 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffboard 3D Object Detection from Point Cloud Sequences
Mar 08, 2021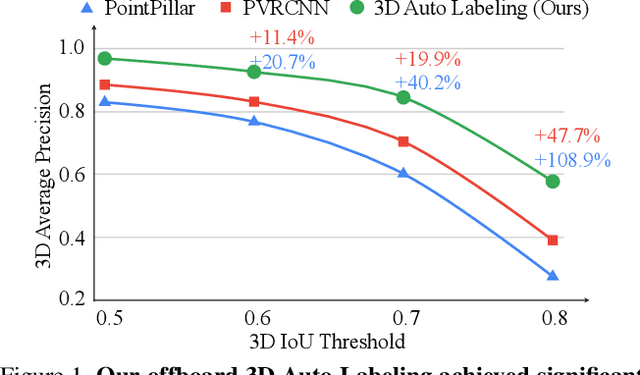
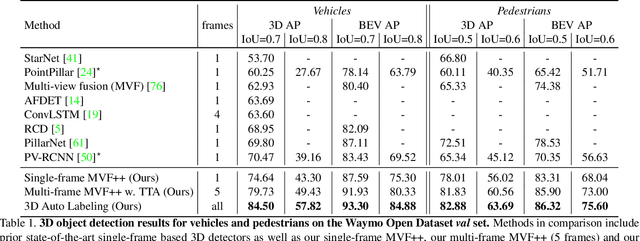
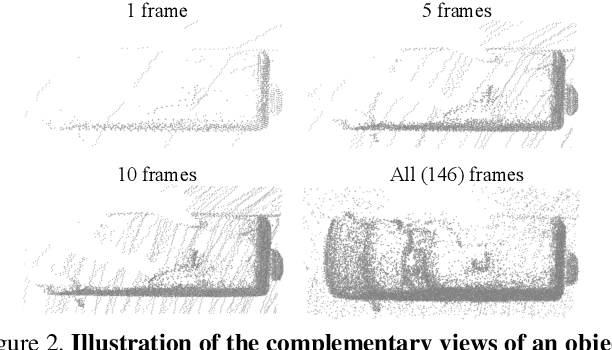

While current 3D object recognition research mostly focuses on the real-time, onboard scenario, there are many offboard use cases of perception that are largely under-explored, such as using machines to automatically generate high-quality 3D labels. Existing 3D object detectors fail to satisfy the high-quality requirement for offboard uses due to the limited input and speed constraints. In this paper, we propose a novel offboard 3D object detection pipeline using point cloud sequence data. Observing that different frames capture complementary views of objects, we design the offboard detector to make use of the temporal points through both multi-frame object detection and novel object-centric refinement models. Evaluated on the Waymo Open Dataset, our pipeline named 3D Auto Labeling shows significant gains compared to the state-of-the-art onboard detectors and our offboard baselines. Its performance is even on par with human labels verified through a human label study. Further experiments demonstrate the application of auto labels for semi-supervised learning and provide extensive analysis to validate various design choices.
Canonical Capsules: Unsupervised Capsules in Canonical Pose
Dec 08, 2020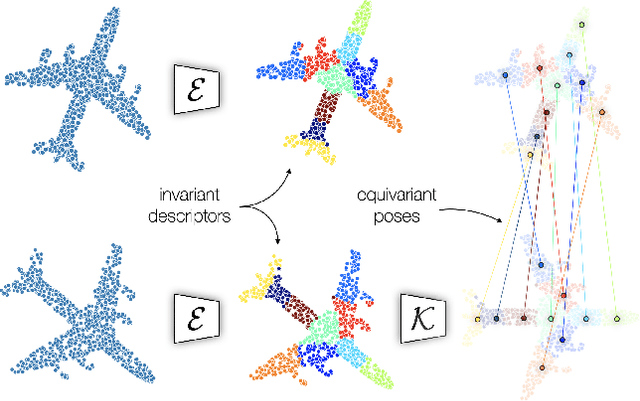
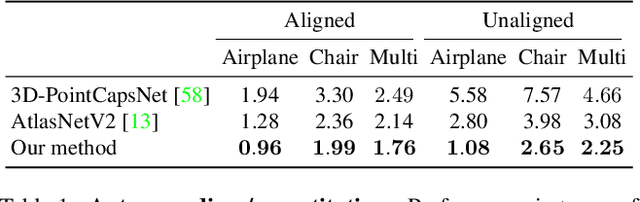

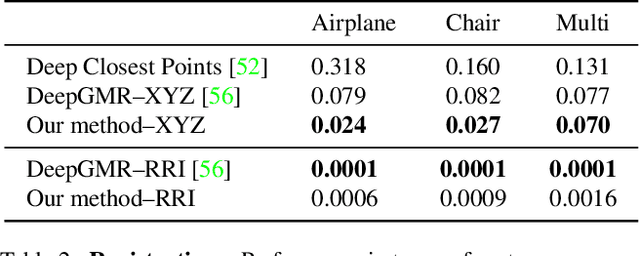
We propose an unsupervised capsule architecture for 3D point clouds. We compute capsule decompositions of objects through permutation-equivariant attention, and self-supervise the process by training with pairs of randomly rotated objects. Our key idea is to aggregate the attention masks into semantic keypoints, and use these to supervise a decomposition that satisfies the capsule invariance/equivariance properties. This not only enables the training of a semantically consistent decomposition, but also allows us to learn a canonicalization operation that enables object-centric reasoning. In doing so, we require neither classification labels nor manually-aligned training datasets to train. Yet, by learning an object-centric representation in an unsupervised manner, our method outperforms the state-of-the-art on 3D point cloud reconstruction, registration, and unsupervised classification. We will release the code and dataset to reproduce our results as soon as the paper is published.
NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis
Dec 07, 2020
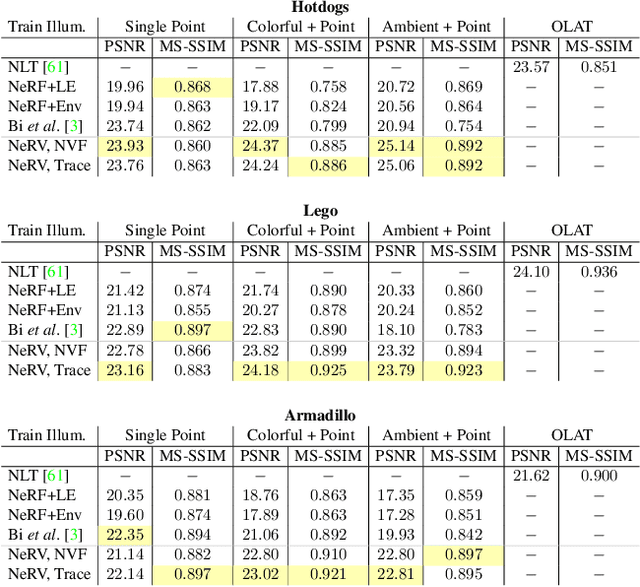
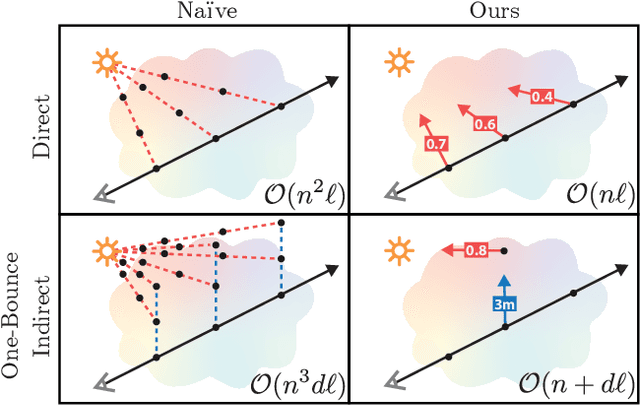
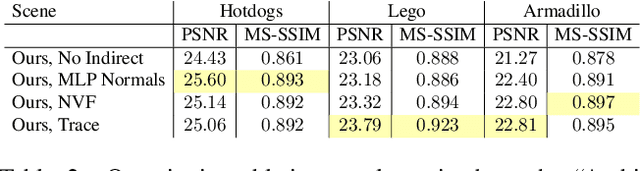
We present a method that takes as input a set of images of a scene illuminated by unconstrained known lighting, and produces as output a 3D representation that can be rendered from novel viewpoints under arbitrary lighting conditions. Our method represents the scene as a continuous volumetric function parameterized as MLPs whose inputs are a 3D location and whose outputs are the following scene properties at that input location: volume density, surface normal, material parameters, distance to the first surface intersection in any direction, and visibility of the external environment in any direction. Together, these allow us to render novel views of the object under arbitrary lighting, including indirect illumination effects. The predicted visibility and surface intersection fields are critical to our model's ability to simulate direct and indirect illumination during training, because the brute-force techniques used by prior work are intractable for lighting conditions outside of controlled setups with a single light. Our method outperforms alternative approaches for recovering relightable 3D scene representations, and performs well in complex lighting settings that have posed a significant challenge to prior work.
NASA: Neural Articulated Shape Approximation
Dec 06, 2019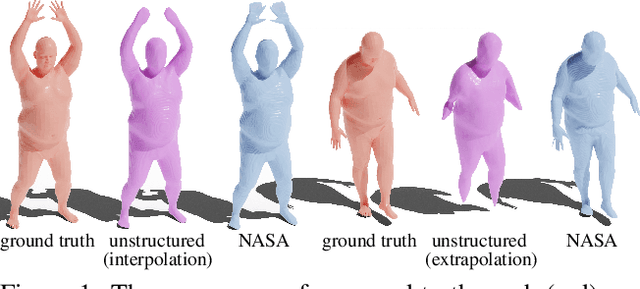
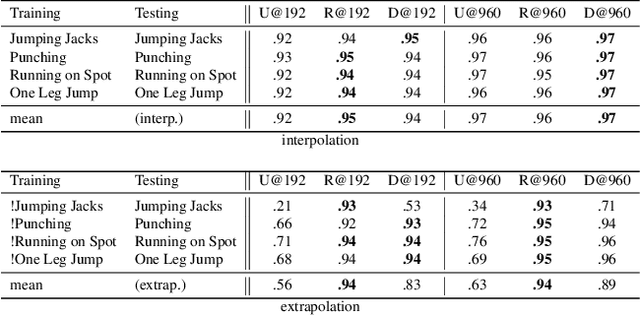


Efficient representation of articulated objects such as human bodies is an important problem in computer vision and graphics. To efficiently simulate deformation, existing approaches represent objects as meshes and deform them using skinning techniques. This paper introduces neural articulated shape approximation (NASA), a framework that enables efficient representation of articulated deformable objects using neural indicator functions parameterized by pose. In contrast to classic approaches, NASA avoids the need to convert between different representations. For occupancy testing, NASA circumvents the complexity of meshes and mitigates the issue of water-tightness. In comparison with regular grids and octrees, our approach provides high resolution without high memory use.
CvxNets: Learnable Convex Decomposition
Sep 12, 2019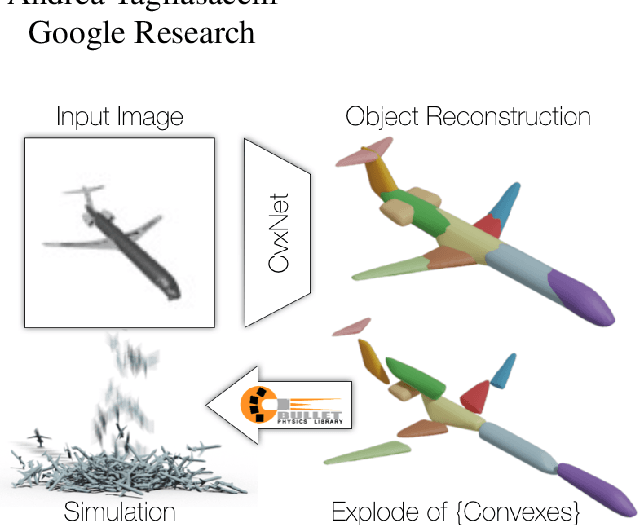
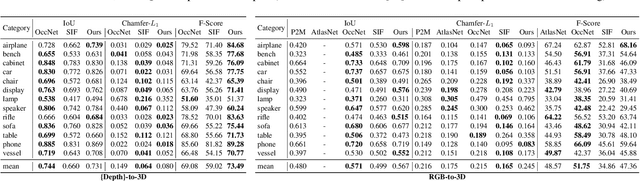
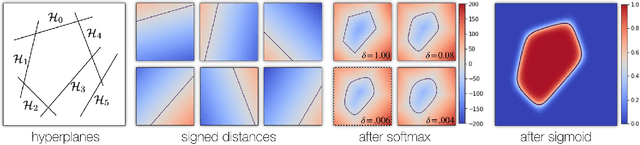
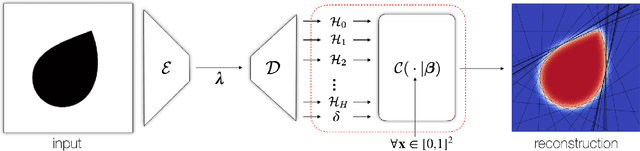
Any solid object can be decomposed into a collection of convex polytopes (in short, convexes). When a small number of convexes are used, such a decomposition can be thought of as a piece-wise approximation of the geometry. This decomposition is fundamental to real-time physics simulation in computer graphics, where it creates a unifying representation of dynamic geometry for collision detection. A convex object also has the property of being simultaneously an explicit and implicit representation: one can interpret it explicitly as a mesh derived by computing the vertices of a convex hull, or implicitly as the collection of half-space constraints or support functions. Their implicit representation makes them particularly well suited for neural network training, as they abstract away from the topology of the geometry they need to represent. We introduce a network architecture to represent a low dimensional family of convexes. This family is automatically derived via an autoencoding process. We investigate the applications of the network including automatic convex decomposition, image to 3D reconstruction, and part-based shape retrieval.
Cerberus: A Multi-headed Derenderer
May 28, 2019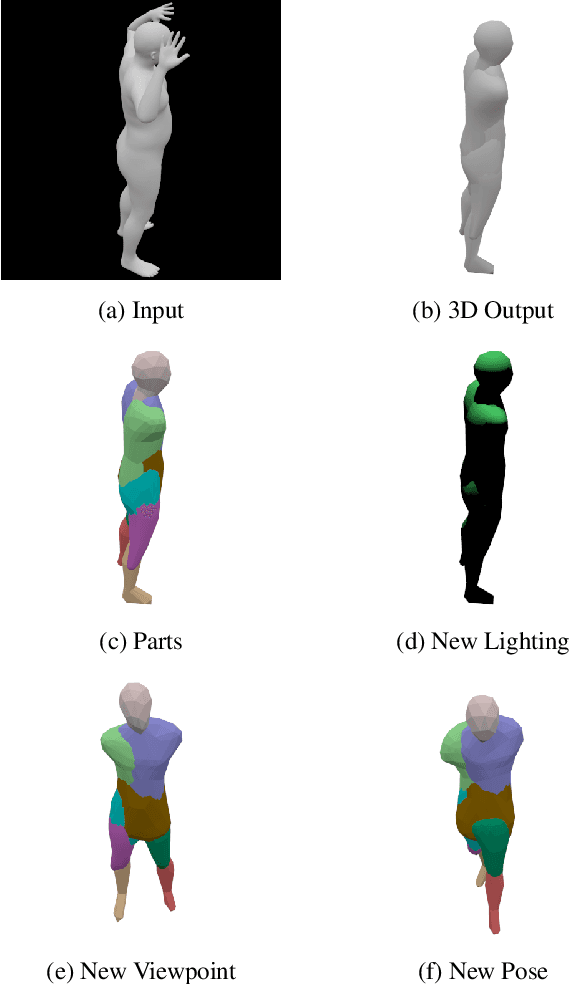

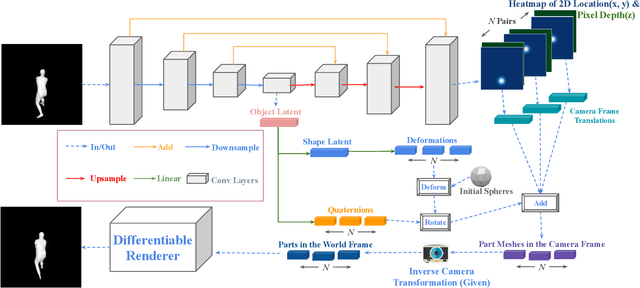
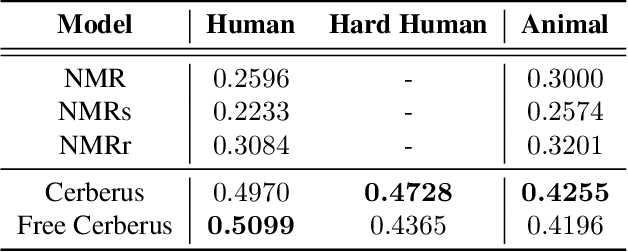
To generalize to novel visual scenes with new viewpoints and new object poses, a visual system needs representations of the shapes of the parts of an object that are invariant to changes in viewpoint or pose. 3D graphics representations disentangle visual factors such as viewpoints and lighting from object structure in a natural way. It is possible to learn to invert the process that converts 3D graphics representations into 2D images, provided the 3D graphics representations are available as labels. When only the unlabeled images are available, however, learning to derender is much harder. We consider a simple model which is just a set of free floating parts. Each part has its own relation to the camera and its own triangular mesh which can be deformed to model the shape of the part. At test time, a neural network looks at a single image and extracts the shapes of the parts and their relations to the camera. Each part can be viewed as one head of a multi-headed derenderer. During training, the extracted parts are used as input to a differentiable 3D renderer and the reconstruction error is backpropagated to train the neural net. We make the learning task easier by encouraging the deformations of the part meshes to be invariant to changes in viewpoint and invariant to the changes in the relative positions of the parts that occur when the pose of an articulated body changes. Cerberus, our multi-headed derenderer, outperforms previous methods for extracting 3D parts from single images without part annotations, and it does quite well at extracting natural parts of human figures.
BlockQNN: Efficient Block-wise Neural Network Architecture Generation
Aug 16, 2018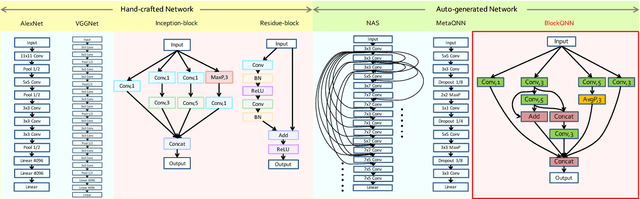
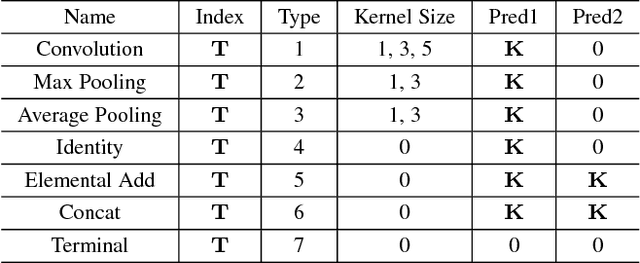
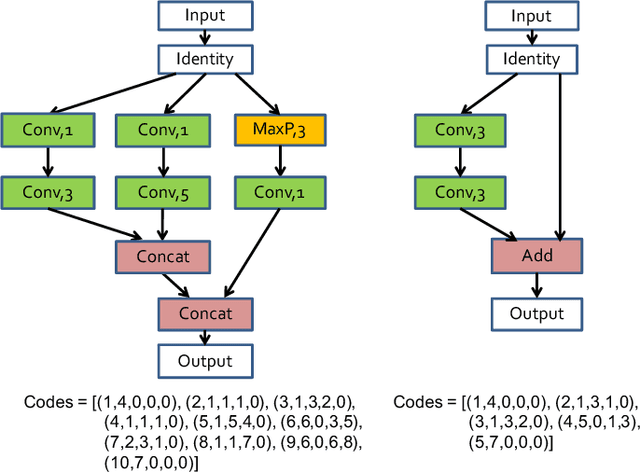

Convolutional neural networks have gained a remarkable success in computer vision. However, most usable network architectures are hand-crafted and usually require expertise and elaborate design. In this paper, we provide a block-wise network generation pipeline called BlockQNN which automatically builds high-performance networks using the Q-Learning paradigm with epsilon-greedy exploration strategy. The optimal network block is constructed by the learning agent which is trained to choose component layers sequentially. We stack the block to construct the whole auto-generated network. To accelerate the generation process, we also propose a distributed asynchronous framework and an early stop strategy. The block-wise generation brings unique advantages: (1) it yields state-of-the-art results in comparison to the hand-crafted networks on image classification, particularly, the best network generated by BlockQNN achieves 2.35% top-1 error rate on CIFAR-10. (2) it offers tremendous reduction of the search space in designing networks, spending only 3 days with 32 GPUs. A faster version can yield a comparable result with only 1 GPU in 20 hours. (3) it has strong generalizability in that the network built on CIFAR also performs well on the larger-scale dataset. The best network achieves very competitive accuracy of 82.0% top-1 and 96.0% top-5 on ImageNet.
Few-shot Learning by Exploiting Visual Concepts within CNNs
Feb 13, 2018
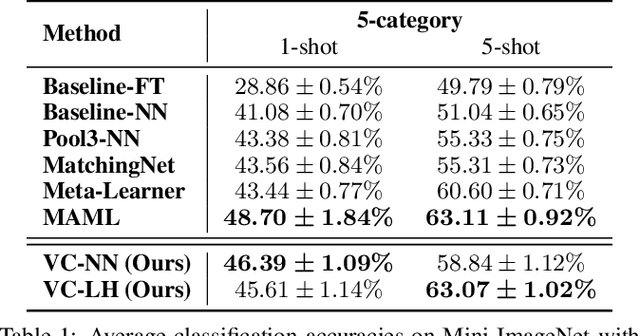
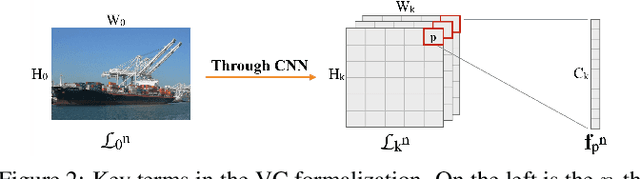
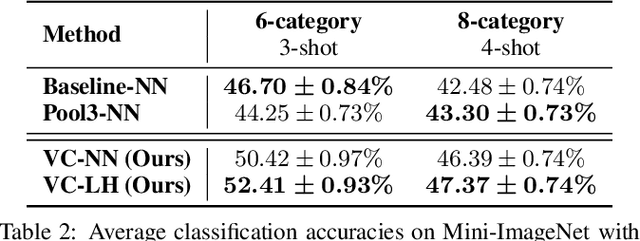
Convolutional neural networks (CNNs) are one of the driving forces for the advancement of computer vision. Despite their promising performances on many tasks, CNNs still face major obstacles on the road to achieving ideal machine intelligence. One is that CNNs are complex and hard to interpret. Another is that standard CNNs require large amounts of annotated data, which is sometimes hard to obtain, and it is desirable to learn to recognize objects from few examples. In this work, we address these limitations of CNNs by developing novel, flexible, and interpretable models for few-shot learning. Our models are based on the idea of encoding objects in terms of visual concepts (VCs), which are interpretable visual cues represented by the feature vectors within CNNs. We first adapt the learning of VCs to the few-shot setting, and then uncover two key properties of feature encoding using VCs, which we call category sensitivity and spatial pattern. Motivated by these properties, we present two intuitive models for the problem of few-shot learning. Experiments show that our models achieve competitive performances, while being more flexible and interpretable than alternative state-of-the-art few-shot learning methods. We conclude that using VCs helps expose the natural capability of CNNs for few-shot learning.
Peephole: Predicting Network Performance Before Training
Dec 09, 2017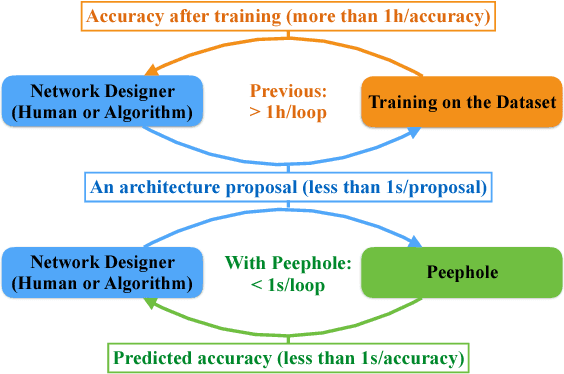
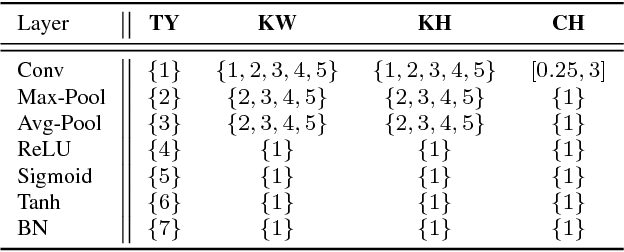
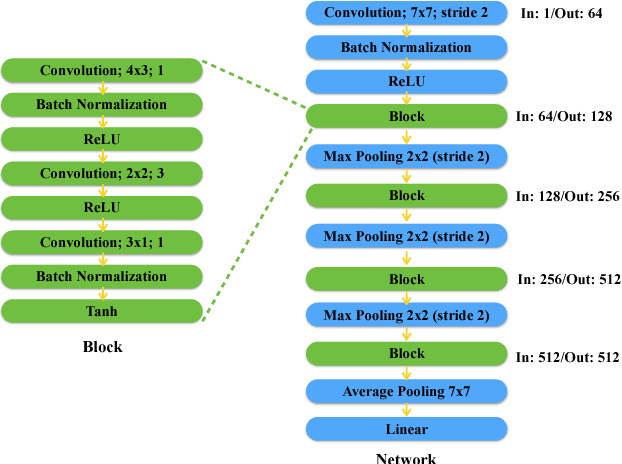
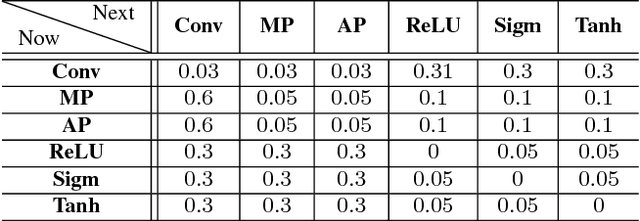
The quest for performant networks has been a significant force that drives the advancements of deep learning in recent years. While rewarding, improving network design has never been an easy journey. The large design space combined with the tremendous cost required for network training poses a major obstacle to this endeavor. In this work, we propose a new approach to this problem, namely, predicting the performance of a network before training, based on its architecture. Specifically, we develop a unified way to encode individual layers into vectors and bring them together to form an integrated description via LSTM. Taking advantage of the recurrent network's strong expressive power, this method can reliably predict the performances of various network architectures. Our empirical studies showed that it not only achieved accurate predictions but also produced consistent rankings across datasets -- a key desideratum in performance prediction.
Hierarchical Deep Recurrent Architecture for Video Understanding
Jul 11, 2017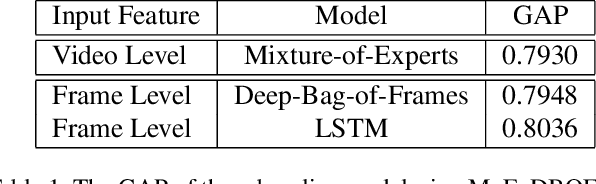
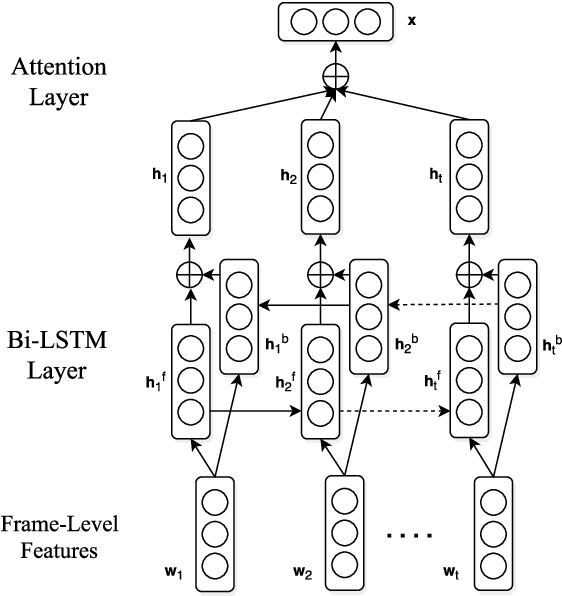

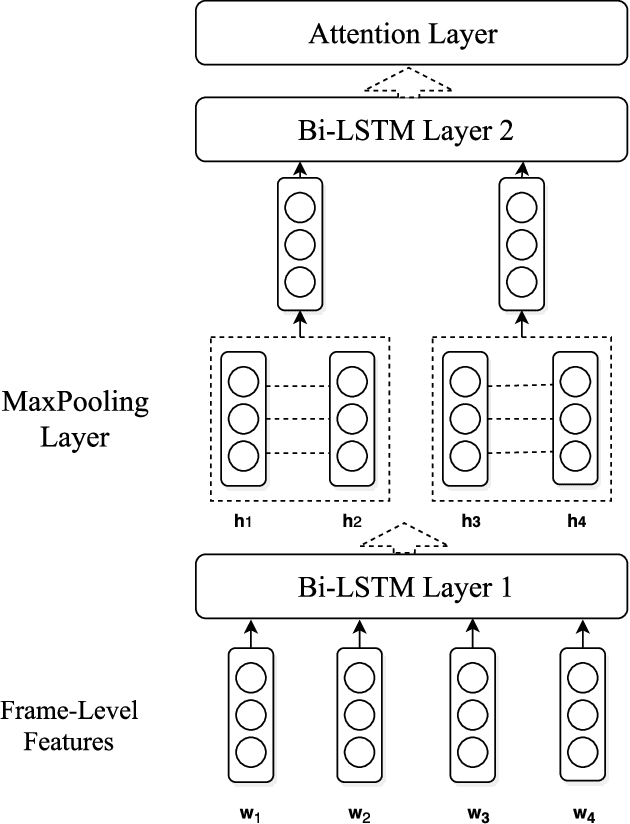
This paper introduces the system we developed for the Youtube-8M Video Understanding Challenge, in which a large-scale benchmark dataset was used for multi-label video classification. The proposed framework contains hierarchical deep architecture, including the frame-level sequence modeling part and the video-level classification part. In the frame-level sequence modelling part, we explore a set of methods including Pooling-LSTM (PLSTM), Hierarchical-LSTM (HLSTM), Random-LSTM (RLSTM) in order to address the problem of large amount of frames in a video. We also introduce two attention pooling methods, single attention pooling (ATT) and multiply attention pooling (Multi-ATT) so that we can pay more attention to the informative frames in a video and ignore the useless frames. In the video-level classification part, two methods are proposed to increase the classification performance, i.e. Hierarchical-Mixture-of-Experts (HMoE) and Classifier Chains (CC). Our final submission is an ensemble consisting of 18 sub-models. In terms of the official evaluation metric Global Average Precision (GAP) at 20, our best submission achieves 0.84346 on the public 50% of test dataset and 0.84333 on the private 50% of test data.