 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Scene-based Topic Channel Construction System for E-Commerce
Oct 06, 2022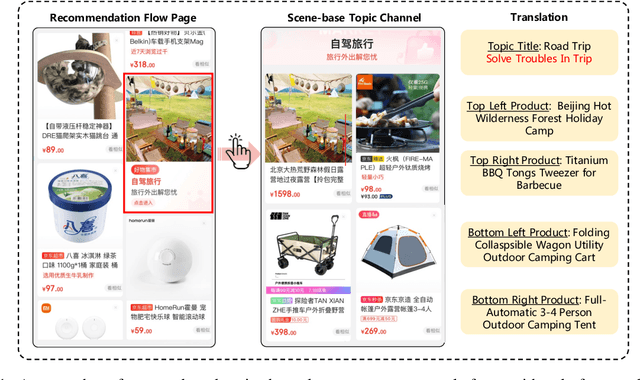

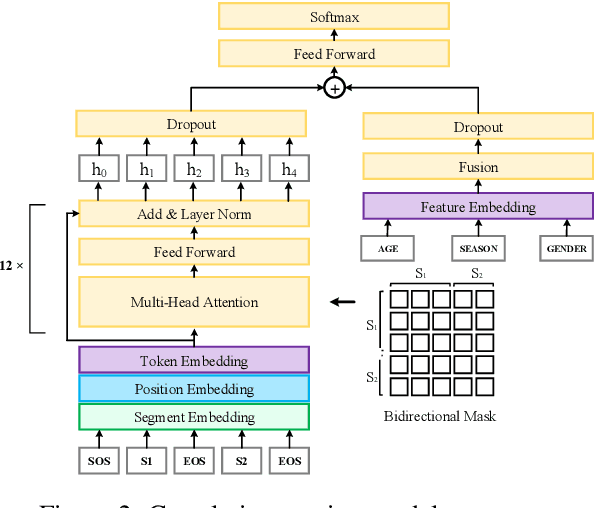
Scene marketing that well demonstrates user interests within a certain scenario has proved effective for offline shopping. To conduct scene marketing for e-commerce platforms, this work presents a novel product form, scene-based topic channel which typically consists of a list of diverse products belonging to the same usage scenario and a topic title that describes the scenario with marketing words. As manual construction of channels is time-consuming due to billions of products as well as dynamic and diverse customers' interests, it is necessary to leverage AI techniques to automatically construct channels for certain usage scenarios and even discover novel topics. To be specific, we first frame the channel construction task as a two-step problem, i.e., scene-based topic generation and product clustering, and propose an E-commerce Scene-based Topic Channel construction system (i.e., ESTC) to achieve automated production, consisting of scene-based topic generation model for the e-commerce domain, product clustering on the basis of topic similarity, as well as quality control based on automatic model filtering and human screening. Extensive offline experiments and online A/B test validates the effectiveness of such a novel product form as well as the proposed system. In addition, we also introduce the experience of deploying the proposed system on a real-world e-commerce recommendation platform.
Pre-training Tasks for User Intent Detection and Embedding Retrieval in E-commerce Search
Aug 22, 2022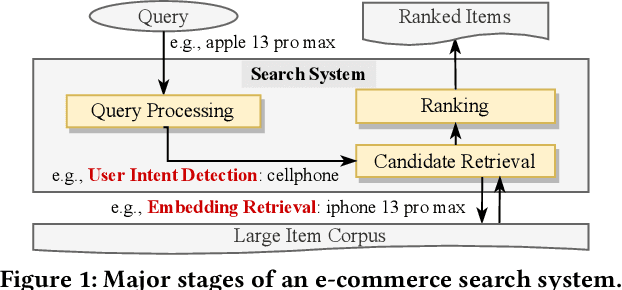

BERT-style models pre-trained on the general corpus (e.g., Wikipedia) and fine-tuned on specific task corpus, have recently emerged as breakthrough techniques in many NLP tasks: question answering, text classification, sequence labeling and so on. However, this technique may not always work, especially for two scenarios: a corpus that contains very different text from the general corpus Wikipedia, or a task that learns embedding spacial distribution for a specific purpose (e.g., approximate nearest neighbor search). In this paper, to tackle the above two scenarios that we have encountered in an industrial e-commerce search system, we propose customized and novel pre-training tasks for two critical modules: user intent detection and semantic embedding retrieval. The customized pre-trained models after fine-tuning, being less than 10% of BERT-base's size in order to be feasible for cost-efficient CPU serving, significantly improve the other baseline models: 1) no pre-training model and 2) fine-tuned model from the official pre-trained BERT using general corpus, on both offline datasets and online system. We have open sourced our datasets for the sake of reproducibility and future works.
Context-Consistent Semantic Image Editing with Style-Preserved Modulation
Jul 13, 2022
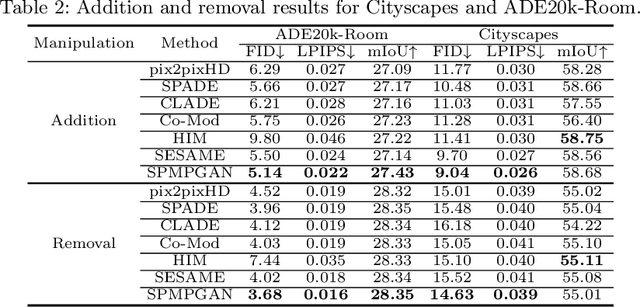
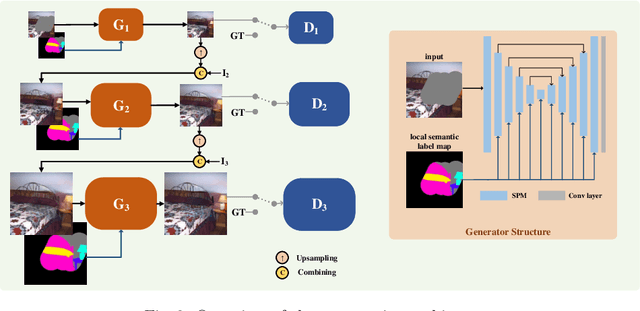
Semantic image editing utilizes local semantic label maps to generate the desired content in the edited region. A recent work borrows SPADE block to achieve semantic image editing. However, it cannot produce pleasing results due to style discrepancy between the edited region and surrounding pixels. We attribute this to the fact that SPADE only uses an image-independent local semantic layout but ignores the image-specific styles included in the known pixels. To address this issue, we propose a style-preserved modulation (SPM) comprising two modulations processes: The first modulation incorporates the contextual style and semantic layout, and then generates two fused modulation parameters. The second modulation employs the fused parameters to modulate feature maps. By using such two modulations, SPM can inject the given semantic layout while preserving the image-specific context style. Moreover, we design a progressive architecture for generating the edited content in a coarse-to-fine manner. The proposed method can obtain context-consistent results and significantly alleviate the unpleasant boundary between the generated regions and the known pixels.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022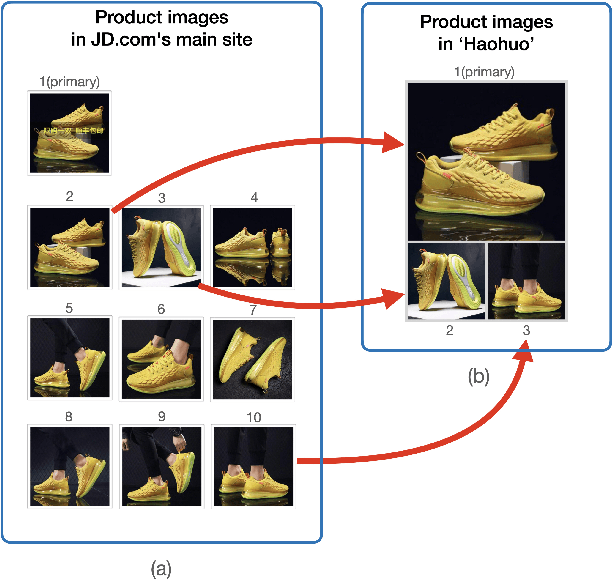

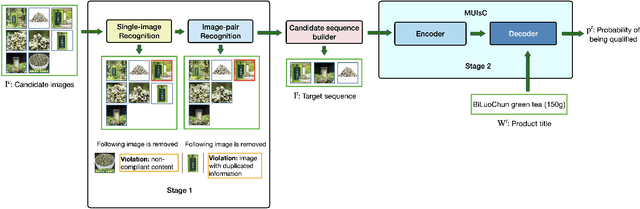
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Automatic Controllable Product Copywriting for E-Commerce
Jun 21, 2022
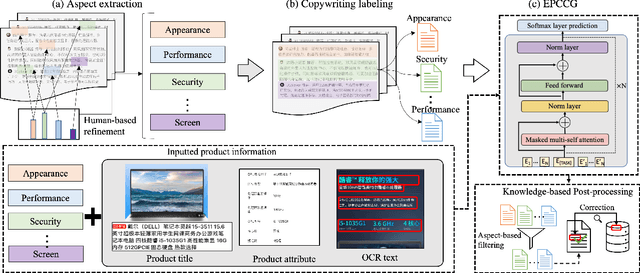
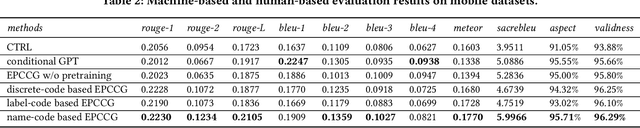
Automatic product description generation for e-commerce has witnessed significant advancement in the past decade. Product copywriting aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. As the services provided by e-commerce platforms become diverse, it is necessary to adapt the patterns of automatically-generated descriptions dynamically. In this paper, we report our experience in deploying an E-commerce Prefix-based Controllable Copywriting Generation (EPCCG) system into the JD.com e-commerce product recommendation platform. The development of the system contains two main components: 1) copywriting aspect extraction; 2) weakly supervised aspect labeling; 3) text generation with a prefix-based language model; 4) copywriting quality control. We conduct experiments to validate the effectiveness of the proposed EPCCG. In addition, we introduce the deployed architecture which cooperates with the EPCCG into the real-time JD.com e-commerce recommendation platform and the significant payoff since deployment.
Robust Meta-learning with Sampling Noise and Label Noise via Eigen-Reptile
Jun 04, 2022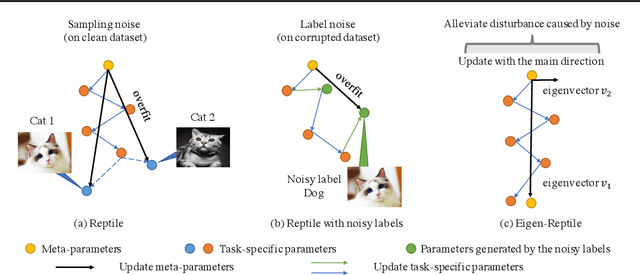
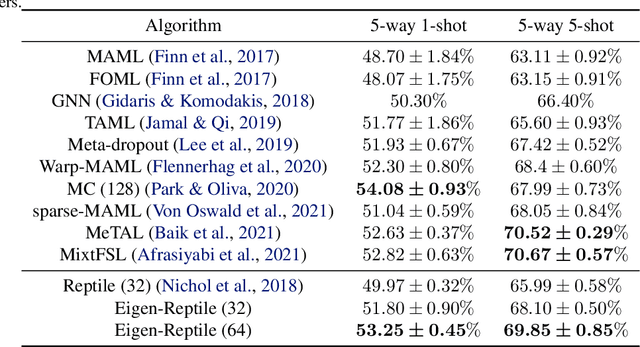
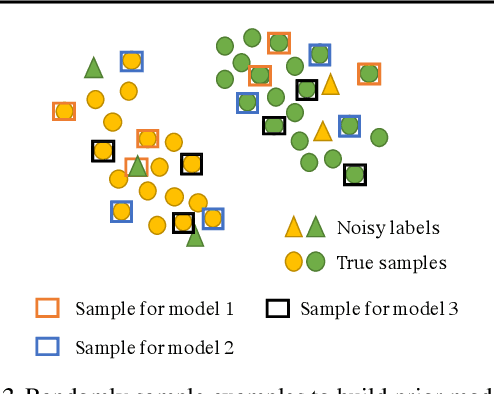
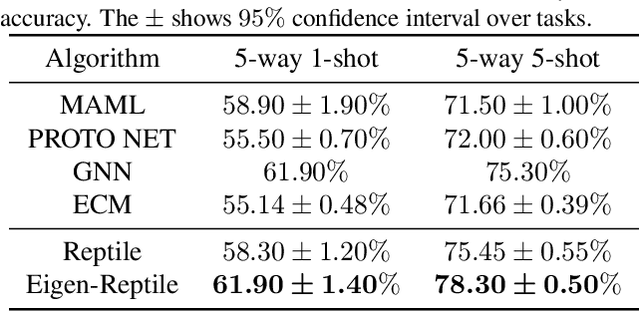
Recent years have seen a surge of interest in meta-learning techniques for tackling the few-shot learning (FSL) problem. However, the meta-learner is prone to overfitting since there are only a few available samples, which can be identified as sampling noise on a clean dataset. Moreover, when handling the data with noisy labels, the meta-learner could be extremely sensitive to label noise on a corrupted dataset. To address these two challenges, we present Eigen-Reptile (ER) that updates the meta-parameters with the main direction of historical task-specific parameters to alleviate sampling and label noise. Specifically, the main direction is computed in a fast way, where the scale of the calculated matrix is related to the number of gradient steps instead of the number of parameters. Furthermore, to obtain a more accurate main direction for Eigen-Reptile in the presence of many noisy labels, we further propose Introspective Self-paced Learning (ISPL). We have theoretically and experimentally demonstrated the soundness and effectiveness of the proposed Eigen-Reptile and ISPL. Particularly, our experiments on different tasks show that the proposed method is able to outperform or achieve highly competitive performance compared with other gradient-based methods with or without noisy labels. The code and data for the proposed method are provided for research purposes https://github.com/Anfeather/Eigen-Reptile.
Meta Policy Learning for Cold-Start Conversational Recommendation
May 24, 2022
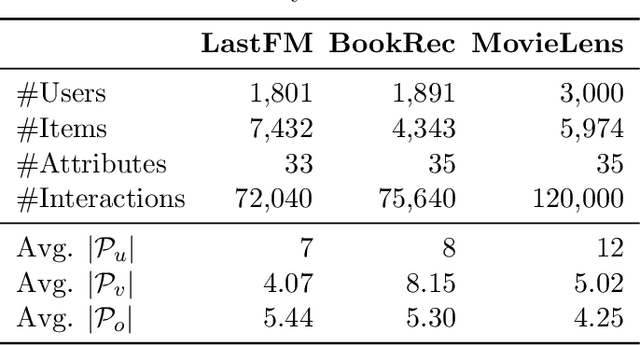
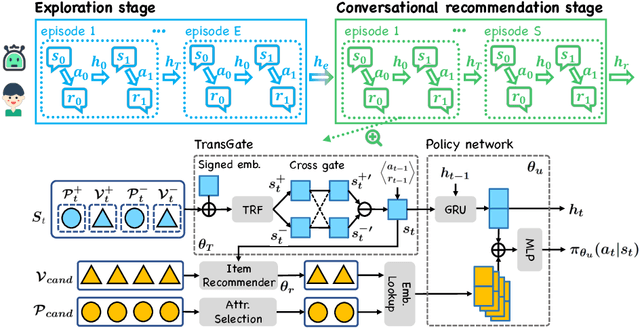
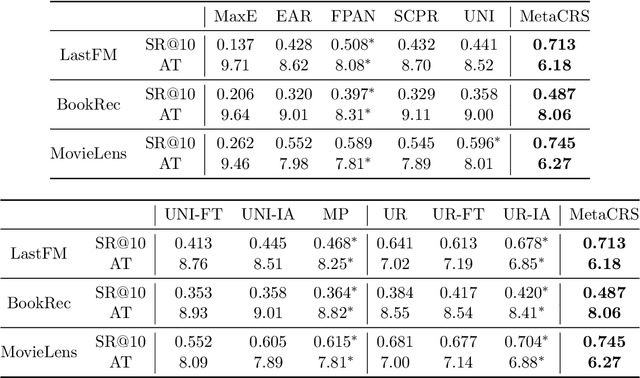
Conversational recommender systems (CRS) explicitly solicit users' preferences for improved recommendations on the fly. Most existing CRS solutions employ reinforcement learning methods to train a single policy for a population of users. However, for users new to the system, such a global policy becomes ineffective to produce conversational recommendations, i.e., the cold-start challenge. In this paper, we study CRS policy learning for cold-start users via meta reinforcement learning. We propose to learn a meta policy and adapt it to new users with only a few trials of conversational recommendations. To facilitate policy adaptation, we design three synergetic components. First is a meta-exploration policy dedicated to identify user preferences via exploratory conversations. Second is a Transformer-based state encoder to model a user's both positive and negative feedback during the conversation. And third is an adaptive item recommender based on the embedded states. Extensive experiments on three datasets demonstrate the advantage of our solution in serving new users, compared with a rich set of state-of-the-art CRS solutions.
Scenario-based Multi-product Advertising Copywriting Generation for E-Commerce
May 21, 2022

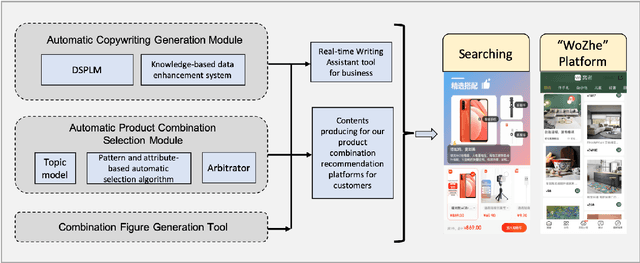
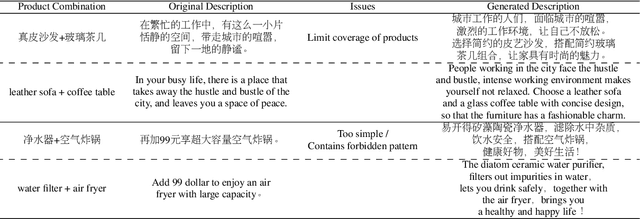
In this paper, we proposed an automatic Scenario-based Multi-product Advertising Copywriting Generation system (SMPACG) for E-Commerce, which has been deployed on a leading Chinese e-commerce platform. The proposed SMPACG consists of two main components: 1) an automatic multi-product combination selection module, which itself is consisted of a topic prediction model, a pattern and attribute-based selection model and an arbitrator model; and 2) an automatic multi-product advertising copywriting generation module, which combines our proposed domain-specific pretrained language model and knowledge-based data enhancement model. The SMPACG is the first system that realizes automatic scenario-based multi-product advertising contents generation, which achieves significant improvements over other state-of-the-art methods. The SMPACG has been not only developed for directly serving for our e-commerce recommendation system, but also used as a real-time writing assistant tool for merchants.
Improving Long Tailed Document-Level Relation Extraction via Easy Relation Augmentation and Contrastive Learning
May 21, 2022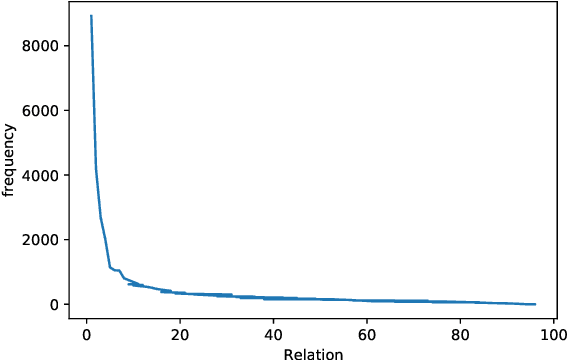
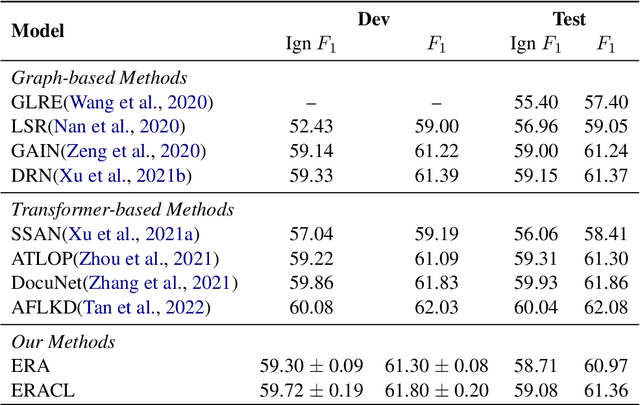
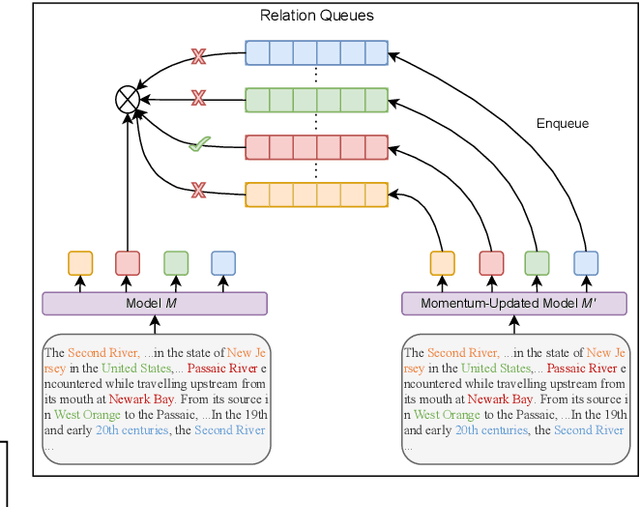
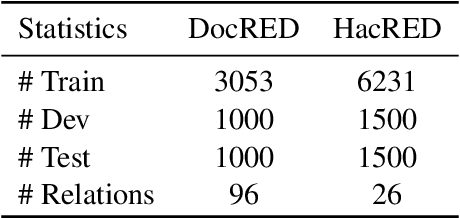
Towards real-world information extraction scenario, research of relation extraction is advancing to document-level relation extraction(DocRE). Existing approaches for DocRE aim to extract relation by encoding various information sources in the long context by novel model architectures. However, the inherent long-tailed distribution problem of DocRE is overlooked by prior work. We argue that mitigating the long-tailed distribution problem is crucial for DocRE in the real-world scenario. Motivated by the long-tailed distribution problem, we propose an Easy Relation Augmentation(ERA) method for improving DocRE by enhancing the performance of tailed relations. In addition, we further propose a novel contrastive learning framework based on our ERA, i.e., ERACL, which can further improve the model performance on tailed relations and achieve competitive overall DocRE performance compared to the state-of-arts.
Reducing Flipping Errors in Deep Neural Networks
Mar 16, 2022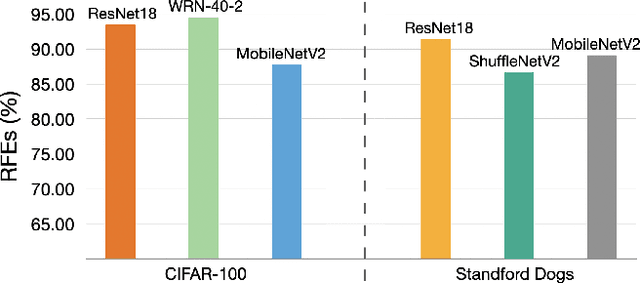
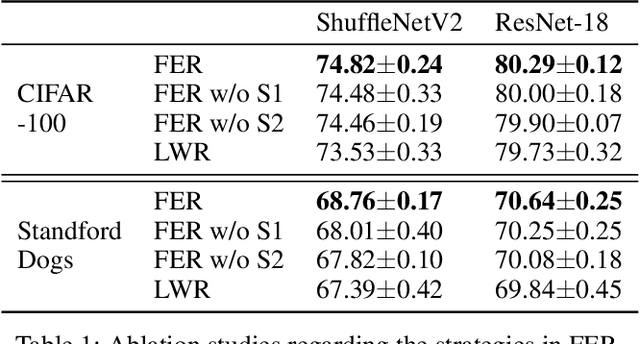
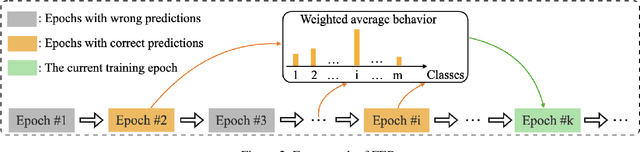
Deep neural networks (DNNs) have been widely applied in various domains in artificial intelligence including computer vision and natural language processing. A DNN is typically trained for many epochs and then a validation dataset is used to select the DNN in an epoch (we simply call this epoch "the last epoch") as the final model for making predictions on unseen samples, while it usually cannot achieve a perfect accuracy on unseen samples. An interesting question is "how many test (unseen) samples that a DNN misclassifies in the last epoch were ever correctly classified by the DNN before the last epoch?". In this paper, we empirically study this question and find on several benchmark datasets that the vast majority of the misclassified samples in the last epoch were ever classified correctly before the last epoch, which means that the predictions for these samples were flipped from "correct" to "wrong". Motivated by this observation, we propose to restrict the behavior changes of a DNN on the correctly-classified samples so that the correct local boundaries can be maintained and the flipping error on unseen samples can be largely reduced. Extensive experiments on different benchmark datasets with different modern network architectures demonstrate that the proposed flipping error reduction (FER) approach can substantially improve the generalization, the robustness, and the transferability of DNNs without introducing any additional network parameters or inference cost, only with a negligible training overhead.