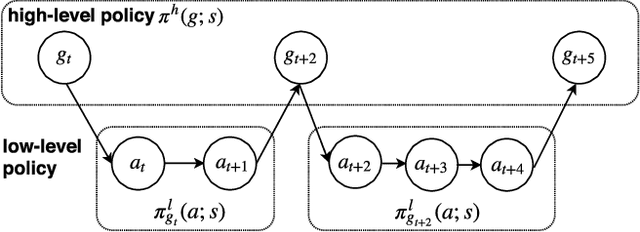
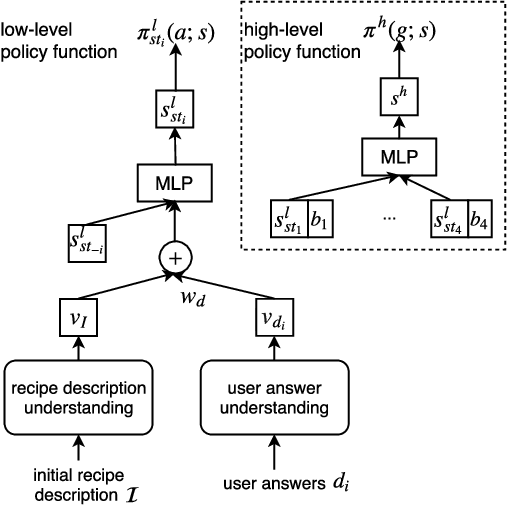

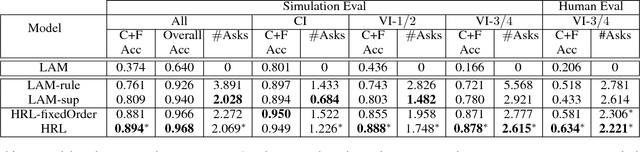
Given a text description, most existing semantic parsers synthesize a program in one shot. However, in reality, the description can be ambiguous or incomplete, solely based on which it is quite challenging to produce a correct program. In this paper, we investigate interactive semantic parsing for If-Then recipes where an agent can interact with users to resolve ambiguities. We develop a hierarchical reinforcement learning (HRL) based agent that can improve the parsing performance with minimal questions to users. Results under both simulation and human evaluation show that our agent substantially outperforms non-interactive semantic parsers and rule-based agents.
Learning flexible representations of stochastic processes on graphs
Mar 13, 2018
Graph convolutional networks adapt the architecture of convolutional neural networks to learn rich representations of data supported on arbitrary graphs by replacing the convolution operations of convolutional neural networks with graph-dependent linear operations. However, these graph-dependent linear operations are developed for scalar functions supported on undirected graphs. We propose a class of linear operations for stochastic (time-varying) processes on directed (or undirected) graphs to be used in graph convolutional networks. We propose a parameterization of such linear operations using functional calculus to achieve arbitrarily low learning complexity. The proposed approach is shown to model richer behaviors and display greater flexibility in learning representations than product graph methods.