 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Human-guided Conditional Variational Generative Modeling for Automated Urban Planning
Oct 12, 2021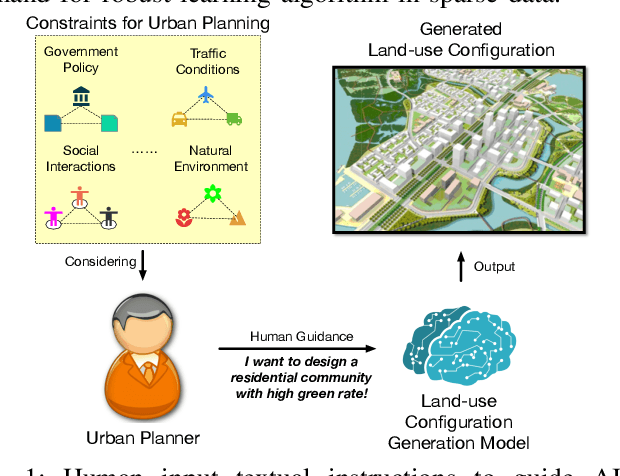
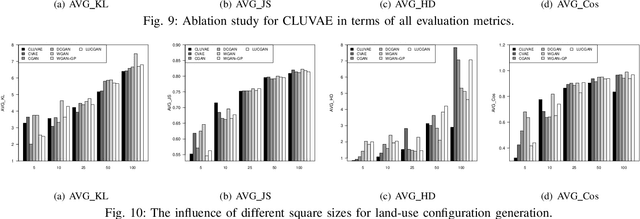
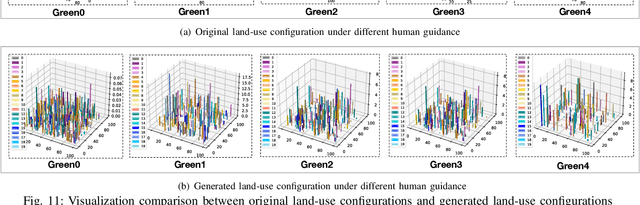
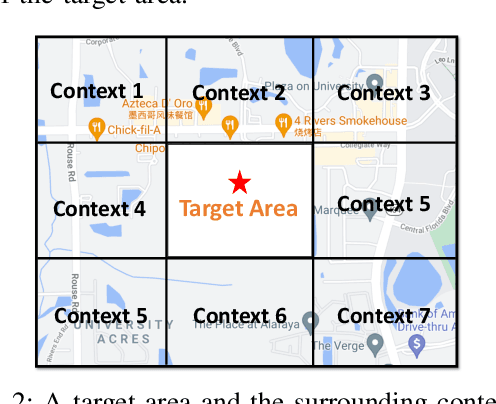
Urban planning designs land-use configurations and can benefit building livable, sustainable, safe communities. Inspired by image generation, deep urban planning aims to leverage deep learning to generate land-use configurations. However, urban planning is a complex process. Existing studies usually ignore the need of personalized human guidance in planning, and spatial hierarchical structure in planning generation. Moreover, the lack of large-scale land-use configuration samples poses a data sparsity challenge. This paper studies a novel deep human guided urban planning method to jointly solve the above challenges. Specifically, we formulate the problem into a deep conditional variational autoencoder based framework. In this framework, we exploit the deep encoder-decoder design to generate land-use configurations. To capture the spatial hierarchy structure of land uses, we enforce the decoder to generate both the coarse-grained layer of functional zones, and the fine-grained layer of POI distributions. To integrate human guidance, we allow humans to describe what they need as texts and use these texts as a model condition input. To mitigate training data sparsity and improve model robustness, we introduce a variational Gaussian embedding mechanism. It not just allows us to better approximate the embedding space distribution of training data and sample a larger population to overcome sparsity, but also adds more probabilistic randomness into the urban planning generation to improve embedding diversity so as to improve robustness. Finally, we present extensive experiments to validate the enhanced performances of our method.
Analysis for full face mechanical behaviors through spatial deduction model with real-time monitoring data
Sep 27, 2021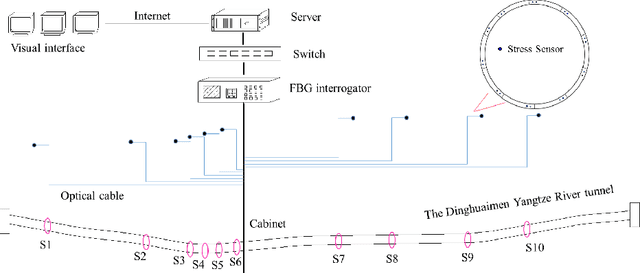
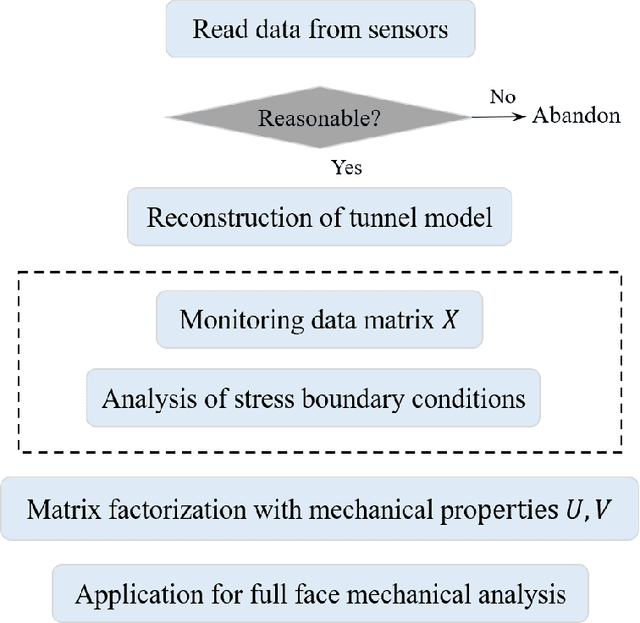
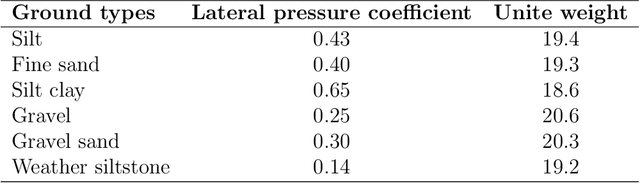
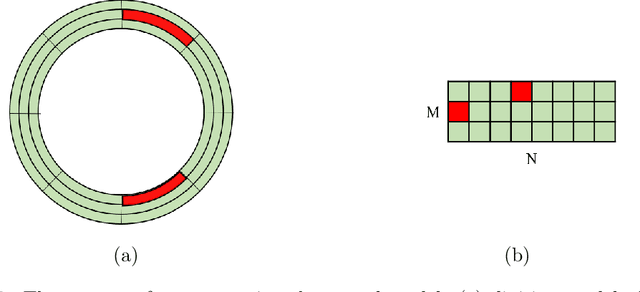
Mechanical analysis for the full face of tunnel structure is crucial to maintain stability, which is a challenge in classical analytical solutions and data analysis. Along this line, this study aims to develop a spatial deduction model to obtain the full-faced mechanical behaviors through integrating mechanical properties into pure data-driven model. The spatial tunnel structure is divided into many parts and reconstructed in a form of matrix. Then, the external load applied on structure in the field was considered to study the mechanical behaviors of tunnel. Based on the limited observed monitoring data in matrix and mechanical analysis results, a double-driven model was developed to obtain the full-faced information, in which the data-driven model was the dominant one and the mechanical constraint was the secondary one. To verify the presented spatial deduction model, cross-test was conducted through assuming partial monitoring data are unknown and regarding them as testing points. The well agreement between deduction results with actual monitoring results means the proposed model is reasonable. Therefore, it was employed to deduct both the current and historical performance of tunnel full face, which is crucial to prevent structural disasters.
Heterogeneous Graph Representation Learning with Relation Awareness
May 24, 2021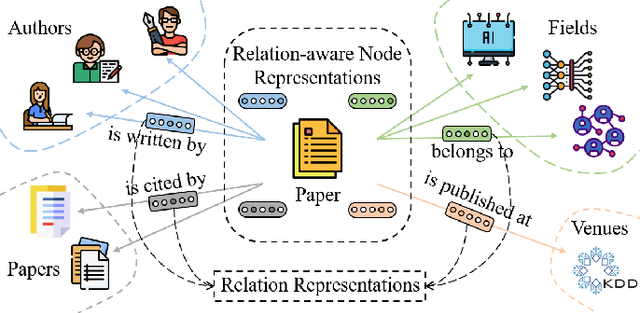
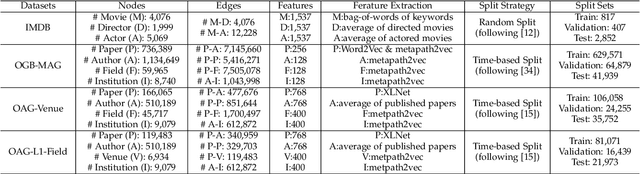
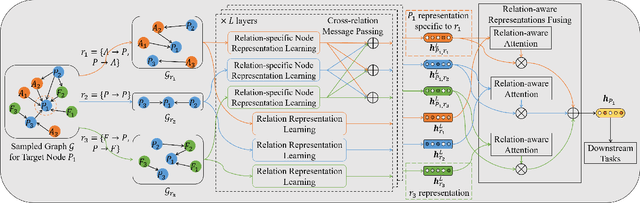

Representation learning on heterogeneous graphs aims to obtain meaningful node representations to facilitate various downstream tasks, such as node classification and link prediction. Existing heterogeneous graph learning methods are primarily developed by following the propagation mechanism of node representations. There are few efforts on studying the role of relations for improving the learning of more fine-grained node representations. Indeed, it is important to collaboratively learn the semantic representations of relations and discern node representations with respect to different relation types. To this end, in this paper, we propose a novel Relation-aware Heterogeneous Graph Neural Network, namely R-HGNN, to learn node representations on heterogeneous graphs at a fine-grained level by considering relation-aware characteristics. Specifically, a dedicated graph convolution component is first designed to learn unique node representations from each relation-specific graph separately. Then, a cross-relation message passing module is developed to improve the interactions of node representations across different relations. Also, the relation representations are learned in a layer-wise manner to capture relation semantics, which are used to guide the node representation learning process. Moreover, a semantic fusing module is presented to aggregate relation-aware node representations into a compact representation with the learned relation representations. Finally, we conduct extensive experiments on a variety of graph learning tasks, and experimental results demonstrate that our approach consistently outperforms existing methods among all the tasks.
Hybrid Micro/Macro Level Convolution for Heterogeneous Graph Learning
Dec 29, 2020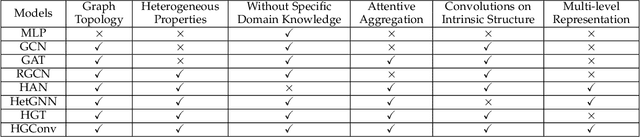
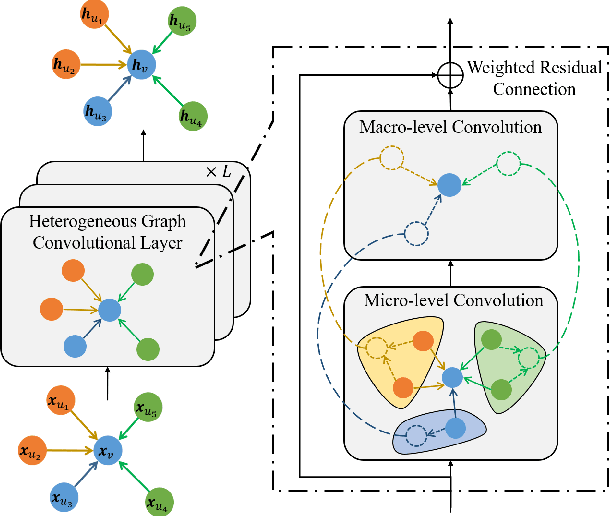
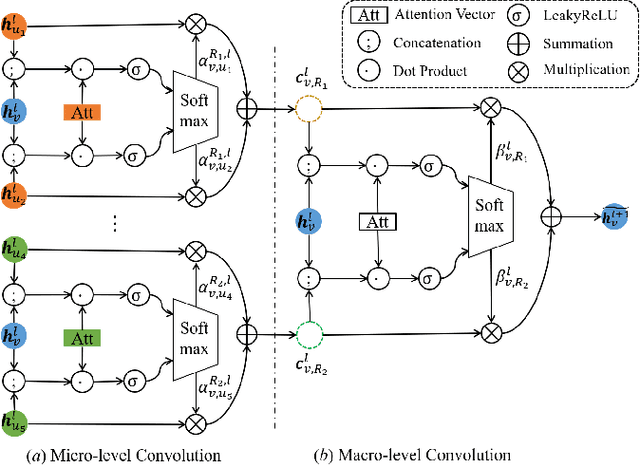
Heterogeneous graphs are pervasive in practical scenarios, where each graph consists of multiple types of nodes and edges. Representation learning on heterogeneous graphs aims to obtain low-dimensional node representations that could preserve both node attributes and relation information. However, most of the existing graph convolution approaches were designed for homogeneous graphs, and therefore cannot handle heterogeneous graphs. Some recent methods designed for heterogeneous graphs are also faced with several issues, including the insufficient utilization of heterogeneous properties, structural information loss, and lack of interpretability. In this paper, we propose HGConv, a novel Heterogeneous Graph Convolution approach, to learn comprehensive node representations on heterogeneous graphs with a hybrid micro/macro level convolutional operation. Different from existing methods, HGConv could perform convolutions on the intrinsic structure of heterogeneous graphs directly at both micro and macro levels: A micro-level convolution to learn the importance of nodes within the same relation, and a macro-level convolution to distinguish the subtle difference across different relations. The hybrid strategy enables HGConv to fully leverage heterogeneous information with proper interpretability. Moreover, a weighted residual connection is designed to aggregate both inherent attributes and neighbor information of the focal node adaptively. Extensive experiments on various tasks demonstrate not only the superiority of HGConv over existing methods, but also the intuitive interpretability of our approach for graph analysis.
Coupled Layer-wise Graph Convolution for Transportation Demand Prediction
Dec 15, 2020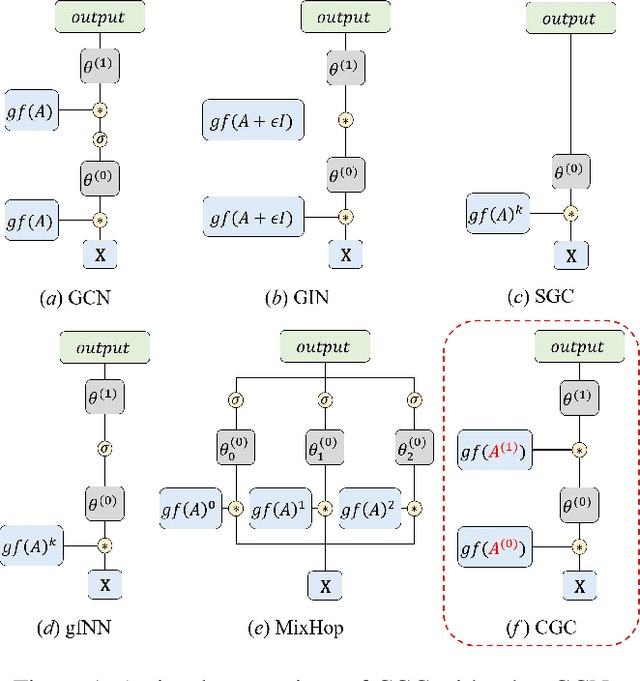
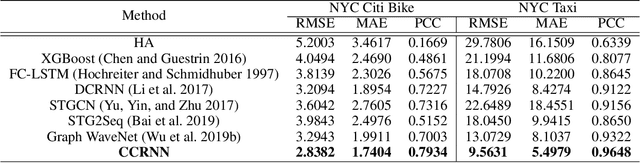
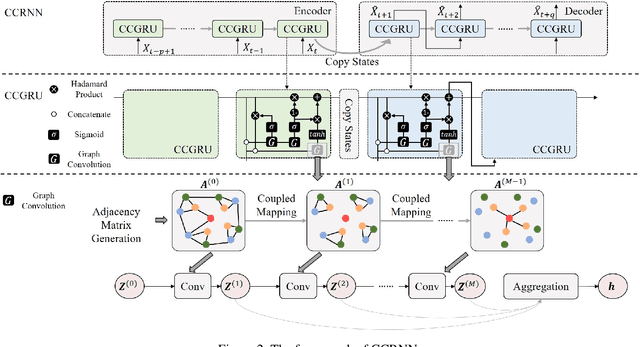
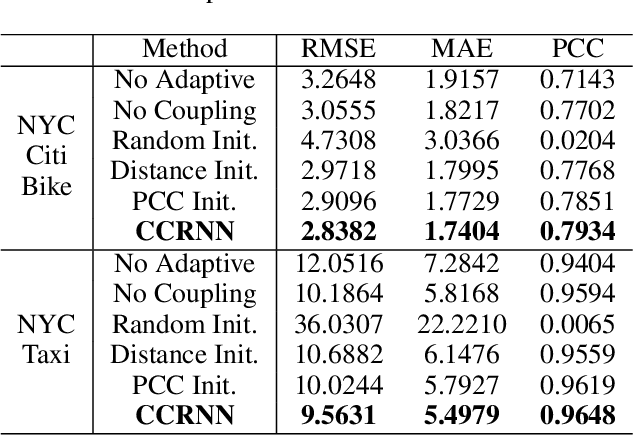
Graph Convolutional Network (GCN) has been widely applied in transportation demand prediction due to its excellent ability to capture non-Euclidean spatial dependence among station-level or regional transportation demands. However, in most of the existing research, the graph convolution was implemented on a heuristically generated adjacency matrix, which could neither reflect the real spatial relationships of stations accurately, nor capture the multi-level spatial dependence of demands adaptively. To cope with the above problems, this paper provides a novel graph convolutional network for transportation demand prediction. Firstly, a novel graph convolution architecture is proposed, which has different adjacency matrices in different layers and all the adjacency matrices are self-learned during the training process. Secondly, a layer-wise coupling mechanism is provided, which associates the upper-level adjacency matrix with the lower-level one. It also reduces the scale of parameters in our model. Lastly, a unitary network is constructed to give the final prediction result by integrating the hidden spatial states with gated recurrent unit, which could capture the multi-level spatial dependence and temporal dynamics simultaneously. Experiments have been conducted on two real-world datasets, NYC Citi Bike and NYC Taxi, and the results demonstrate the superiority of our model over the state-of-the-art ones.
Defending Water Treatment Networks: Exploiting Spatio-temporal Effects for Cyber Attack Detection
Aug 26, 2020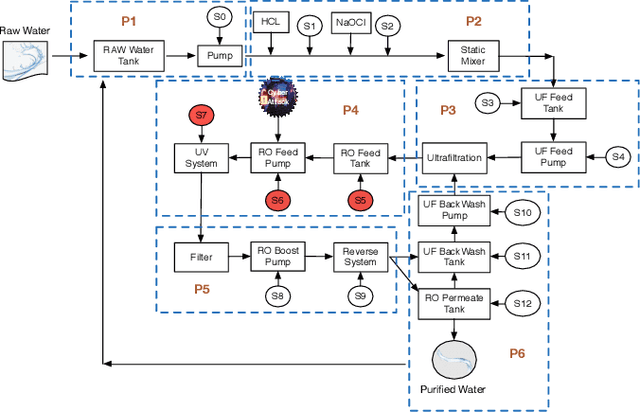
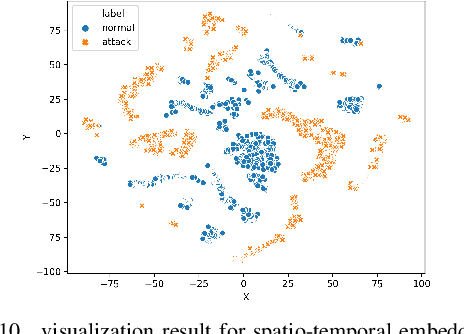

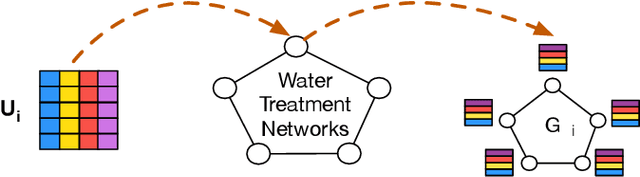
While Water Treatment Networks (WTNs) are critical infrastructures for local communities and public health, WTNs are vulnerable to cyber attacks. Effective detection of attacks can defend WTNs against discharging contaminated water, denying access, destroying equipment, and causing public fear. While there are extensive studies in WTNs attack detection, they only exploit the data characteristics partially to detect cyber attacks. After preliminary exploring the sensing data of WTNs, we find that integrating spatio-temporal knowledge, representation learning, and detection algorithms can improve attack detection accuracy. To this end, we propose a structured anomaly detection framework to defend WTNs by modeling the spatio-temporal characteristics of cyber attacks in WTNs. In particular, we propose a spatio-temporal representation framework specially tailored to cyber attacks after separating the sensing data of WTNs into a sequence of time segments. This framework has two key components. The first component is a temporal embedding module to preserve temporal patterns within a time segment by projecting the time segment of a sensor into a temporal embedding vector. We then construct Spatio-Temporal Graphs (STGs), where a node is a sensor and an attribute is the temporal embedding vector of the sensor, to describe the state of the WTNs. The second component is a spatial embedding module, which learns the final fused embedding of the WTNs from STGs. In addition, we devise an improved one class-SVM model that utilizes a new designed pairwise kernel to detect cyber attacks. The devised pairwise kernel augments the distance between normal and attack patterns in the fused embedding space. Finally, we conducted extensive experimental evaluations with real-world data to demonstrate the effectiveness of our framework.
Predicting Temporal Sets with Deep Neural Networks
Jul 08, 2020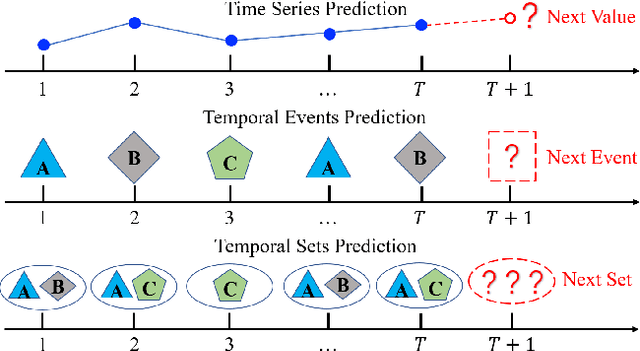
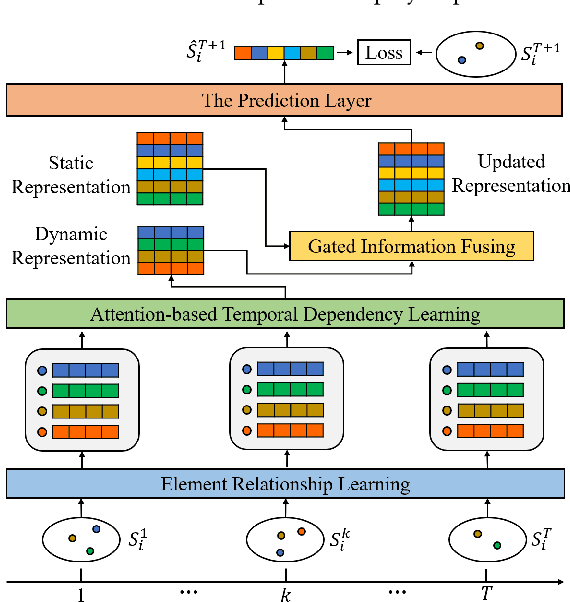

Given a sequence of sets, where each set contains an arbitrary number of elements, the problem of temporal sets prediction aims to predict the elements in the subsequent set. In practice, temporal sets prediction is much more complex than predictive modelling of temporal events and time series, and is still an open problem. Many possible existing methods, if adapted for the problem of temporal sets prediction, usually follow a two-step strategy by first projecting temporal sets into latent representations and then learning a predictive model with the latent representations. The two-step approach often leads to information loss and unsatisfactory prediction performance. In this paper, we propose an integrated solution based on the deep neural networks for temporal sets prediction. A unique perspective of our approach is to learn element relationship by constructing set-level co-occurrence graph and then perform graph convolutions on the dynamic relationship graphs. Moreover, we design an attention-based module to adaptively learn the temporal dependency of elements and sets. Finally, we provide a gated updating mechanism to find the hidden shared patterns in different sequences and fuse both static and dynamic information to improve the prediction performance. Experiments on real-world data sets demonstrate that our approach can achieve competitive performances even with a portion of the training data and can outperform existing methods with a significant margin.
Snoopy: Sniffing Your Smartwatch Passwords via Deep Sequence Learning
Dec 11, 2019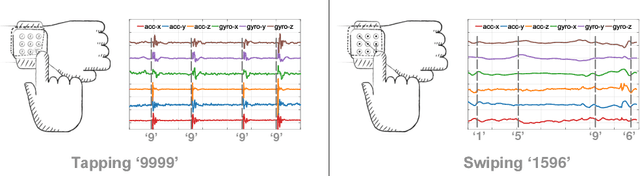
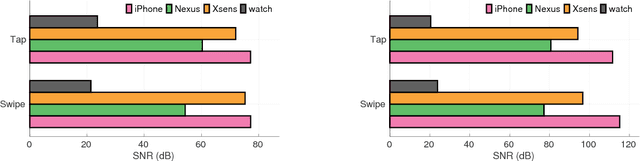
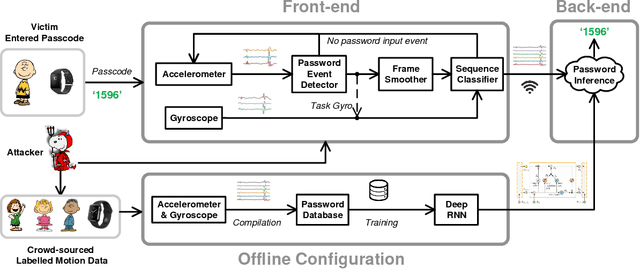
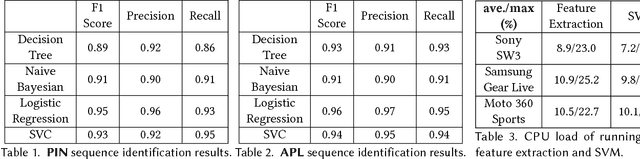
Demand for smartwatches has taken off in recent years with new models which can run independently from smartphones and provide more useful features, becoming first-class mobile platforms. One can access online banking or even make payments on a smartwatch without a paired phone. This makes smartwatches more attractive and vulnerable to malicious attacks, which to date have been largely overlooked. In this paper, we demonstrate Snoopy, a password extraction and inference system which is able to accurately infer passwords entered on Android/Apple watches within 20 attempts, just by eavesdropping on motion sensors. Snoopy uses a uniform framework to extract the segments of motion data when passwords are entered, and uses novel deep neural networks to infer the actual passwords. We evaluate the proposed Snoopy system in the real-world with data from 362 participants and show that our system offers a 3-fold improvement in the accuracy of inferring passwords compared to the state-of-the-art, without consuming excessive energy or computational resources. We also show that Snoopy is very resilient to user and device heterogeneity: it can be trained on crowd-sourced motion data (e.g. via Amazon Mechanical Turk), and then used to attack passwords from a new user, even if they are wearing a different model. This paper shows that, in the wrong hands, Snoopy can potentially cause serious leaks of sensitive information. By raising awareness, we invite the community and manufacturers to revisit the risks of continuous motion sensing on smart wearable devices.
Autonomous Learning for Face Recognition in the Wild via Ambient Wireless Cues
Aug 14, 2019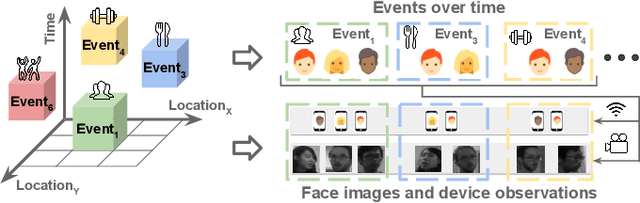

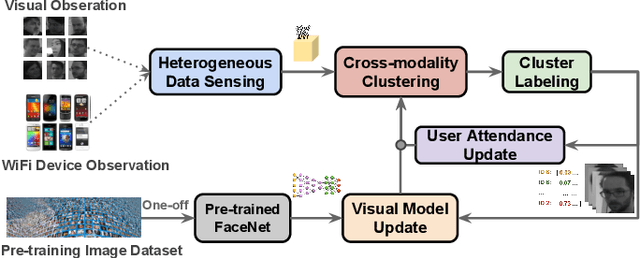
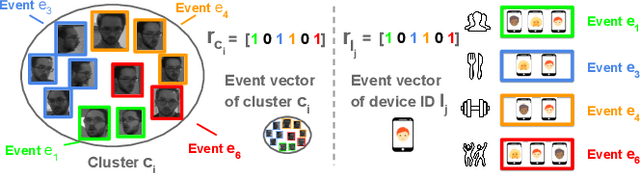
Facial recognition is a key enabling component for emerging Internet of Things (IoT) services such as smart homes or responsive offices. Through the use of deep neural networks, facial recognition has achieved excellent performance. However, this is only possibly when trained with hundreds of images of each user in different viewing and lighting conditions. Clearly, this level of effort in enrolment and labelling is impossible for wide-spread deployment and adoption. Inspired by the fact that most people carry smart wireless devices with them, e.g. smartphones, we propose to use this wireless identifier as a supervisory label. This allows us to curate a dataset of facial images that are unique to a certain domain e.g. a set of people in a particular office. This custom corpus can then be used to finetune existing pre-trained models e.g. FaceNet. However, due to the vagaries of wireless propagation in buildings, the supervisory labels are noisy and weak.We propose a novel technique, AutoTune, which learns and refines the association between a face and wireless identifier over time, by increasing the inter-cluster separation and minimizing the intra-cluster distance. Through extensive experiments with multiple users on two sites, we demonstrate the ability of AutoTune to design an environment-specific, continually evolving facial recognition system with entirely no user effort.
Dynamic Demand Prediction for Expanding Electric Vehicle Sharing Systems: A Graph Sequence Learning Approach
Mar 10, 2019
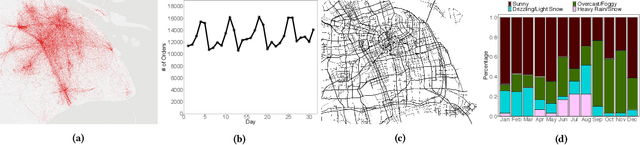
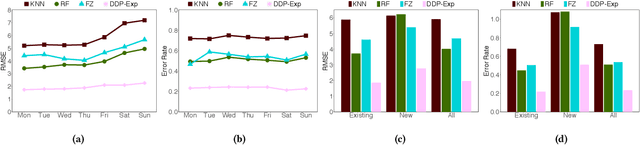
Electric Vehicle (EV) sharing systems have recently experienced unprecedented growth across the globe. During their fast expansion, one fundamental determinant for success is the capability of dynamically predicting the demand of stations as the entire system is evolving continuously. There are several challenges in this dynamic demand prediction problem. Firstly, unlike most of the existing work which predicts demand only for static systems or at few stages of expansion, in the real world we often need to predict the demand as or even before stations are being deployed or closed, to provide information and support for decision making. Secondly, for the stations to be deployed, there is no historical record or additional mobility data available to help the prediction of their demand. Finally, the impact of deploying/closing stations to the remaining stations in the system can be very complex. To address these challenges, in this paper we propose a novel dynamic demand prediction approach based on graph sequence learning, which is able to model the dynamics during the system expansion and predict demand accordingly. We use a local temporal encoding process to handle the available historical data at individual stations, and a dynamic spatial encoding process to take correlations between stations into account with graph convolutional neural networks. The encoded features are fed to a multi-scale prediction network, which forecasts both the long-term expected demand of the stations and their instant demand in the near future. We evaluate the proposed approach on real-world data collected from a major EV sharing platform in Shanghai for one year. Experimental results demonstrate that our approach significantly outperforms the state of the art, showing up to three-fold performance gain in predicting demand for the rapidly expanding EV sharing system.