 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataScribe: An AI-Native, Policy-Aligned Web Platform for Multi-Objective Materials Design and Discovery
Jan 12, 2026The acceleration of materials discovery requires digital platforms that go beyond data repositories to embed learning, optimization, and decision-making directly into research workflows. We introduce DataScribe, an AI-native, cloud-based materials discovery platform that unifies heterogeneous experimental and computational data through ontology-backed ingestion and machine-actionable knowledge graphs. The platform integrates FAIR-compliant metadata capture, schema and unit harmonization, uncertainty-aware surrogate modeling, and native multi-objective multi-fidelity Bayesian optimization, enabling closed-loop propose-measure-learn workflows across experimental and computational pipelines. DataScribe functions as an application-layer intelligence stack, coupling data governance, optimization, and explainability rather than treating them as downstream add-ons. We validate the platform through case studies in electrochemical materials and high-entropy alloys, demonstrating end-to-end data fusion, real-time optimization, and reproducible exploration of multi-objective trade spaces. By embedding optimization engines, machine learning, and unified access to public and private scientific data directly within the data infrastructure, and by supporting open, free use for academic and non-profit researchers, DataScribe functions as a general-purpose application-layer backbone for laboratories of any scale, including self-driving laboratories and geographically distributed materials acceleration platforms, with built-in support for performance, sustainability, and supply-chain-aware objectives.
Deep Gaussian Process-based Cost-Aware Batch Bayesian Optimization for Complex Materials Design Campaigns
Sep 17, 2025The accelerating pace and expanding scope of materials discovery demand optimization frameworks that efficiently navigate vast, nonlinear design spaces while judiciously allocating limited evaluation resources. We present a cost-aware, batch Bayesian optimization scheme powered by deep Gaussian process (DGP) surrogates and a heterotopic querying strategy. Our DGP surrogate, formed by stacking GP layers, models complex hierarchical relationships among high-dimensional compositional features and captures correlations across multiple target properties, propagating uncertainty through successive layers. We integrate evaluation cost into an upper-confidence-bound acquisition extension, which, together with heterotopic querying, proposes small batches of candidates in parallel, balancing exploration of under-characterized regions with exploitation of high-mean, low-variance predictions across correlated properties. Applied to refractory high-entropy alloys for high-temperature applications, our framework converges to optimal formulations in fewer iterations with cost-aware queries than conventional GP-based BO, highlighting the value of deep, uncertainty-aware, cost-sensitive strategies in materials campaigns.
Data Driven Insights into Composition Property Relationships in FCC High Entropy Alloys
Aug 06, 2025Structural High Entropy Alloys (HEAs) are crucial in advancing technology across various sectors, including aerospace, automotive, and defense industries. However, the scarcity of integrated chemistry, process, structure, and property data presents significant challenges for predictive property modeling. Given the vast design space of these alloys, uncovering the underlying patterns is essential yet difficult, requiring advanced methods capable of learning from limited and heterogeneous datasets. This work presents several sensitivity analyses, highlighting key elemental contributions to mechanical behavior, including insights into the compositional factors associated with brittle and fractured responses observed during nanoindentation testing in the BIRDSHOT center NiCoFeCrVMnCuAl system dataset. Several encoder decoder based chemistry property models, carefully tuned through Bayesian multi objective hyperparameter optimization, are evaluated for mapping alloy composition to six mechanical properties. The models achieve competitive or superior performance to conventional regressors across all properties, particularly for yield strength and the UTS/YS ratio, demonstrating their effectiveness in capturing complex composition property relationships.
Efficient Propagation of Uncertainty via Reordering Monte Carlo Samples
Feb 09, 2023



Uncertainty analysis in the outcomes of model predictions is a key element in decision-based material design to establish confidence in the models and evaluate the fidelity of models. Uncertainty Propagation (UP) is a technique to determine model output uncertainties based on the uncertainty in its input variables. The most common and simplest approach to propagate the uncertainty from a model inputs to its outputs is by feeding a large number of samples to the model, known as Monte Carlo (MC) simulation which requires exhaustive sampling from the input variable distributions. However, MC simulations are impractical when models are computationally expensive. In this work, we investigate the hypothesis that while all samples are useful on average, some samples must be more useful than others. Thus, reordering MC samples and propagating more useful samples can lead to enhanced convergence in statistics of interest earlier and thus, reducing the computational burden of UP process. Here, we introduce a methodology to adaptively reorder MC samples and show how it results in reduction of computational expense of UP processes.
Deep Multimodal Transfer-Learned Regression in Data-Poor Domains
Jun 16, 2020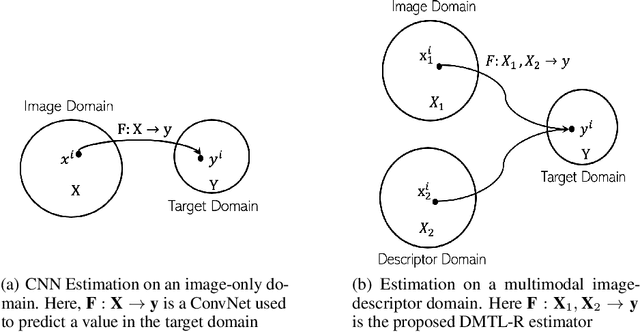
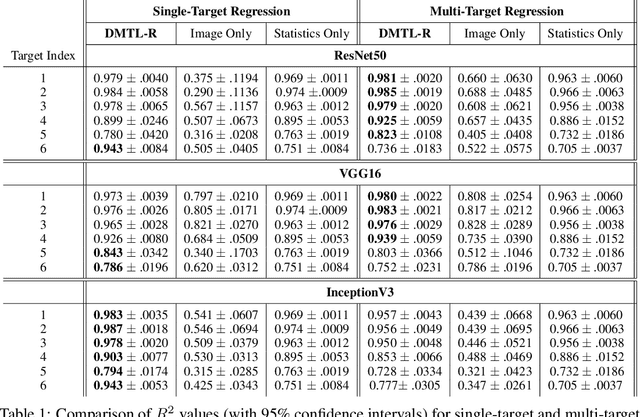
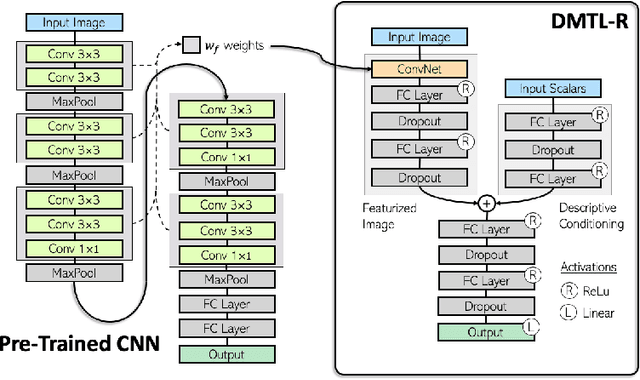

In many real-world applications of deep learning, estimation of a target may rely on various types of input data modes, such as audio-video, image-text, etc. This task can be further complicated by a lack of sufficient data. Here we propose a Deep Multimodal Transfer-Learned Regressor (DMTL-R) for multimodal learning of image and feature data in a deep regression architecture effective at predicting target parameters in data-poor domains. Our model is capable of fine-tuning a given set of pre-trained CNN weights on a small amount of training image data, while simultaneously conditioning on feature information from a complimentary data mode during network training, yielding more accurate single-target or multi-target regression than can be achieved using the images or the features alone. We present results using phase-field simulation microstructure images with an accompanying set of physical features, using pre-trained weights from various well-known CNN architectures, which demonstrate the efficacy of the proposed multimodal approach.