 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity Encoder for Personalized Diffusion
Apr 14, 2023



Many applications can benefit from personalized image generation models, including image enhancement, video conferences, just to name a few. Existing works achieved personalization by fine-tuning one model for each person. While being successful, this approach incurs additional computation and storage overhead for each new identity. Furthermore, it usually expects tens or hundreds of examples per identity to achieve the best performance. To overcome these challenges, we propose an encoder-based approach for personalization. We learn an identity encoder which can extract an identity representation from a set of reference images of a subject, together with a diffusion generator that can generate new images of the subject conditioned on the identity representation. Once being trained, the model can be used to generate images of arbitrary identities given a few examples even if the model hasn't been trained on the identity. Our approach greatly reduces the overhead for personalized image generation and is more applicable in many potential applications. Empirical results show that our approach consistently outperforms existing fine-tuning based approach in both image generation and reconstruction, and the outputs is preferred by users more than 95% of the time compared with the best performing baseline.
Taming Encoder for Zero Fine-tuning Image Customization with Text-to-Image Diffusion Models
Apr 05, 2023This paper proposes a method for generating images of customized objects specified by users. The method is based on a general framework that bypasses the lengthy optimization required by previous approaches, which often employ a per-object optimization paradigm. Our framework adopts an encoder to capture high-level identifiable semantics of objects, producing an object-specific embedding with only a single feed-forward pass. The acquired object embedding is then passed to a text-to-image synthesis model for subsequent generation. To effectively blend a object-aware embedding space into a well developed text-to-image model under the same generation context, we investigate different network designs and training strategies, and propose a simple yet effective regularized joint training scheme with an object identity preservation loss. Additionally, we propose a caption generation scheme that become a critical piece in fostering object specific embedding faithfully reflected into the generation process, while keeping control and editing abilities. Once trained, the network is able to produce diverse content and styles, conditioned on both texts and objects. We demonstrate through experiments that our proposed method is able to synthesize images with compelling output quality, appearance diversity, and object fidelity, without the need of test-time optimization. Systematic studies are also conducted to analyze our models, providing insights for future work.
Domain Generalization with Adversarial Intensity Attack for Medical Image Segmentation
Apr 05, 2023Most statistical learning algorithms rely on an over-simplified assumption, that is, the train and test data are independent and identically distributed. In real-world scenarios, however, it is common for models to encounter data from new and different domains to which they were not exposed to during training. This is often the case in medical imaging applications due to differences in acquisition devices, imaging protocols, and patient characteristics. To address this problem, domain generalization (DG) is a promising direction as it enables models to handle data from previously unseen domains by learning domain-invariant features robust to variations across different domains. To this end, we introduce a novel DG method called Adversarial Intensity Attack (AdverIN), which leverages adversarial training to generate training data with an infinite number of styles and increase data diversity while preserving essential content information. We conduct extensive evaluation experiments on various multi-domain segmentation datasets, including 2D retinal fundus optic disc/cup and 3D prostate MRI. Our results demonstrate that AdverIN significantly improves the generalization ability of the segmentation models, achieving significant improvement on these challenging datasets. Code is available upon publication.
Spatiotemporally Discriminative Video-Language Pre-Training with Text Grounding
Mar 28, 2023



Most of existing video-language pre-training methods focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. In this work, we propose a simple yet effective video-language pre-training framework, namely G-ViLM, to learn discriminative spatiotemporal features. Two novel designs involving spatiotemporal grounding and temporal grouping promote learning local region-noun alignment and temporal-aware features simultaneously. Specifically, spatiotemporal grounding aggregates semantically similar video tokens and aligns them with noun phrases extracted from the caption to promote local region-noun correspondences. Moreover, temporal grouping leverages cut-and-paste to manually create temporal scene changes and then learns distinguishable features from different scenes. Comprehensive evaluations demonstrate that G-ViLM performs favorably against existing approaches on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition and temporal action localization. G-ViLM performs competitively on all evaluated tasks and in particular achieves R@10 of 65.1 on zero-shot MSR-VTT retrieval, over 9% higher than the state-of-the-art method.
Unified Visual Relationship Detection with Vision and Language Models
Mar 16, 2023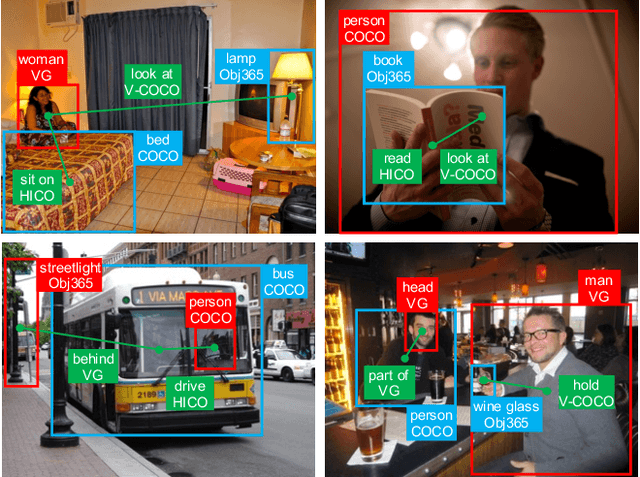
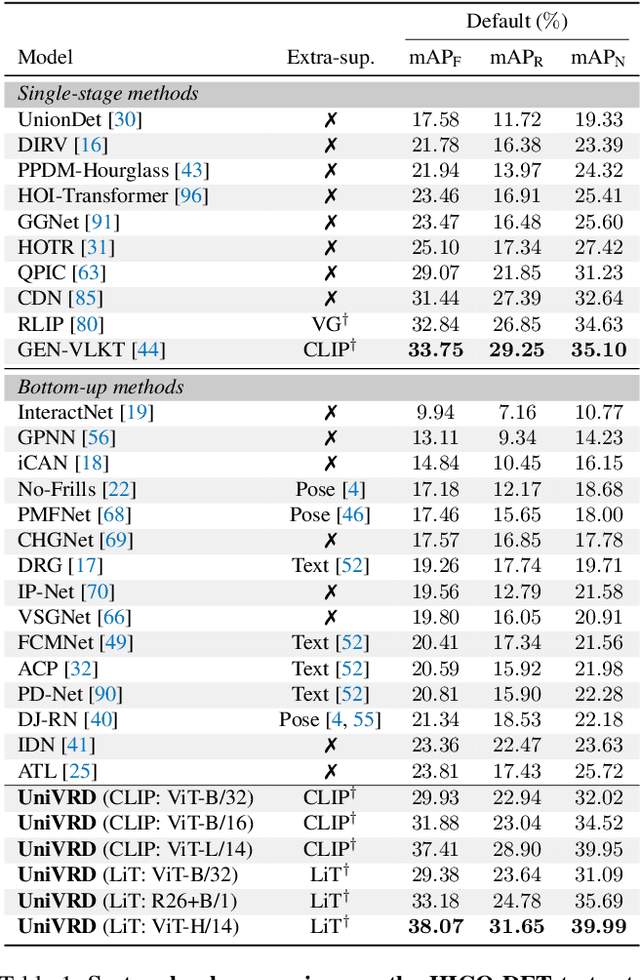
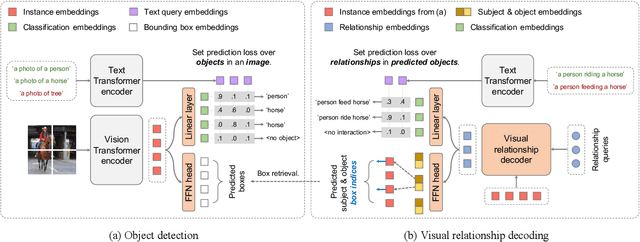
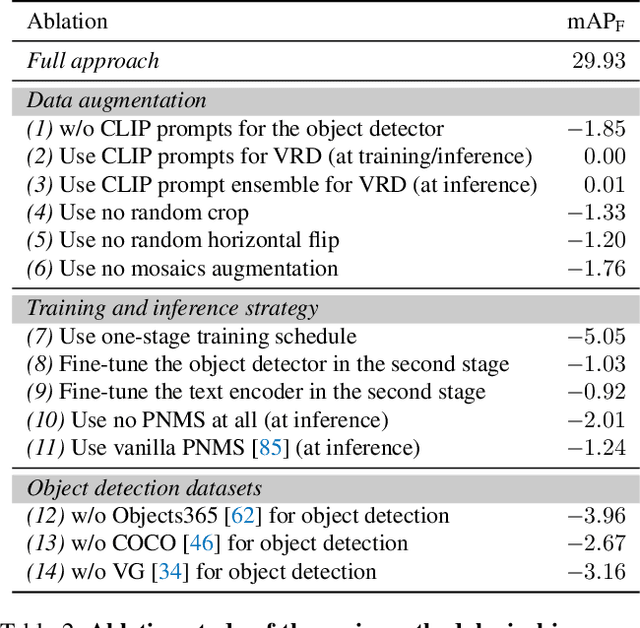
This work focuses on training a single visual relationship detector predicting over the union of label spaces from multiple datasets. Merging labels spanning different datasets could be challenging due to inconsistent taxonomies. The issue is exacerbated in visual relationship detection when second-order visual semantics are introduced between pairs of objects. To address this challenge, we propose UniVRD, a novel bottom-up method for Unified Visual Relationship Detection by leveraging vision and language models (VLMs). VLMs provide well-aligned image and text embeddings, where similar relationships are optimized to be close to each other for semantic unification. Our bottom-up design enables the model to enjoy the benefit of training with both object detection and visual relationship datasets. Empirical results on both human-object interaction detection and scene-graph generation demonstrate the competitive performance of our model. UniVRD achieves 38.07 mAP on HICO-DET, outperforming the current best bottom-up HOI detector by 60% relatively. More importantly, we show that our unified detector performs as well as dataset-specific models in mAP, and achieves further improvements when we scale up the model.
On Calibrating Semantic Segmentation Models: Analysis and An Algorithm
Dec 22, 2022



We study the problem of semantic segmentation calibration. For image classification, lots of existing solutions are proposed to alleviate model miscalibration of confidence. However, to date, confidence calibration research on semantic segmentation is still limited. We provide a systematic study on the calibration of semantic segmentation models and propose a simple yet effective approach. First, we find that model capacity, crop size, multi-scale testing, and prediction correctness have impact on calibration. Among them, prediction correctness, especially misprediction, is more important to miscalibration due to over-confidence. Next, we propose a simple, unifying, and effective approach, namely selective scaling, by separating correct/incorrect prediction for scaling and more focusing on misprediction logit smoothing. Then, we study popular existing calibration methods and compare them with selective scaling on semantic segmentation calibration. We conduct extensive experiments with a variety of benchmarks on both in-domain and domain-shift calibration, and show that selective scaling consistently outperforms other methods.
LESS: Label-Efficient Semantic Segmentation for LiDAR Point Clouds
Oct 14, 2022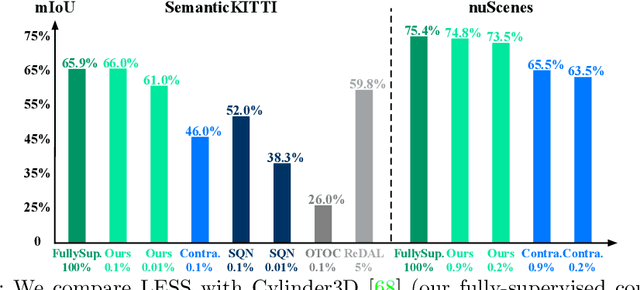
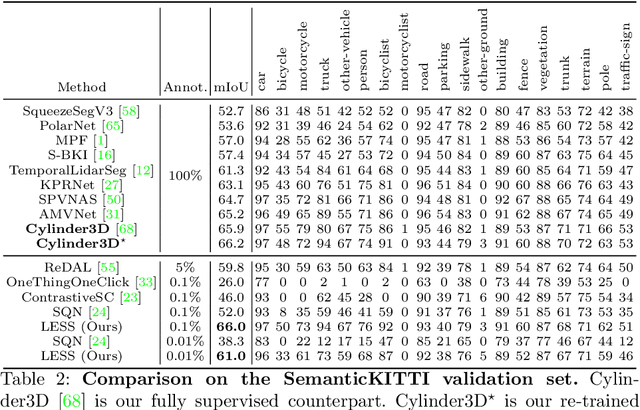
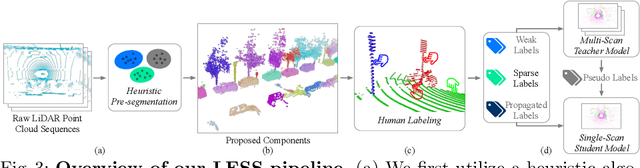
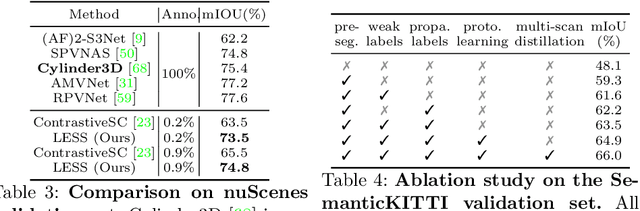
Semantic segmentation of LiDAR point clouds is an important task in autonomous driving. However, training deep models via conventional supervised methods requires large datasets which are costly to label. It is critical to have label-efficient segmentation approaches to scale up the model to new operational domains or to improve performance on rare cases. While most prior works focus on indoor scenes, we are one of the first to propose a label-efficient semantic segmentation pipeline for outdoor scenes with LiDAR point clouds. Our method co-designs an efficient labeling process with semi/weakly supervised learning and is applicable to nearly any 3D semantic segmentation backbones. Specifically, we leverage geometry patterns in outdoor scenes to have a heuristic pre-segmentation to reduce the manual labeling and jointly design the learning targets with the labeling process. In the learning step, we leverage prototype learning to get more descriptive point embeddings and use multi-scan distillation to exploit richer semantics from temporally aggregated point clouds to boost the performance of single-scan models. Evaluated on the SemanticKITTI and the nuScenes datasets, we show that our proposed method outperforms existing label-efficient methods. With extremely limited human annotations (e.g., 0.1% point labels), our proposed method is even highly competitive compared to the fully supervised counterpart with 100% labels.
Open Long-Tailed Recognition in a Dynamic World
Aug 17, 2022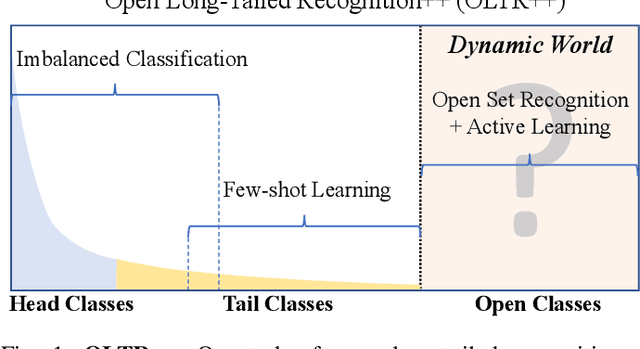
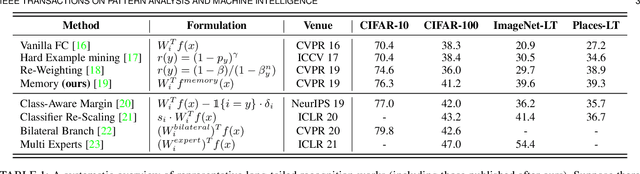
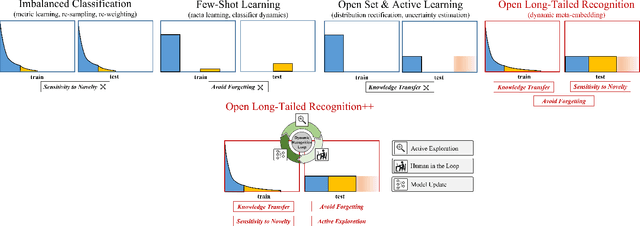

Real world data often exhibits a long-tailed and open-ended (with unseen classes) distribution. A practical recognition system must balance between majority (head) and minority (tail) classes, generalize across the distribution, and acknowledge novelty upon the instances of unseen classes (open classes). We define Open Long-Tailed Recognition++ (OLTR++) as learning from such naturally distributed data and optimizing for the classification accuracy over a balanced test set which includes both known and open classes. OLTR++ handles imbalanced classification, few-shot learning, open-set recognition, and active learning in one integrated algorithm, whereas existing classification approaches often focus only on one or two aspects and deliver poorly over the entire spectrum. The key challenges are: 1) how to share visual knowledge between head and tail classes, 2) how to reduce confusion between tail and open classes, and 3) how to actively explore open classes with learned knowledge. Our algorithm, OLTR++, maps images to a feature space such that visual concepts can relate to each other through a memory association mechanism and a learned metric (dynamic meta-embedding) that both respects the closed world classification of seen classes and acknowledges the novelty of open classes. Additionally, we propose an active learning scheme based on visual memory, which learns to recognize open classes in a data-efficient manner for future expansions. On three large-scale open long-tailed datasets we curated from ImageNet (object-centric), Places (scene-centric), and MS1M (face-centric) data, as well as three standard benchmarks (CIFAR-10-LT, CIFAR-100-LT, and iNaturalist-18), our approach, as a unified framework, consistently demonstrates competitive performance. Notably, our approach also shows strong potential for the active exploration of open classes and the fairness analysis of minority groups.
medXGAN: Visual Explanations for Medical Classifiers through a Generative Latent Space
Apr 17, 2022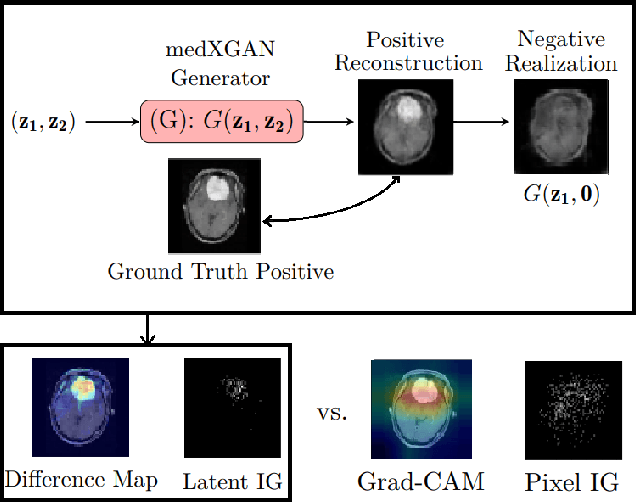
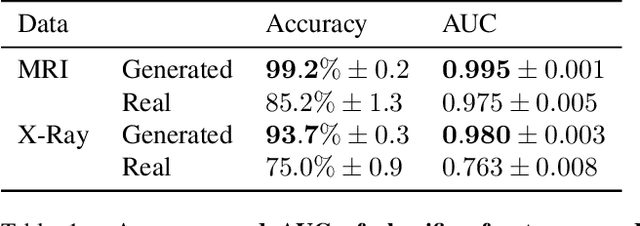
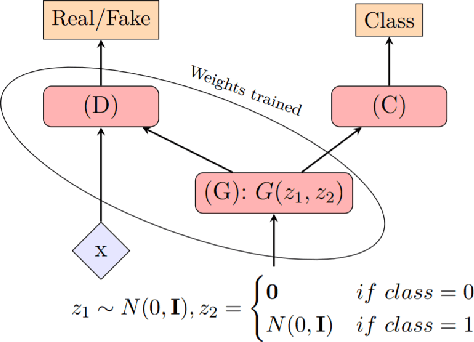
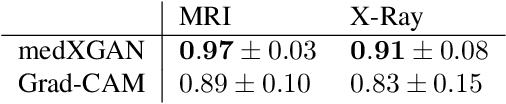
Despite the surge of deep learning in the past decade, some users are skeptical to deploy these models in practice due to their black-box nature. Specifically, in the medical space where there are severe potential repercussions, we need to develop methods to gain confidence in the models' decisions. To this end, we propose a novel medical imaging generative adversarial framework, medXGAN (medical eXplanation GAN), to visually explain what a medical classifier focuses on in its binary predictions. By encoding domain knowledge of medical images, we are able to disentangle anatomical structure and pathology, leading to fine-grained visualization through latent interpolation. Furthermore, we optimize the latent space such that interpolation explains how the features contribute to the classifier's output. Our method outperforms baselines such as Gradient-Weighted Class Activation Mapping (Grad-CAM) and Integrated Gradients in localization and explanatory ability. Additionally, a combination of the medXGAN with Integrated Gradients can yield explanations more robust to noise. The code is available at: https://avdravid.github.io/medXGAN_page/.
Surrogate Gap Minimization Improves Sharpness-Aware Training
Mar 19, 2022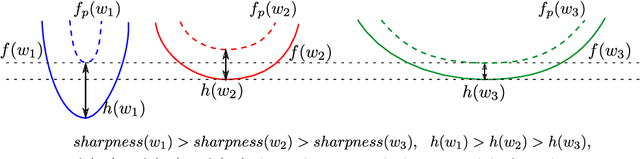
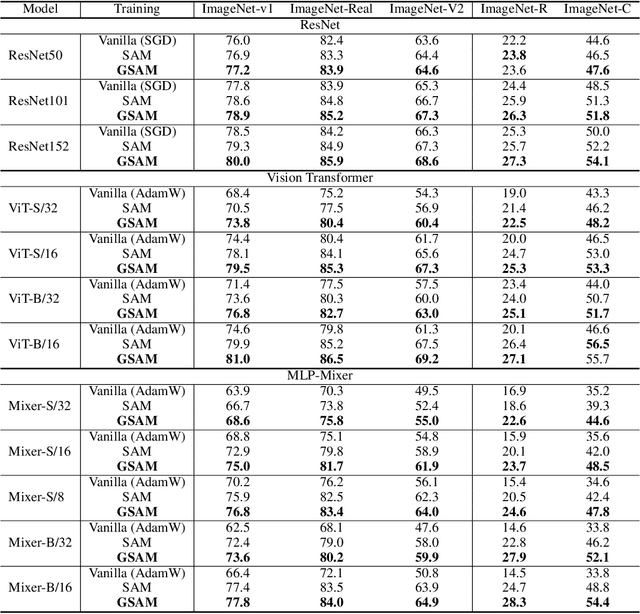


The recently proposed Sharpness-Aware Minimization (SAM) improves generalization by minimizing a \textit{perturbed loss} defined as the maximum loss within a neighborhood in the parameter space. However, we show that both sharp and flat minima can have a low perturbed loss, implying that SAM does not always prefer flat minima. Instead, we define a \textit{surrogate gap}, a measure equivalent to the dominant eigenvalue of Hessian at a local minimum when the radius of the neighborhood (to derive the perturbed loss) is small. The surrogate gap is easy to compute and feasible for direct minimization during training. Based on the above observations, we propose Surrogate \textbf{G}ap Guided \textbf{S}harpness-\textbf{A}ware \textbf{M}inimization (GSAM), a novel improvement over SAM with negligible computation overhead. Conceptually, GSAM consists of two steps: 1) a gradient descent like SAM to minimize the perturbed loss, and 2) an \textit{ascent} step in the \textit{orthogonal} direction (after gradient decomposition) to minimize the surrogate gap and yet not affect the perturbed loss. GSAM seeks a region with both small loss (by step 1) and low sharpness (by step 2), giving rise to a model with high generalization capabilities. Theoretically, we show the convergence of GSAM and provably better generalization than SAM. Empirically, GSAM consistently improves generalization (e.g., +3.2\% over SAM and +5.4\% over AdamW on ImageNet top-1 accuracy for ViT-B/32). Code is released at \url{ https://sites.google.com/view/gsam-iclr22/home}.