 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopo-VM-UNetV2: Encoding Topology into Vision Mamba UNet for Polyp Segmentation
May 09, 2025



Convolutional neural network (CNN) and Transformer-based architectures are two dominant deep learning models for polyp segmentation. However, CNNs have limited capability for modeling long-range dependencies, while Transformers incur quadratic computational complexity. Recently, State Space Models such as Mamba have been recognized as a promising approach for polyp segmentation because they not only model long-range interactions effectively but also maintain linear computational complexity. However, Mamba-based architectures still struggle to capture topological features (e.g., connected components, loops, voids), leading to inaccurate boundary delineation and polyp segmentation. To address these limitations, we propose a new approach called Topo-VM-UNetV2, which encodes topological features into the Mamba-based state-of-the-art polyp segmentation model, VM-UNetV2. Our method consists of two stages: Stage 1: VM-UNetV2 is used to generate probability maps (PMs) for the training and test images, which are then used to compute topology attention maps. Specifically, we first compute persistence diagrams of the PMs, then we generate persistence score maps by assigning persistence values (i.e., the difference between death and birth times) of each topological feature to its birth location, finally we transform persistence scores into attention weights using the sigmoid function. Stage 2: These topology attention maps are integrated into the semantics and detail infusion (SDI) module of VM-UNetV2 to form a topology-guided semantics and detail infusion (Topo-SDI) module for enhancing the segmentation results. Extensive experiments on five public polyp segmentation datasets demonstrate the effectiveness of our proposed method. The code will be made publicly available.
Adapting a Segmentation Foundation Model for Medical Image Classification
May 09, 2025



Recent advancements in foundation models, such as the Segment Anything Model (SAM), have shown strong performance in various vision tasks, particularly image segmentation, due to their impressive zero-shot segmentation capabilities. However, effectively adapting such models for medical image classification is still a less explored topic. In this paper, we introduce a new framework to adapt SAM for medical image classification. First, we utilize the SAM image encoder as a feature extractor to capture segmentation-based features that convey important spatial and contextual details of the image, while freezing its weights to avoid unnecessary overhead during training. Next, we propose a novel Spatially Localized Channel Attention (SLCA) mechanism to compute spatially localized attention weights for the feature maps. The features extracted from SAM's image encoder are processed through SLCA to compute attention weights, which are then integrated into deep learning classification models to enhance their focus on spatially relevant or meaningful regions of the image, thus improving classification performance. Experimental results on three public medical image classification datasets demonstrate the effectiveness and data-efficiency of our approach.
White Light Specular Reflection Data Augmentation for Deep Learning Polyp Detection
May 08, 2025Colorectal cancer is one of the deadliest cancers today, but it can be prevented through early detection of malignant polyps in the colon, primarily via colonoscopies. While this method has saved many lives, human error remains a significant challenge, as missing a polyp could have fatal consequences for the patient. Deep learning (DL) polyp detectors offer a promising solution. However, existing DL polyp detectors often mistake white light reflections from the endoscope for polyps, which can lead to false positives.To address this challenge, in this paper, we propose a novel data augmentation approach that artificially adds more white light reflections to create harder training scenarios. Specifically, we first generate a bank of artificial lights using the training dataset. Then we find the regions of the training images that we should not add these artificial lights on. Finally, we propose a sliding window method to add the artificial light to the areas that fit of the training images, resulting in augmented images. By providing the model with more opportunities to make mistakes, we hypothesize that it will also have more chances to learn from those mistakes, ultimately improving its performance in polyp detection. Experimental results demonstrate the effectiveness of our new data augmentation method.
GMAI-VL-R1: Harnessing Reinforcement Learning for Multimodal Medical Reasoning
Apr 02, 2025Recent advances in general medical AI have made significant strides, but existing models often lack the reasoning capabilities needed for complex medical decision-making. This paper presents GMAI-VL-R1, a multimodal medical reasoning model enhanced by reinforcement learning (RL) to improve its reasoning abilities. Through iterative training, GMAI-VL-R1 optimizes decision-making, significantly boosting diagnostic accuracy and clinical support. We also develop a reasoning data synthesis method, generating step-by-step reasoning data via rejection sampling, which further enhances the model's generalization. Experimental results show that after RL training, GMAI-VL-R1 excels in tasks such as medical image diagnosis and visual question answering. While the model demonstrates basic memorization with supervised fine-tuning, RL is crucial for true generalization. Our work establishes new evaluation benchmarks and paves the way for future advancements in medical reasoning models. Code, data, and model will be released at \href{https://github.com/uni-medical/GMAI-VL-R1}{this link}.
LeX-Art: Rethinking Text Generation via Scalable High-Quality Data Synthesis
Mar 27, 2025We introduce LeX-Art, a comprehensive suite for high-quality text-image synthesis that systematically bridges the gap between prompt expressiveness and text rendering fidelity. Our approach follows a data-centric paradigm, constructing a high-quality data synthesis pipeline based on Deepseek-R1 to curate LeX-10K, a dataset of 10K high-resolution, aesthetically refined 1024$\times$1024 images. Beyond dataset construction, we develop LeX-Enhancer, a robust prompt enrichment model, and train two text-to-image models, LeX-FLUX and LeX-Lumina, achieving state-of-the-art text rendering performance. To systematically evaluate visual text generation, we introduce LeX-Bench, a benchmark that assesses fidelity, aesthetics, and alignment, complemented by Pairwise Normalized Edit Distance (PNED), a novel metric for robust text accuracy evaluation. Experiments demonstrate significant improvements, with LeX-Lumina achieving a 79.81% PNED gain on CreateBench, and LeX-FLUX outperforming baselines in color (+3.18%), positional (+4.45%), and font accuracy (+3.81%). Our codes, models, datasets, and demo are publicly available.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025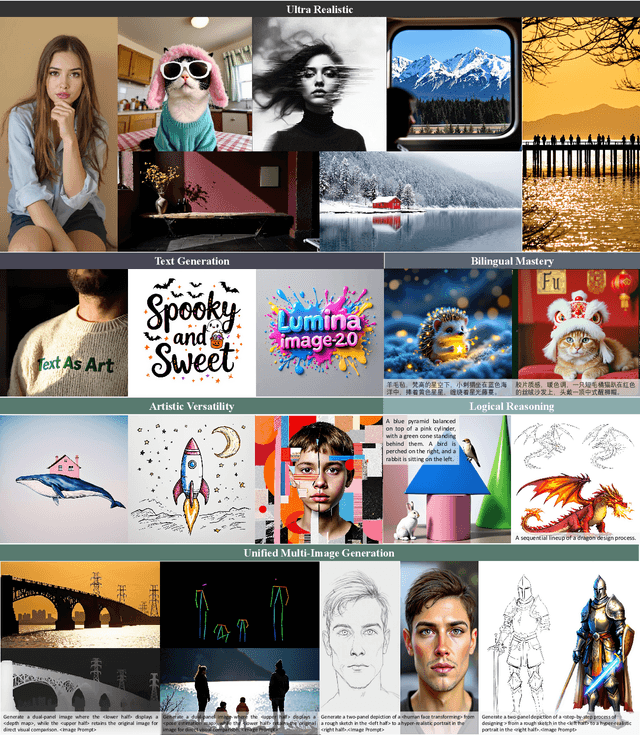
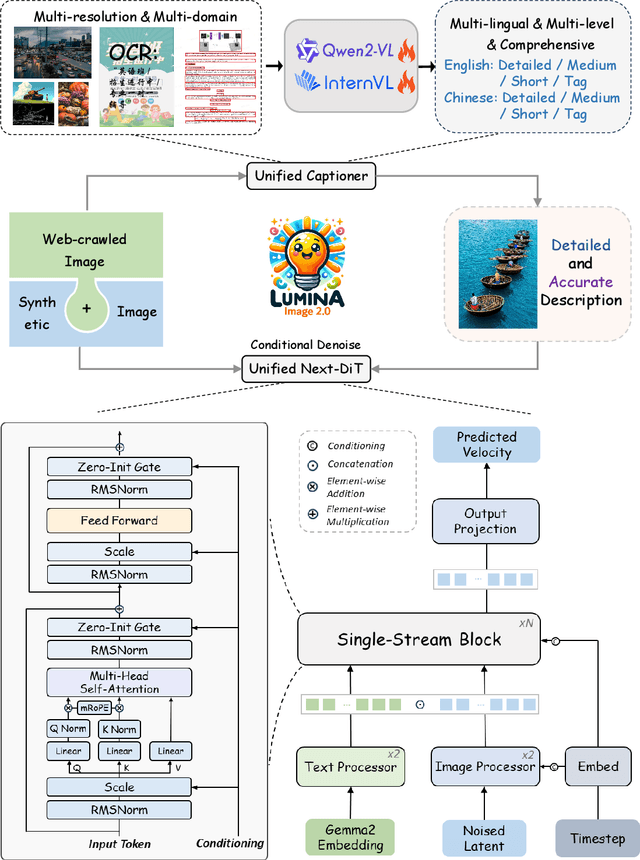

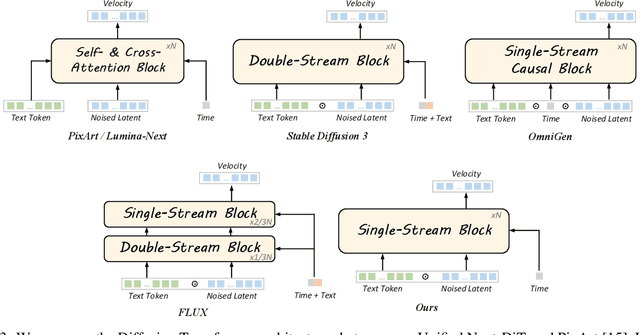
We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
Lumina-Video: Efficient and Flexible Video Generation with Multi-scale Next-DiT
Feb 10, 2025Recent advancements have established Diffusion Transformers (DiTs) as a dominant framework in generative modeling. Building on this success, Lumina-Next achieves exceptional performance in the generation of photorealistic images with Next-DiT. However, its potential for video generation remains largely untapped, with significant challenges in modeling the spatiotemporal complexity inherent to video data. To address this, we introduce Lumina-Video, a framework that leverages the strengths of Next-DiT while introducing tailored solutions for video synthesis. Lumina-Video incorporates a Multi-scale Next-DiT architecture, which jointly learns multiple patchifications to enhance both efficiency and flexibility. By incorporating the motion score as an explicit condition, Lumina-Video also enables direct control of generated videos' dynamic degree. Combined with a progressive training scheme with increasingly higher resolution and FPS, and a multi-source training scheme with mixed natural and synthetic data, Lumina-Video achieves remarkable aesthetic quality and motion smoothness at high training and inference efficiency. We additionally propose Lumina-V2A, a video-to-audio model based on Next-DiT, to create synchronized sounds for generated videos. Codes are released at https://www.github.com/Alpha-VLLM/Lumina-Video.
GMAI-VL & GMAI-VL-5.5M: A Large Vision-Language Model and A Comprehensive Multimodal Dataset Towards General Medical AI
Nov 21, 2024Despite significant advancements in general artificial intelligence, such as GPT-4, their effectiveness in the medical domain (general medical AI, GMAI) remains constrained due to the absence of specialized medical knowledge. To address this challenge, we present GMAI-VL-5.5M, a comprehensive multimodal medical dataset created by converting hundreds of specialized medical datasets into meticulously constructed image-text pairs. This dataset features comprehensive task coverage, diverse modalities, and high-quality image-text data. Building upon this multimodal dataset, we propose GMAI-VL, a general medical vision-language model with a progressively three-stage training strategy. This approach significantly enhances the model's ability by integrating visual and textual information, thereby improving its ability to process multimodal data and support accurate diagnosis and clinical decision-making. Experimental evaluations demonstrate that GMAI-VL achieves state-of-the-art results across a wide range of multimodal medical tasks, such as visual question answering and medical image diagnosis. Our contributions include the development of the GMAI-VL-5.5M dataset, the introduction of the GMAI-VL model, and the establishment of new benchmarks in multiple medical domains. Code and dataset will be released at https://github.com/uni-medical/GMAI-VL.
Intent-Aware Dialogue Generation and Multi-Task Contrastive Learning for Multi-Turn Intent Classification
Nov 21, 2024



Generating large-scale, domain-specific, multilingual multi-turn dialogue datasets remains a significant hurdle for training effective Multi-Turn Intent Classification models in chatbot systems. In this paper, we introduce Chain-of-Intent, a novel mechanism that combines Hidden Markov Models with Large Language Models (LLMs) to generate contextually aware, intent-driven conversations through self-play. By extracting domain-specific knowledge from e-commerce chat logs, we estimate conversation turns and intent transitions, which guide the generation of coherent dialogues. Leveraging LLMs to enhance emission probabilities, our approach produces natural and contextually consistent questions and answers. We also propose MINT-CL, a framework for multi-turn intent classification using multi-task contrastive learning, improving classification accuracy without the need for extensive annotated data. Evaluations show that our methods outperform baselines in dialogue quality and intent classification accuracy, especially in multilingual settings, while significantly reducing data generation efforts. Furthermore, we release MINT-E, a multilingual, intent-aware multi-turn e-commerce dialogue corpus to support future research in this area.
Balancing Accuracy and Efficiency in Multi-Turn Intent Classification for LLM-Powered Dialog Systems in Production
Nov 19, 2024



Accurate multi-turn intent classification is essential for advancing conversational AI systems. However, challenges such as the scarcity of comprehensive datasets and the complexity of contextual dependencies across dialogue turns hinder progress. This paper presents two novel approaches leveraging Large Language Models (LLMs) to enhance scalability and reduce latency in production dialogue systems. First, we introduce Symbol Tuning, which simplifies intent labels to reduce task complexity and improve performance in multi-turn dialogues. Second, we propose C-LARA (Consistency-aware, Linguistics Adaptive Retrieval Augmentation), a framework that employs LLMs for data augmentation and pseudo-labeling to generate synthetic multi-turn dialogues. These enriched datasets are used to fine-tune a small, efficient model suitable for deployment. Experiments conducted on multilingual dialogue datasets demonstrate significant improvements in classification accuracy and resource efficiency. Our methods enhance multi-turn intent classification accuracy by 5.09%, reduce annotation costs by 40%, and enable scalable deployment in low-resource multilingual industrial systems, highlighting their practicality and impact.