 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
KAT-Coder-V2 Technical Report
Mar 29, 2026We present KAT-Coder-V2, an agentic coding model developed by the KwaiKAT team at Kuaishou. KAT-Coder-V2 adopts a "Specialize-then-Unify" paradigm that decomposes agentic coding into five expert domains - SWE, WebCoding, Terminal, WebSearch, and General - each undergoing independent supervised fine-tuning and reinforcement learning, before being consolidated into a single model via on-policy distillation. We develop KwaiEnv, a modular infrastructure sustaining tens of thousands of concurrent sandbox instances, and scale RL training along task complexity, intent alignment, and scaffold generalization. We further propose MCLA for stabilizing MoE RL training and Tree Training for eliminating redundant computation over tree-structured trajectories with up to 6.2x speedup. KAT-Coder-V2 achieves 79.6% on SWE-bench Verified (vs. Claude Opus 4.6 at 80.8%), 88.7 on PinchBench (surpassing GLM-5 and MiniMax M2.7), ranks first across all three frontend aesthetics scenarios, and maintains strong generalist scores on Terminal-Bench Hard (46.8) and tau^2-Bench (93.9). Our model is publicly available at https://streamlake.com/product/kat-coder.
NTIRE 2025 Challenge on Short-form UGC Video Quality Assessment and Enhancement: KwaiSR Dataset and Study
Apr 21, 2025In this work, we build the first benchmark dataset for short-form UGC Image Super-resolution in the wild, termed KwaiSR, intending to advance the research on developing image super-resolution algorithms for short-form UGC platforms. This dataset is collected from the Kwai Platform, which is composed of two parts, i.e., synthetic and wild parts. Among them, the synthetic dataset, including 1,900 image pairs, is produced by simulating the degradation following the distribution of real-world low-quality short-form UGC images, aiming to provide the ground truth for training and objective comparison in the validation/testing. The wild dataset contains low-quality images collected directly from the Kwai Platform, which are filtered using the quality assessment method KVQ from the Kwai Platform. As a result, the KwaiSR dataset contains 1800 synthetic image pairs and 1900 wild images, which are divided into training, validation, and testing parts with a ratio of 8:1:1. Based on the KwaiSR dataset, we organize the NTIRE 2025 challenge on a second short-form UGC Video quality assessment and enhancement, which attracts lots of researchers to develop the algorithm for it. The results of this competition have revealed that our KwaiSR dataset is pretty challenging for existing Image SR methods, which is expected to lead to a new direction in the image super-resolution field. The dataset can be found from https://lixinustc.github.io/NTIRE2025-KVQE-KwaSR-KVQ.github.io/.
Disentangled Graph Social Recommendation
Mar 14, 2023Social recommender systems have drawn a lot of attention in many online web services, because of the incorporation of social information between users in improving recommendation results. Despite the significant progress made by existing solutions, we argue that current methods fall short in two limitations: (1) Existing social-aware recommendation models only consider collaborative similarity between items, how to incorporate item-wise semantic relatedness is less explored in current recommendation paradigms. (2) Current social recommender systems neglect the entanglement of the latent factors over heterogeneous relations (e.g., social connections, user-item interactions). Learning the disentangled representations with relation heterogeneity poses great challenge for social recommendation. In this work, we design a Disentangled Graph Neural Network (DGNN) with the integration of latent memory units, which empowers DGNN to maintain factorized representations for heterogeneous types of user and item connections. Additionally, we devise new memory-augmented message propagation and aggregation schemes under the graph neural architecture, allowing us to recursively distill semantic relatedness into the representations of users and items in a fully automatic manner. Extensive experiments on three benchmark datasets verify the effectiveness of our model by achieving great improvement over state-of-the-art recommendation techniques. The source code is publicly available at: https://github.com/HKUDS/DGNN.
Entity Candidate Network for Whole-Aware Named Entity Recognition
Apr 29, 2020
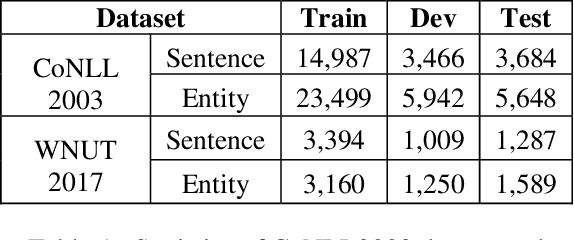
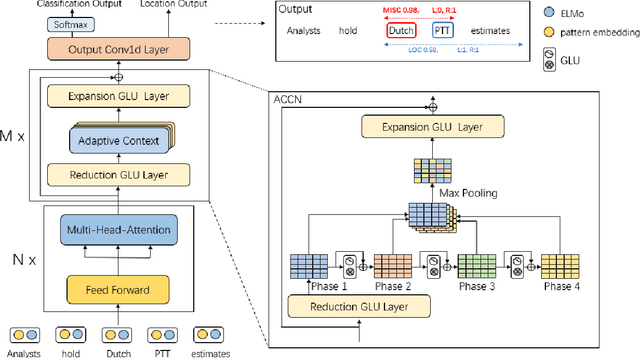
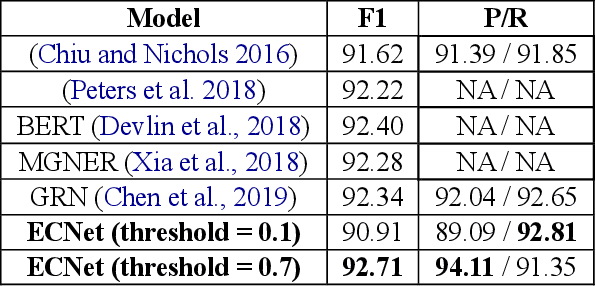
Named Entity Recognition (NER) is a crucial upstream task in Natural Language Processing (NLP). Traditional tag scheme approaches offer a single recognition that does not meet the needs of many downstream tasks such as coreference resolution. Meanwhile, Tag scheme approaches ignore the continuity of entities. Inspired by one-stage object detection models in computer vision (CV), this paper proposes a new no-tag scheme, the Whole-Aware Detection, which makes NER an object detection task. Meanwhile, this paper presents a novel model, Entity Candidate Network (ECNet), and a specific convolution network, Adaptive Context Convolution Network (ACCN), to fuse multi-scale contexts and encode entity information at each position. ECNet identifies the full span of a named entity and its type at each position based on Entity Loss. Furthermore, ECNet is regulable between the highest precision and the highest recall, while the tag scheme approaches are not. Experimental results on the CoNLL 2003 English dataset and the WNUT 2017 dataset show that ECNet outperforms other previous state-of-the-art methods.