 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-1: Self-training with Oracle and 1-best Hypothesis
Aug 14, 2023



We introduce O-1, a new self-training objective to reduce training bias and unify training and evaluation metrics for speech recognition. O-1 is a faster variant of Expected Minimum Bayes Risk (EMBR), that boosts the oracle hypothesis and can accommodate both supervised and unsupervised data. We demonstrate the effectiveness of our approach in terms of recognition on publicly available SpeechStew datasets and a large-scale, in-house data set. On Speechstew, the O-1 objective closes the gap between the actual and oracle performance by 80\% relative compared to EMBR which bridges the gap by 43\% relative. O-1 achieves 13\% to 25\% relative improvement over EMBR on the various datasets that SpeechStew comprises of, and a 12\% relative gap reduction with respect to the oracle WER over EMBR training on the in-house dataset. Overall, O-1 results in a 9\% relative improvement in WER over EMBR, thereby speaking to the scalability of the proposed objective for large-scale datasets.
Using Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023



Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Large-scale Language Model Rescoring on Long-form Data
Jun 13, 2023



In this work, we study the impact of Large-scale Language Models (LLM) on Automated Speech Recognition (ASR) of YouTube videos, which we use as a source for long-form ASR. We demonstrate up to 8\% relative reduction in Word Error Eate (WER) on US English (en-us) and code-switched Indian English (en-in) long-form ASR test sets and a reduction of up to 30\% relative on Salient Term Error Rate (STER) over a strong first-pass baseline that uses a maximum-entropy based language model. Improved lattice processing that results in a lattice with a proper (non-tree) digraph topology and carrying context from the 1-best hypothesis of the previous segment(s) results in significant wins in rescoring with LLMs. We also find that the gains in performance from the combination of LLMs trained on vast quantities of available data (such as C4) and conventional neural LMs is additive and significantly outperforms a strong first-pass baseline with a maximum entropy LM.
* 5 pages, accepted in ICASSP 2023
Understanding Shared Speech-Text Representations
Apr 27, 2023Recently, a number of approaches to train speech models by incorpo-rating text into end-to-end models have been developed, with Mae-stro advancing state-of-the-art automatic speech recognition (ASR)and Speech Translation (ST) performance. In this paper, we expandour understanding of the resulting shared speech-text representationswith two types of analyses. First we examine the limits of speech-free domain adaptation, finding that a corpus-specific duration modelfor speech-text alignment is the most important component for learn-ing a shared speech-text representation. Second, we inspect the sim-ilarities between activations of unimodal (speech or text) encodersas compared to the activations of a shared encoder. We find that theshared encoder learns a more compact and overlapping speech-textrepresentation than the uni-modal encoders. We hypothesize that thispartially explains the effectiveness of the Maestro shared speech-textrepresentations.
Robust Knowledge Distillation from RNN-T Models With Noisy Training Labels Using Full-Sum Loss
Mar 10, 2023This work studies knowledge distillation (KD) and addresses its constraints for recurrent neural network transducer (RNN-T) models. In hard distillation, a teacher model transcribes large amounts of unlabelled speech to train a student model. Soft distillation is another popular KD method that distills the output logits of the teacher model. Due to the nature of RNN-T alignments, applying soft distillation between RNN-T architectures having different posterior distributions is challenging. In addition, bad teachers having high word-error-rate (WER) reduce the efficacy of KD. We investigate how to effectively distill knowledge from variable quality ASR teachers, which has not been studied before to the best of our knowledge. We show that a sequence-level KD, full-sum distillation, outperforms other distillation methods for RNN-T models, especially for bad teachers. We also propose a variant of full-sum distillation that distills the sequence discriminative knowledge of the teacher leading to further improvement in WER. We conduct experiments on public datasets namely SpeechStew and LibriSpeech, and on in-house production data.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
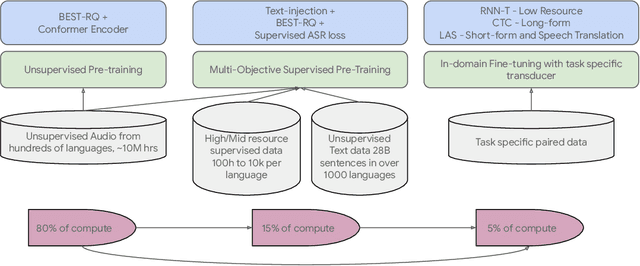
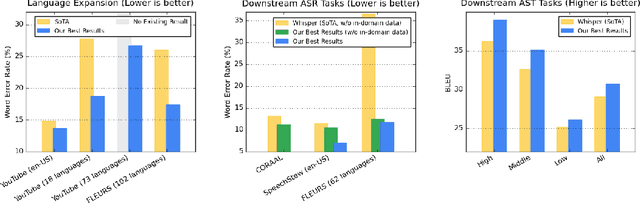

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
JEIT: Joint End-to-End Model and Internal Language Model Training for Speech Recognition
Feb 16, 2023



We propose JEIT, a joint end-to-end (E2E) model and internal language model (ILM) training method to inject large-scale unpaired text into ILM during E2E training which improves rare-word speech recognition. With JEIT, the E2E model computes an E2E loss on audio-transcript pairs while its ILM estimates a cross-entropy loss on unpaired text. The E2E model is trained to minimize a weighted sum of E2E and ILM losses. During JEIT, ILM absorbs knowledge from unpaired text while the E2E training serves as regularization. Unlike ILM adaptation methods, JEIT does not require a separate adaptation step and avoids the need for Kullback-Leibler divergence regularization of ILM. We also show that modular hybrid autoregressive transducer (MHAT) performs better than HAT in the JEIT framework, and is much more robust than HAT during ILM adaptation. To push the limit of unpaired text injection, we further propose a combined JEIT and JOIST training (CJJT) that benefits from modality matching, encoder text injection and ILM training. Both JEIT and CJJT can foster a more effective LM fusion. With 100B unpaired sentences, JEIT/CJJT improves rare-word recognition accuracy by up to 16.4% over a model trained without unpaired text.
* 5 pages, 3 figures, in ICASSP 2023
Modular Hybrid Autoregressive Transducer
Oct 31, 2022



Text-only adaptation of a transducer model remains challenging for end-to-end speech recognition since the transducer has no clearly separated acoustic model (AM), language model (LM) or blank model. In this work, we propose a modular hybrid autoregressive transducer (MHAT) that has structurally separated label and blank decoders to predict label and blank distributions, respectively, along with a shared acoustic encoder. The encoder and label decoder outputs are directly projected to AM and internal LM scores and then added to compute label posteriors. We train MHAT with an internal LM loss and a HAT loss to ensure that its internal LM becomes a standalone neural LM that can be effectively adapted to text. Moreover, text adaptation of MHAT fosters a much better LM fusion than internal LM subtraction-based methods. On Google's large-scale production data, a multi-domain MHAT adapted with 100B sentences achieves relative WER reductions of up to 12.4% without LM fusion and 21.5% with LM fusion from 400K-hour trained HAT.
* 8 pages, 1 figure, SLT 2022
Virtuoso: Massive Multilingual Speech-Text Joint Semi-Supervised Learning for Text-To-Speech
Oct 27, 2022This paper proposes Virtuoso, a massively multilingual speech-text joint semi-supervised learning framework for text-to-speech synthesis (TTS) models. Existing multilingual TTS typically supports tens of languages, which are a small fraction of the thousands of languages in the world. One difficulty to scale multilingual TTS to hundreds of languages is collecting high-quality speech-text paired data in low-resource languages. This study extends Maestro, a speech-text joint pretraining framework for automatic speech recognition (ASR), to speech generation tasks. To train a TTS model from various types of speech and text data, different training schemes are designed to handle supervised (paired TTS and ASR data) and unsupervised (untranscribed speech and unspoken text) datasets. Experimental evaluation shows that 1) multilingual TTS models trained on Virtuoso can achieve significantly better naturalness and intelligibility than baseline ones in seen languages, and 2) they can synthesize reasonably intelligible and naturally sounding speech for unseen languages where no high-quality paired TTS data is available.
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
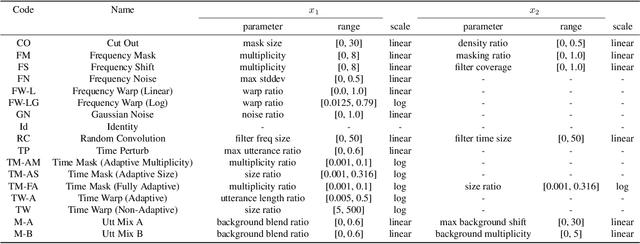
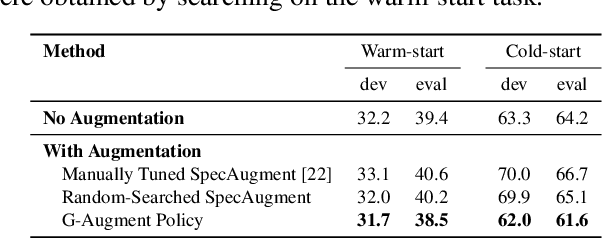
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.